Asynchrony in programming
In the area of developing high-load multi-threaded or distributed applications, there are often discussions about asynchronous programming. Today we will plunge into asynchrony in detail and study what it is when it occurs, how it affects the code and programming language that we use. We will understand why we need Futures and Promises and touch upon the Korutin and operating systems. This will make the trade-offs arising during software development more explicit.
The material is based on a transcript of a report by Ivan Puzyrevsky, a teacher at the Yandex Data Analysis School.

Videotape
1. Content
2. Introduction
Hello everyone, my name is Ivan Puzyrevsky, I work for Yandex. For the last six years I have been working on the infrastructure for storing and processing data; now I have moved to a product - in the search for travel, hotels and tickets. Since I worked for a long time in the infrastructure, I have accumulated quite a lot of experience how to write different loaded applications. Our infrastructure operates 24*7*365 every day non-stop, continuously on thousands of machines. Naturally, you need to write code so that it works reliably and efficiently and solves the tasks that the company sets for us.
Today we will talk about asynchrony. What is asynchrony? This is a mismatch of something with something in time. From this description it’s not at all clear what I’m going to talk about today. To somehow clarify the question, I need an example a la “Hello, world!”. Asynchrony usually occurs in the context of writing network applications, so I will have a network equivalent of “Hello, world!”. This application is ping-pong. The code looks like this:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return; I create a socket, read a string from there, and check if it is ping, then I write back pong. Very simple and straightforward. What happens when you see such code on your computer screen? We think of this code as a sequence of such steps:
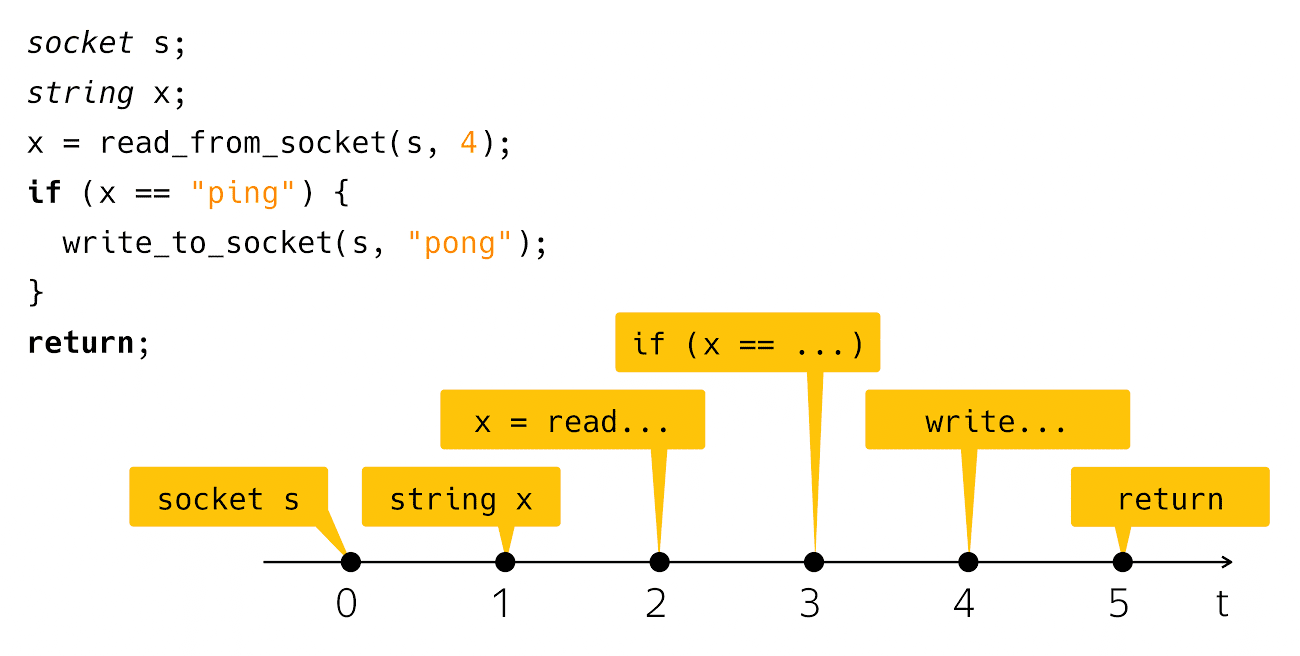
From the point of view of real physical time, everything is a bit shifted.

