As we did cloudy FaaS inside Kubernetes and won at Tinkoff hackathon
Since last year, our company began to organize hackathons. The first such competition was very successful, we wrote about it in the article . The second hackathon was held in February 2019 and was no less successful. The organizer wrote about the purpose of the latter not so long ago.
The participants were given a rather interesting task with complete freedom in choosing a stack of technologies for its implementation. It was necessary to implement a decision-making platform for convenient deployment of client scoring functions that could work on a fast stream of applications, withstand heavy loads, and the system itself was easily scaled.
The task is non-trivial and can be solved in many ways, as we have seen at the demonstration of the final presentations of the participants' projects. On the hackathon there were 6 teams of 5 people each, all participants had good projects, but our platform turned out to be the most competitive. We have a very interesting project, which I would like to talk about in this article.
')
Our solution is a platform based on Serverless architecture inside Kubernetes, which reduces the time it takes to bring new features to production. It allows analysts to write code in a convenient environment for them and deploy it to the prod without the participation of engineers and developers.
What is scoring?
In Tinkoff.ru, as in many modern companies, there is scoring clients. Scoring is a customer rating system based on statistical data analysis methods.
For example, a client requests us to give him a loan, or open an account with us. If we plan to issue a loan to him, then we need to evaluate his solvency, and if we have an IP account, then we need to be sure that the client will not conduct fraudulent operations.
Making such decisions is based on mathematical models that analyze both the data from the application itself and the data from our repository. In addition to scoring, similar statistical methods can also be used in the service of forming individual recommendations for new products for our customers.
The method of such an assessment can take a variety of input data. And at some point we can add a new parameter to the input, which, according to the results of the analysis of historical data, will increase the conversion of the use of the service.
We keep a lot of customer relationship data, and the amount of this information is constantly growing. In order for scoring to work, data processing also requires rules (or mathematical models) that allow you to quickly decide who will approve the application, who will refuse, and who else to offer a couple of products, assessing its potential interest.
For this task, we already use a specialized decision-making system IBM WebSphere ILOG JRules BRMS , which, based on the rules set by analysts, technologists and developers, decides whether to approve a particular banking product to a client or refuse.
There are many ready-made solutions on the market, both for scoring models and for decision-making systems themselves. We use one of such systems in our company. But business is growing, diversifying, increasing both the number of customers and the number of products offered, and along with this there are ideas how to improve the existing decision-making process. Surely people working with the existing system have a lot of ideas how to make it easier, better, more convenient, but sometimes ideas from outside can be useful. In order to gather sound ideas, a new hackathon was organized.
Task
Hackathon was held on February 23. The participants were offered a combat mission: to develop a decision-making system that had to meet a number of conditions.
We were told how the existing system functions and what difficulties arise during its operation, as well as what business goals the developed platform should pursue. The system should have fast time-to-market rules being developed so that the working code of analysts gets into production as quickly as possible. And for the incoming flow of applications decision time should strive to minimize. Also, the system being developed should be cross-sell in order to give the client the opportunity to purchase other products of the company if they are approved by us and potential interest from the client.
It is clear that overnight it is impossible to write a ready-to-release project that will certainly go into production, and the whole system is quite difficult to cover, so we were asked to implement at least a part of it. A number of requirements were established that a prototype must meet. It was possible to try both to cover all the requirements entirely, and to work out in detail the individual sections of the developed platform.
As for technology, then all participants were given complete freedom of choice. It was possible to use any concepts and technologies: Data streaming, machine learning, event sourcing, big data and others.
Our solution
After a small brainstorming session, we decided that the FaaS solution would be ideal for the task.
For this solution, it was necessary to find a suitable Serverless framework to implement the rules of the developed decision-making system. Since Tinkoff actively uses Kubernetes to manage the infrastructure, we have considered several ready-made solutions based on it, I will discuss more about it later.
