Experience in developing the Refund Tool service with an asynchronous API on Kafka
What can make such a big company like Lamoda with a streamlined process and dozens of interrelated services significantly change the approach? The motivation can be completely different: from the legislative to the inherent desire of all programmers to experiment.
But this does not mean that you can not count on additional benefits. What exactly can be won if you implement the events-driven API on Kafka, will tell Sergey Zaika ( fewald ). There will also be about stuffed bumps and interesting discoveries - there is no way to experiment without them.
')
Disclaimer: This article is based on the materials of the mitap that Sergey spent in November 2018 on HighLoad ++. Lamoda’s lively experience of working with Kafka attracted listeners no less than to other reports from the schedule. It seems to us that this is a great example of what you can and should always find like-minded people, and the organizers of HighLoad ++ will continue to try to create an atmosphere conducive to this.
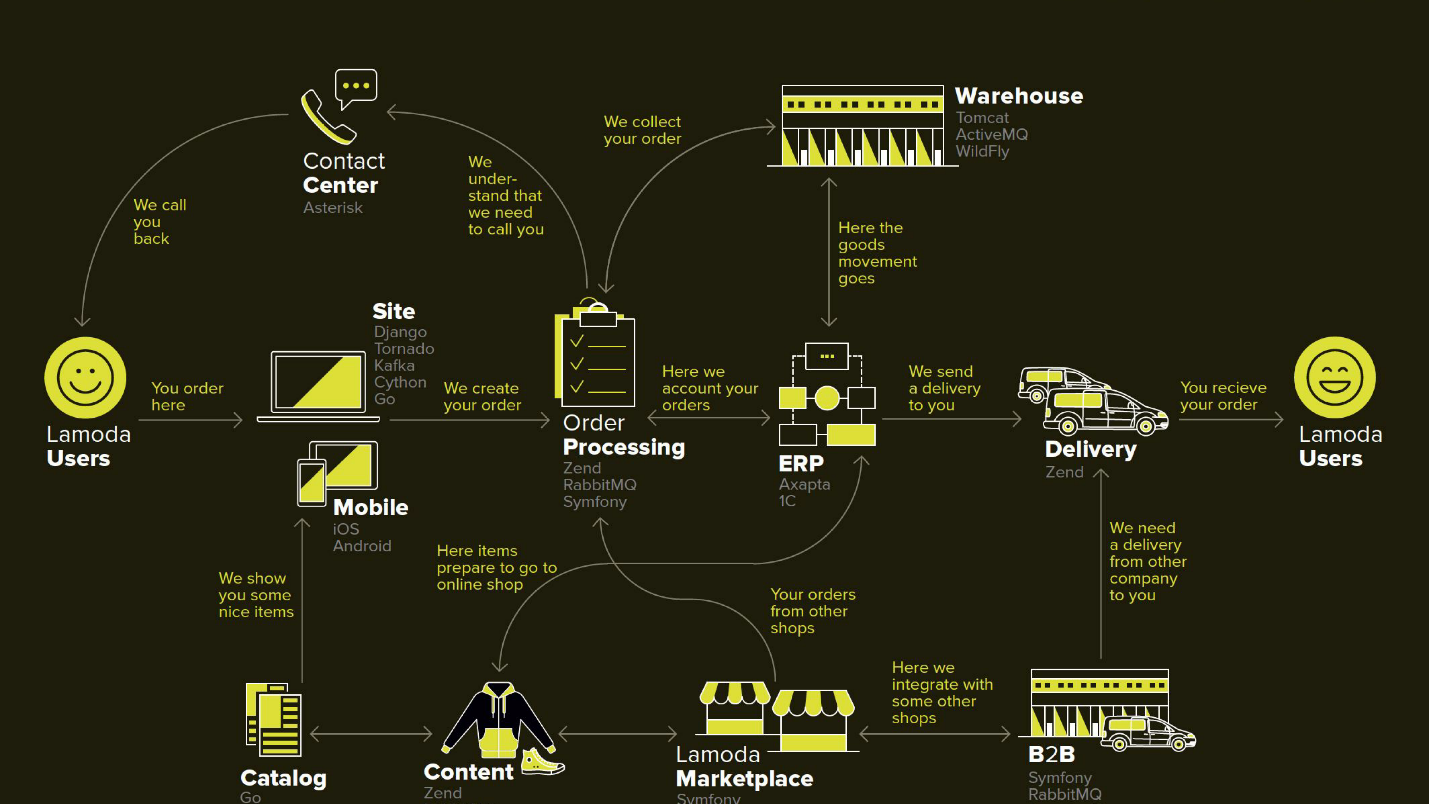
Lamoda is a large e-commerce platform that has its own contact center, a delivery service (and many partnerships), a photo studio, a huge warehouse and it all works on its software. There are dozens of payment methods, b2b-partners who can use part or all of these services and want to know the latest information on their products. In addition, Lamoda works in three countries besides the Russian Federation and everything is a bit different in its own way. In total, there are probably more than a hundred ways to configure a new order, which must be processed in its own way. All this works with the help of dozens of services that sometimes communicate in an unobvious way. There is also a central system, whose main responsibility is the status of orders. We call her BOB, I work with her.
