How I did NOT scan the Belarusian Internet
Foreword
This article is not quite similar to those that were published earlier about scanning the Internet of certain countries, because I did not pursue the goals of mass scanning of a specific segment of the Internet to open ports and the presence of the most popular vulnerabilities due to the fact that this is against the law.
I rather had a slightly different interest - try to identify all relevant sites in the BY domain zone using different methods, determine the stack of technologies used, through services like Shodan, VirusTotal, etc. Perform passive reconnaissance on IP and open ports and collect some other useful information in the appendage. information for the formation of some general statistics on the level of security regarding sites and users.
Introductory and our tools
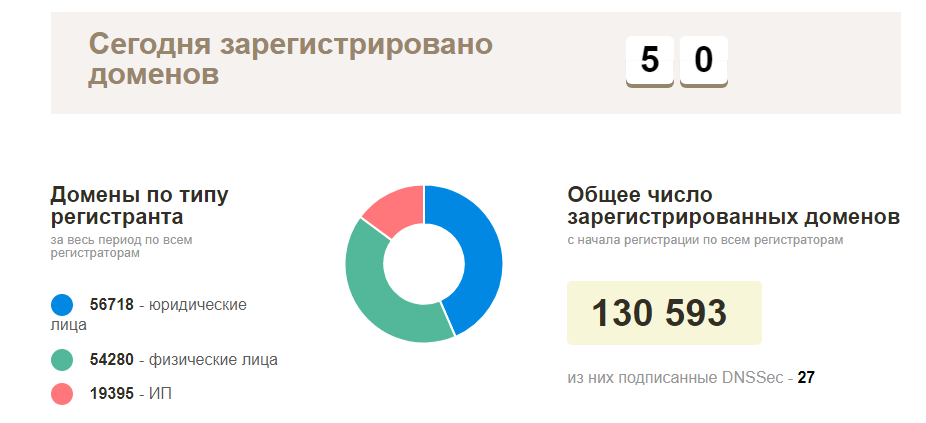
The plan at the very beginning was simple - contact the local registrar for a list of currently registered domains, then check everything for availability and start exploring functioning sites. In reality, everything turned out to be much more complicated - naturally, no one wanted to provide this kind of information, except for the official statistics page of current registered domain names in the BY zone (about 130 thousand domains). If there is no such information, then you will have to collect it yourself.
')
According to the toolkit, everything is actually quite simple - we are looking in the direction of open source, something can always be added, finished some minimal crutches. From the most popular, the following tools were used:
- Whatweb
- curl
- dig
- wafw00f
- API third-party services ( VirusTotal , Google SafeBrwosing , Shodan , Vulners )
Beginning of activities: Starting point
As an introductory one, as I have already said, domain names ideally suited, but where can I get them? We need to start with something simpler, in this case, we can use IP addresses, but then again - with reverse loops it is not always possible to catch all the domains, and when collecting hostnames - not always the correct domain. At this stage, I began to think about possible scenarios for collecting this kind of information, again - the fact that our budget is $ 5 for renting a VPS was still taken into account, the rest should be free of charge.
Our potential sources of information:
- IP addresses ( ip2location site)
- Search domains by the second part of the email address (but where to get them? We will understand below)
- Some registrars / hosting providers may provide us such information in the form of sub-domains.
- Subdomains and their subsequent reverse (Sublist3r and Aquatone can help here)
- Brutfors and manual input (long, dreary, but possible, although I did not use this option)
I'll run a little ahead and say that with this approach I managed to collect about 50 thousand unique domains and sites, respectively (I didn't manage to process everything). If I continued to actively gather information, then in less than a month of work my conveyor would probably have mastered the entire base, or most of it.
Getting down to business
In previous articles, information about IP addresses was taken from the IP2LOCATION site, I didn’t stumble upon these articles (for all the actions took place much earlier), but I also came to this resource. However, in my case, the approach was different - I decided not to take the base to my place and not to extract information from CSV, but decided to monitor the changes directly on the site, on an ongoing basis and as the main base from which all subsequent scripts will take goals - made a table with IP addresses in different formats: CIDR, “from” and “to” list, country mark (just in case), AS Number, AS Description.
