The truth is about the parsing of sites, or "all online stores do it"
In this article I will try to most simply tell about parsing sites and its main nuances. My company has been engaged in parsing websites for more than three years and we parse about 300 sites every day. I usually openly write about it in social networks (plus we put a lot of things from the results of parsing the largest stores in Russia for free - publicly), which causes heated discussions and disapproval of users. It's funny after reading the comments to look in my personal and read messages with offers of cooperation from the same people who have just condemned us in the comments under the post :) The whole article will be in the format of the most frequently asked questions and honest answers (marketing material, not technical ).
By definition, parsing is an automated collection of unstructured information, its conversion and output in a structured form. Pretty harmless, isn't it? However, the society treats it in a rather peculiar way, like teenage masturbation - many were engaged in this :), but no one speaks about it publicly. Moreover, parsing is often condemned and considered something slightly shameful. The reason as in most similar cases, in the wrong perception.
I will tell you a secret: everyone is engaged in parsing ... At least all the major players in the market. A couple of years ago, in one of the articles in Vedomosti, representatives of “M-video”, “Svyaznoy” and “Citylink” even openly talked about this in response to FAS interest (see here ).
First of all, the purpose of parsing is price “intelligence”, assortment analysis, tracking of commodity stocks. “Who, what, for how much and in what quantities does it sell?” Are the main questions that parsing has to answer. In more detail, the parsing of the range of competitors or the same Yandex.Market answers the first three questions.
')
With the turnover of goods is somewhat more complicated. However, companies such as Wildberries, Lamoda and Leroy Merlin openly provide information on daily sales volumes (orders) or stock balances, on the basis of which it is not difficult to form a general idea of sales (I often hear the opinion that this data may be distorted intentionally - perhaps and perhaps not). We look at how many goods were in stock today, tomorrow, the day after tomorrow, and so on for a month, and now the schedule and the dynamics of changes in the quantity of the position are made up (the turnover of the goods is actually). The higher the dynamics, the greater the turnover.
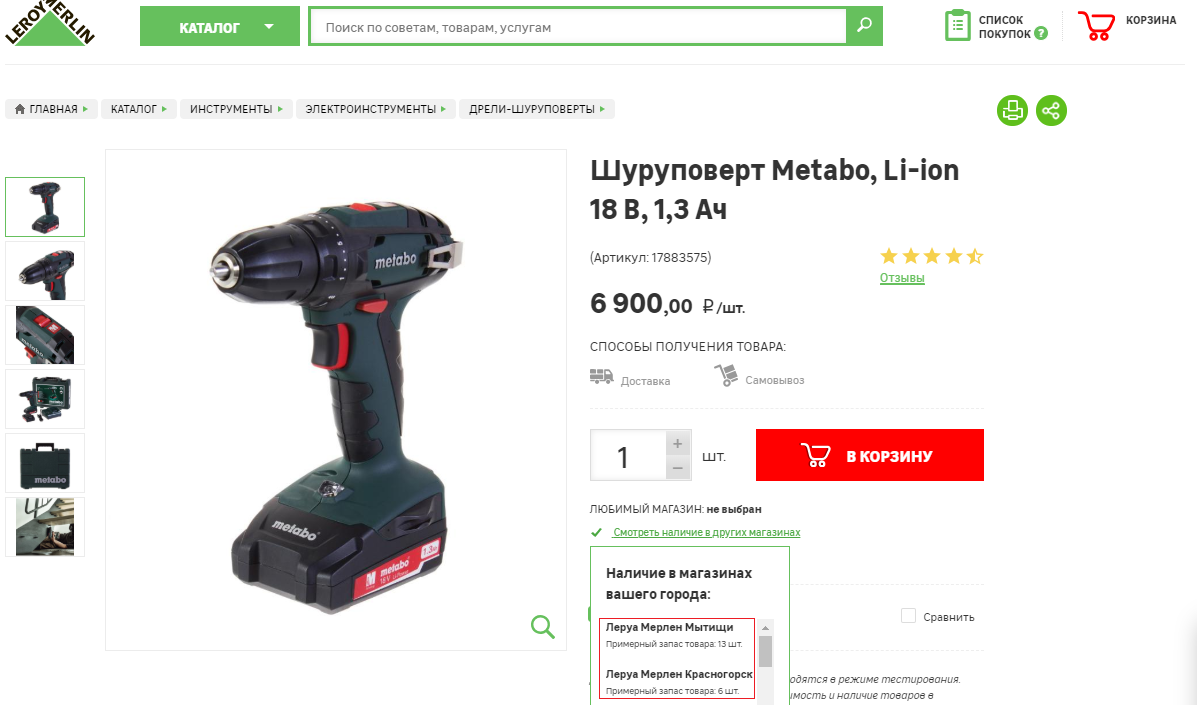
Potentially possible way to find out the turnover of goods with the help of daily analysis of the remains of the Leroy Merlin website.
