Trillion Little Shingles

Image source: www.nikonsmallworld.com
Anti-plagiarism is a specialized search engine, which was already mentioned earlier . Any search engine, anyway, to work quickly, you need your own index, which takes into account all the features of the search area. In my first article on Habré, I will talk about the current implementation of our search index, the history of its development and the reasons for choosing a particular solution. Efficient algorithms on .NET are not a myth, but a hard and productive reality. We will plunge into the world of hashing, bit-by-bit compression and multi-level priority caches. What to do if you need a search faster than O (1) ?
If someone else does not know where the shingles are in this picture, welcome ...
Shingles, index and why to look for them
Shingle - this is a piece of text, the size of a few words. Shingles go overlapping one after another, hence the name (English, shingles - scales, tiles). Their specific size is an open secret - 4 words. Or 5? Well, it depends. However, even this value does little and depends on the composition of stop words, the algorithm for normalizing words and other details that are not significant in this article. In the end, we calculate on the basis of this shingle 64-bit hash, which we will call shingle later on.
The text of the document can form a set of shingles, the number of which is comparable to the number of words in the document:
text: string → shingles: uint64 []
If several documents coincide with two documents, we will assume that the documents overlap. The more shingles match, the more identical text in this pair of documents. The index searches for documents with the most intersections with the document being checked.

Image source: Wikipedia
The index of shingle allows you to perform two basic operations:
Index the shingles of documents with their identifiers:
index.Add (docId, shingles)
Search in yourself and produce a ranked list of identifiers of overlapping documents:
index.Search (shingles) → (docId, score) []
The ranking algorithm, I think, is worthy of a separate article, so we will not write about it here.
The index of shingles is very different from well-known full-text counterparts, such as Sphinx, Elastic or larger ones: Google, Yandex, etc ... On the one hand, it does not require any NLP and other pleasures of life. All text processing is taken out and does not affect the process, as well as the order of shingles in the text. On the other hand, a search query is not a word or a phrase made of several words, but up to several hundred thousand hashes , which have a meaning all in the aggregate, and not separately.
Hypothetically, one can use the full-text index as a substitute for the index of shingles, but the differences are too great. The easiest way to use any known key-value-storage, this will be mentioned below. We saw our bicycle implementation, which is called ShingleIndex.
Why do we bother? But why?
- Volumes :
- A lot of documents. Now we have about 650 million of them, and this year there will obviously be more of them;
- The number of unique shingles is growing by leaps and bounds and already reaches hundreds of billions. We are waiting for a trillion.
- Speed :
- During the day, during the summer session, more than 300 thousand documents are checked by the Antiplagiat system . This is a bit by the standards of popular search engines, but keeps in good shape;
- For a successful check of documents for uniqueness, the number of indexed documents must be orders of magnitude larger than those being checked. The current version of our index on average can be filled at a speed of more than 4000 average documents per second.
And this is all on the same machine! Yes, we are able to replicate , we gradually approach dynamic sharding on a cluster, but since 2005 and to this day, the index on one machine with careful care has been able to cope with all the difficulties listed above.
Strange experience
However, it is now we are so experienced. Like it or not, but we also grew up and in the course of growth we tried different things, which are now fun to remember.
Image source: Wikipedia
First of all, an inexperienced reader would want to use a SQL database. You are not the only ones who think so; the SQL implementation has served us for several years to implement very small collections. Nevertheless, the focus was immediately on millions of documents, so I had to go further.
Nobody likes bicycles, and LevelDB was not yet in the public domain, so in 2010 our eyes fell on BerkeleyDB. Everything is cool - a persistent embedded key-value-base with the appropriate btree and hash access methods and a long history. Everything about her was wonderful, but:
- In the case of a hash-implementation, when it reaches 2GB, it just fell. Yes, we were still working in 32-bit mode;
- The B + tree implementation worked stably, but with volumes over several gigabytes, the search speed started to drop significantly.
We'll have to admit that we have not found a way to adjust it for our task. Maybe the problem is in .net-binding, which still had to finish. The BDB implementation was eventually used as a replacement for SQL as an intermediate index before pouring into the main one.