To find the most effective solution, we looked at the product under development through the eyes of its users. The main users of our system are the analysts who develop the rules. The rules must be deployed to the server, or, in our case, deployed in the cloud, for later decision making. From the perspective of the analyst, the workflow is as follows:
- The analyst writes a script, rule, or ML model based on data from the repository. As part of the hackathon, we decided to use Mongodb, but the choice of data storage system is not critical here.
- After testing the developed rules on historical data, the analyst pours his code into the admin area.
- In order to ensure versioning, all the code will go into the Git repository.
- Through the admin panel, you can deploy the code in the cloud as a separate functional Serverless module.
Source data from customers must pass through a specialized Enrichment service designed to enrich the initial request with data from the repository. It was important to implement this service in such a way as to ensure work with a single repository (from which the analyst takes data when developing rules), in order to maintain a single data structure.
Even before the hackathon, we decided on a Serverless framework to be used. Today, there are quite a few technologies on the market that implement this approach. The most popular solutions in the framework of the Kubernetes architecture are Fission, Open FaaS and Kubeless. There is even a good article with their description and comparative analysis .
After weighing all the pros and cons, we opted for Fission . This Serverless framework is quite simple to manage and meets the requirements of the task.
To work with Fission, you need to understand two basic concepts: function and environment. A function is a piece of code written in one of the languages for which there is a fission environment. The list of environments implemented within this framework includes Python, JS, Go, JVM and many other popular languages and technologies.
Fission is also capable of performing functions split into several files, pre-packaged in an archive. The work of Fission in the Kubernetes cluster is provided by specialized trades managed by the framework itself. To interact with the cluster sub-fields, each function must be assigned its own route, and to which you can send GET parameters or request body in case of a POST request.
As a result, we planned to get a solution that allows analysts to deploy developed rules scripts without the participation of engineers and developers. The described approach also saves developers from having to rewrite the code of analysts into another language. For example, for the current decision-making system we use, we have to write rules on narrow-profile technologies and languages, the scope of which is extremely limited, and there is also a strong dependence on the application server, since all the draft rules of the bank are deployed in a single environment. As a result, for the deployment of new rules, it is necessary to release the entire system.
