Happy Party or a couple of memory lines about your introduction to PostgreSQL10 partitioning
Preface or how the partitioning idea came about
The beginning of the story is here: Do you remember how it all began. It was the first time and again. After almost all the resources to optimize the query, at that time, were exhausted, the question arose - what next? So the idea of partitioning arose.

Lyrical digression:
')
It was "at that time", because as it turned out, there were unused reserves of optimization . Thanks asmm and Habra!
So, how else can you make the customer seem to be happy, at the same time and pump your own skills?
If to simplify everything to the utmost , then, there are drastic ways to improve something in the speed of the database, only two:
- Extensive way - we increase resources, change the configuration;
- The intensive way is query optimization.
Since, I repeat, at that time it was not clear what else to change in the query for acceleration, the path was chosen - changes to the design of the tables.
So - the main question arises - what and how will we change?
Initial conditions
First, there is such an ERD (shown conditionally simplified):
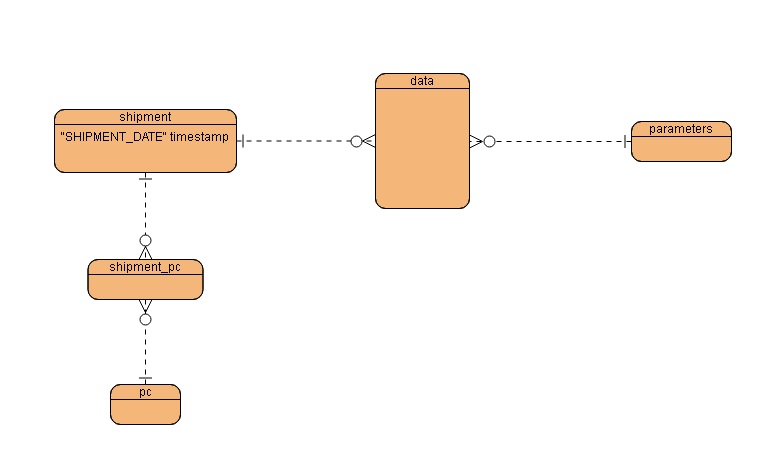
Key Features:
- many-to-many relationship
- the table already has a potential partitioning key
Original request:
SELECT p."PARAMETER_ID" as parameter_id, pc."PC_NAME" AS pc_name, pc."CUSTOMER_PARTNUMBER" AS customer_partnumber, w."LASERMARK" AS lasermark, w."LOTID" AS lotid, w."REPORTED_VALUE" AS reported_value, w."LOWER_SPEC_LIMIT" AS lower_spec_limit, w."UPPER_SPEC_LIMIT" AS upper_spec_limit, p."TYPE_CALCUL" AS type_calcul, s."SHIPMENT_NAME" AS shipment_name, s."SHIPMENT_DATE" AS shipment_date, extract(year from s."SHIPMENT_DATE") AS year, extract(month from s."SHIPMENT_DATE") as month, s."REPORT_NAME" AS report_name, p."SPARAM_NAME" AS SPARAM_name, p."CUSTOMERPARAM_NAME" AS customerparam_name FROM data w INNER JOIN shipment s ON s."SHIPMENT_ID" = w."SHIPMENT_ID" INNER JOIN parameters p ON p."PARAMETER_ID" = w."PARAMETER_ID" INNER JOIN shipment_pc sp ON s."SHIPMENT_ID" = sp."SHIPMENT_ID" INNER JOIN pc pc ON pc."PC_ID" = sp."PC_ID" INNER JOIN ( SELECT w2."LASERMARK" , MAX(s2."SHIPMENT_DATE") AS "SHIPMENT_DATE" FROM shipment s2 INNER JOIN data w2 ON s2."SHIPMENT_ID" = w2."SHIPMENT_ID" GROUP BY w2."LASERMARK" ) md ON md."SHIPMENT_DATE" = s."SHIPMENT_DATE" AND md."LASERMARK" = w."LASERMARK" WHERE s."SHIPMENT_DATE" >= '2018-07-01' AND s."SHIPMENT_DATE" <= '2018-09-30' ; Execution results on the test database:
Cost : 502 997.55
Execution time : 505 seconds.
What do we see? Normal request, by time slice.
We make the simplest logical assumption: if there is a sample of the time slice, will it help us? Correct - sectioning.
What to partition?
