Building blocks distributed applications. First approach

In the last article, we discussed the theoretical foundations of reactive architecture. It's time to talk about data streams, ways to implement reactive Erlang / Elixir systems, and message exchange patterns in them:
- Request-response
- Request-Chunked Response
- Response with Request
- Publish-subscribe
- Inverted Publish-subscribe
- Task distribution
SOA, MSA and messaging
SOA, MSA - system architectures that define the rules for building systems, while messaging provides primitives for their implementation.
I do not want to promote this or that system architecture. I am for the application of the most effective and useful practices for a particular project and business. Whatever paradigm we choose, it is better to create system blocks with an eye on the Unix-way: components with minimal connectivity that are responsible for individual entities. API methods perform as simple as possible with entities.
Messaging - as the name implies - a message broker. His main goal is to receive and give messages. He is responsible for information sending interfaces, the formation of logical channels of information transfer within the system, routing and balancing, and the processing of failures at the system level.
The developed messaging does not try to compete with or replace rabbitmq. Its main features are:
- Distribution.
Exchange points can be created on all nodes of the cluster, as close as possible to the code using them. - Simplicity.
Focus on minimizing the template code and ease of use. - Best performance.
We are not trying to repeat the functionality of rabbitmq, but select only the architectural and transport layer, which is as simple as possible to fit into the OTP, minimizing costs. - Flexibility.
Each service can unite in itself a set of exchange patterns. - Fail safety inherent in the design.
- Scalable.
Messaging grows with the application. As the load increases, you can move the exchange points to individual machines.
Comment. From the point of view of code organization, meta-projects are well suited for complex systems on Erlang / Elixir. All project code is in one repository - umbrella project. At the same time, microservices are maximally isolated and perform simple operations that are responsible for a separate entity. With this approach, it is easy to maintain the API of the entire system, just make changes, it is convenient to write a unit and integration tests.
Components of the system interact directly or through a broker. From the standpoint of messaging, each service has several vital phases:
- Initialization service.
At this stage, the process and dependencies that execute the service are configured and launched. - Create exchange point.
The service can use a static exchange point specified in the node configuration, or else create exchange points dynamically. - Registration service.
In order for the service to serve requests, it must be registered at the exchange point. - Normal functioning
The service does useful work. - Completion of work.
There are 2 types of completion: regular and emergency. With a regular service, it disconnects from the exchange point and stops. In emergency cases, messaging performs one of the failure handling scenarios.
It looks quite difficult, but the code is not so scary. Code samples with comments will be given in the parsing templates a little later.
Exchanges
The exchange point is a process of messaging that implements the logic of interaction with components within the framework of a message exchange pattern. In all the examples presented below, the components interact through exchange points, the combination of which forms a messaging.
Message exchange patterns (MEPs)
Global exchange patterns can be divided into bilateral and one-sided. The first implies a response to the received message, the second is not. A classic example of a two-way pattern in a client-server architecture is the Request-response pattern. Consider the pattern and its modifications.
Request – response or RPC
RPC is used when we need to get a response from another process. This process can be run on the same node or be on a different continent. Below is a diagram of the interaction between the client and server via messaging.