In our proposed solution, there is no need to release the rules, the code is easily deployed at the touch of a button. Infrastructure management in Kubernetes allows not to think about the load and scaling, such problems are solved out of the box. And the use of a unified data warehouse eliminates the need to compare real-time data with historical data, which simplifies the work of the analyst.
What we did
Since we came to the hackathon with a ready-made solution (in our fantasies), we only need to convert all our thoughts into lines of code.
The key to success on any hackathon is a preparation and a well-written plan. Therefore, first of all, we decided on which modules the architecture of our system will consist of and what technologies we will use.
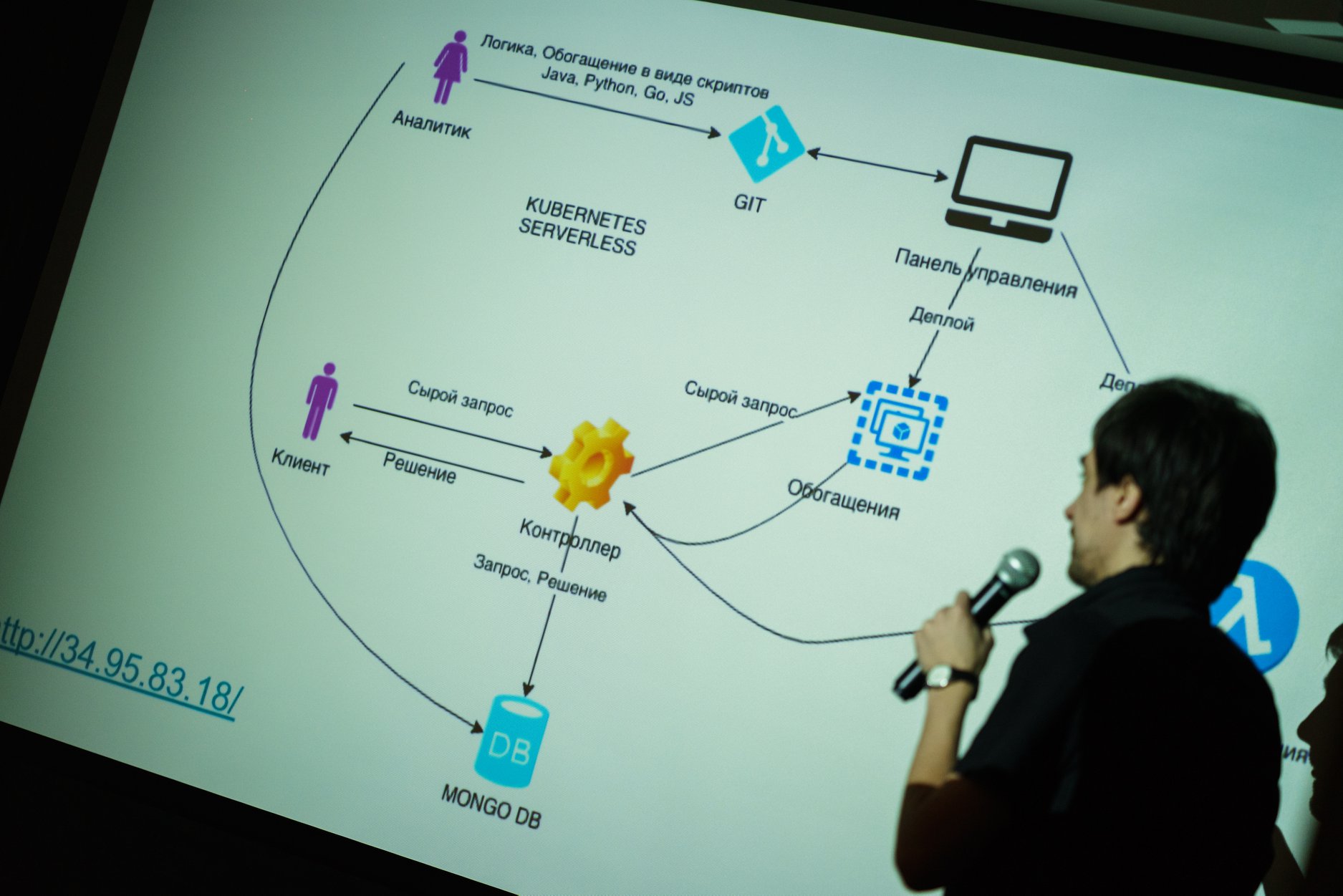
The architecture of our project was as follows:

This diagram shows two entry points, an analyst (the main user of our system) and a client.
The work process is built like this. The analyst develops the rule function and the data enrichment function for his model, stores his code in the Git repository, and through the administrator’s application deploys his model in the cloud. Consider how the expanded function will be called and make decisions on incoming requests from customers:
- The client filling the form on the site, sends the request to the controller. The application comes to the input of the system, according to which it is necessary to make a decision, and is recorded in the database in its original form.
- Next, a raw request is sent for enrichment, if necessary. You can supplement the initial request with data from external services as well as from the repository. The resulting enriched query is also stored in the database.
- The analyst function is launched, which accepts an enriched query at the input and returns a solution, which is also recorded in the repository.
In our system, we decided to use MongoDB as a storage in the form of documented data storage in the form of JSON documents, since enrichment services, including the original request, aggregated all the data through REST controllers.
So, we had a day for the implementation of the platform. We quite successfully distributed the roles; each team member had his own area of responsibility in our project:
- Front-end admin for the analyst to work, through which he could download the rules from the system of control of versioning of written scripts, choose options for enriching the input data and edit the script rules online.
- Backend admin, which includes a front-end REST API and VCS integration.
- Setting up the infrastructure in Google Cloud and developing a data enrichment service.
- The module for integrating the admin application with the Serverless framework for subsequent deployment of rules.
- Scripts of rules for testing the health of the entire system and aggregation of analytics for incoming applications (decisions taken) for the final demonstration.
Let's start in order.