As time went. In 2014, tried LMDB and LevelDB, but did not implement. The guys from our Research Department in Antiplagiat as an index used RocksDB for their needs. At first glance, it was a godsend. But the slow replenishment and mediocre search speed even on small volumes reduced everything to nothing.
All of the above we did, in parallel, developing our own custom index. As a result, he became so good at solving our problems that we abandoned the previous “gags” and focused on improving it, which we now use in production everywhere.
Index layers
In the end, what do we have now? In fact, the index of shingles consists of several layers (arrays) with elements of constant length - from 0 to 128 bits - which depends not only on the layer and is not necessarily a multiple of eight.
Each layer plays a certain role. Some makes the search faster, some saves space, and some never used, but very necessary. We will try to describe them in order of increasing their total search efficiency.

Image source: Wikipedia
1. Index array
Without loss of generality, we will now assume that the document is mapped to a single shingle,
(docId → shingle)
Swap the elements of the pair in places (inverted, because the index is actually “inverted”!),
(shingle → docId)
Sort by shingle values and form a layer. Because Since the size of the shingle and the document identifier are constant, now anyone who understands binary search can find a pair of O (logn) file reads. What a lot, damn a lot. But this is better than just O (n) .
If the document has several shingles, then there will be several such pairs from the document. If there are several documents with the same shingle, then this will also change little - there will be several pairs in succession with the same shingle. In these both cases, the search will go for comparable time.
2. Group array
Carefully divide the index elements from the previous step into groups in any convenient way. For example, so that they fit into the sector cluster allocation unit unit (read, 4096 bytes), taking into account the number of bits and other tricks and form an effective dictionary. We will have a simple array of positions of such groups:
group_map (hash (shingle)) → group_position.
When searching for a shingle, we will now first look for the position of the group in this dictionary, and then unload the group and search directly in the memory. The whole operation requires two readings.
The vocabulary of group positions takes several orders of magnitude less space than the index itself, it can often be simply unloaded into memory. Thus, the readings will not be two, but one. Total, O (1) .
3. Bloom filter
At interviews, candidates often solve puzzles, producing unique solutions with O (n ^ 2) or even O (2 ^ n) . But we are not engaged in nonsense. Is there an O (0) in the world, that is the question? Let's try without much hope for the result ...
Referring to the subject area. If the student did a good job and wrote the work himself, or simply there is no text, but rubbish, then a significant part of his shingles will be unique and will not appear in the index. Such a data structure as a Bloom filter is well known in the world. Before searching, check the shingle for it. If there is no shingle in the index, then you can not search further, otherwise we go further.
The Bloom filter itself is fairly simple, but using the vector of hash functions with our volumes is meaningless. Just use one: +1 reading from Bloom’s filter. This gives -1 or -2 readings from subsequent stages, in case the shingle is unique, and there is no false positive response in the filter. Watch your hands!
The probability of Bloom’s filter error is given when building; the probability of an unknown shingle is determined by the student’s integrity. Simple calculations can come to the following dependency:
- If we trust the honesty of people (ie, in fact, the document is original), then the search speed will decrease;
- If the document is clearly styrenny, then the search speed will increase, but we will need a lot of memory.
With confidence in the students, we have the principle of “trust, but verify,” and practice shows that there is a profit from Bloom’s filter.
Given that this data structure is also smaller than the index itself and can be cached, at best it allows you to discard a shingle without any disk access at all.
4. Heavy tails
There are shingles that are found almost everywhere. Their share of the total is scanty, but when building the index in the first step, groups of tens and hundreds of MB can be obtained in the second step. Remember them separately and we will immediately throw away from the search query.
When for the first time in 2011 this trivial step was used, the size of the index was halved, and the search itself was accelerated.
5. Other tails
Even so, there may be a lot of documents on a shingle. And that's fine. Dozens, hundreds, thousands ... It becomes unprofitable to keep them inside the main index; We will carry them out in a separate sequence with more efficient storage. Statistics show that such a decision is more than justified. Moreover, various bit-wrap packages allow reducing the number of disk accesses and decreasing the index volume.
