Developing Kubernetes operator with Operator Framework

As mentioned in the article Radar Technologies , Lamoda is actively moving in the direction of microservice architecture. Most of our services are packaged with Helm and deployed to Kubernetes. This approach fully satisfies our needs in 99% of cases. Remains 1%, when the standard functionality Kubernetes is not enough, for example, when you need to configure a backup or update the service for a specific event. To solve this problem, we use the pattern operator. In this series of articles, I - Grigory Mikhalkin, the developer of the R & D team at Lamoda - will talk about the lessons I learned from my experience of developing K8s operators using the Operator Framework .
What is an operator?
One of the ways to expand the functionality of Kubernetes is to create your own controllers. The main abstractions in Kubernetes are objects and controllers. Objects describe the desired state of the cluster. For example, Pod describes which containers need to be run and startup parameters, and the ReplicaSet object says how many replicas of this Pod should be launched. The controllers manage the cluster state based on the description of the objects, as applied to the above case, the ReplicationController will maintain the number of Pod replicas specified in the ReplicaSet. With the help of new controllers, you can implement additional logic such as sending notifications on events, recovering from a crash, or managing third party resources .
Operator is a kubernetes application that includes one or more controllers serving the third party resource. The concept came up with the CoreOS team in 2016, and recently the popularity of operators has been growing rapidly. You can try to find the desired operator in the list on kubedex , (more than 100 publicly available operators are listed here), as well as on OperatorHub . To develop the operator now there are 3 popular tools: Kubebuilder , Operator SDK and Metacontroller . In Lamoda, we use Operator SDK, so we’ll talk about it later.
Operator SDK
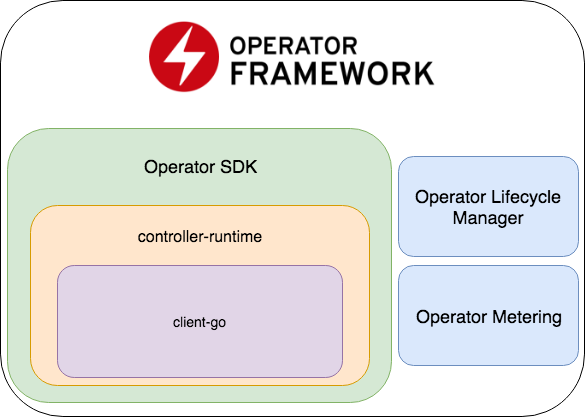
The Operator SDK is part of the Operator Framework, which includes two more important parts: Operator Lifecycle Manager and Operator Metering.
- Operator SDK is a wrapper over a controller-runtime , a popular library for developing controllers (which, in turn, is a wrapper over a client-go ), code generator + framework for writing E2E tests.
- Operator Lifecycle Manager - a framework for managing already working operators; resolves situations when an operator switches to zombie mode or rolls out a new version.
- Operator Metering - as the name implies, it collects data on the work of the operator, and can also generate reports based on them.
Creating a new project
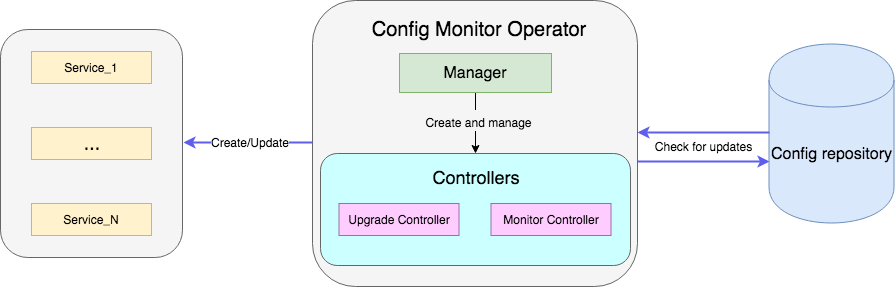
As an example, there will be an operator who monitors the file with configs in the repository and, when updated, restarts the deployment of the service with new configs. Full sample code is available here .
Create a project with a new operator:
operator-sdk new config-monitor The code generator will create a code for an operator working in a dedicated namespace . This approach is preferable to giving access to the entire cluster, since in case of errors the problems will be isolated within the same namespace. You can generate a cluster-wide statement by adding to the --cluster-scoped . Inside the created project there will be the following directories:
- cmd - contains the
main package, in which theManagerinitialized and started; - deploy - contains declarations of the operator, CRD and objects necessary for setting up the RBAC operator;
- pkg - here will be our main code for new objects and controllers.