At first glance, the choice is obvious - the declarative sectioning of the “shipment” table with the key “SHIPMENT_DATE” ( running a lot ahead - in the end, the production turned out a bit wrong ).
How to partition?
This question is also not too complicated. Fortunately, in PostgreSQL 10, now the human partitioning mechanism.
So:
- Save dump of source table - pg_dump source_table
- Remove source table - drop table source_table
- Create parent table with range partitioning - create table source_table
- Create sections - create table source_table, create index
- Import the dump created in step 1 - pg_restore
Sectioning scripts
For simplicity and convenience, steps 2,3,4 were combined in one script.
So:
Save the source table dump
pg_dump postgres --file=/dump/shipment.dmp --format=c --table=shipment --verbose > /dump/shipment.log 2>&1 Delete the source table + Create a parent table with range partitioning + Create sections
--create_partition_shipment.sql do language plpgsql $$ declare rec_shipment_date RECORD ; partition_name varchar; index_name varchar; current_year varchar ; current_month varchar ; begin_year varchar ; begin_month varchar ; next_year varchar ; next_month varchar ; first_flag boolean ; i integer ; begin RAISE NOTICE 'CREATE TEMPORARY TABLE FOR SHIPMENT_DATE'; CREATE TEMP TABLE tmp_shipment_date as select distinct "SHIPMENT_DATE" from shipment order by "SHIPMENT_DATE" ; RAISE NOTICE 'DROP TABLE shipment'; drop table shipment cascade ; CREATE TABLE public.shipment ( "SHIPMENT_ID" integer NOT NULL DEFAULT nextval('shipment_shipment_id_seq'::regclass), "SHIPMENT_NAME" character varying(30) COLLATE pg_catalog."default", "SHIPMENT_DATE" timestamp without time zone, "REPORT_NAME" character varying(40) COLLATE pg_catalog."default" ) PARTITION BY RANGE ("SHIPMENT_DATE") WITH ( OIDS = FALSE ) TABLESPACE pg_default; RAISE NOTICE 'CREATE PARTITIONS FOR TABLE shipment'; current_year:='0'; current_month:='0'; begin_year := '0' ; begin_month := '0' ; next_year := '0' ; next_month := '0' ; FOR rec_shipment_date IN SELECT * FROM tmp_shipment_date LOOP RAISE NOTICE 'SHIPMENT_DATE=%',rec_shipment_date."SHIPMENT_DATE"; current_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE"); current_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE") ; IF to_number(current_month,'99') < 10 THEN current_month := '0'||current_month ; END IF ; --Init borders IF begin_year = '0' THEN first_flag := true ; --first time flag begin_year := current_year ; begin_month := current_month ; IF current_month = '12' THEN next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ; ELSE next_year := current_year ; END IF; next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ; END IF; -- Check current date into borders NOT for First time IF to_date( current_year||'.'||current_month, 'YYYY.MM') >= to_date( begin_year||'.'||begin_month, 'YYYY.MM') AND to_date( current_year||'.'||current_month, 'YYYY.MM') < to_date( next_year||'.'||next_month, 'YYYY.MM') AND NOT first_flag THEN CONTINUE ; ELSE --NEW borders only for second and after time begin_year := current_year ; begin_month := current_month ; IF current_month = '12' THEN next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ; ELSE next_year := current_year ; END IF; next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ; END IF; partition_name := 'shipment_shipment_date_'||begin_year||'-'||begin_month||'-01-'|| next_year||'-'||next_month||'-01' ; EXECUTE format('CREATE TABLE ' || quote_ident(partition_name) || ' PARTITION OF shipment FOR VALUES FROM ( %L ) TO ( %L ) ' , current_year||'-'||current_month||'-01' , next_year||'-'||next_month||'-01' ) ; index_name := partition_name||'_shipment_id_idx'; RAISE NOTICE 'INDEX NAME =%',index_name; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID") TABLESPACE pg_default ' ) ; --Drop first time flag first_flag := false ; END LOOP; end $$; Importing dump
pg_restore -d postgres --data-only --format=c --table=shipment --verbose shipment.dmp > /tmp/data_dump/shipment_restore.log 2>&1 Check partitioning results
What do we have as a result? The full text of the implementation plan is large and boring, so it is quite possible to limit ourselves to the totals.
It was
Cost: 502 997.55
Execution time: 505 seconds.
It became
Cost: 77 872.36
Execution time: 79 seconds.
It is a good result. Reduced cost and lead time. Thus, the use of partitioning gives the expected effect and, in general, without surprises.