As a result, for ease of maintenance, we will print all these layers into one big file - chunk. There are ten such layers in it. But the part is not used when searching, the part is quite small and is always stored in memory, the part is actively cached as needed / possible.
In combat, most often the search for a shingle comes down to one or two random file reads. In the worst case, you have to do three. All layers are effectively (sometimes broken) packed arrays of elements of constant length. Such is the normalization. The time for unpacking is insignificant in comparison with the price of the final volume during storage and the possibility of better caching.
When building, the sizes of layers are mainly calculated in advance, are written sequentially, so this procedure is quite fast.
How did you go there, did not know where
2010 , . , . , .
Image source: Wikipedia
Initially, our index consisted of two parts - the constant described above and the temporary one, which was either SQL, or BDB, or its own update log. Occasionally, for example, once a month (and sometimes a year), the temporary one was sorted, filtered and merged with the main one. The result was a combined, and two old ones were deleted. If the temporary could not fit into the RAM, then the procedure went through external sorting.
This procedure was rather troublesome, started in a semi-manual mode and required the actual rewriting of the entire index file from scratch. Rewriting hundreds of gigabytes for the sake of a couple of millions of documents - well, so-so pleasure, I tell you ...
SSD. , 31 SSD wcf- . , . , .So that the SSD is not particularly strained, and the index is updated more often, in 2012, involved a chain of several pieces, chunk'ov according to the following scheme:

Here the index consists of a chain of similar chunks, except the very first one. The first, addon, was an append-only magazine with an in-memory index. Subsequent chunk'i increased in size (and age) until the very last (zero, main, root, ...).
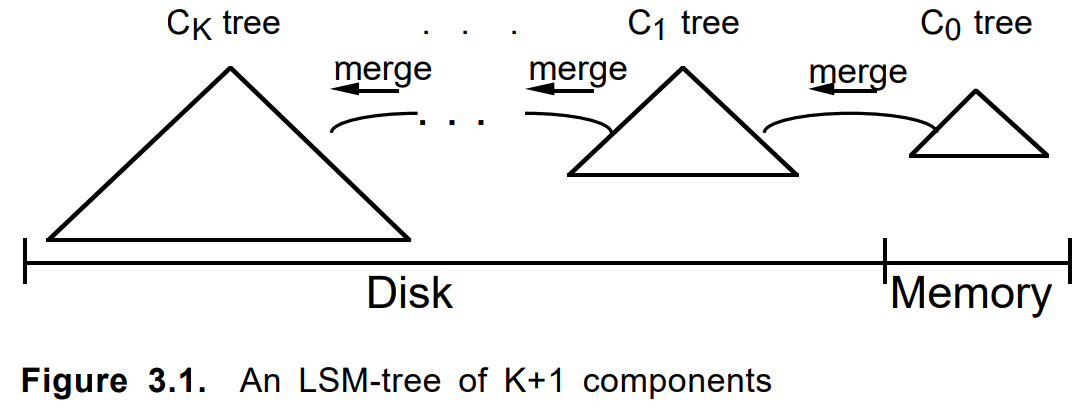
When you add a document first formed in the addon. At its overflow or by other criteria, a constant chunk was built on it. The next few chunks, if necessary, merged into a new one, and the original ones were deleted. Updating a document or deleting it was done in the same way.
Criteria for merging, chain length, traversal algorithm, accounting for deleted items and updates, other parameters tyunilis. The approach itself was used in several similar tasks and took shape as a separate internal LSM framework on pure .net. Around the same time, LevelDB came out and became popular.
The LSM algorithm in our case has very suitable features:
- instant insert / delete / update,
- reduced load on the SSD during the update,
- simplified chunks format,
- selective search only for old / new chunks,
- trivial backup,
- what else do you want.
- ...
In general, bicycles are sometimes useful for self-development.
Macro, micro, nano optimization
And finally, we will share technical advice, as we in Antiplagiat do such things on .Net (and not only on it).