The word events-driven is pretty jaded, a little further we will define in more detail what is meant by this. I will start with the context in which we decided to try out the event-driven API approach in Kafka.

In any store, in addition to orders for which buyers pay, there are times when the store is required to return money, because the goods did not fit the customer. This is a relatively short process: we clarify information, if there is such a need, and transfer money.
But the return became more complicated due to the change of legislation, and we had to implement a separate microservice for it.

Our motivation:

In this diagram, the main Lamoda systems are drawn. Now most of them are more like a constellation of 5-10 microservices around a decreasing monolith . They are slowly growing, but we are trying to make them smaller, because deploying the fragment selected in the middle is scary - we should not allow it to fall. We have to reserve all exchanges (arrows) and pledge that any of them may be unavailable.
There are also quite a lot of exchanges in BOB: payment systems, delivery, notifications, etc.
Technically, BOB is:
Deploying BOB is expensive and painful, the amount of code and the tasks it solves is such that no one can put it in its head entirely. In general, there are many reasons to simplify it.
Initially, two systems are involved in the process: BOB and Payment. Now two more appear:
Now the process looks like this:
As a result, we made a kind of event bus at Kafka - the event-bus, on which everything started. Hooray, now we have a single point of failure (sarcasm).

The pros and cons are pretty obvious. We did the bus, so now all the services depend on it. This simplifies the design, but introduces a single point of failure into the system. Kafka will fall, the process will rise.
A good answer to this question is in the report of Martin Fowler (GOTO 2017) “The Many Meanings of Event-Driven Architecture” .
Briefly, what we have done:
As part of the launch of the Refund Tool, we used the third option. This simplified event handling, since there is no need to extract detailed information, plus eliminated the scenario when each new event generates a surge of refinement get-requests from consumers.
The Refund Tool service is not loaded , so Kafka is more likely to try the pen than the need. I don’t think that if the refund service became a highload project, the business would be happy.
For asynchronous exchanges, the PHP department usually uses RabbitMQ. We collected the data for the request, put it in a queue, and the consumer of the same service counted it and sent it (or did not send it). For the API itself, Lamoda actively uses Swagger. We design API, we describe it in Swagger, we generate client and server code. We also use slightly advanced JSON RPC 2.0.
In some places esb-buses are used, someone lives on activeMQ, but, in general, RabbitMQ is standard .
Designing the exchange through the events-bus, an analogy can be traced. We similarly describe the future exchange of data through the descriptions of the structure of the event. The yaml format, code generation had to be done by ourselves, the generator according to the specification creates DTO and teaches clients and servers to work with them. The generation goes into two languages - golang and php . This allows you to keep libraries consistent. The generator is written in golang, for which he received the name gogi.
Event-sourcing at Kafka is a typical thing. There is a solution from the main enterprise version of Kafka Confluent, there is nakadi , a solution from our “brothers” in the domain domain Zalando. Our motivation to start with vanilla Kafka is to leave the decision free until we finally decide whether we will use it everywhere, and also leave ourselves room for maneuver and improvements: we want support for our JSON RPC 2.0 , generators for two languages and see what else.
It is ironic that even in such a happy case, when there is a similar Zalando business, which made a similar decision, we cannot use it effectively.
Architecturally, at the launch, the pattern is as follows: we read directly from Kafka, but we write only through the events-bus. Kafka has a lot of ready-to-read: brokers, balancers and she is more or less ready for horizontal scaling, I wanted to keep it. Record, we wanted to wrap through one Gateway aka Events-bus, and here's why.
Or a bus event. This is just a stateless http gateway, which assumes several important roles:
We work in a large company with a streamlined process. Why change something? This is an experiment , and we expect to get several benefits.
With Kafka, it is very easy to connect new consumers to the API.
Suppose you have a directory that needs to be kept up to date on several systems at once (and in some new ones). Previously, we invented the bundle that implemented the set-API, and the master system was informed by the addresses of consumers. Now the master system sends updates to the topic, and everyone who is interested in reading. There was a new system - they signed it on the topic. Yes, also bundle, but simpler.
In the case of the refund-tool, which is the essence of a BOB piece, it is convenient for us to keep them synchronized through Kafka. Payment says that the money was returned: BOB, RT found out about it, changed their status, the Fiscalization Service found out about it and knocked out a check.

We have plans to make a single Notifications Service, which would notify the client about the news on his order / returns. Now this responsibility is spread between systems. It will be enough for us to teach Notifications Service to retrieve relevant information from Kafka and react to it (and disable these notifications in other systems). No new direct exchanges are required.
The information between the systems becomes transparent - no matter how “bloody enterprise” you have and no matter how puffy your backlog is. Lamoda has a Data Analytics department that collects data on systems and brings them into a reusable form, both for business and for intelligent systems. Kafka allows you to quickly give them a lot of data and keep this information stream current.
Messages do not disappear after reading, as in RabbitMQ. When an event contains enough information for processing, we have a history of recent changes to the object, and, if desired, the ability to apply these changes.
The shelf life of replication log depends on the intensity of writing to this topic, Kafka allows you to flexibly adjust the limits for storage time and for data volume. For intensive topics, it is important that all consumers have time to read information before it disappears, even in the case of short-term inoperability. Usually it turns out to store data for units of days , which is quite enough for support.