You can, of course, refer to the movement of goods between points. But in total, if you take, for example, Moscow, the number will not change much, and it is difficult to believe in significant movement of goods across the regions.
The situation with sales is similar. There are, of course, companies that publish information in the form of many / few, but even with this you can work, and the best-selling positions are easily tracked. Especially if you cut off cheap positions and focus exclusively on those that are of the greatest value. At least, we did such an analysis - it turned out interesting.
Secondly, parsing is used to get content. There may already be stories in the style of “legal shades of gray.” Many people are obsessed with the fact that parsing is theft of content, although this is absolutely not the case. Parsing is just an automated collection of information, nothing more. For example, parsing photos, especially with “watermarks”, is pure content stealing and copyright infringement. Therefore, they are usually not engaged in this (we limit ourselves in our work to collecting links to images, nothing more ... well, sometimes they are asked to count the number of photos, track the availability of video for a product and give a link, etc.).
Regarding the collection of content, interesting situation with the descriptions of goods. Recently, we received an order to collect data on 50 sites of large online pharmacies. In addition to the information on the assortment and price, we were asked to “pair” the description of the medicinal devices — the very thing that is included in each pack and is so-called actual information, i.e. unlikely to fall under copyright law. As a result, instead of a set of instructions manually, customers will only have to make small adjustments to the instruction templates, and that’s all — the content for the site is ready. But yes, there may be copyright descriptions of drugs that are notarized and made specifically as a kind of trap for content thieves :).
Consider also the collection of descriptions of books, for example, with OZON.RU or Labyrinth.ru. Here the situation is not so straightforward from a legal point of view. On the one hand, the use of such a description may violate copyright, especially if the description of each card with the goods was notarized (which I strongly doubt - after all, it may not be certified, the exception is small resources that they want to get by the courts of content thieves). In any case, in this situation, you will have to “sweat a lot” to prove the uniqueness of this description. Some customers go even further - they connect synonymizers, which “on the fly” change (good or bad) the words in the description, keeping the general meaning.
Another use of parsing is quite original - “self parsing”. There are several goals here. To begin with, this is tracking what happens to the site content: where there are broken links, where descriptions are missing, duplication of products, lack of illustrations, etc. Half an hour of the parser work - and here you have a finished table with all categories and data. Conveniently! “Self-parsing” can also be used to compare the balances on the site with its warehouse balances (there are also such customers that monitor failures of uploads to the site). Another use of “self parsing” that we encountered in our work is the structuring of data from the site for uploading them to Yandex Market. It was easier for the guys to do it than to do it manually.
Also ads are parted, for example, on CIAN-e, Avito, etc. The goals here can be both resale of bases to realtors or tour operators, as well as outright telephone spam, retargeting, etc. In the case of Avito, this is especially obvious, since a table is immediately drawn up with the users 'phones (despite the fact that Avito replaces the users' phones for protection and publishes them as an image, it is still impossible to get away from incoming calls).
Recently, requests for parsing Headhunter have become relevant. True, first people ask to sell them a “Headhunter base”. But, when they already understand that we have no base and cannot be, we turn to talking about parsing in their profile (“under the password”). This is a peculiar direction of parsing and, to be honest, we are not particularly interested in it, but it’s worth telling about it.
What is the subtlety? The client provides access to his account and sets the task of collecting data for his needs. Those. He has already paid for access to the HH database and, signing a contract with us, sets us the task of automatically collecting information in his interest and under his account, which is completely under his responsibility. If HH detects an abnormal activity, the account will be blocked. Therefore, we try to simulate human activity as best we can while collecting data.