Those who actually wrote this code and run it know that after the read step and after the step
write goes a rather noticeable time interval when our program seems to be doing nothing from the point of view of our code, but under the hood there is a machine, which we call “input-output”.

During I / O, packets are exchanged over the network and all associated heavy, low-level work. Let's conduct a mental experiment: let's take such a single program, run it on a single physical processor and pretend that we don't have any operating system, what will we get? The processor can not stop, it continues to take cycles, without executing any instructions, just wasting energy.
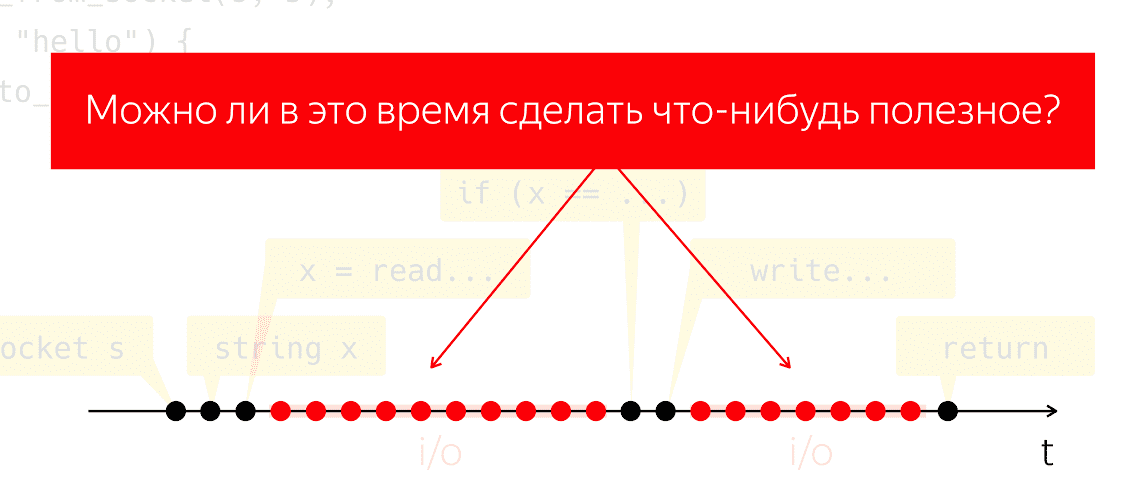
The question arises whether we can do something useful during this period of time. A very natural question, the answer to which would allow us to save processor power and use them for something useful, while our application seems to be doing nothing.
3. Basic concepts
3.1. Execution thread
How can we approach this task? Let's agree on the concepts. I will say “flow of execution,” meaning some sensible sequence of elementary operations or steps. Meaningfulness will be determined by the context in which I speak of the flow of execution. That is, if we are talking about a single-threaded algorithm (Aho-Korasik, search by graph), then this algorithm itself - there is already a thread of execution. He takes some steps to solve the problem.
If I am talking about a database, then one thread of execution can be part of the actions performed by the database to service one incoming request. Same for web servers. If I write some kind of mobile or web application, then to service a single user operation, for example, a click on a button, network interactions, interaction with local storage, and so on occur. The sequence of these actions from the point of view of my mobile application will also be a separate meaningful flow of execution. From the point of view of the operating system, the process or thread of the process is also a meaningful thread of execution.
3.2. Multitasking and concurrency
The cornerstone of performance is the ability to do this trick: when I have one execution thread that contains emptiness in my physical temporal sweep, then fill these voids with something useful — perform the steps of other execution threads.
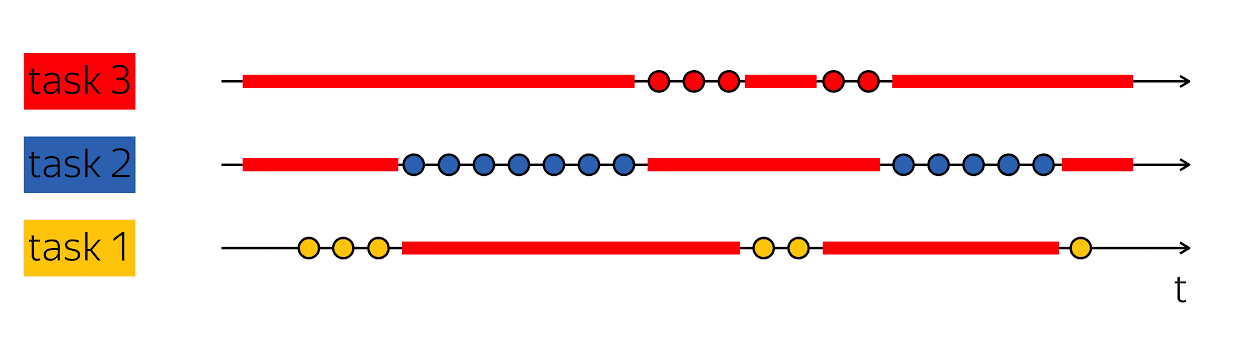
Databases typically serve many clients at the same time. If we can combine work on multiple threads of execution within a single thread of a higher level, this is called multitasking. That is, multitasking is when I, within the framework of one larger stream of execution, perform actions that are subordinate to the solution of smaller tasks.
It is important not to confuse the concept of multitasking with parallelism. Parallelism -
these are properties of the execution environment, which makes it possible to make progress in different execution threads in one step of time, in one step. If I have two physical processors, then they can execute two instructions in one clock cycle. If the program is running on a single processor, then it will take two bars of time to execute the same two instructions.