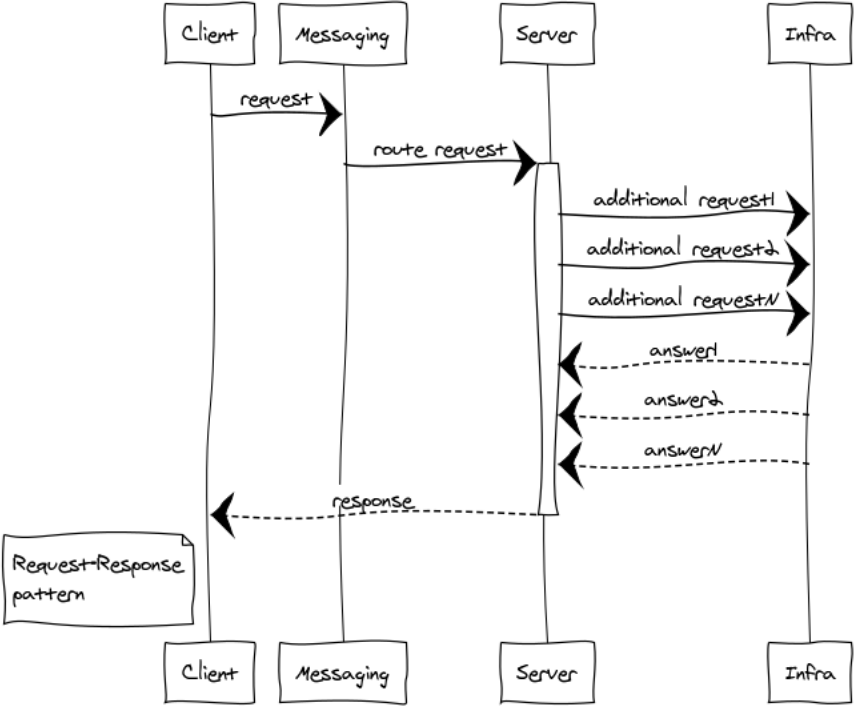
Since messaging is completely asynchronous, for the client the exchange is divided into 2 phases:
Submit request
messaging:request(Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess).Exchange - the unique name of the exchange point
ResponseMatchingTag is the local label for handling the response. For example, in the case of sending several identical requests belonging to different users.
RequestDefinition - request body
HandlerProcess - PID handler. This process will receive a response from the server.Response processing
handle_info(#'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State)ResponsePayload - server response.
For the server, the process also consists of 2 phases:
- Initialization of the exchange point
- Processing incoming requests
We illustrate with the code this template. Suppose we need to implement a simple service that provides a single method of accurate time.
Server code
We put the definition of the service API in api.hrl:
%% ===================================================== %% entities %% ===================================================== -record(time, { unixtime :: non_neg_integer(), datetime :: binary() }). -record(time_error, { code :: non_neg_integer(), error :: term() }). %% ===================================================== %% methods %% ===================================================== -record(time_req, { opts :: term() }). -record(time_resp, { result :: #time{} | #time_error{} }). Define a service controller in time_controller.erl
%% . gen_server . %% gen_server init(Args) -> %% messaging:monitor_exchange(req_resp, ?EXCHANGE, default, self()) {ok, #{}}. %% . , . handle_info(#exchange_die{exchange = ?EXCHANGE}, State) -> erlang:send(self(), monitor_exchange), {noreply, State}; %% API handle_info(#time_req{opts = _Opts}, State) -> messaging:response_once(Client, #time_resp{ result = #time{ unixtime = time_utils:unixtime(now()), datetime = time_utils:iso8601_fmt(now())} }); {noreply, State}; %% gen_server terminate(_Reason, _State) -> messaging:demonitor_exchange(req_resp, ?EXCHANGE, default, self()), ok. Client code
In order to send a request to the service, you can call the messaging request API anywhere:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of ok -> ok; _ -> %% repeat or fail logic end In a distributed system, the configuration of the components may be very different and at the time of the request messaging may not start up yet, or the service controller will not be ready to service the request. Therefore, we need to check the messaging response and handle the case of failure.
After successfully sending to the client from the service will receive a response or error.
We handle both cases in handle_info:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) -> ?debugVal(Utime), {noreply, State}; handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) -> ?debugVal({error, ErrorCode}), {noreply, State}; Request-Chunked Response
It is better to prevent the transfer of huge messages. Responsiveness and stable operation of the entire system depends on it. If the answer to the request takes a lot of memory, then the breakdown is required.
