Building blocks distributed applications. Second approximation
Announcement
Colleagues, in the middle of summer I plan to release another series of articles on the design of queuing systems: “VTrade Experiment” - an attempt to write a framework for trading systems. In the cycle, the theory and practice of building an exchange, an auction and a store will be analyzed. At the end of the article I propose to vote for the most interesting topics for you.

This is the final article of the cycle on distributed reactive applications on Erlang / Elixir. In the first article you can find the theoretical foundations of reactive architecture. The second article illustrates the basic patterns and mechanisms for constructing such systems.
Today we will raise the issues of development of the code base and projects in general.
Service organization
In real life, when developing a service, it is often necessary to combine several interaction patterns in one controller. For example, the users service, which solves the problem of managing user profiles for a project, should respond to requests for req-resp and report on profile updates via pub-sub. This case is quite simple: there is one controller for messaging, which implements the service logic and publishes updates.
The situation is complicated when we need to implement a fault-tolerant distributed service. Imagine that the requirements for users have changed:
- now the service should process requests on 5 nodes of the cluster,
- be able to perform background processing tasks,
- and also be able to dynamically manage subscription lists for profile updates.
Note: We do not consider the issue of consistent storage and data replication. Suppose that these issues are resolved earlier and a reliable and scalable storage layer already exists in the system, and the handlers have mechanisms for interacting with it.
The formal description of the users service has become complicated. From the point of view of the programmer, thanks to the use of messaging, the changes are minimal. To satisfy the first requirement, we need to adjust the balancing on the req-resp exchange point.
The requirement to process background tasks occurs frequently. In users, this can be the verification of user documents, the processing of downloaded media, or the synchronization of data with social media. by networks. These tasks need to be somehow distributed within the cluster and monitored the progress. Therefore, we have two solutions: either use the task distribution template from the previous article, or, if it does not fit, write a custom task scheduler that will be necessary for us to manage the pool of handlers.
Point 3 requires an extension of the pub-sub pattern. And for implementation, after creating the pub-sub exchange point, we need to additionally run the controller of this point as part of our service. Thus, we seem to take out the logic of processing a subscription and unsubscribing from the messaging layer to the users implementation.
As a result, the decomposition of the task showed that in order to meet the requirements we need to run 5 instances of the service on different nodes and create an additional entity - the pub-sub controller responsible for the subscription.
To run 5 handlers there is no need to change the service code. The only additional action is to set up balancing rules on the exchange point, which we will talk about later.
Also, there was an additional difficulty: the pub-sub controller and the custom task scheduler should work in a single copy. Again, the messaging service, as fundamental, must provide a leader selection mechanism.
Leader selection
In distributed systems, the choice of a leader is the procedure for assigning a single process that is responsible for planning the distributed processing of a load.
In systems that are not prone to centralization, universal algorithms and algorithms based on consensus, such as paxos or raft, are used.
Since messaging is a broker and a central element, it knows about all service controllers — candidates for leadership. Messaging can appoint a leader without a vote.
All services after starting and connecting to the exchange point receive the system message #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} . If the LeaderPid matches the pid current process, it is assigned the leader, and the Servers list includes all nodes and their parameters.
At the time of the emergence of a new and disconnected cluster node, all service controllers receive #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} and #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} respectively.
Thus, all components are aware of all changes, and in a cluster at one time moment one leader is guaranteed.
Mediators
To implement complex distributed processing processes, as well as in optimization problems of an existing architecture, it is convenient to use intermediaries.
In order not to change the service code and solve, for example, additional processing, routing or message logging tasks, you can enable the proxy handler before the service, which will do all the extra work.
A classic example of a pub-sub optimization is a distributed application with a business core that generates update events, such as a price change in the market, and an access layer — N servers that provide the websocket API for web clients.
If you decide "in the forehead," customer service is as follows:
- the client is connecting to the platform. On the server side, which terminates traffic, the process that starts this connection is launched.
- in the context of the serving process, authorization and subscription to updates take place. The process calls the subscribe method for topics.
- after generating an event in the kernel, it is delivered to the processes serving the connections.
Imagine that we have 50,000 subscribers to the topic “news”. Subscribers are distributed across 5 servers evenly. As a result, each update, coming to the exchange point, will be replicated 50,000 times: 10,000 times to each server, according to the number of subscribers on it. Not exactly an effective scheme, right?
To improve the situation, we introduce a proxy, having the same name with the exchange point. A global name registrar should be able to return the closest process by name, this is important.
We will run this proxy on the access layer servers, and all our processes serving websocket api will subscribe to it, and not to the original pub-sub exchange point in the kernel. Proxy subscribes to the kernel only in case of a unique subscription and replicates the received message to all its subscribers.
As a result, 5 messages will be forwarded between the kernel and access servers, instead of 50,000.