It is important not to confuse these concepts, as they fall into different categories. Multitasking is a property of your program that it is internally structured as a variable work on different tasks. Parallelism is a property of the execution environment that allows you to work on several tasks in one measure of time.
In many ways, asynchronous code and writing asynchronous code is writing multitasking code. The main difficulty is in how I code tasks and how to manage them. Therefore, today we will talk about this - about writing multi-tasking code.
4. Blocking and waiting

Let's start with some simple example. Let's go back to the ping-pong:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return; As we have already discussed, after the read and white lines, the execution thread falls asleep, is blocked. Usually we say, "the flow is blocked."
socket s; string x; x = read_from_socket(s, 4); /* thread is blocked here */ if (x == "ping") { write_to_socket(s, "pong"); /* thread is blocked here */ } return; This means that the flow of execution has reached a point where it is necessary for an event to proceed to continue. In particular, in the case of our network application, it is necessary for the data to arrive over the network or, on the contrary, we have a buffer for writing data to the network. Events may be different. If we are talking about time aspects, we can wait for the timer to trigger or for another process to complete. Events here are a kind of abstract thing, it is important to understand about them that they can be expected.

When we write simple code, we implicitly give control of the expectation of events to a higher level. In our case, the operating system. She, as the essence of a higher level, is responsible for choosing which task will be performed further, and she is also responsible for tracking the occurrence of events.
Our code, which we write as developers, is structured at the same time regarding the work on one task. The example code fragment processes one connection: it reads ping from one connection and writes pong to one connection.
The code is clear. You can read it and understand what it does, how it works, what problem it solves, what invariants it has, and so on. At the same time, we very poorly manage the planning of tasks in such a model. In general, operating systems have concepts of priorities, but if you wrote soft real-time systems, then you know that the tools available in Linux are not enough to create sufficiently sane real-time systems.
Further, the operating system is a complex thing, and switching the context from our application to the kernel costs a few microseconds, which, with some simple counting, gives us an estimate of about 20-100 thousand context switches per second. This means that if we write a web server, we can process about 20 thousand requests in one second, assuming that processing requests is ten times more expensive than the work of the system.

4.1. Non-blocking wait
If you come to the situation that you need to work with the network more efficiently, then you start looking for help on the Internet and come to the use of select / epoll. It is written on the Internet that if you want to serve thousands of connections at the same time, you need an epoll, because it is a good mechanism and so on. You open the documentation and see something like this:
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout); void FD_CLR(int fd, fd_set* set); int FD_ISSET(int fd, fd_set* set); void FD_SET(int fd, fd_set* set); void FD_ZERO(fd_set* set); int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout); Functions in which the interface contains either a set of descriptors that you work with (in the select case) or a set of events that pass
across the boundaries of your operating system kernel application that you need to handle (in the case of epoll).
It is also worth adding that you can come not to select / epoll, but to a library like libuv, which has no events in the API, but will have many callbacks. The library interface will say: "Dear friend, to read the socket, provide a callback, which I will call when the data is available."
int uv_timer_start(uv_timer_t* handle, uv_timer_cb cb, uint64_t timeout, uint64_t repeat); typedef void (*uv_timer_cb)(uv_timer_t* handle); int uv_read_start(uv_stream_t* stream, uv_alloc_cb alloc_cb, uv_read_cb read_cb); int uv_read_stop(uv_stream_t*); typedef void (*uv_read_cb)(uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf); int uv_write(uv_write_t* req, uv_stream_t* handle, const uv_buf_t bufs[], unsigned int nbufs, uv_write_cb cb); typedef void (*uv_write_cb)(uv_write_t* req, int status); What has changed compared to our synchronous code in the previous chapter? The code has become asynchronous. This means that we in the application took the logic to determine the point in time when the occurrence of events is monitored. Explicit select / epoll calls are points where we request information about the events from the operating system. We also took a choice in the code of our application, on which task to work further.