If HH (as far as I know, “successfully” who failed his experiments with the API) would provide (sell) the data in the table for the regions, say, the contacts of all currently working marketing directors in Moscow, no one would come to us. In the meantime, the person has to do it with “hands”, they come to us. After all, when you have such a table, it is much more convenient to engage in advertising spam - cold calls.
Let me emphasize again, we do not have a HH database, we simply collect data for each client for his needs, his account and his responsibility. And a breach of an offer is not related to the use of the site by the paring party. When signing a contract with us, the client receives, for the run, contacts of the order of 450 decision makers, which we put on his server, and then his sales department will decide what to do with it. Eh, we would also “spam” if we had such a base. Just kidding :)
Although, personally, I believe that there are no prospects for parsing under a password. But parsing open resources is another matter. You once set everything up and parse all the time, then resell access to all collected data. This is more promising.
In the Russian legislation there is no article prohibiting parsing. Prohibited hacking, DDOS, theft of copyright content, and parsing is neither one nor the other, not the third and, accordingly, it is not prohibited.
Some people perceive parsing as a DDOS attack and treat it with doubt. However, these are completely different things, and when parsing, we, on the contrary, try to load the target site as little as possible and not harm the business. As in the case of a healthy parasitism - we do not want the business to “drop the hoof”, otherwise we will have nothing to “parasitize”.
Usually they ask to parse large sites, from the top 300-500 sites of Russia. At such sites, attendance is usually several million per month, maybe even more. And on this background, parsing one product per second or two is almost imperceptible (there is no point parsing more often, 1-2 seconds per product is the optimal speed for large sites). Accordingly, there is no hint of a DDOS attack in our actions. Very rarely, people ask us to update, for example, the entire site BERU.RU per day - this is, frankly, bust and too much load on the site ... usually takes 3-4 days.
Let me remind you that parsing is just a collection of what we can see on our website and copy to ourselves with our hands. Thus, only actions with already collected information can be included under the copyright article, i.e. actions of the customer. It is just that a person does this for a long time slowly and with errors, and the parser does not make mistakes quickly. What to do when it comes to collecting data from AliExpress or Wildberies? Such a task is simply not possible for a person, and parsing is the only way out.
True, they recently asked to parse the site of a state organization - the court, if I am not mistaken. All information is publicly available there, but we (just in case) refused. :)
Price monitoring is one of the most popular areas of parsing. But with him, not everything is so simple - in this case it will be necessary to work not only for us, but also for the client himself.
When ordering price monitoring, we immediately warn that we will parse not only competitors, but also the customer. This is necessary to obtain similar tables with products and prices, which we will be able to update automatically. However, by themselves, such data does not carry value, as long as they are not related to each other (the so-called matching of goods). We can automatically compare some positions from different sites, but, unfortunately, at the moment “machines” are not yet so good as to make it guaranteed without errors, and no one is better than a person (for example, an employee working remotely for part-time employees from regions) will do.
If everyone were displaying the barcode on the site, then in general it would be great, and we could do all the “bundles” automatically. But, unfortunately, this is not the case, and even different companies write different product names.
It is good that such work should be carried out once, and then periodically rechecked and make minor adjustments, if required. In the presence of bundles, we can already update these tables automatically. In addition, usually people do not need to monitor prices for everything: there are conventionally 3-5 thousand positions that are in the top, and the trifle is not of interest. And the operator from the region can easily perform such work for the money of about 10,000 rubles per month.
The most successful and correct case in this case, in my opinion, is to load the received price list of competitors directly into your 1C-ku (or another ERP system) and there already perform a comparison. Thus, price monitoring is easiest to incorporate into the daily activities of its analysts. And without analysis, no one needs such parsing.
Yes, nothing. And is it worth defending against parsing? I would not. There is still no working 100% protection (or rather, we have not yet met), so I don’t see much point in trying to protect myself. The best protection against parsing is to simply lay out a ready-made table on the site and write - take it from here, update it every couple of days. If people do this, then we will have no bread.
By the way, recently called up with the IT director of a large network - they wanted to test their protection against parsing. I asked him directly why they do not do that. As a technical specialist, he is well aware that no protection from parsing will save, only scare away amateurs; but companies that make money by parsing can easily afford research in this area - long and painfully to understand the new defense, and as a result, it can be bypassed ...