Further a little retelling of the documentation, for those who are not familiar with Kafka (the picture is also from the documentation)
There are queues in AMQP: we write messages to the queue for the concierge. As a rule, one queue is processed by one system with the same business logic. If you need to notify several systems, you can teach the application to write in several queues or configure the exchange with the fanout mechanism, which itself clones them.
In Kafka there is a similar abstraction of the topic , in which you write messages, but they do not disappear after reading. By default, when you connect to Kafka, you get all the messages, and at the same time it is possible to save the place where you stopped. That is, you read sequentially, you may not mark the message as read, but save the id from which you continue reading. The Id at which you stopped is called offset (offset), and the mechanism - commit offset.
Accordingly, it is possible to implement different logic. For example, we have BOB in 4 instances for different countries - Lamoda exists in Russia, Kazakhstan, Ukraine, Belarus. Since they are deployed separately, they have their own configs and their own business logic. We indicate in the message to which country it belongs. Each BOB consumer in each country reads with a different groupId, and, if the message does not apply to it, skip it, i.e. Immediately commit offset +1. If the same topic reads our Payment Service, then it does so with a separate group, and therefore the offset does not overlap.
Event requirements:
We have three Kafka installations:
Today we are talking only about the last paragraph. In the events-bus we have not very large installations - 3 brokers (servers) and only 27 topics. As a rule, one topic is one process. But this is a delicate moment, and now we touch it.
The above rps chart. The process of refunds is marked with a turquoise line (yes, the one that lies on the X axis), and the pink line indicates the process of updating the content.
The Lamoda catalog contains millions of products, and the data is updated all the time. Some collections go out of fashion, new ones are released instead, new models constantly appear in the catalog. We try to predict what will be interesting to our customers tomorrow, so we constantly buy new things, photograph them and update the shop window.
Pink peaks are product update, that is, changes by product. It is evident that the guys took pictures, took pictures, and then again! - downloaded a pack of events.
We use the built architecture for such operations:
Now the more interesting part about stuffed bumps and interesting discoveries that occurred in six months.
Suppose we want to make a new thing - for example, transfer the entire delivery process to Kafka. Now part of the process is implemented in Order Processing at BOB. After the transfer of the order to the delivery service, moving to the intermediate warehouse and other things, there is a status model. There is a whole monolith, even two, plus a bunch of APIs dedicated to delivery. They know much more about delivery.
These seem to be similar areas, but for Order Processing at BOB and for the delivery system, the statuses are different. For example, some courier services do not send intermediate statuses, but only final ones: “delivered” or “lost”. Others, on the contrary, report in great detail on the movement of goods. Everyone has their own validation rules: for someone, email is valid, so it will be processed; for others, it is not valid, but the order will still be processed, because there is a telephone for communication, and someone will say that such an order will not be processed at all.
In the case of Kafka, the question of organizing the data flow arises. This task is connected with the choice of strategy on several points, we will go over all of them.
We have an event specification. In BOB we write that such an order must be delivered, and we indicate: the order number, its composition, some SKU and bar codes, etc. When the goods arrive at the warehouse, the delivery will be able to get the status, timestamps and everything you need. But then we want to receive updates on this data in BOB. We have a reverse process of receiving data from the delivery. Is this the same event? Or is it a separate exchange that deserves a separate topic?
Most likely, they will be very similar, and the temptation to make one topic is not unreasonable, because a separate topic is separate concumers, separate configs, a separate generation of all this. But not a fact.
But if you use the same events, another problem arises. For example, not all delivery systems can generate a DTO that can generate BOBs. We send them an id, but they don’t save them, because they don’t need them, and from the point of view of starting the event-bus process, this field is mandatory.
If we introduce a rule for event-bus that this field is mandatory, then we are forced to set additional validation rules in the BOB or in the handler of the start event. Validation begins to creep away on service - it is not very convenient.
Another problem is the temptation of incremental development. We are told that we need to add something to the event, and maybe, if you think well, it should have been a separate event. But in our scheme, a separate event is a separate topic. A separate topic is the whole process that I described above. The developer is tempted to simply add another field to the JSON schema and regenerate it.
In case of refunds, we came to the event of the event in six months. We had one meta event called refund update, in which there was a type field describing what this update itself actually is. From this, we had “beautiful” switches with validators, who said how to validate this event with this type.
Avro can be used to validate messages in Kafka, but it was necessary to immediately lay it out and use Confluent. In our case, with versioning you have to be careful. It will not always be possible to re-read messages from replication log, because the model has "left." Basically, it turns out to build versions so that the model is backward compatible: for example, to make the field temporarily optional. If the differences are too strong, we start writing in a new topic, and the clients are transplanted when they finish reading the old one.
Topics inside Kafka are divided into partitions. This is not very important while we design entities and exchanges, but it is important when we decide how to conclude and scale this.
In the usual case, you write one topic in Kafka. By default, one partition is used, and all messages from this topic fall into it. And the consumer accordingly sequentially reads these messages. Suppose now that you need to expand the system so that the messages read two different consumer accounts. If you, for example, send SMS, then you can tell Kafka to make an additional partition, and Kafka will begin to decompose the messages into two parts - half there, half here.