There is only one cmd/manager/main.go file in cmd/manager/main.go .
// Become the leader before proceeding err = leader.Become(ctx, "config-monitor-lock") if err != nil { log.Error(err, "") os.Exit(1) } // Create a new Cmd to provide shared dependencies and start components mgr, err := manager.New(cfg, manager.Options{ Namespace: namespace, MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort), }) ... // Setup Scheme for all resources if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Error(err, "") os.Exit(1) } // Setup all Controllers if err := controller.AddToManager(mgr); err != nil { log.Error(err, "") os.Exit(1) } ... // Start the Cmd if err := mgr.Start(signals.SetupSignalHandler()); err != nil { log.Error(err, "Manager exited non-zero") os.Exit(1) } In the first line: err = leader.Become(ctx, "config-monitor-lock") - the leader is selected. In most scenarios, only one active instance of a statement is needed per namespace / cluster. By default, the Operator SDK uses the Leader for life strategy — the first instance of the operator will remain the leader until it is removed from the cluster.
After this instance of the operator has been designated as a leader, a new Manager is initialized - mgr, err := manager.New(...) . His responsibilities include:
err := apis.AddToScheme(mgr.GetScheme())- registration of new resource schemes;err := controller.AddToManager(mgr)- register controllers;err := mgr.Start(signals.SetupSignalHandler())- launch and control of controllers.
At the moment we have neither new resources nor controllers for registration. You can add a new resource using the command:
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredService This command will add the definition of the MonitoredService resource schema to the pkg/apis directory, as well as yaml with the definition of CRD in deploy/crds . Of all the generated files, it’s worth changing only the schema definition in monitoredservice_types.go . The MonitoredServiceSpec type determines the desired state of the resource: what the user specifies in yaml with the definition of the resource. In the context of our operator, the Size field determines the desired number of replicas. ConfigRepo indicates where the actual configs can be pulled from. MonitoredServiceStatus determines the observed state of the resource, for example, it stores the names of the Pods belonging to this resource and the current spec Pods.
After editing the scheme, you need to run the command:
operator-sdk generate k8s It will update the definition of CRD in deploy/crds .
Now we will create the main part of our operator, the controller:
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=Monitor The monitor_controller.go file will appear in the pkg/controller monitor_controller.go , in which we add the logic we need.
Controller development
The controller is the main working unit of the operator. In our case there are two controllers:
- Monitor ontroller monitors the change of configs of the service;
- Upgrade controller updates the service and maintains it in the desired state.
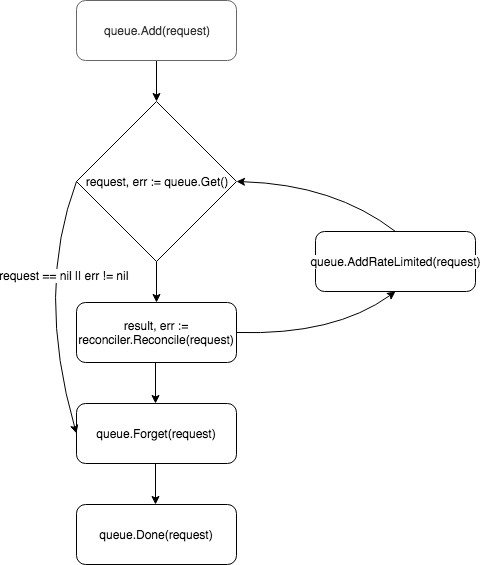
At its core, the controller is a control loop, it monitors the queue with the events to which it is subscribed, and processes them:
A new controller is created and registered by the manager in the add method:
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r}) Using the Watch method, we sign it to events regarding the creation of a new resource or the Spec update of an existing MonitoredService resource:
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate) The event type can be configured using the src and predicates parameters. src accepts objects of type Source .
Informer- periodically pollsapiserverabout events that satisfy the filter, if there is such an event, puts it in the controller's queue. Incontroller-runtimethis is a wrapper over theSharedIndexInformerfrom theclient-go.Kindis also a wrapper overSharedIndexInformer, but, unlikeInformer, it independently creates an informer instance based on the passed parameters (the monitored resource scheme).Channel- acceptschan event.GenericEventas a parameter, events coming through it puts in the controller queue.
redicates expects objects that satisfy the Predicate interface. In fact, this is an additional filter for events, for example, when filtering UpdateEvent you can see exactly what changes were made in the resource spec .