As a rule, all use the same type of protection, and such a study is useful again and again. So, it turned out that the marketing department is not ready for this: “Why do we simplify life for competitors?” It would seem logical, but ... As a result, the company will spend money on protection that does not help, and the parasitic load on the site will remain. Although, in fairness, it is worth noting that everything that “moves” from the “students” studying python and parsing can help.
By the way, both Yandex and Google are engaged in parsing: they enter the site and index it - they collect information. Only everyone wants Yandex and Google to index their sites for obvious reasons, and no one wants them to be parsed :)
Once we were approached with an interesting order for test parsing. The company deals with airline tickets and they were interested in the prices of competitors for a couple of the most popular destinations. The task turned out to be non-trivial, since had to tinker with the substitution and comparison of flights. What turned out to be interesting was that the prices of “Onetwotrip”, “Aviasales” and “Skyscanner” for the same flights are slightly different (the spread is about 5-7%).
The project seemed to me very interesting, and I posted a post about it in social networks. To my surprise, the discussion under the post turned out to be quite aggressive, and I did not immediately understand why. Then the CEO of one of the companies, the leader of the ticket market in Russia, wrote to me, and the situation cleared up. It turned out that requests for ticket prices for such companies are paid because they take information from international paid services. And, in addition to the parasitic load, the parsing is also financial for them.
In any case, no one is demanding payment from you if you are personally looking for tickets to these services, and ordinary people also make inquiries a lot while sifting through various options ... In general, there is such a business dilemma :)
I think, for a greater understanding of all aspects of parsing, it is worth opening the curtain of our “internal kitchen”.
It all starts with the order. Sometimes customers contact us themselves, and sometimes we call. Especially successful with orders for monitoring prices. In this case, we have to parse not only competitors, but also the customer. Therefore, we sometimes call those who are somehow parsim, and openly talk about it, offering our services - the work is already being done by us. At first, the reaction is very negative, but a couple of days pass, the emotions subside, and the customers call back themselves, saying: “Damn it! Whom are you still parsing? ”
Parsing with VERY many owners of visited resources causes emotions. First, the negative, because it is similar to peeping through the keyhole. Then it grows into an interest, and then into an awareness of the need. Businessmen are smart people. When emotions come to naught and there remains a cold calculation, the question always arises: “And, maybe, we have failed somewhere, and we also need it?”
Thanks to these emotions, we are quite actively growing and developing. At the moment we parse about 300 sites per day. Usually 8-15 sites are ordered from us, and the parsing of one costs from 5 to 9 thousand rubles a month, depending on the complexity of the connection, because each site has to be connected individually (it takes about 4-5 hours for a resource). The difficulty is that some are protected. The fight goes not so much with the parsing, as with some kind of parasitic load, which does not bring them profit, but sometimes you have to tinker.
In any case, everything is parasitized, even if the price of the goods is published on the site as a picture :). Those who want to try their hand at parsing, I recommend to work out on the site "Pharmacy Stolichki" and match the prices .