Note in advance that often everything depends very much on your particular hardware, data, or mode of use. Having tightened up in one place, we will take off from the CPU cache, in the other we will rest on the bandwidth of the SATA interface, in the third we will start to hang in the GC. And somewhere and at all in the inefficiency of the implementation of a specific system call.

Image source: Wikipedia
Work with file
The problem with access to the file, we are not unique. There is a terabyte exabyte large file, the size of which is many times greater than the amount of RAM. The task is to read a million scattered over it some small random values. And do it quickly, efficiently and inexpensively. We have to squeeze, benchmark and think a lot.
Let's start with the simple. To read the coveted byte you need:
- Open file (new FileStream);
- Move to the desired position (Position or Seek, no difference);
- Read the desired byte array (Read);
- Close file (Dispose).
And this is bad, because long and dreary. By trial, error and repeated attack on a rake, we identified the following sequence of actions:
Single open, multiple read
If we make this sequence head-on, for each request to the disk, we will be bent very quickly. Each of these points goes into a query to the OS kernel, which is expensive.
Obviously, you should open the file once and read all the millions of our values from it consistently, which we do
Nothing Extra
Getting the size of the file, the current position in it - also quite heavy operations. Even if the file has not changed.
You should avoid any queries like getting the size of the file or the current position in it.
FileStreamPool
Further. Alas, FileStream is essentially single threaded. If you want to read the file in parallel, you will have to create / close new file streams.
Until they create something like aiosync, they will have to reinvent their own bikes.
My advice is to create a pool of file streams per file. This will avoid wasting time opening / closing the file. And if you combine it with ThreadPool and take into account that SSD gives its mega-ops with strong multithreading ... Well, you understood me.
Allocation unit
Further. Data storage devices (HDD, SSD, Optane) and file system operate on block-level files (cluster, sector, allocation unit). They may not coincide, but now it is almost always 4096 bytes. Reading one or two bytes on the border of two such blocks in the SSD is about one and a half times slower than inside the block itself.
You should organize your data so that the elements to be read are within the boundaries of the
cluster sectorcluster.No buffer.
Further. FileStream uses a default buffer of 4096 bytes. And there is bad news - it can not be turned off. However, if you read data larger than the buffer size, the latter will be ignored.
With random reading, you should set the buffer to 1 byte (less will not work) and then assume that it is not used.
Use buffer.
In addition to random readings, there are also sequential ones. Here the buffer may already be useful if you do not want to read everything at once. I advise you to start by referring to this article . What size of the buffer to set, depends on whether the file is on the HDD or on the SSD. In the first case 1MB will be optimal, in the second there will be enough standard 4kB. If the size of the readable data area is comparable with these values, then it is better to read it at once, skipping the buffer, as in the case of random reading. Large buffers will not bring profit in speed, but will start to beat on GC.
When sequentially reading large pieces of a file, set the buffer to 1MB for HDD and 4kB for SSD. Well, it depends.
MMF vs FileStream
In 2011, the targeting to MemoryMappedFile came, since this mechanism was implemented starting from .Net Framework v4.0. At first it was used when caching Bloom's filter, which already caused inconvenience in 32-bit mode due to the 4GB limit. But when moving to the world of 64 bits, I wanted more. The first tests were impressive. Free caching, Freaky speed, user-friendly interface for reading structures. But there were problems:
- First, oddly enough, speed. If the data has already been cached, then everything is ok. But if not, reading one byte from a file was accompanied by “lifting up” a lot more data than it would have been with regular reading.
- Secondly, oddly enough, memory. When warming up, shared memory grows, workingset does not, which is logical. But then the neighboring processes begin to behave not very well. They can go into a swap, or involuntarily fall from OoM. The volume occupied by the MMF in RAM, alas, is impossible to control. And the profit from the cache in the case when the readable file itself is a couple of orders of magnitude more memory becomes meaningless.
The second problem could still be fought. It disappears if the index is working in the docker or on a dedicated virtual machine. But the problem of speed was fatal.