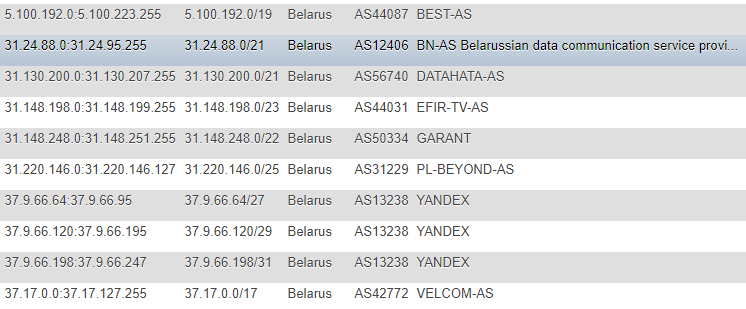
The format is not the most optimal, but for the demo and one-time action I was quite satisfied, and in order not to seek support information like ASN on a permanent basis, I decided to log it in addition. To get this information, I turned to the IpToASN service, they have a convenient API (with restrictions), which in fact you just need to integrate to yourself.
Code for parsing ip
function ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); } After we dealt with IP, we need to get rid of our entire database through reverse lookup services, alas, without any restrictions - this is impossible, except for money.
From the services that are great for this and are easy to use, I want to point out as many as two:
- VirusTotal - limit but the frequency of accessing from a single API key
- Hackertarget.com (their API) - limit on the number of hits from a single IP
Bypassing the limits we got the following options:
- In the first case, one of the scenarios is to withstand timeouts of 15 seconds, for a total of 4 hits per minute, which can greatly affect our speed and in this situation, using 2-3 such keys will be useful, and I would also recommend using to proxy and change user-agent.
- In the second case, I wrote a script for automatic parsing of the proxy database based on publicly available information, their validation and subsequent use (but later withdrew from this option because, in fact, VirusTotal was enough)
Go ahead and smoothly go to email addresses. They can also be a source of useful information, but where are they to be collected? It did not take long to find a solution, since in our segment of personal sites, users keep few, and in the bulk of this organization - then we will suit specialized sites like online store catalogs, forums, conditional marketplaces.
For example, a cursory inspection of one of these sites showed that so many users add their email directly to their public profile and accordingly - this case can be carefully parsed for later use.
One of the parsers
#!/usr/bin/env python3 import sys, threading, time, os, urllib, re, requests, pymysql from html.parser import HTMLParser from urllib import request from bs4 import BeautifulSoup # HEADERS CONFIG headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11.9; rv:42.0) Gecko/20200202 Firefox/41.0' } file = open('dat.html', 'w') def parseMails(uid): page = 'https://profile.onliner.by/user/'+str(uid)+'' cookie = {'onl_session': 'YOUR_SESSION_COOOKIE_HERE'} r = requests.get(page, headers = headers, cookies = cookie) data = BeautifulSoup(r.text) userinfo = data.find_all('dl', {'class': 'uprofile-info'}) find_email = [] for item in userinfo: find_email += str(item.find('a')) get_mail = ''.join(find_email) detect_email = re.compile(".+?>(.+@.+?)</a>").search(get_mail) file.write("<li>('"+detect_email.group(1)+"'),</li>") for uid in range(1, 10000): t = threading.Thread(target=parseMails, args=(uid,)) t.start() time.sleep(0.3) I will not go into details of the parsing of each of the sites, it is more convenient to guess the user ID somewhere by searching, somewhere easier to parse the site map, get information from the company pages from it, and then collect addresses from them. After collecting addresses, it remains for us to perform several simple operations at once sorted by domain zone, retaining tails for ourselves and driving away to eliminate duplicates on the existing base.
At this stage, I believe that with the formation of a skoup, we can finish and proceed to exploration. Exploration, as we already know, can be of two types - active and passive, in our case - the most relevant will be the passive approach. But then again, simply accessing a site on port 80 or 443 without a malicious load and exploiting vulnerabilities is quite a legitimate action. Our interest is server responses to a single request, in some cases there may be two requests (redirection from http to https), in more rare cases, as many as three (when using www).
Intelligence service
Using such information as a domain, we can collect the following data:
- DNS records (NS, MX, TXT)
- Answer Headers
- Determine the technology stack used
- Understand what protocol the site is running
- Try to identify open ports (based on Shodan / Censys) without direct scanning
- Try to identify vulnerabilities based on the correlation of information from Shodan / Censys with the Vulners base
- Is it in the malicious Google Safe Browsing database?