From the examples of interfaces, it can be noted that there are basically two mechanisms for introducing multitasking. One kind of "pull" when we
We pull out many of the events that we are waiting for, and then somehow react to them. In this approach, it is easy to absorb the overhead of one
an event and therefore achieve a high throughput of communication about the multitude of events that have occurred. Usually, all network elements like kernel interaction with a network card or interactions between you and the operating system are based on poll mechanisms.
The second way is a “push” type mechanism, when a certain external entity obviously comes, interrupts the execution flow and says: “Now, please process the event that has now arrived.” This is an approach with callbacks, with unix signals, with interruptions at the processor level, when an external entity intrudes into your execution flow and says: “Now, please, we are working on this event.” Such an approach appeared in order to reduce the delay between the occurrence of an event and the reaction to it.
Why do we, C ++ developers, who write and solve concrete applied problems, may want to drag an event model into our code? If we drag and drop the work on many tasks and their management into our code, then due to the lack of transition to the core and back, we can work a little faster and perform more useful actions per unit of time.
What does this lead to in terms of the code that we write? Take, for example, nginx - a high-performance HTTP server, very common. If you read his code, it is built on an asynchronous model. The code is quite difficult to read. When you ask yourself what exactly happens when processing a single HTTP request, it turns out that there are a lot of fragments in the code, separated by different files, in different corners of the code base. Each fragment does a small amount of work as part of serving the entire HTTP request. For example:
static void ngx_http_request_handler(ngx_event_t *ev) { … if (c->close) { ngx_http_terminate_request(r, 0); return; } if (ev->write) { r->write_event_handler(r); } else { r->read_event_handler(r); } ... } /* where the handler... */ typedef void (*ngx_http_event_handler_pt)(ngx_http_request_t *r); struct ngx_http_request_s { /*... */ ngx_http_event_handler_pt read_event_handler; /* ... */ }; /* ...is set when switching to the next processing stage */ r->read_event_handler = ngx_http_request_empty_handler; r->read_event_handler = ngx_http_block_reading; r->read_event_handler = ngx_http_test_reading; r->read_event_handler = ngx_http_discarded_request_body_handler; r->read_event_handler = ngx_http_read_client_request_body_handler; r->read_event_handler = ngx_http_upstream_rd_check_broken_connection; r->read_event_handler = ngx_http_upstream_read_request_handler; There is a request structure that is forwarded to the event handler when the socket signals readiness or write access. Further, this handler is constantly switched along with the program, depending on the state of the request processing. Either we read the headers, or we read the request body, or we ask upstream data - in general, many different states.
Such code is difficult to read, because, in its essence, it is described in terms of reaction to events. We are in such and such a state and react in a certain way to the events that have occurred. There is a lack of a complete picture of the entire process of processing an HTTP request.
Another option - which is commonly used in JavaScript - is to build code on the basis of callbacks, when we send our callback to the interface call, which usually has some nested callback on the occurrence of the event, and so on.
int LibuvStreamWrap::ReadStart() { return uv_read_start(stream(), [](uv_handle_t* handle, size_t suggested_size, uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(handle->data)->OnUvAlloc(suggested_size, buf); }, [](uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(stream->data)->OnUvRead(nread, buf); }); } /* ...for example, parsing http... */ for (p=data; p != data + len; p++) { ch = *p; reexecute: switch (CURRENT_STATE()) { case s_start_req_or_res: /*... */ case s_res_or_resp_H: /*... */ case s_res_HT: /*... */ case s_res_HTT: /* ... */ case s_res_HTTP: /* ... */ case s_res_http_major: /*... */ case s_res_http_dot: /*... */ /* ... */ The code is again very fragmented, there is no understanding of the current state of how we work on the request. A lot of information is transmitted through the closures, and you need to put mental effort into reconstructing the logic of processing a single request.
Thus, by introducing multitasking into our code (the logic of the choice of working tasks and their multiplexing), we get effective code and control over the prioritization of tasks, but very much lose readability. This code is difficult to read and difficult to maintain.