As a result, the MMF was abandoned a little more than completely. Caching in Antiplagiat began to be made explicitly, if possible keeping in memory the most frequently used layers at the given priorities and limits.

Image source: Wikipedia
Bits / Bytes
Not bytes the world is one. Sometimes you need to descend to the level of a bit.
For example: imagine that you have a trillion partially ordered numbers, eager to save and frequent reading. How to work with all this?
- Simple BinaryWriter.Write? - quickly, but slowly. Size does matter. Cold reading primarily depends on the file size.
- Another variation VarInt? - quickly, but slowly. Constancy matters. The volume begins to depend on the data, which requires additional memory for positioning.
- Bitwise packaging? - quickly, but slowly. You have to control your hands even more carefully.
There is no perfect solution, but in a particular case, simple compression of the range from 32 bits to the required storage of tails saved 12% more (tens of GB!) Than VarInt (while preserving only the difference of neighboring ones, of course), and that one - at times from base case.
Another example. You have a link in the file to an array of numbers. Link 64-bit file per terabyte. Everything seems ok. Sometimes there are many numbers in the array, sometimes few. Often a little. Often. Then just take and store the entire array in the link itself. Profit. Pack gently just do not forget.
Struct, unsafe, batching, micro-opts
Well, and other micro-optimizations. I will not write here about the banal "is it worth it to keep the Length of the array in a loop" or "which is faster, for or foreach".
There are two simple rules, and we will follow them: 1. "benchmark everything", 2. "more benchmark".
Struct . Used everywhere. Do not ship GC. And, as it is fashionable today, we also have our megastry ValueList.
Unsafe . Allows you to map (and spread) structures into an array of bytes when used. Thus, we do not need separate means of serialization. There are, however, questions about pinning and heap defragmentation, but it has not yet manifested itself. Well, it depends.
Batching Work with many elements should be through packs / groups / blocks. Read / write file, transfer between functions. A separate question is the size of these packs. Usually there is an optimum, and its size is often in the range from 1kB to 8MB (CPU cache size, cluster size, page size, size of something else). Try to pump through the function IEnumerable <byte> or IEnumerable <byte [1024]> and feel the difference.
Pooling . Every time you write "new", a kitten dies somewhere. Once a new byte [ 85000 ] - and the tractor drove a ton of geese. If it is not possible to use stackalloc, then create a pool of any objects and reuse it again.
Inlining . How can creating two functions instead of one accelerate everything tenfold? Simply. The smaller the size of the body of the function (method), the greater the chance that it will be inline. Unfortunately, in the dotnet world, it is not yet possible to do a partial inlining, so if you have a hot function that, in 99% of cases, goes after processing the first few lines, and the remaining hundred lines go to processing the remaining 1%, then safely break it into two (or three), carrying a heavy tail into a separate function.
What else?
Span <T> , Memory <T> - promising. The code will be simpler and maybe a little faster. We are waiting for the release. Net Core v3.0 and Std v2.1, to go to them, because our kernel on .Net Std v2.0, which doesn’t normally support span.
Async / await is still ambiguous. The simplest benchmarks of random reading showed that CPU consumption is indeed falling, but the reading speed is also decreasing. Must watch. Inside the index is not yet used.
Conclusion
I hope I have the remoteness to give you the pleasure of understanding the beauty of some decisions. We really like our index. It is effective, beautiful code, works fine. A highly specialized solution in the core of the system, the critical place of its work is better than the general one. Our version control system remembers assembler inserts in C ++ code. Now four pluses - only pure C #, only .Net. On it we write even the most complex search algorithms and do not regret it at all. With the advent of .Net Core, the transition to Docker has made the path to a bright DevOps future easier and clearer. Ahead - solving the problem of dynamic shardization and replication without reducing the efficiency and beauty of the solution.
Thanks to everyone who read to the end. About all ochepyatkah and other inconsistencies, please write comments. I will be glad to any reasonable advice and refutations in the comments.
')
Source: https://habr.com/ru/post/445952/
All Articles