- Collect email addresses by domain, as well as match already found and check on Have I Been Pwned, in addition - linking to social networks
- A domain is in some cases not only the face of the company, but also the product of its activity, email addresses for registering with services, etc., respectively - you can search for information that is associated with them on resources like GitHub, Pastebin, Google Dorks (Google CSE )
You can always go ahead and use as a variant masscan or nmap, zmap, setting them up in advance through Tor with launching at random time or even from several instances, but we have different goals and the name implies that I didn’t do direct scans.
We collect DNS records, check the possibility of amplifying queries and configuration errors like AXFR:
Example of collecting NS server records
dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}' Example of collecting MX records (see NS, just replace 'ns' with 'mx'
Check on AXFR (there are many solutions here, here is another kostylny, but not a secret, used to view the output)
$digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr))); DNS Amplification Check
In my case, the NS servers were taken from the database, by the end of the variable, there you can substitute just any server as a matter of fact. Regarding the correctness of the results of this service - I can not be sure that everything there works 100% straight and the results are always valid, but I hope that most of the results are real.
dig +short test.openresolver.com TXT @$dns In my case, the NS servers were taken from the database, by the end of the variable, there you can substitute just any server as a matter of fact. Regarding the correctness of the results of this service - I can not be sure that everything there works 100% straight and the results are always valid, but I hope that most of the results are real.
If for any purpose we need to save the full-fledged final URL to the site, for this I used cURL:
curl -I -L $target | awk '/Location/{print $2}' He himself goes over the whole redirect and displays the final one, i.e. current site URL. In my case, this was extremely useful when later using a tool like WhatWeb.
Why do we use it? In order to determine the OS used, the web server, the CMS site, some headers, additional modules like JS / HTML libraries / frameworks, as well as the site title on which you can later try to filter to the same by activity.
In this case, a very convenient option would be to export the results of the work in XML format for subsequent parsing and import into the database if there is a goal to process everything later.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml For myself, I did the output on the basis of JSON and it was already added to the database.
Speaking of headers, you can do almost the same thing with ordinary cURLs, performing a query like this:
curl -I https://www.mywebsite.com In the headers to independently catch information about the CMS and web servers using regular expressions for example.
In addition to the stack from the useful, we can also highlight the ability to collect information about open ports using Shodan and then using the data — perform a check on the Vulners database using their API (links to services are given in the header). Of course, with accuracy in this situation there may be problems, yet this is not a direct scan with manual validation, but a banal “juggling” with data from third-party sources, but it's better than that at all.
PHP function for Shodan
function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); } An example of such a comparative analysis # 1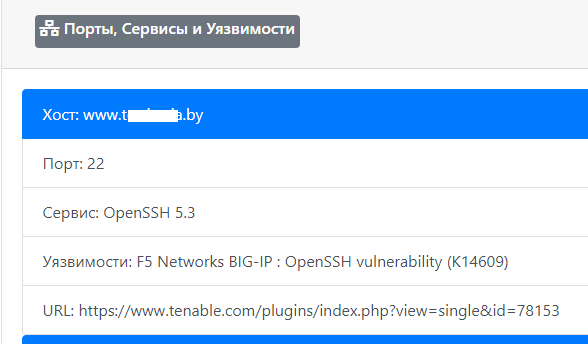
Example # 2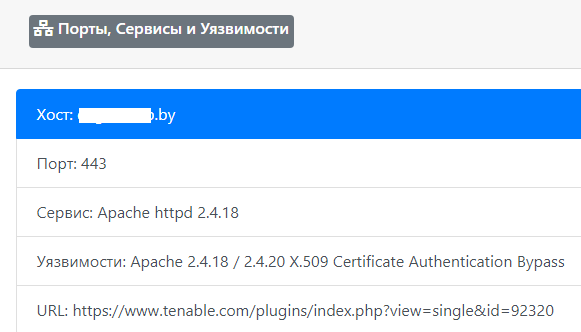
Yes, since I started talking over the API, Vulners has limitations and the most optimal solution would be to use their Python script, everything will work fine there without twisting and spinning, in the case of PHP it ran into some minor difficulties (again - add. timeouts saved the situation).
One of the last tests - we will study the information on the firewall used with the help of such a script as “wafw00f”. When testing this wonderful tula I noticed one interesting thing, it was not always the first time to determine the type of firewall used.
To see what types of firewalls can potentially determine wafw00f, you can enter the following command:
wafw00f -l To determine the type of firewall - wafw00f analyzes the server response headers after sending a standard request to the site, if this attempt is not enough, it forms an additional simple test request and if this is not enough again, the third method operates with data after the first two attempts .