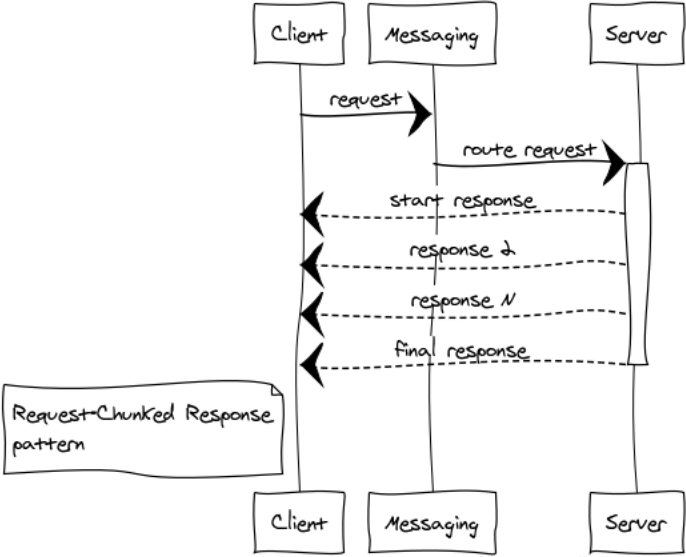
I will give a couple of examples of such cases:
- Components exchange binary data, such as files. Breakdown of the answer to small parts helps to work effectively with files of any size and not catching memory overflow.
- Listings For example, we need to select all records from a huge table in the database and transfer it to another component.
I call such answers a locomotive. Anyway, 1024 messages on 1 Mb are better, than the only message in the size of 1 Gb.
In the Erlang cluster, we get an additional gain - reducing the load on the exchange point and the network, since the answers are immediately sent to the recipient, bypassing the exchange point.
Response with Request
This is a rather rare modification of the RPC pattern for building interactive systems.
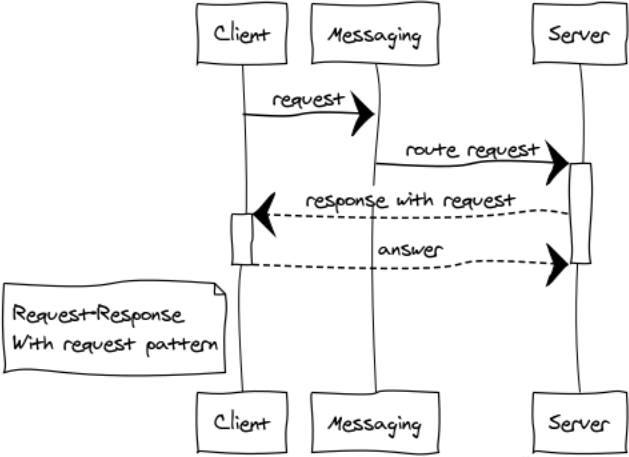
Publish-subscribe (data distribution tree)
Event-oriented systems deliver data to consumers as they become available. Thus, systems are more prone to push models than pull or poll. This feature allows you not to waste resources, constantly requesting and waiting for data.
The figure shows the process of distributing a message to consumers who subscribe to a specific topic.
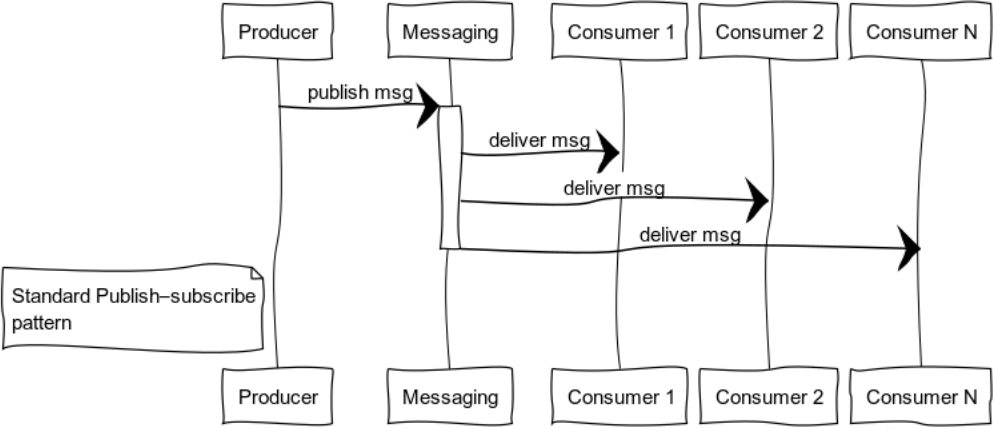
Classical examples of the use of this template are the state propagation: the game world in computer games, market data on exchanges, useful information in data feeds.