Our frontend was written in Angular 7 using the bank UI Kit. The final admin version looked like this:
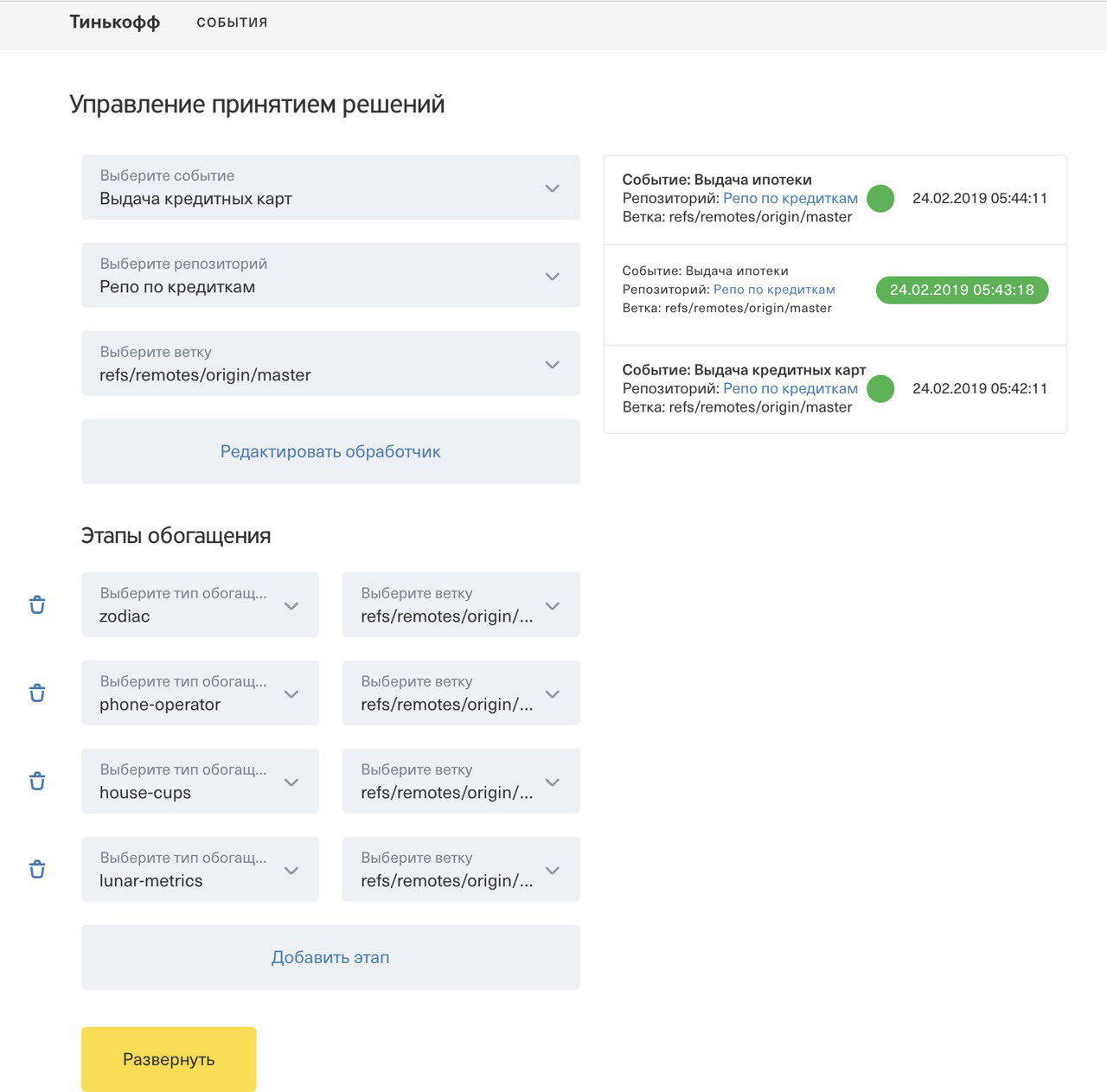
Since there was not much time, we tried to implement only the key functionality. To deploy a function in the Kubernetes cluster, it was necessary to select an event (a service for which the rule should be deployed in the cloud) and the code for the function that implements the decision logic. For each deployment of the rule for the selected service, we wrote a log of this event. In the admin panel you could see the logs of all events.