How does Kafka divide them? Each message has a body (in which we store JSON) and there is a key. To this key, you can attach a hash function that will determine which partition will get the message.
In our case with refunds, this is important if we take two partitions, then there is a chance that a parallel account will process the second event before the first and there will be trouble. The hash function ensures that messages with the same key fall into the same partition.
This is another problem we are facing. An event is a kind of event: we say that something happened somewhere (something_happened), for example, item canceled or there was a refund. If someone listens to these events, then by “item canceled” the essence of the refund will be created, and “a refund has occurred” will be written somewhere in the setup.
But usually, when you design events, you do not want to write them in vain - you are laying on the fact that someone will read them. It is tempting to write not something_happened (item_canceled, refund_refunded), but something_should_be_done. For example, item is ready to be returned.
On the one hand, it tells you how the event will be used. On the other hand, it is much less like a normal event name. In addition, it is not far from here to the do_something command. But you have no guarantee that someone has read this event; and if read, then read successfully; and if I read successfully, I did something, and this something went well. The moment the event becomes do_something, feedback becomes necessary, and this is a problem.

In the asynchronous exchange in RabbitMQ, when you read the message, went to http, you have a response — at least that the message was received. When you recorded in Kafka, there is a message that you recorded in Kafka, but you know nothing about how it was processed.
Therefore, in our case, we had to enter a response event and set up monitoring on the fact that if so many events took off, after a certain time, the same number of response events should arrive. If this did not happen, then it seems that something went wrong. For example, if we sent the event “item_ready_to_refund”, we expect that the refund will be created, the client will get the money back, the event “money_refunded” will fly to us. But this is not accurate, so monitoring is needed.
There is a fairly obvious problem: if you read from a topic consistently, and you have a bad message, the customer falls and you will not go on. You need to stop all the consummers, commit the offset further to continue reading.
We knew about it, it was laid on it, and still it happened. This happened because the event was valid from the point of view of events-bus, the event was valid from the point of view of the validator of the application, but it was not valid from the point of view of PostgreSQL, because we have UNSIGNED INT in one MySQL system, and The system was PostgreSQL just with int. His size is a little smaller, and Id did not fit. Symfony died with an exception. We, of course, caught the exception, because we laid on it, and were going to commit this offset, but before that we wanted to increment the problem counter, since the message was processed unsuccessfully. The counters in this project are also in the database, and Symfony has already closed communication with the database, and the second exception killed the whole process without a chance to commit the offset.
For a while the service had lain - fortunately, with Kafka it is not so bad, because the messages remain. When work is restored they can be read. It's comfortable.
Kafka has an opportunity through tooling to set an arbitrary offset. But in order to do this, you need to stop all consumer accountants - in our case, prepare a separate release, which will not have consumer accounts, redeployments. Then, with Kafka, tooling can offset the offset, and the message will pass.
Another nuance - replication log vs rdkafka.so - is related to the specifics of our project. We have PHP, and in PHP, as a rule, all the libraries communicate with Kafka via the rdkafka.so repository, and then some kind of wrapper follows. Perhaps these are our personal difficulties, but it turned out that simply re-reading a piece of what has already been read is not so easy. In general, there were software problems.
Coming back to the specifics of working with partitions, consumers are right in the documentation for the >> topic partitions . But I learned about it much later than I would like. If you want to scale and have two consumers, you need at least two partitions. That is, if you had one partition in which 20 thousand messages accumulated, and you made a fresh one, the number of messages will not even out evenly. Therefore, to have two parallel concumer, it is necessary to deal with partitions.
I think, by the way we monitor, it will be even clearer what problems there are in the existing approach.
For example, we consider how many goods in the database have recently changed their status, and, accordingly, events should have happened due to these changes, and send this number to our monitoring system. Kafka , . , .

, , , events-bus , . , Refund Tool , BOB - ( ).

consumer-group lag. , . , 0, . Kafka , .
Burrow , Kafka. API consumer-group , . Failed warning, , — , . , .