Consider the subscriber code:
init(_Args) -> %% , = key messaging:subscribe(?SUBSCRIPTION, key, tag, self()), {ok, #{}}. handle_info(#exchange_die{exchange = ?SUBSCRIPTION}, State) -> %% , messaging:subscribe(?SUBSCRIPTION, key, tag, self()), {noreply, State}; %% handle_info(#'$msg'{exchange = ?SUBSCRIPTION, message = Msg}, State) -> ?debugVal(Msg), {noreply, State}; %% - terminate(_Reason, _State) -> messaging:unsubscribe(?SUBSCRIPTION, key, tag, self()), ok. The source can call the function of publishing the message in any convenient place:
messaging:publish_message(Exchange, Key, Message). Exchange - the name of the exchange point
Key - routing key
Message - payload
Inverted Publish-subscribe
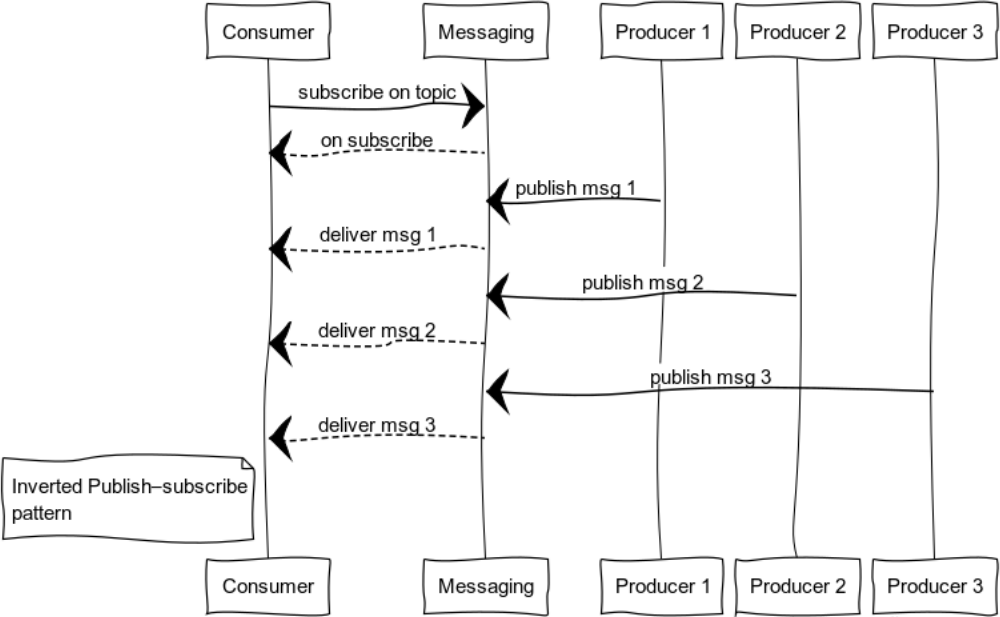
By deploying a pub-sub, you can get a pattern that is convenient for logging. The set of sources and consumers can be completely different. The figure shows the case with a single consumer and multiple sources.
Task distribution pattern
Almost every project has deferred processing tasks, such as generating reports, delivering notifications, and receiving data from third-party systems. The capacity of the system performing these tasks is easily scaled by adding handlers. All that remains for us is to form a cluster of handlers and evenly distribute the tasks between them.
Consider emerging situations on the example of 3 handlers. Even at the stage of distribution of tasks, the question arises of the fairness of distribution and overflow of handlers. For justice, the round-robin distribution will be responsible, and in order to avoid the situation of overflowing handlers, we introduce the restriction prefetch_limit . In transient modes, prefetch_limit will not allow one handler to get all the tasks.
Messaging manages queues and priority processing. Handlers receive tasks as they arrive. Task execution can be completed successfully or by failure:
messaging:ack(Tack)- called upon successful processing of the messagemessaging:nack(Tack)- called in all abnormal situations. After returning the task, the messaging will transfer it to another handler.