All function code was stored in a remote Git repository, which also had to be set in the admin panel. For code versioning, all functions were stored in different branches of the repository. The admin panel also provides for the possibility of making adjustments to the written scripts so that before deploying the functions to the production, you can not only check the written code, but also make the necessary edits.
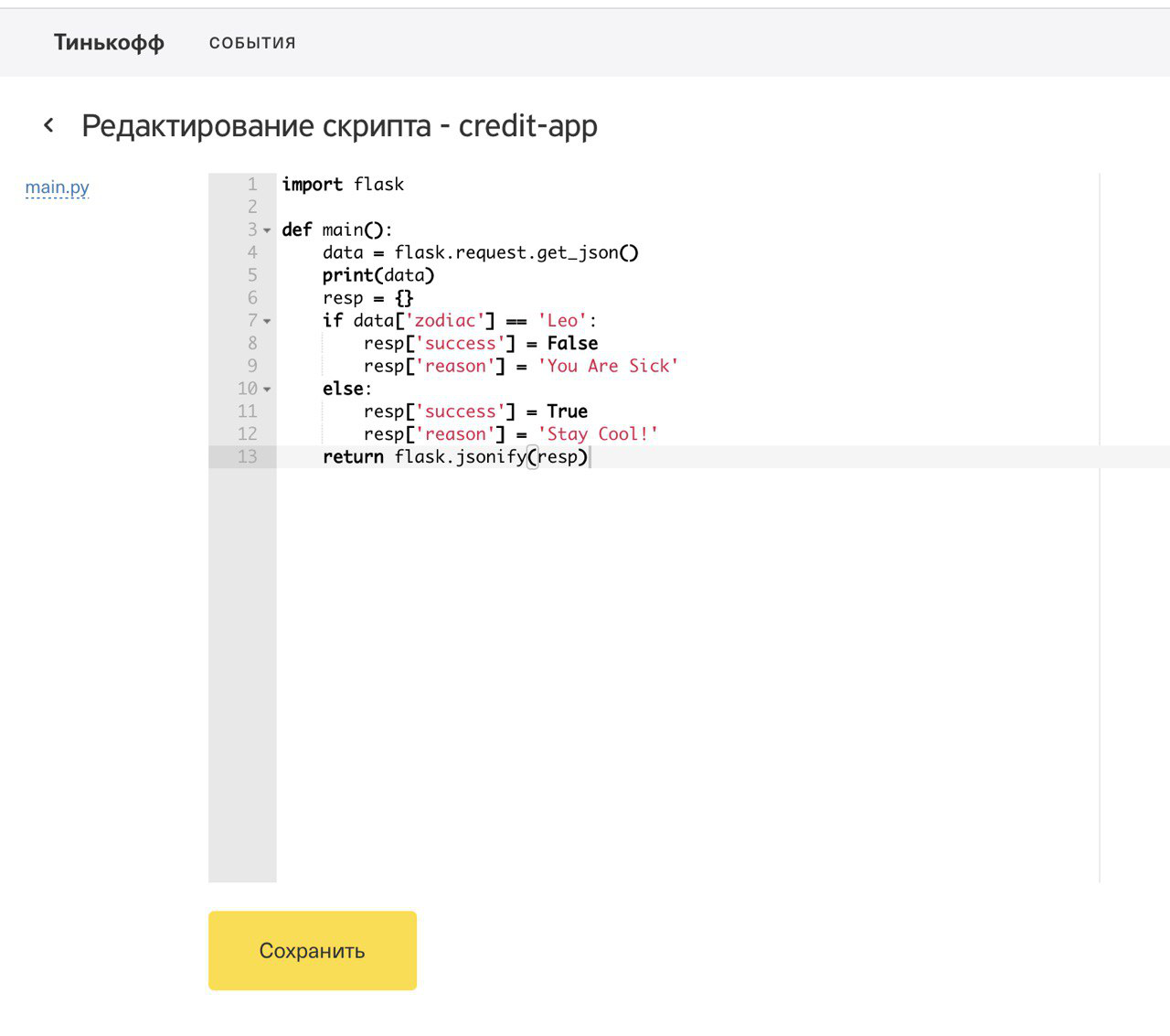
In addition to the rules functions, we also implemented the possibility of stepwise enrichment of source data with the help of Enrichment functions, the code of which was also scripts in which one could go to the data warehouse, call third-party services and perform preliminary calculations. To demonstrate our solution, we calculated the sign of the client’s zodiac, which left the application, and determined its mobile operator using a third-party REST service.