Please customer
Test results were submitted to the customer for review. And after reading them, a somewhat unexpected verdict was issued: “Great, section the“ data ”table”.
Yes, but we investigated a completely different “shipment” table, the “data” table does not have a “SHIPMENT_DATE” field.
Not a problem, add, change. The main thing is that the customer is satisfied with what happens as a result, the implementation details are not particularly important.
We partition the main table "data"
In general, no particular difficulties arose. Although, the partitioning algorithm, of course, has changed somewhat.
Add the column “SHIPMENT_DATA” to the table “data”
psql -h -U -d => ALTER TABLE data ADD COLUMN "SHIPMENT_DATE" timestamp without time zone ; Fill in the values of the column “SHIPMENT_DATA” in the table “data” with the values of the same column from the table “shipment”
----------------------------- --update_data.sql --updating for altered table "data" to values of "shipment_data" from the table "shipment" --version 1.0 do language plpgsql $$ declare rec_shipment_data RECORD ; shipment_date timestamp without time zone ; row_count integer ; total_rows integer ; begin select count(*) into total_rows from shipment ; RAISE NOTICE 'Total %',total_rows; row_count:= 0 ; FOR rec_shipment_data IN SELECT * FROM shipment LOOP update data set "SHIPMENT_DATE" = rec_shipment_data."SHIPMENT_DATE" where "SHIPMENT_ID" = rec_shipment_data."SHIPMENT_ID"; row_count:= row_count +1 ; RAISE NOTICE 'row count = % , from %',row_count,total_rows; END LOOP; end $$; We save a dump of the data table
pg_dump postgres --file=/dump/data.dmp --format=c --table=data --verbose > /dump/data.log 2>&1</source Re-create the partitioned data table
--create_partition_data.sql --create partitions for the table "wafer data" by range column "shipment_data" with one month duration --version 1.0 do language plpgsql $$ declare rec_shipment_date RECORD ; partition_name varchar; index_name varchar; current_year varchar ; current_month varchar ; begin_year varchar ; begin_month varchar ; next_year varchar ; next_month varchar ; first_flag boolean ; i integer ; begin RAISE NOTICE 'CREATE TEMPORARY TABLE FOR SHIPMENT_DATE'; CREATE TEMP TABLE tmp_shipment_date as select distinct "SHIPMENT_DATE" from shipment order by "SHIPMENT_DATE" ; RAISE NOTICE 'DROP TABLE data'; drop table data cascade ; RAISE NOTICE 'CREATE PARTITIONED TABLE data'; CREATE TABLE public.data ( "RUN_ID" integer, "LASERMARK" character varying(20) COLLATE pg_catalog."default" NOT NULL, "LOTID" character varying(80) COLLATE pg_catalog."default", "SHIPMENT_ID" integer NOT NULL, "PARAMETER_ID" integer NOT NULL, "INTERNAL_VALUE" character varying(75) COLLATE pg_catalog."default", "REPORTED_VALUE" character varying(75) COLLATE pg_catalog."default", "LOWER_SPEC_LIMIT" numeric, "UPPER_SPEC_LIMIT" numeric , "SHIPMENT_DATE" timestamp without time zone ) PARTITION BY RANGE ("SHIPMENT_DATE") WITH ( OIDS = FALSE ) TABLESPACE pg_default ; RAISE NOTICE 'CREATE PARTITIONS FOR TABLE data'; current_year:='0'; current_month:='0'; begin_year := '0' ; begin_month := '0' ; next_year := '0' ; next_month := '0' ; i := 1; FOR rec_shipment_date IN SELECT * FROM tmp_shipment_date LOOP RAISE NOTICE 'SHIPMENT_DATE=%',rec_shipment_date."SHIPMENT_DATE"; current_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE"); current_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE") ; --Init borders IF begin_year = '0' THEN RAISE NOTICE '***Init borders'; first_flag := true ; --first time flag begin_year := current_year ; begin_month := current_month ; IF current_month = '12' THEN next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ; ELSE next_year := current_year ; END IF; next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ; END IF; -- RAISE NOTICE 'current_year=% , current_month=% ',current_year,current_month; -- RAISE NOTICE 'begin_year=% , begin_month=% ',begin_year,begin_month; -- RAISE NOTICE 'next_year=% , next_month=% ',next_year,next_month; -- Check current date into borders NOT for First time RAISE NOTICE 'Current data = %',to_char( to_date( current_year||'.'||current_month, 'YYYY.MM'), 'YYYY.MM'); RAISE NOTICE 'Begin data = %',to_char( to_date( begin_year||'.'