Why? Imagine I have a simple case, for example, I read a file and transfer it over the network. In a non-blocking version, this linear state machine will correspond to this case:
- Initial state
- Start reading file
- Waiting for a response from the file system,
- Write file to socket
- The final state.
Now, let's say I want to add information from the database to this file. Simple option:
- initial state
- I read the file
- read the file
- read from the database
- read from the database
- working with a socket
- written to the socket.
It seems like a linear code, but the number of states has increased.
Then you start to think that it would be nice to parallelize two steps - reading from a file and from a database. The wonders of combinatorics begin: you are in the initial state, requesting the reading of the file and the data from the database. Then you can either come to the state where there is data from the database, but there is no file, or vice versa - there is data from the file, but not from the database. Next you need to go into a state where you have one of the two. Again, these are two states. Then you need to go into a state where you have both ingredients. Then write them in the socket and so on.
The more complex the application, the more states, the more code fragments that need to be combined in your head. Inconvenient. Or you write noodles from kollbekov which is inconvenient to read. If a spreading system is written, then one day there comes a time when it can no longer be tolerated.
5. Futures / Promises
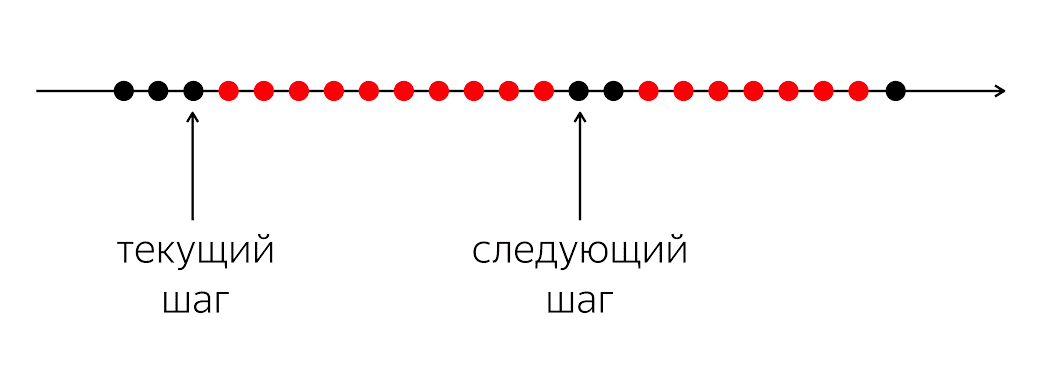
To solve a problem, you need to look at the situation easier.

There is a program, it has black and red circles. Our execution flow is black circles; sometimes they are interspersed with red when the stream cannot continue its work. The problem is that for our black flow you need to get into the next black circle, which will not be known when.
The problem is that when we write code in a programming language, we explain to the computer what to do right now. A computer is a conventionally simple thing that is awaiting instructions that we write in the programming language. She is waiting for instructions on the next circle, and in our programming language there are not enough means to say: "In the future, please, when some event comes, do something."