The platform backend was written in Java and implemented as a Spring Boot application. We initially planned to use Postgres for storing admin data, but, as part of the hackathon, we decided to limit ourselves to simple H2, in order to save time. On the back-end, integration with Bitbucket was implemented for versioning the query enrichment functions and rule scripts. For integration with remote Git repositories, the JGit library was used , which is a kind of wrapper over CLI commands that allows you to execute any git instructions using a convenient software interface. So we had two separate repositories for enrichment functions and rules, and all the scripts are arranged in directories. Through the UI, it was possible to select the last commit script of an arbitrary repository branch. When making changes to the code through the admin in the remote repositories, commits of the modified code were created.
To implement our idea, we needed a suitable infrastructure. We decided to deploy our Kubernetes cluster in the cloud. Our choice was Google Cloud Platform. The Fission serverless framework was installed in the Kubernetes cluster, which we deployed to Gcloud. Initially, the source data enrichment service was implemented by a separate Java application wrapped in a Pod within the k8s cluster. But after preliminary demonstration of our project in the middle of the hackathon, we were recommended to make the Enrichment service more flexible in order to provide the opportunity to choose how to enrich the raw data of the incoming requests. And we had no choice but to make the enrichment service also Serverless.
To work with Fission, we used the Fission CLI, which needs to be installed on top of the Kubernetes CLI. Deploy functions in the k8s cluster is quite simple, you only need to assign an internal route and ingress for the function to allow incoming traffic if access is needed outside the cluster. Deployment of a single function usually takes no more than 10 seconds.
Final show of the project and debriefing
To demonstrate the operation of our system, we have placed on a remote server a simple form on which you can apply for one of the bank products. For the request it was necessary to enter your initials, date of birth and phone number.
The data from the client form went to the controller, which in parallel sent the requests for all available rules, having previously enriched the data according to the specified conditions, and saving them to the common storage. In total, we have deployed three functions that make decisions on incoming requests and 4 data enrichment services. After sending the application, the client received our solution:

In addition to refusal or approval, the client also received a list of other products, requests for which we sent in parallel. So we demonstrated the possibility of cross-sale in our platform.
In total, 3 fictional products of the bank were available:
- Credit.
- A toy
- Mortgage.
During each demonstration, we deployed the prepared functions and enrichment scripts for each service.
Each rule required its own set of input data. So, for the approval of the mortgage, we calculated the client's zodiac sign and associated it with the logic of the lunar calendar. For the approval of the toy, we checked that the client had reached the age of majority, and for issuing a loan we sent a request to the external open service of determining the cellular operator, and made a decision on it.
We tried to make our demonstration interesting and interactive, everyone present could enter our form and check the availability of our imaginary services. And at the very end of the presentation, we demonstrated the analytics of the received applications, where it was shown how many people used our service, the number of approvals, refusals.
To collect online analytics, we further deployed the open source BI tool Metabase and screwed it to our repository. Metabase allows you to build screens with analytics on the data of interest to us, you only need to register the connection to the database, select the tables (in our case, data collections, since we used MongoDB), and specify the fields of interest.
As a result, we got a good prototype of a decision-making platform, and at the demonstration, each listener could personally test its performance. An interesting solution, a ready-made prototype and a successful demonstration allowed us to win, despite strong competition from other teams. I am sure that you can also write an interesting article on the project of each team.
Source: https://habr.com/ru/post/446616/
All Articles