||begin_month, 'YYYY.MM'), 'YYYY.MM'); RAISE NOTICE 'Next data = %',to_char( to_date( next_year||'.'||next_month, 'YYYY.MM'), 'YYYY.MM'); IF to_date( current_year||'.'||current_month, 'YYYY.MM') >= to_date( begin_year||'.'||begin_month, 'YYYY.MM') AND to_date( current_year||'.'||current_month, 'YYYY.MM') < to_date( next_year||'.'||next_month, 'YYYY.MM') AND NOT first_flag THEN RAISE NOTICE '***CONTINUE'; CONTINUE ; ELSE --NEW borders only for second and after time RAISE NOTICE '***NEW BORDERS'; begin_year := current_year ; begin_month := current_month ; IF current_month = '12' THEN next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ; ELSE next_year := current_year ; END IF; next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ; END IF; IF to_number(current_month,'99') < 10 THEN current_month := '0'||current_month ; END IF ; IF to_number(begin_month,'99') < 10 THEN begin_month := '0'||begin_month ; END IF ; IF to_number(next_month,'99') < 10 THEN next_month := '0'||next_month ; END IF ; RAISE NOTICE 'current_year=% , current_month=% ',current_year,current_month; RAISE NOTICE 'begin_year=% , begin_month=% ',begin_year,begin_month; RAISE NOTICE 'next_year=% , next_month=% ',next_year,next_month; partition_name := 'data_'||begin_year||begin_month||'01_'||next_year||next_month||'01' ; RAISE NOTICE 'PARTITION NUMBER % , TABLE NAME =%',i , partition_name; EXECUTE format('CREATE TABLE ' || quote_ident(partition_name) || ' PARTITION OF data FOR VALUES FROM ( %L ) TO ( %L ) ' , begin_year||'-'||begin_month||'-01' , next_year||'-'||next_month||'-01' ) ; index_name := partition_name||'_shipment_id_parameter_id_idx'; RAISE NOTICE 'INDEX NAME =%',index_name; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID", "PARAMETER_ID") TABLESPACE pg_default ' ) ; index_name := partition_name||'_lasermark_idx'; RAISE NOTICE 'INDEX NAME =%',index_name; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("LASERMARK" COLLATE pg_catalog."default") TABLESPACE pg_default ' ) ; index_name := partition_name||'_shipment_id_idx'; RAISE NOTICE 'INDEX NAME =%',index_name; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID") TABLESPACE pg_default ' ) ; index_name := partition_name||'_parameter_id_idx'; RAISE NOTICE 'INDEX NAME =%',index_name; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("PARAMETER_ID") TABLESPACE pg_default ' ) ; index_name := partition_name||'_shipment_date_idx'; RAISE NOTICE 'INDEX NAME =%',index_name; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_DATE") TABLESPACE pg_default ' ) ; --Drop first time flag first_flag := false ; END LOOP; end $$; Load the dump created in step 3.
pg_restore -h - -d --data-only --format=c --table=data --verbose data.dmp > data_restore.log 2>&1 We create a separate section for old data
--------------------------------------------------- --create_partition_for_old_dates.sql --create partitions for keeping old dates --version 1.0 do language plpgsql $$ declare rec_shipment_date RECORD ; partition_name varchar; index_name varchar; begin SELECT min("SHIPMENT_DATE") AS min_date INTO rec_shipment_date from data ; RAISE NOTICE 'Old date is %',rec_shipment_date.min_date ; partition_name := 'data_old_dates' ; RAISE NOTICE 'PARTITION NAME IS %',partition_name; EXECUTE format('CREATE TABLE ' || quote_ident(partition_name) || ' PARTITION OF data FOR VALUES FROM ( %L ) TO ( %L ) ' , '1900-01-01' , to_char( rec_shipment_date.min_date,'YYYY')||'-'||to_char(rec_shipment_date.min_date,'MM')||'-01' ) ; index_name := partition_name||'_shipment_id_parameter_id_idx'; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID", "PARAMETER_ID") TABLESPACE pg_default ' ) ; index_name := partition_name||'_lasermark_idx'; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("LASERMARK" COLLATE pg_catalog."default") TABLESPACE pg_default ' ) ; index_name := partition_name||'_shipment_id_idx'; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID") TABLESPACE pg_default ' ) ; index_name := partition_name||'_parameter_id_idx'; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("PARAMETER_ID") TABLESPACE pg_default ' ) ; index_name := partition_name||'_shipment_date_idx'; EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_DATE") TABLESPACE pg_default ' ) ; end $$; Final results:
It was
Cost: 502 997.55
Execution time : 505 seconds.