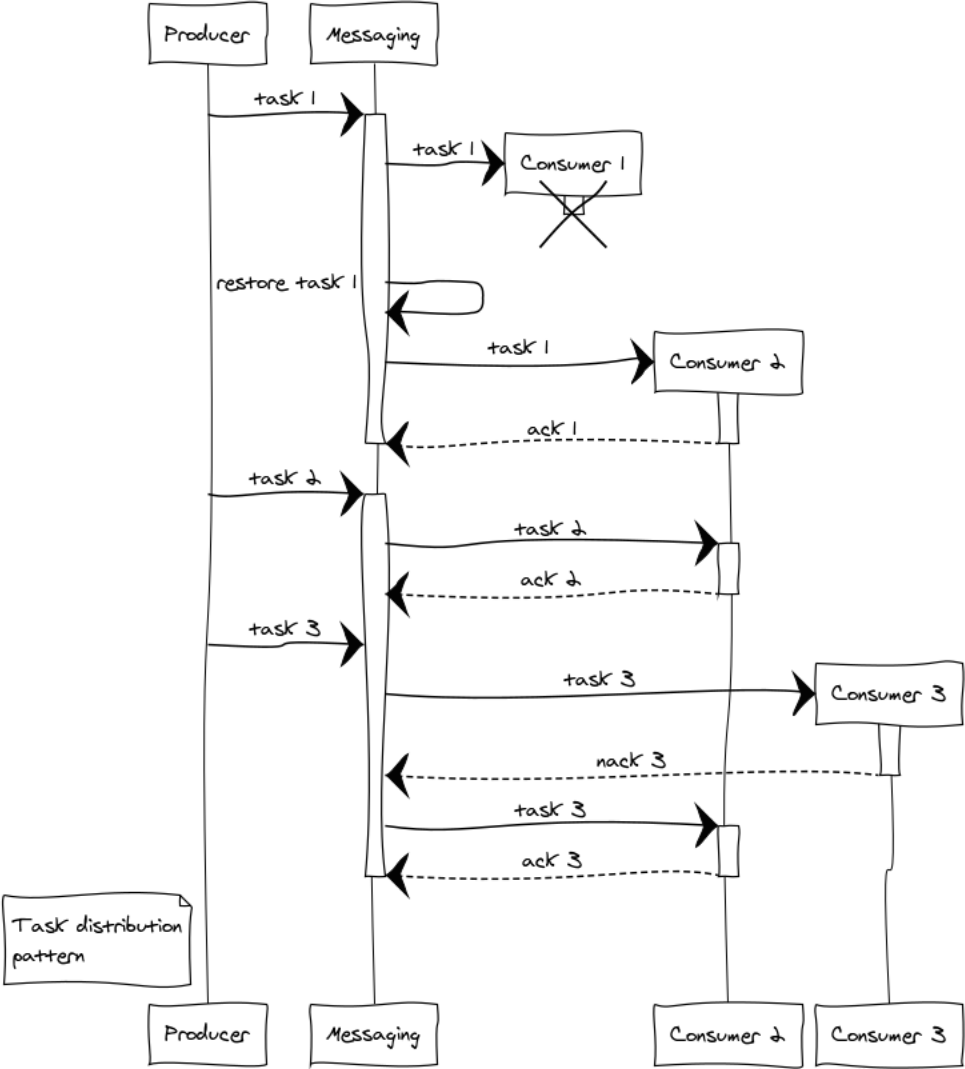
Suppose, when processing three tasks, a complex failure occurred: handler 1 fell after receiving the task, not having time to report anything to the exchange point. In this case, the exchange point after the expiration of ack timeout will transfer the job to another handler. Handler 3 for some reason refused the task and sent nack, as a result, the task also went to another handler who successfully completed it.
Preliminary result
We took apart the basic building blocks of distributed systems and gained a basic understanding of their use in Erlang / Elixir.
By combining basic patterns, you can build complex paradigms to solve emerging problems.
In the final part of the cycle we will look at the general issues of service organization, routing and balancing, and also talk about the practical side of scalability and fault tolerance of systems.
The end of the second part.
Marius Christensen Photos
Illustrations prepared using websequencediagrams.com
')
Source: https://habr.com/ru/post/446108/
All Articles