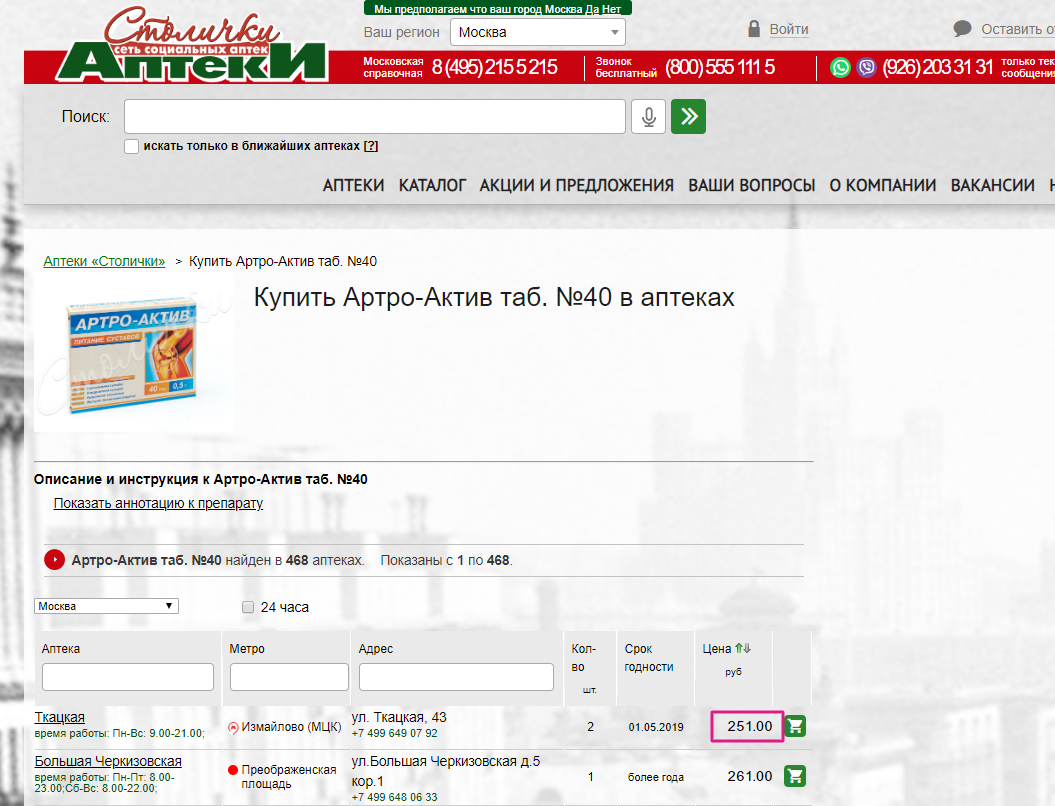
The online store of the Stolichki pharmacy chain - prices are written in internal font and in order to get them ready, one of the solutions will be the formation of a picture and its recognition. We do this at least.
The collected data is transmitted to the client. Usually we place them on our own cloud, constantly updating, and provide the client with access to them by API. If something suddenly becomes wrong with the data (which is rarely done once every 3-4 months), they immediately call and write us, and we try to fix the problem as soon as possible. Such failures occur when installing a new protection or blocking, and are solved with the help of research and proxies, respectively. In another case, when something changes on the site, the bot simply ceases to understand where something is, and our programmer has to re-configure it. But everything is solved, and customers usually refer to such problems with understanding.
I note that in our case the identity of the customer has never been disclosed - we take it very carefully, and no one has repealed the items in the non-disclosure agreement. Although in parsing there is nothing reprehensible, but many are shy.
As a matter of fact, to sum up, if you are a growing business, trading in widely distributed goods or working in a rapidly changing environment (such as hiring staff or offering specific services for a certain category of advertisers, resumes and content of other “message boards” on the Internet), then or later come across parsing (as a customer or as a target).
PS: if you like the article, we will write about the technical side of the case - how we bypass the protection, what powers we use, what is written on (spoiler .net), etc.
Maxim Kulgin, xmldatafeed.com
1. What is parsing?
By definition, parsing is an automated collection of unstructured information, its conversion and output in a structured form. Pretty harmless, isn't it? However, the society treats it in a rather peculiar way, like teenage masturbation - many were engaged in this :), but no one speaks about it publicly. Moreover, parsing is often condemned and considered something slightly shameful. The reason as in most similar cases, in the wrong perception.
I will tell you a secret: everyone is engaged in parsing ... At least all the major players in the market. A couple of years ago, in one of the articles in Vedomosti, representatives of “M-video”, “Svyaznoy” and “Citylink” even openly talked about this in response to FAS interest (see here ).
2. What is parsing for?
First of all, the purpose of parsing is price “intelligence”, assortment analysis, tracking of commodity stocks. “Who, what, for how much and in what quantities does it sell?” Are the main questions that parsing has to answer. In more detail, the parsing of the range of competitors or the same Yandex.Market answers the first three questions.
')
With the turnover of goods is somewhat more complicated. However, companies such as Wildberries, Lamoda and Leroy Merlin openly provide information on daily sales volumes (orders) or stock balances, on the basis of which it is not difficult to form a general idea of sales (I often hear the opinion that this data may be distorted intentionally - perhaps and perhaps not). We look at how many goods were in stock today, tomorrow, the day after tomorrow, and so on for a month, and now the schedule and the dynamics of changes in the quantity of the position are made up (the turnover of the goods is actually). The higher the dynamics, the greater the turnover.