In the programming language, we operate with understandable, momentary actions: a function call, arithmetic operations, and so on. They describe the specific next next step. At the same time, in order to process the application logic, we need to describe not the next physical step, but the next logical step: what should we do when data from the database appears, for example.
Therefore, we need a mechanism to combine these fragments. In the case when we wrote the synchronous code, we hid the question completely under the hood and said that the operating system would do this, allowed it to interrupt and reschedule our execution threads.
In level 1, we opened this Pandora's box, and it introduced a lot of switch, case, conditions, branches, and states into the code. I want some kind of compromise, so that the code is relatively readable, but retains all the advantages of level 1.
Fortunately for us, in 1988, people involved in distributed systems, Barbara Liskov and Lyuba Shirira, realized the problem, and came to the need for linguistic changes. In the programming language, you need to add constructions that allow you to express temporal connections between events - at the current time and at an uncertain moment in the future.
This is called Promises. The concept is cool, but it has been gathering for twenty years on a shelf. — , Twitter, Ruby on Rails Scala, , , , future . Your Server as a Function. , .
Scala, , ++ ?
, Future. T c : , - .
template <class T> class Future <T> , , , . , «», , . Future «», Promise — «». ; , JavaScript, Promise — , Java – Future.
, . , , boost::future ( std::future) — , .
5.1. Future & Promise
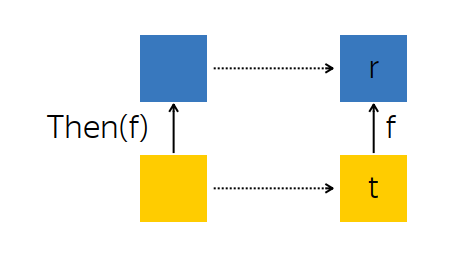
template <class T> class Future { bool IsSet() const; const T& Get() const; T* TryGet() const; void Subscribe(std::function<void(const T&)> cb); template <class R> Future<R> Then( std::function<R(const T&)> f); template <class R> Future<R> Then( std::function<Future<R>(const T&)> f); }; template <class T> Future<T> MakeFuture(const T& value); , , - , . , , , . , , — , , . Then, .
template <class T> class Promise { bool IsSet() const; void Set(const T& value); bool TrySet(const T& value); Future<T> ToFuture() const; }; template <class T> Promise<T> NewPromise(); . , . «, , , ».
5.2.
? , . Then — , .
, — future --, - t — . , , , f, - r.
t f. , , r.
: t, , r . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<R(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto r = f(t); promise.Set(r); }); return promise.ToFuture(); } :
PromiseR,Future<T>t,- ,
r = f(t), rPromise,Promise.
f , R , Future<R> , R . :
T,- ,
T, ,R, - ,
R, , .
template <class T> template <class R> Future<R> Future<T>::Then(std::function<Future<R>(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto that = f(t); that.Subscribe([promise] (R r) { promise.Set(r); }); }); return promise.ToFuture(); } , - t. f, r, . , , .

, Then :
Promise,Subscribe-,Promise,Future.
, . , , , .
, , , -. , , -, Subscribe. , , , - . , .
5.3. Examples
AsyncComputeValue, GPU, . Then, , (2v+1) 2 .
Future<int> value = AsyncComputeValue(); // value.Subscribe([] (int v) { std::cerr << "Value is: " << v << std::endl; }); . , : (2v+1) 2 . , .
// (2v+1)^2 Future<int> anotherValue = value .Then([] (int v) { return 2 * v; }) .Then([] (int u) { return u + 1; }) .Then([] (int w) { return w * w; }); , , . .
. : , ; ; .
Future<int> GetDbKey(); Future<string> LoadDbValue(int key); Future<void> SendToMars(string message); Future<void> ExploreOuterSpace() { return GetDbKey() // Future<int> .Then(&LoadDbValue) // Future<string> .Then(&SendToMars); // Future<void> } ExploreOuterSpace().Subscribe( [] () { std::cout << "Mission Complete!" << std::endl; }); — ExploreOuterSpace. Then; — — , . ( ) . .
5.4. Any-
: Future , , . , , :
template <class T> Future<T> Any(Future<T> f1, Future<T> f2) { auto promise = NewPromise<T>(); f1.Subscribe([promise] (const T& t) { promise.TrySet(t); }); f2.Subscribe([promise] (const T& t) { promise.TrySet(t); }); return promise.ToFuture(); } // , Any-, Future : , . , , .
, , , , , . « DB1, DB2, — - ».
5.5. All-
. , , , ( T1 T2), T1 T2 , , .
template <class T1, class T2> Future<std::tuple<T1, T2>> All(Future<T1> f1, Future<T2> f2) { auto promise = NewPromise<std::tuple<T1, T2>>(); auto result = std::make_shared< std::tuple<T1, T2> >(); auto counter = std::make_shared< std::atomic<int> >(2); f1.Subscribe([promise, result, counter] (const T1& t1) { std::get<0>(*result) = t1; if (--(*counter) == 0) { promise.Set(*result)); } }); f2.Subscribe([promise, result, counter] (const T2& t2) { /* */ } return promise.ToFuture(); } // nginx. , , . nginx « », « », « » . All- , . .
5.6.
Future Promises — legacy-, . callback- , , : Future, , callback- Future.
// cb void LegacyAsyncComputeStuff(std::function<void(int)> cb); // Future Future<int> ModernAsyncComputeStuff() { auto promise = NewPromise<int>(); LegacyAsyncComputeStuff( [promise] (int value) { promise.Set(value); }); return promise.ToFuture(); } : , Future .
6.
, , . .
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); // req 2 : QueryBackend Reply GetRequest().Subscribe( [] (Request req) { auto rsp = QueryBackend(req) .Then(&HandlePayload) .Then(Bind(&Reply, req)); }); . Request, - . , . , , , . , - .
, , . What to do? — , request payload, — , .
, Java Netty. , , . , , .
, GetRequest, QueryBackend, HandlePayload Reply , Future.
, , Future T — WaitFor.
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); // req 2 : QueryBackend Reply GetRequest().Subscribe( [] (Request req) { auto rsp = QueryBackend(req) .Then(&HandlePayload) .Then(Bind(&Reply, req)); }); :
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor(GetRequest()); auto pld = WaitFor(QueryBackend(req)); auto rsp = WaitFor(HandlePayload(pld)); WaitFor(Reply(req, rsp)); : Future, . . , . .
. . - 0, , , mutex+cvar future. . , .