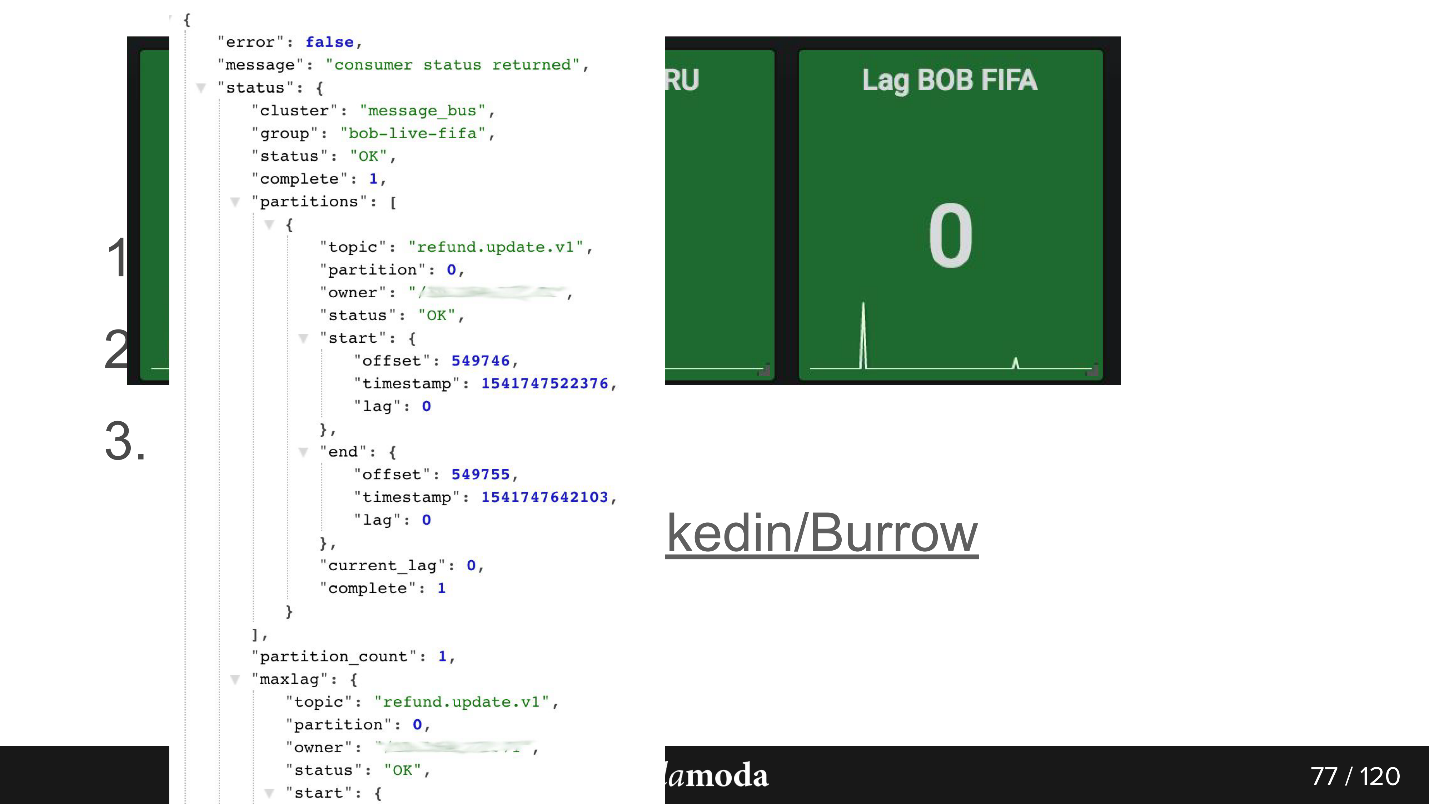
API. bob-live-fifa, partition refund.update.v1, , lag 0 — offset -.
updated_at SLA (stuck) . , , . Cron, , 5 refund ( ), - , . Cron, , 0, .
, , :
But this does not mean that you can not count on additional benefits. What exactly can be won if you implement the events-driven API on Kafka, will tell Sergey Zaika ( fewald ). There will also be about stuffed bumps and interesting discoveries - there is no way to experiment without them.
')
Disclaimer: This article is based on the materials of the mitap that Sergey spent in November 2018 on HighLoad ++. Lamoda’s lively experience of working with Kafka attracted listeners no less than to other reports from the schedule. It seems to us that this is a great example of what you can and should always find like-minded people, and the organizers of HighLoad ++ will continue to try to create an atmosphere conducive to this.
About the process
Lamoda is a large e-commerce platform that has its own contact center, a delivery service (and many partnerships), a photo studio, a huge warehouse and it all works on its software. There are dozens of payment methods, b2b-partners who can use part or all of these services and want to know the latest information on their products. In addition, Lamoda works in three countries besides the Russian Federation and everything is a bit different in its own way. In total, there are probably more than a hundred ways to configure a new order, which must be processed in its own way. All this works with the help of dozens of services that sometimes communicate in an unobvious way. There is also a central system, whose main responsibility is the status of orders. We call her BOB, I work with her.
Refund Tool with events-driven API
The word events-driven is pretty jaded, a little further we will define in more detail what is meant by this. I will start with the context in which we decided to try out the event-driven API approach in Kafka.
In any store, in addition to orders for which buyers pay, there are times when the store is required to return money, because the goods did not fit the customer. This is a relatively short process: we clarify information, if there is such a need, and transfer money.
But the return became more complicated due to the change of legislation, and we had to implement a separate microservice for it.
Our motivation:
- Law FZ-54 - briefly, the law requires you to report to the tax office about every monetary transaction, whether it be a refund or a return, in a rather short SLA in a few minutes. We, as e-commerce, carry out quite a lot of operations. Technically, this means a new responsibility (and therefore a new service) and improvements in all the involved systems.
- BOB split is an internal project of the company to rid BOB of a large number of non-core responsibilities and reduce its total complexity.
In this diagram, the main Lamoda systems are drawn. Now most of them are more like a constellation of 5-10 microservices around a decreasing monolith . They are slowly growing, but we are trying to make them smaller, because deploying the fragment selected in the middle is scary - we should not allow it to fall. We have to reserve all exchanges (arrows) and pledge that any of them may be unavailable.
There are also quite a lot of exchanges in BOB: payment systems, delivery, notifications, etc.
Technically, BOB is:
- ~ 150k lines of code + ~ 100k lines of tests;
- php7.2 + Zend 1 & Symfony Components 3;
- > 100 API & ~ 50 outgoing integrations;
- 4 countries with their business logic.