It became
Cost: 68 533.70
Execution time: 69 seconds
Worthy, quite worthy. And considering that along the way, we managed to more or less master the partitioning mechanism in PostgreSQL 10 - Excellent result.
Lyrical digression
And you can do even better - YES, YOU CAN!
For this you need to use MATERIALIZED VIEW.
Once again we rewrite the query:
And we get another result:
It was
Cost: 502 997.55
Execution time : 505 seconds
It became
Cost: 42 481.16
Execution time: 43 seconds.
Although of course, he promises such a promising result, ideas need to be refreshed. So the final time of data acquisition is not very helpful. But as an experiment, it is quite interesting.
In fact, as it turned out, thanks again to asmm and Habra! - the query can be further improved.
CREATE MATERIALIZED VIEW LASERMARK_VIEW
CREATE MATERIALIZED VIEW LASERMARK_VIEW AS SELECT w."LASERMARK" , MAX(s."SHIPMENT_DATE") AS "SHIPMENT_DATE" FROM shipment s INNER JOIN data w ON s."SHIPMENT_ID" = w."SHIPMENT_ID" GROUP BY w."LASERMARK" ; CREATE INDEX lasermark_vw_shipment_date_ind on lasermark_view USING btree ("SHIPMENT_DATE") TABLESPACE pg_default; analyze lasermark_view ; Once again we rewrite the query:
Query using materialized view
SELECT p."PARAMETER_ID" as parameter_id, pc."PC_NAME" AS pc_name, pc."CUSTOMER_PARTNUMBER" AS customer_partnumber, w."LASERMARK" AS lasermark, w."LOTID" AS lotid, w."REPORTED_VALUE" AS reported_value, w."LOWER_SPEC_LIMIT" AS lower_spec_limit, w."UPPER_SPEC_LIMIT" AS upper_spec_limit, p."TYPE_CALCUL" AS type_calcul, s."SHIPMENT_NAME" AS shipment_name, s."SHIPMENT_DATE" AS shipment_date, extract(year from s."SHIPMENT_DATE") AS year, extract(month from s."SHIPMENT_DATE") as month, s."REPORT_NAME" AS report_name, p."STC_NAME" AS STC_name, p."CUSTOMERPARAM_NAME" AS customerparam_name FROM data w INNER JOIN shipment s ON s."SHIPMENT_ID" = w."SHIPMENT_ID" INNER JOIN parameters p ON p."PARAMETER_ID" = w."PARAMETER_ID" INNER JOIN shipment_pc sp ON s."SHIPMENT_ID" = sp."SHIPMENT_ID" INNER JOIN pc pc ON pc."PC_ID" = sp."PC_ID" INNER JOIN LASERMARK_VIEW md ON md."SHIPMENT_DATE" = s."SHIPMENT_DATE" AND md."LASERMARK" = w."LASERMARK" WHERE s."SHIPMENT_DATE" >= '2018-07-01' AND s."SHIPMENT_DATE" <= '2018-09-30'; And we get another result:
It was
Cost: 502 997.55
Execution time : 505 seconds
It became
Cost: 42 481.16
Execution time: 43 seconds.
Although of course, he promises such a promising result, ideas need to be refreshed. So the final time of data acquisition is not very helpful. But as an experiment, it is quite interesting.
In fact, as it turned out, thanks again to asmm and Habra! - the query can be further improved.
Afterword
So, the customer is satisfied. And you need to take advantage of the situation.
New task : What can you think of this to deepen and expand?
And then I remember - guys, and in fact we do not have monitoring of our PostgreSQL databases.
Hand on heart, there is some monitoring in the form of Cloud Watch on AWS. But what is the use of this monitoring for DBA? In general, almost none.
If you have a chance to make something useful and interesting for yourself, you should not take advantage of this chance ...
FOR

That's how we came to the most interesting:
December 3, 2018But this is a completely different story.
Make a decision about starting research on the existing capabilities for monitoring PostgreSQL query performance.
To be continued...
Source: https://habr.com/ru/post/446442/
All Articles