Potentially possible way to find out the turnover of goods with the help of daily analysis of the remains of the Leroy Merlin website.
You can, of course, refer to the movement of goods between points. But in total, if you take, for example, Moscow, the number will not change much, and it is difficult to believe in significant movement of goods across the regions.
The situation with sales is similar. There are, of course, companies that publish information in the form of many / few, but even with this you can work, and the best-selling positions are easily tracked. Especially if you cut off cheap positions and focus exclusively on those that are of the greatest value. At least, we did such an analysis - it turned out interesting.
Secondly, parsing is used to get content. There may already be stories in the style of “legal shades of gray.” Many people are obsessed with the fact that parsing is theft of content, although this is absolutely not the case. Parsing is just an automated collection of information, nothing more. For example, parsing photos, especially with “watermarks”, is pure content stealing and copyright infringement. Therefore, they are usually not engaged in this (we limit ourselves in our work to collecting links to images, nothing more ... well, sometimes they are asked to count the number of photos, track the availability of video for a product and give a link, etc.).
Regarding the collection of content, interesting situation with the descriptions of goods. Recently, we received an order to collect data on 50 sites of large online pharmacies. In addition to the information on the assortment and price, we were asked to “pair” the description of the medicinal devices — the very thing that is included in each pack and is so-called actual information, i.e. unlikely to fall under copyright law. As a result, instead of a set of instructions manually, customers will only have to make small adjustments to the instruction templates, and that’s all — the content for the site is ready. But yes, there may be copyright descriptions of drugs that are notarized and made specifically as a kind of trap for content thieves :).
Consider also the collection of descriptions of books, for example, with OZON.RU or Labyrinth.ru. Here the situation is not so straightforward from a legal point of view. On the one hand, the use of such a description may violate copyright, especially if the description of each card with the goods was notarized (which I strongly doubt - after all, it may not be certified, the exception is small resources that they want to get by the courts of content thieves). In any case, in this situation, you will have to “sweat a lot” to prove the uniqueness of this description. Some customers go even further - they connect synonymizers, which “on the fly” change (good or bad) the words in the description, keeping the general meaning.
Another use of parsing is quite original - “self parsing”. There are several goals here. To begin with, this is tracking what happens to the site content: where there are broken links, where descriptions are missing, duplication of products, lack of illustrations, etc. Half an hour of the parser work - and here you have a finished table with all categories and data. Conveniently! “Self-parsing” can also be used to compare the balances on the site with its warehouse balances (there are also such customers that monitor failures of uploads to the site). Another use of “self parsing” that we encountered in our work is the structuring of data from the site for uploading them to Yandex Market. It was easier for the guys to do it than to do it manually.
Also ads are parted, for example, on CIAN-e, Avito, etc. The goals here can be both resale of bases to realtors or tour operators, as well as outright telephone spam, retargeting, etc. In the case of Avito, this is especially obvious, since a table is immediately drawn up with the users 'phones (despite the fact that Avito replaces the users' phones for protection and publishes them as an image, it is still impossible to get away from incoming calls).
3. “What is your CV in?” Or parsing HH.RU
Recently, requests for parsing Headhunter have become relevant. True, first people ask to sell them a “Headhunter base”. But, when they already understand that we have no base and cannot be, we turn to talking about parsing in their profile (“under the password”). This is a peculiar direction of parsing and, to be honest, we are not particularly interested in it, but it’s worth telling about it.
What is the subtlety? The client provides access to his account and sets the task of collecting data for his needs. Those. He has already paid for access to the HH database and, signing a contract with us, sets us the task of automatically collecting information in his interest and under his account, which is completely under his responsibility. If HH detects an abnormal activity, the account will be blocked. Therefore, we try to simulate human activity as best we can while collecting data.
If HH (as far as I know, “successfully” who failed his experiments with the API) would provide (sell) the data in the table for the regions, say, the contacts of all currently working marketing directors in Moscow, no one would come to us. In the meantime, the person has to do it with “hands”, they come to us. After all, when you have such a table, it is much more convenient to engage in advertising spam - cold calls.