Because For statistics, we don’t need the answer as a matter of fact, we cut off all unnecessary with a regular expression and leave only the name firewall:
/is\sbehind\sa\s(.+?)\n/ Well, as I wrote earlier, in addition to information about the domain and website, information about email addresses and social networks was also updated in a passive mode:
Statistics for email defined based on domain
An example of determining the binding of social networks to email address
The easiest was to deal with the validation of addresses on Twitter (2 ways), with Facebook (1 way) in this regard it turned out to be a little more difficult because of a slightly more complicated system of generating a real user session.
We turn to the dry statistics
DNS statistics
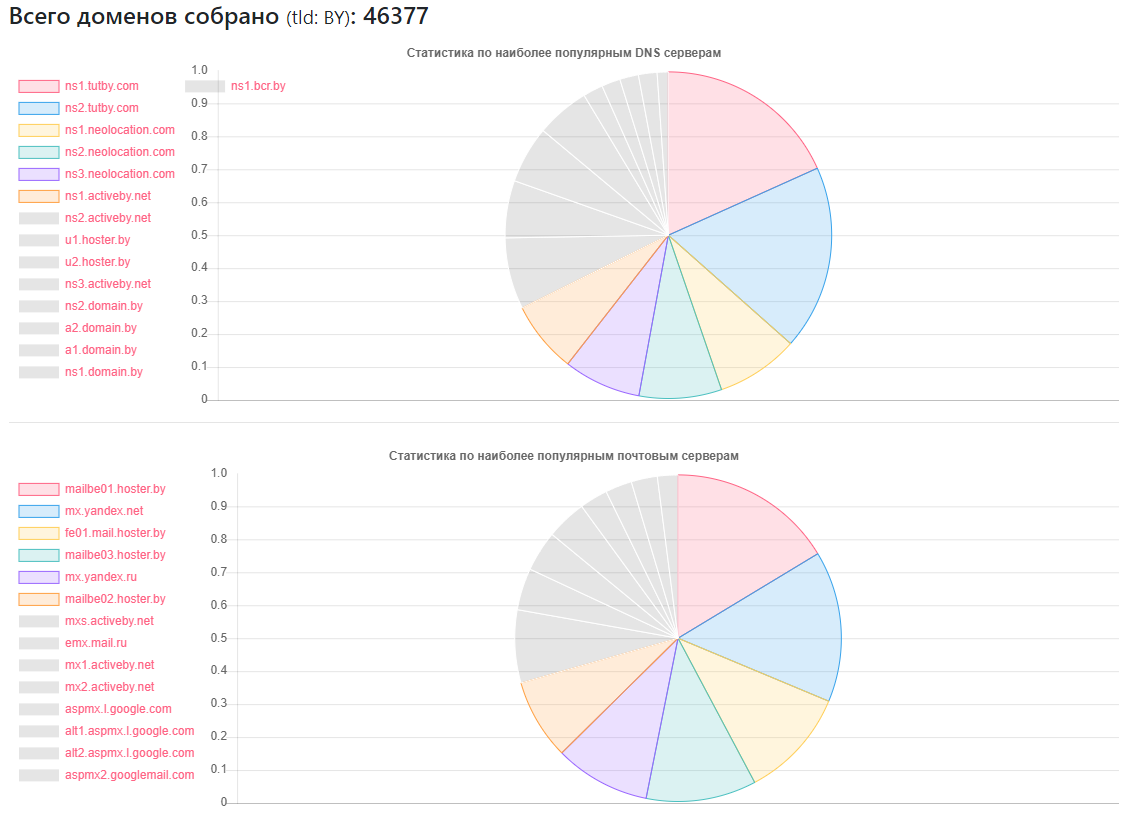
Provider - how many sites
ns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
Unique DNS detected: 2462
Unique MX (mail) servers: 9175 (except for popular services, there are a sufficient number of administrators who use their own mail services)
Affected DNS Zone Transfer: 1011
Subject to DNS Amplification: 531
Few CloudFlare fans: 375 (based on the NS records used)
CMS statistics
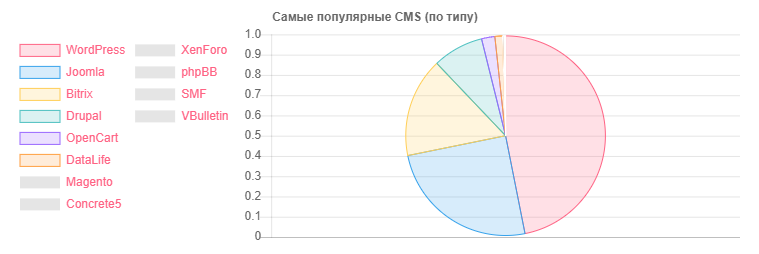
CMS - Quantity
WordPress: 5118
Joomla: 2722
Bitrix: 1757
Drupal: 898
OpenCart: 235
DataLife: 133
Magento: 32
- Potentially vulnerable WordPress installations: 2977
- Potentially vulnerable Joomla installations: 212
- Using the Google SafeBrowsing service, it turned out to identify potentially dangerous or infected sites: about 10,000 (at different times, someone fixed, someone apparently broke, the statistics are not entirely objective)
- About HTTP and HTTPS - less than half of the sites of the volume found use the latter, but taking into account that my database is not complete, but only 40% of the total, it is quite possible that most of the sites from the second half can and communicate via HTTPS .