Routing and balancing
Req-resp
In the current messaging implementation, there are 7 query distribution strategies:
default. The request is transmitted to all controllers.round-robin. The search and cyclic distribution of requests among controllers is carried out.consensus. Controllers serving the service are divided into leader and slave. Requests are transmitted only to the leader.consensus & round-robin. The group has a leader, but requests are shared among all members.sticky. The hash function is computed and assigned to a specific handler. Subsequent requests with this signature go to the same handler.sticky-fun. When the exchange point is initialized, the function of calculating the hash forstickybalancing is additionally transferred.fun. Similar to sticky-fun, only you can additionally redirect, reject, or preprocess it.
The distribution strategy is set when the exchange point is initialized.
In addition to balancing messaging allows you to tag entities. Consider the types of tags in the system:
- Connection tag. It allows you to understand what connection the events came through. Used when the controller process connects to the same exchange point, but with different routing keys.
- Service tag. Allows for one service to aggregate handlers into groups and expand the possibilities of routing and balancing. For req-resp pattern routing is linear. We send a request to the exchange point, then it sends it to the service. But if we need to break handlers into logical groups, then splitting is done with the help of tags. When specifying the tag, the request will be sent to a specific group of controllers.
- Request tag Allows you to distinguish the answers. Since our system is asynchronous, to process the responses of the service, you need to be able to specify RequestTag when sending a request. According to it, we can understand the answer to which request came to us.
Pub sub
For pub-sub everything is a bit easier. We have a point of exchange for which messages are published. The exchange point distributes messages between subscribers who have subscribed to the routing keys they need (we can say that this is an analogue of those).
Scalability and resiliency
The scalability of the system as a whole depends on the degree of scalability of the layers and components of the system:
- Services are scaled by adding additional nodes to the cluster with handlers for this service. During trial operation, you can select the optimal balancing policy.
- The very same messaging service within a separate cluster in the general case is scaled either by moving specially loaded exchange points to separate cluster nodes, or by adding proxy processes to specially loaded areas of the cluster.
- The scalability of the entire system as a characteristic depends on the flexibility of the architecture and the possibility of combining individual clusters into a common logical entity.
The success of a project often depends on simplicity and speed of scaling. Messaging in the current performance grows with the application. Even if we lack a cluster of 50-60 cars, we can resort to the federation. Unfortunately, the topic of federation is beyond the scope of this article.
Reservation
When parsing load balancing, we have already discussed the redundancy of service controllers. However, messaging must also be reserved. In the event of a node or machine crash, messaging should automatically recover, and in the shortest possible time.
In my projects I use additional nodes that pick up the load in case of a fall. In Erlang, there is a standard distributed mode implementation for OTP applications. Distributed mode performs the restoration in the event of a failure by running the fallen application on another previously running node. The process is transparent, after a failure, the application moves automatically to the failover node. You can read more about this functionality here .
Performance
Let's try to at least approximately compare the performance of rabbitmq and our custom messaging.
I found the official rabbitmq test results from the openstack team.
In clause 6.14.1.2.1.2.2. The original document presents the result of RPC CAST: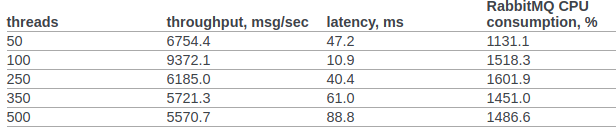
We will not make any additional settings in the OS kernel or erlang VM. Conditions for testing:
- erl opts: + A1 + sbtu.
- A test within one erlang node runs on a laptop with an old i7 in a mobile version.
- Cluster tests are performed on servers with 10G network.
- The code works in docker containers. Network in NAT mode.
Test code:
req_resp_bench(_) -> W = perftest:comprehensive(10000, fun() -> messaging:request(?EXCHANGE, default, ping, self()), receive #'$msg'{message = pong} -> ok after 5000 -> throw(timeout) end end ), true = lists:any(fun(E) -> E >= 30000 end, W), ok. Scenario 1: The test runs on a laptop with an old i7 mobile performance. Test, messaging and service are performed on one node in the same docker-container:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s) Sequential 20000 cycles in ~1 seconds (26915 cycles/s) Sequential 100000 cycles in ~4 seconds (26957 cycles/s) Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s) Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s) Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s) Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s) Scenario 2 : 3 nodes running on different machines under docker (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s) Sequential 20000 cycles in ~2 seconds (8424 cycles/s) Sequential 100000 cycles in ~12 seconds (8655 cycles/s) Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s) Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s) Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s) Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s) In all cases, CPU utilization did not exceed 250%.
Results
I hope this cycle does not look like a consciousness dump and my experience will bring real benefits to both distributed system researchers and practitioners who are at the very beginning of building distributed architectures for their business systems and look at Erlang / Elixir with interest, but they doubt is it worth ...
Photo @chuttersnap
')
Source: https://habr.com/ru/post/446344/
All Articles