Let me emphasize again, we do not have a HH database, we simply collect data for each client for his needs, his account and his responsibility. And a breach of an offer is not related to the use of the site by the paring party. When signing a contract with us, the client receives, for the run, contacts of the order of 450 decision makers, which we put on his server, and then his sales department will decide what to do with it. Eh, we would also “spam” if we had such a base. Just kidding :)
Although, personally, I believe that there are no prospects for parsing under a password. But parsing open resources is another matter. You once set everything up and parse all the time, then resell access to all collected data. This is more promising.
4. Is parsing generally legal?
In the Russian legislation there is no article prohibiting parsing. Prohibited hacking, DDOS, theft of copyright content, and parsing is neither one nor the other, not the third and, accordingly, it is not prohibited.
Some people perceive parsing as a DDOS attack and treat it with doubt. However, these are completely different things, and when parsing, we, on the contrary, try to load the target site as little as possible and not harm the business. As in the case of a healthy parasitism - we do not want the business to “drop the hoof”, otherwise we will have nothing to “parasitize”.
Usually they ask to parse large sites, from the top 300-500 sites of Russia. At such sites, attendance is usually several million per month, maybe even more. And on this background, parsing one product per second or two is almost imperceptible (there is no point parsing more often, 1-2 seconds per product is the optimal speed for large sites). Accordingly, there is no hint of a DDOS attack in our actions. Very rarely, people ask us to update, for example, the entire site BERU.RU per day - this is, frankly, bust and too much load on the site ... usually takes 3-4 days.
Let me remind you that parsing is just a collection of what we can see on our website and copy to ourselves with our hands. Thus, only actions with already collected information can be included under the copyright article, i.e. actions of the customer. It is just that a person does this for a long time slowly and with errors, and the parser does not make mistakes quickly. What to do when it comes to collecting data from AliExpress or Wildberies? Such a task is simply not possible for a person, and parsing is the only way out.
True, they recently asked to parse the site of a state organization - the court, if I am not mistaken. All information is publicly available there, but we (just in case) refused. :)
5. “Why are you parsing us, we are the customer” or what is the difference between parsing and price monitoring?
Price monitoring is one of the most popular areas of parsing. But with him, not everything is so simple - in this case it will be necessary to work not only for us, but also for the client himself.
When ordering price monitoring, we immediately warn that we will parse not only competitors, but also the customer. This is necessary to obtain similar tables with products and prices, which we will be able to update automatically. However, by themselves, such data does not carry value, as long as they are not related to each other (the so-called matching of goods). We can automatically compare some positions from different sites, but, unfortunately, at the moment “machines” are not yet so good as to make it guaranteed without errors, and no one is better than a person (for example, an employee working remotely for part-time employees from regions) will do.
If everyone were displaying the barcode on the site, then in general it would be great, and we could do all the “bundles” automatically. But, unfortunately, this is not the case, and even different companies write different product names.
It is good that such work should be carried out once, and then periodically rechecked and make minor adjustments, if required. In the presence of bundles, we can already update these tables automatically. In addition, usually people do not need to monitor prices for everything: there are conventionally 3-5 thousand positions that are in the top, and the trifle is not of interest. And the operator from the region can easily perform such work for the money of about 10,000 rubles per month.
The most successful and correct case in this case, in my opinion, is to load the received price list of competitors directly into your 1C-ku (or another ERP system) and there already perform a comparison. Thus, price monitoring is easiest to incorporate into the daily activities of its analysts. And without analysis, no one needs such parsing.
6. How to protect against parsing?
Yes, nothing. And is it worth defending against parsing? I would not. There is still no working 100% protection (or rather, we have not yet met), so I don’t see much point in trying to protect myself. The best protection against parsing is to simply lay out a ready-made table on the site and write - take it from here, update it every couple of days. If people do this, then we will have no bread.
By the way, recently called up with the IT director of a large network - they wanted to test their protection against parsing. I asked him directly why they do not do that. As a technical specialist, he is well aware that no protection from parsing will save, only scare away amateurs; but companies that make money by parsing can easily afford research in this area - long and painfully to understand the new defense, and as a result, it can be bypassed ...
As a rule, all use the same type of protection, and such a study is useful again and again. So, it turned out that the marketing department is not ready for this: “Why do we simplify life for competitors?” It would seem logical, but ... As a result, the company will spend money on protection that does not help, and the parasitic load on the site will remain. Although, in fairness, it is worth noting that everything that “moves” from the “students” studying python and parsing can help.