Deploying BOB is expensive and painful, the amount of code and the tasks it solves is such that no one can put it in its head entirely. In general, there are many reasons to simplify it.
Return process
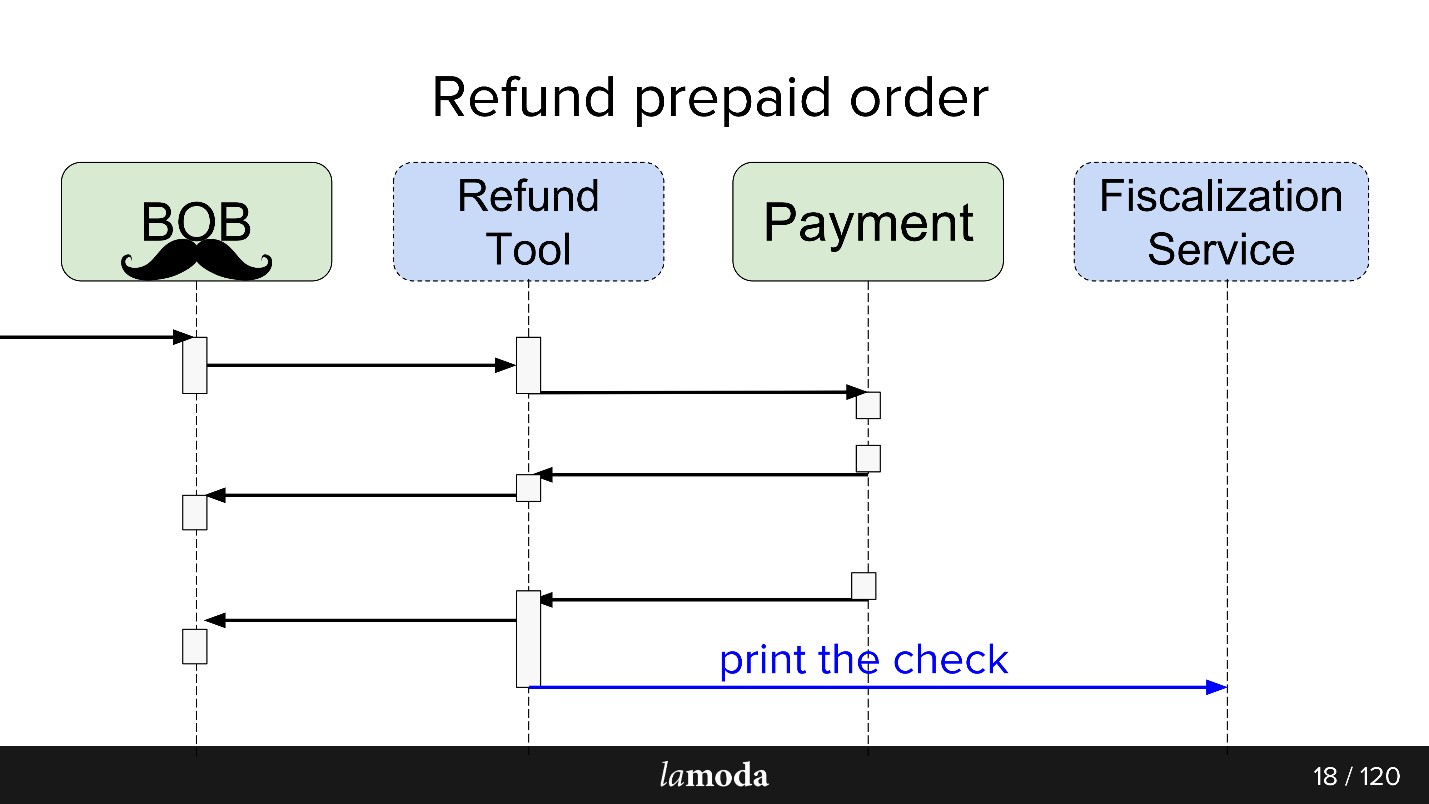
Initially, two systems are involved in the process: BOB and Payment. Now two more appear:
- Fiscalization Service, which will take on problems with fiscalization and communication with external services.
- Refund Tool, in which new exchanges are simply taken out so as not to inflate BOB.
Now the process looks like this:
- To BOB comes a request for a refund.
- BOB talks about this refund tool.
- Refund Tool says Payment: “Return the money.”
- Payment returns money.
- The Refund Tool and BOB synchronize the statuses with each other, because for the time being, both of them need it. We are not yet ready to switch completely to the Refund Tool, since BOB has UI, reports for bookkeeping, and in general a lot of data that you can’t transfer so easily. We have to sit on two chairs.
- The request for fiscalization is leaving.
As a result, we made a kind of event bus at Kafka - the event-bus, on which everything started. Hooray, now we have a single point of failure (sarcasm).
The pros and cons are pretty obvious. We did the bus, so now all the services depend on it. This simplifies the design, but introduces a single point of failure into the system. Kafka will fall, the process will rise.
What is a events-driven API?
A good answer to this question is in the report of Martin Fowler (GOTO 2017) “The Many Meanings of Event-Driven Architecture” .