Firewall statistics:

Firewall - Number
ModSecurity: 4354
IBM Web App Security: 126
Better WP Security: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
Web server statistics
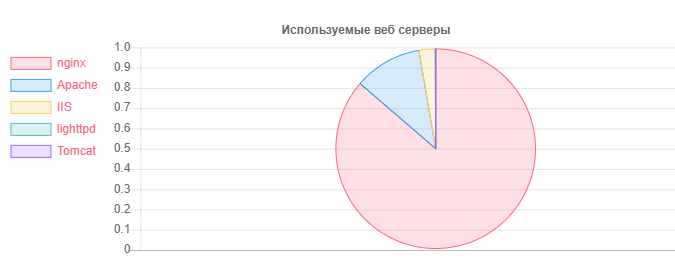
Web Server - Number
Nginx: 31752
Apache: 4042
IIS: 959
Outdated and potentially vulnerable Nginx installations: 20966
Outdated and potentially vulnerable Apache installations: 995
Despite the fact that the leader in domains and hosting as a whole, we are hoster.by, we can make an Open contact, but it’s true in terms of the number of sites on the same IP:
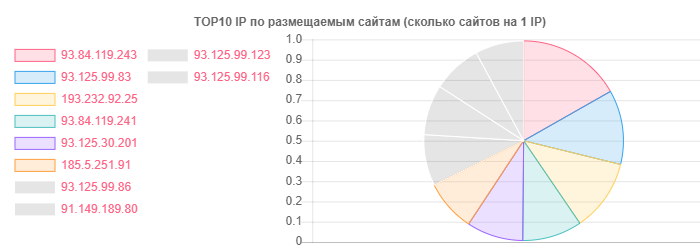
IP Sites
93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
According to email, I decided not to pull the detailed statistics at all, not to sort by domain zone, but rather the interest was to look at the location of users for specific vendors:
- On the service TUT.BY: 38282
- On Yandex service (by | ru): 28127
- On Gmail service: 33452
- Linked to Facebook: 866
- Linked to Twitter: 652
- Appeared in leaks according to HIBP information: 7844
- Passive intelligence helped to identify more than 13 thousand email addresses
As you can see, the overall picture is quite positive, especially pleased with the active use of nginx by hosting providers. Perhaps this is more due to the popular type of hosting among popular users.
From the fact that I didn’t like it very much - there are a sufficient number of medium-sized hosting providers who had errors like AXFR, outdated versions of SSH and Apache were used, and some other small problems. Here, of course, more light on the situation could shed a survey with the active phase, but at the moment, due to our legislation, it seems to me that it is impossible, and it’s not particularly desirable to register for such cases in the pest ranks.
The picture on the email as a whole is quite rosy, if you can call it that. Oh yeah, where the TUT.BY provider is indicated - it meant the use of a domain, since This service is based on Yandex.
Conclusion
As a conclusion, I can say one thing - even with the available results, you can quickly understand that there is a large amount of work for professionals who are engaged in cleaning sites from viruses, setting up WAF and configuring / completing different CMS.
Well, seriously, as in the previous two articles, we see that problems exist at absolutely different levels in absolutely all segments of the Internet and countries, and some of them even appear when studying the issue remotely, without using offensive techniques, t. e. operating with publicly available information for the collection of which special skills and is not required.
Source: https://habr.com/ru/post/446022/
All Articles