When an event arrives, it is received by EventHandler - the second argument of the Watch method - which wraps the event in a request format that Reconciler expects:
EnqueueRequestForObject- creates a query with the name and namespace of the object that caused the event;EnqueueRequestForOwner- creates a request with the data of the object's parent. This is necessary, for example, if the resource under the control of thePodbeen deleted, and it is necessary to start its replacement;EnqueueRequestsFromMapFunc- takes as a parametermapfunction that receives the event (wrapped inMapObject) at the input and returns a list of requests. An example of when you need this handler is a timer, for each tick of which you need to pull out new configs for all available services.
Requests are put into the controller's queue, and one of the workers (by default, the controller has one) pulls the event out of the queue and sends it to Reconciler 's.
Reconciler implements only one method - Reconcile , which contains the main event processing logic:
func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) { reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name) reqLogger.Info("Checking updates in repo for MonitoredService") // fetch the Monitor instance instance := &servicesv1alpha1.MonitoredService{} err := r.client.Get(context.Background(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } // check if service's config was updated // if it was, send event to upgrade controller if podSpec, ok := r.isServiceConfigUpdated(instance); ok { // Update instance Spec instance.Status.PodSpec = *podSpec instance.Status.ConfigChanged = true err = r.client.Status().Update(context.Background(), instance) if err != nil { reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name) return reconcile.Result{}, err } r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance} } return reconcile.Result{}, nil } The method accepts a Request object with the NamespacedName field, by which the resource can be pulled out of the cache: r.client.Get(context.TODO(), request.NamespacedName, instance) . In the example, a request is made to the file with the service configuration referenced by the ConfigRepo field in the resource spec . If the config is updated, a new event of the GenericEvent type is GenericEvent and sent to the channel that the Upgrade controller is listening to.
After processing the request, Reconcile returns a Result and error object. If in Result the Requeue: true or error != nil Requeue: true field, the controller will return the request back to the queue using the queue.AddRateLimited method. The request will be returned to the queue with a delay, which is determined by RateLimiter . The default is ItemExponentialFailureRateLimiter , which increases exponentially the delay time with an increase in the number of "returns" of the request. If the Requeue field Requeue not set, and no error occurred during the processing of the request, the controller will call the Queue.Forget method, which will remove the request from the RateLimiter cache (and thereby resetting the number of returns). At the end of the request processing, the controller removes it from the queue using the Queue.Done method.
Operator start
The components of the operator were described above, and one question remained: how to start it. First you need to make sure that all the necessary resources are installed (for local testing I recommend setting up minikube ):
# Setup Service Account kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml # Setup custom resource kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yaml After the prerequisites have been met, there are two easy ways to run the statement for testing. The easiest way is to run it outside the cluster using the command:
operator-sdk up local --namespace=default The second way is to close the operator in the cluster. First you need to build a Docker image with the operator:
operator-sdk build config-monitor-operator:latest In the file deploy/operator.yaml replace REPLACE_IMAGE with config-monitor-operator:latest :
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yaml Create a deployment with the operator:
kubectl create -f deploy/operator.yaml Now Pod with a test service should appear on the cluster's list on the cluster, and in the second case, another one with an operator.
Instead of Conclusion or Best Practices
The key problems of the development of operators at the moment are the poorly documented tools and the lack of well-established best practices. When a new developer starts developing an operator, he has practically nowhere to look at examples of the implementation of one or another requirement, therefore mistakes are inevitable. Below are a few lessons that we learned from our mistakes:
- If there are two related applications, you should avoid the desire to combine them with a single operator. Otherwise, the principle of loose coupling services is violated.
- It is necessary to remember about the separation of concerns: do not try to implement all the logic in one controller. For example, it is worth spreading the functions of monitoring configs and creating / updating a resource.
- In the
Reconcilemethod, you should avoid blocking calls. For example, you can pull up configs from an external source, but if the operation is longer, create a Gorutin for this, and send the request back to the queue, specifyingRequeue: truein the response.
In the comments it would be interesting to hear about your experience in developing operators. And in the next part we will talk about operator testing.
')
Source: https://habr.com/ru/post/446648/
All Articles