Briefly, what we have done:
- Wrapped up all asynchronous exchanges via events storage . Instead of reporting the status change to each interested consumer on the network, we write a state change event to the centralized repository, and the consumers interested in the topic read from there everything that appears.
- The event (event) in this case is the notification ( notifications ) that something has changed somewhere. For example, the order status has changed. A consumer who is interested in some kind of accompanying status change data and who is not in the notification can find out their status by himself.
- The maximum option is a full event sourcing, state transfer , in which event contains all the information needed for processing: from where and in what status it was transferred, how exactly the data changed, etc. The only question is expediency and the amount of information you can afford to store.
As part of the launch of the Refund Tool, we used the third option. This simplified event handling, since there is no need to extract detailed information, plus eliminated the scenario when each new event generates a surge of refinement get-requests from consumers.
The Refund Tool service is not loaded , so Kafka is more likely to try the pen than the need. I don’t think that if the refund service became a highload project, the business would be happy.
Async exchange AS IS
For asynchronous exchanges, the PHP department usually uses RabbitMQ. We collected the data for the request, put it in a queue, and the consumer of the same service counted it and sent it (or did not send it). For the API itself, Lamoda actively uses Swagger. We design API, we describe it in Swagger, we generate client and server code. We also use slightly advanced JSON RPC 2.0.
In some places esb-buses are used, someone lives on activeMQ, but, in general, RabbitMQ is standard .
Async exchange TO BE
Designing the exchange through the events-bus, an analogy can be traced. We similarly describe the future exchange of data through the descriptions of the structure of the event. The yaml format, code generation had to be done by ourselves, the generator according to the specification creates DTO and teaches clients and servers to work with them. The generation goes into two languages - golang and php . This allows you to keep libraries consistent. The generator is written in golang, for which he received the name gogi.
Event-sourcing at Kafka is a typical thing. There is a solution from the main enterprise version of Kafka Confluent, there is nakadi , a solution from our “brothers” in the domain domain Zalando. Our motivation to start with vanilla Kafka is to leave the decision free until we finally decide whether we will use it everywhere, and also leave ourselves room for maneuver and improvements: we want support for our JSON RPC 2.0 , generators for two languages and see what else.
It is ironic that even in such a happy case, when there is a similar Zalando business, which made a similar decision, we cannot use it effectively.
Architecturally, at the launch, the pattern is as follows: we read directly from Kafka, but we write only through the events-bus. Kafka has a lot of ready-to-read: brokers, balancers and she is more or less ready for horizontal scaling, I wanted to keep it. Record, we wanted to wrap through one Gateway aka Events-bus, and here's why.
Events-bus
Or a bus event. This is just a stateless http gateway, which assumes several important roles:
- Production validation - we check that events meet our specification.
- The master system for events , that is, it is the main and only system in the company that answers the question, which events with which structures are considered valid. Validation includes simply data types and enums for tight content specifications.
- Hash-function for sharding - the structure of the Kafka message is key-value, and now, according to the hash, the key calculates where to put it.
Why
We work in a large company with a streamlined process. Why change something? This is an experiment , and we expect to get several benefits.
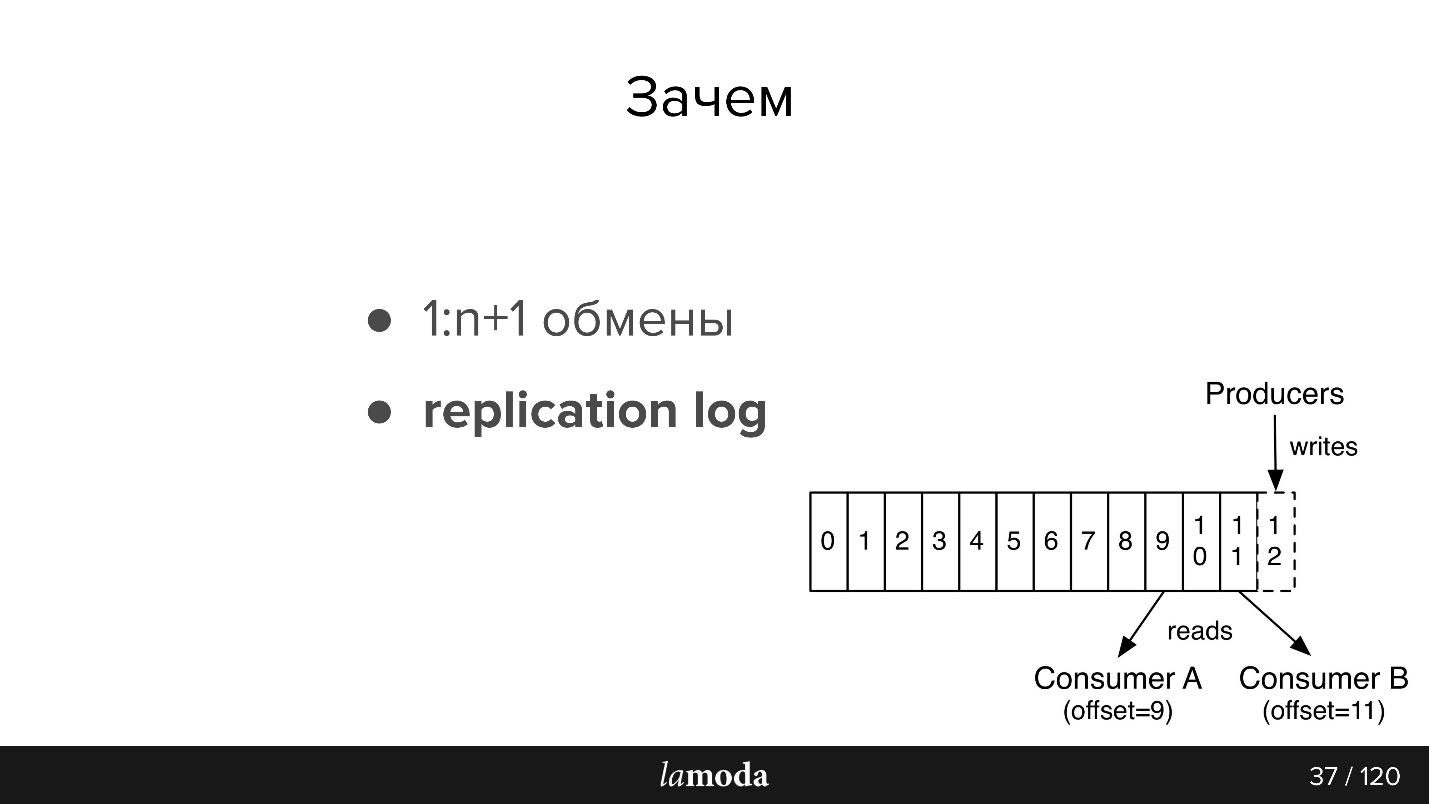
1: n + 1 exchanges (one to many)
With Kafka, it is very easy to connect new consumers to the API.
Suppose you have a directory that needs to be kept up to date on several systems at once (and in some new ones). Previously, we invented the bundle that implemented the set-API, and the master system was informed by the addresses of consumers. Now the master system sends updates to the topic, and everyone who is interested in reading. There was a new system - they signed it on the topic. Yes, also bundle, but simpler.