6.1.
, . , , , , - , . , - .
— «» , , . . . : boost::asio boost::fiber.
, . How to do it?
6.2. WaitFor
, , boost::context, : , ; , . x86/64 , , .
// class MachineContext; // from, to void SwitchContext(MachineContext* from, MachineContext* to); // – boost::context // // * x86_64-ASM (push...-movq(rsp,eip)-pop...-jmpq) // * makecontext/swapcontext // * setjmp/longjmp , goto: , , , .
, - . Fiber — . +Future. , , Future, .
class Fiber { /* */ MachineContext context_; Future<void> future_; }; class Scheduler { /* */ void WaitFor(Future<void> future); void Loop(); MachineContext loop_context_; Fiber* current_fiber_; std::deque<Fiber*> run_queue_; }; Future , , , . : Loop, , , , , .
WaitFor?
thread_local Scheduler* ThisScheduler; template <class T> T WaitFor(Future<T> future) { ThisScheduler->WaitFor(future.As<void>()); return future.Get(); } void Scheduler::WaitFor(Future<void> future) { current_fiber_->future_ = future; SwitchContext(¤t_fiber_->context_, &loop_context_); } : , - , , Future void, . .
Future<void> , , - .
WaitFor : : « Fiber Future», ( ) .
, :ThisScheduler->WaitFor return future.Get() , .
? , Future, .
6.3.
- , , , - , . SwitchContext , 2 — .
void Scheduler::Loop() { while (true) { // (1) (= !) current_fiber_ = run_queue_.front(); run_queue_.pop_front(); SwitchContext(&loop_context_, ¤t_fiber_->context_); // (2) , //… ? , , , Future, Future, , , .
void Scheduler::Loop() { while (true) { // (1) … // (2) , if (current_fiber_->future_) { current_fiber_->future_.Subscribe( [this, fiber = current_fiber_] { fiber->future_ = nullptr; run_queue_.push_back(fiber); }); } //… , . :
WaitFor — .

Switch- .

Future ( ), , . - Fiber.

WaitFor Future , - , Future . :
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor( GetRequest()); auto pld = WaitFor( QueryBackend(req)); auto rsp = WaitFor( HandlePayload(pld)); WaitFor( Reply(req, rsp)); , , , . , , .
6.4. Coroutine TS
? — . Coroutine TS, , WaitFor CoroutineWait, CoroutineTS — - . , - . , Waiter Co, , .
7. ?
. , , , . , , , .
— . , . . , . , , , , .
- , , . , . , , .

, ? , .
. , , , , . . , , , , .
nginx, , , , , . , , , future promises.
, , , , , , , .
futures, promises actors. . , .
: , , , . , , , , . ? , .
Minute advertising. 19-20 C++ Russia 2019. , , Grimm Rainer «Concurrency and parallelism in C++17 and C++20/23» , C++ . , . , , - .
')
Source: https://habr.com/ru/post/446562/
All Articles