By the way, both Yandex and Google are engaged in parsing: they enter the site and index it - they collect information. Only everyone wants Yandex and Google to index their sites for obvious reasons, and no one wants them to be parsed :)
7. “I searched here for free ...” or the story about air tickets
Once we were approached with an interesting order for test parsing. The company deals with airline tickets and they were interested in the prices of competitors for a couple of the most popular destinations. The task turned out to be non-trivial, since had to tinker with the substitution and comparison of flights. What turned out to be interesting was that the prices of “Onetwotrip”, “Aviasales” and “Skyscanner” for the same flights are slightly different (the spread is about 5-7%).
The project seemed to me very interesting, and I posted a post about it in social networks. To my surprise, the discussion under the post turned out to be quite aggressive, and I did not immediately understand why. Then the CEO of one of the companies, the leader of the ticket market in Russia, wrote to me, and the situation cleared up. It turned out that requests for ticket prices for such companies are paid because they take information from international paid services. And, in addition to the parasitic load, the parsing is also financial for them.
In any case, no one is demanding payment from you if you are personally looking for tickets to these services, and ordinary people also make inquiries a lot while sifting through various options ... In general, there is such a business dilemma :)
8. “Chef Parser Recipes”. or how do we work?
I think, for a greater understanding of all aspects of parsing, it is worth opening the curtain of our “internal kitchen”.
It all starts with the order. Sometimes customers contact us themselves, and sometimes we call. Especially successful with orders for monitoring prices. In this case, we have to parse not only competitors, but also the customer. Therefore, we sometimes call those who are somehow parsim, and openly talk about it, offering our services - the work is already being done by us. At first, the reaction is very negative, but a couple of days pass, the emotions subside, and the customers call back themselves, saying: “Damn it! Whom are you still parsing? ”
Parsing with VERY many owners of visited resources causes emotions. First, the negative, because it is similar to peeping through the keyhole. Then it grows into an interest, and then into an awareness of the need. Businessmen are smart people. When emotions come to naught and there remains a cold calculation, the question always arises: “And, maybe, we have failed somewhere, and we also need it?”
Thanks to these emotions, we are quite actively growing and developing. At the moment we parse about 300 sites per day. Usually 8-15 sites are ordered from us, and the parsing of one costs from 5 to 9 thousand rubles a month, depending on the complexity of the connection, because each site has to be connected individually (it takes about 4-5 hours for a resource). The difficulty is that some are protected. The fight goes not so much with the parsing, as with some kind of parasitic load, which does not bring them profit, but sometimes you have to tinker.
In any case, everything is parasitized, even if the price of the goods is published on the site as a picture :). Those who want to try their hand at parsing, I recommend to work out on the site "Pharmacy Stolichki" and match the prices .
The online store of the Stolichki pharmacy chain - prices are written in internal font and in order to get them ready, one of the solutions will be the formation of a picture and its recognition. We do this at least.
The collected data is transmitted to the client. Usually we place them on our own cloud, constantly updating, and provide the client with access to them by API. If something suddenly becomes wrong with the data (which is rarely done once every 3-4 months), they immediately call and write us, and we try to fix the problem as soon as possible. Such failures occur when installing a new protection or blocking, and are solved with the help of research and proxies, respectively. In another case, when something changes on the site, the bot simply ceases to understand where something is, and our programmer has to re-configure it. But everything is solved, and customers usually refer to such problems with understanding.
I note that in our case the identity of the customer has never been disclosed - we take it very carefully, and no one has repealed the items in the non-disclosure agreement. Although in parsing there is nothing reprehensible, but many are shy.
As a matter of fact, to sum up, if you are a growing business, trading in widely distributed goods or working in a rapidly changing environment (such as hiring staff or offering specific services for a certain category of advertisers, resumes and content of other “message boards” on the Internet), then or later come across parsing (as a customer or as a target).
PS: if you like the article, we will write about the technical side of the case - how we bypass the protection, what powers we use, what is written on (spoiler .net), etc.
Maxim Kulgin, xmldatafeed.com
Source: https://habr.com/ru/post/446488/
All Articles