In the case of the refund-tool, which is the essence of a BOB piece, it is convenient for us to keep them synchronized through Kafka. Payment says that the money was returned: BOB, RT found out about it, changed their status, the Fiscalization Service found out about it and knocked out a check.
We have plans to make a single Notifications Service, which would notify the client about the news on his order / returns. Now this responsibility is spread between systems. It will be enough for us to teach Notifications Service to retrieve relevant information from Kafka and react to it (and disable these notifications in other systems). No new direct exchanges are required.
Data driven
The information between the systems becomes transparent - no matter how “bloody enterprise” you have and no matter how puffy your backlog is. Lamoda has a Data Analytics department that collects data on systems and brings them into a reusable form, both for business and for intelligent systems. Kafka allows you to quickly give them a lot of data and keep this information stream current.
Replication log
Messages do not disappear after reading, as in RabbitMQ. When an event contains enough information for processing, we have a history of recent changes to the object, and, if desired, the ability to apply these changes.
The shelf life of replication log depends on the intensity of writing to this topic, Kafka allows you to flexibly adjust the limits for storage time and for data volume. For intensive topics, it is important that all consumers have time to read information before it disappears, even in the case of short-term inoperability. Usually it turns out to store data for units of days , which is quite enough for support.
Further a little retelling of the documentation, for those who are not familiar with Kafka (the picture is also from the documentation)
There are queues in AMQP: we write messages to the queue for the concierge. As a rule, one queue is processed by one system with the same business logic. If you need to notify several systems, you can teach the application to write in several queues or configure the exchange with the fanout mechanism, which itself clones them.
In Kafka there is a similar abstraction of the topic , in which you write messages, but they do not disappear after reading. By default, when you connect to Kafka, you get all the messages, and at the same time it is possible to save the place where you stopped. That is, you read sequentially, you may not mark the message as read, but save the id from which you continue reading. The Id at which you stopped is called offset (offset), and the mechanism - commit offset.
Accordingly, it is possible to implement different logic. For example, we have BOB in 4 instances for different countries - Lamoda exists in Russia, Kazakhstan, Ukraine, Belarus. Since they are deployed separately, they have their own configs and their own business logic. We indicate in the message to which country it belongs. Each BOB consumer in each country reads with a different groupId, and, if the message does not apply to it, skip it, i.e. Immediately commit offset +1. If the same topic reads our Payment Service, then it does so with a separate group, and therefore the offset does not overlap.
Event requirements:
- Completeness of data. I wish there was enough data in the event so that it could be processed.
- Integrity. We delegate Events-bus to check that the event is consistent and can handle it.
- The order is important. In the case of a return, we are forced to work with history. With notifications, the order is not important, if it is homogeneous notifications, the email will be the same no matter which order arrived first. In the case of a return there is a clear process, if you change the order, then exceptions will occur, the refund will not be created or will not be processed - we will fall into another status.
- Consistency We have a repository, and now instead of the API we create events. We need a way to quickly and cheaply transfer to our services information about new events and about changes in existing ones. This is achieved by using a common specification in a separate git repository and code generator. Therefore, clients and servers in different services are agreed with us.
Kafka in Lamoda
We have three Kafka installations:
- Logs;
- R & D;
- Events-bus.
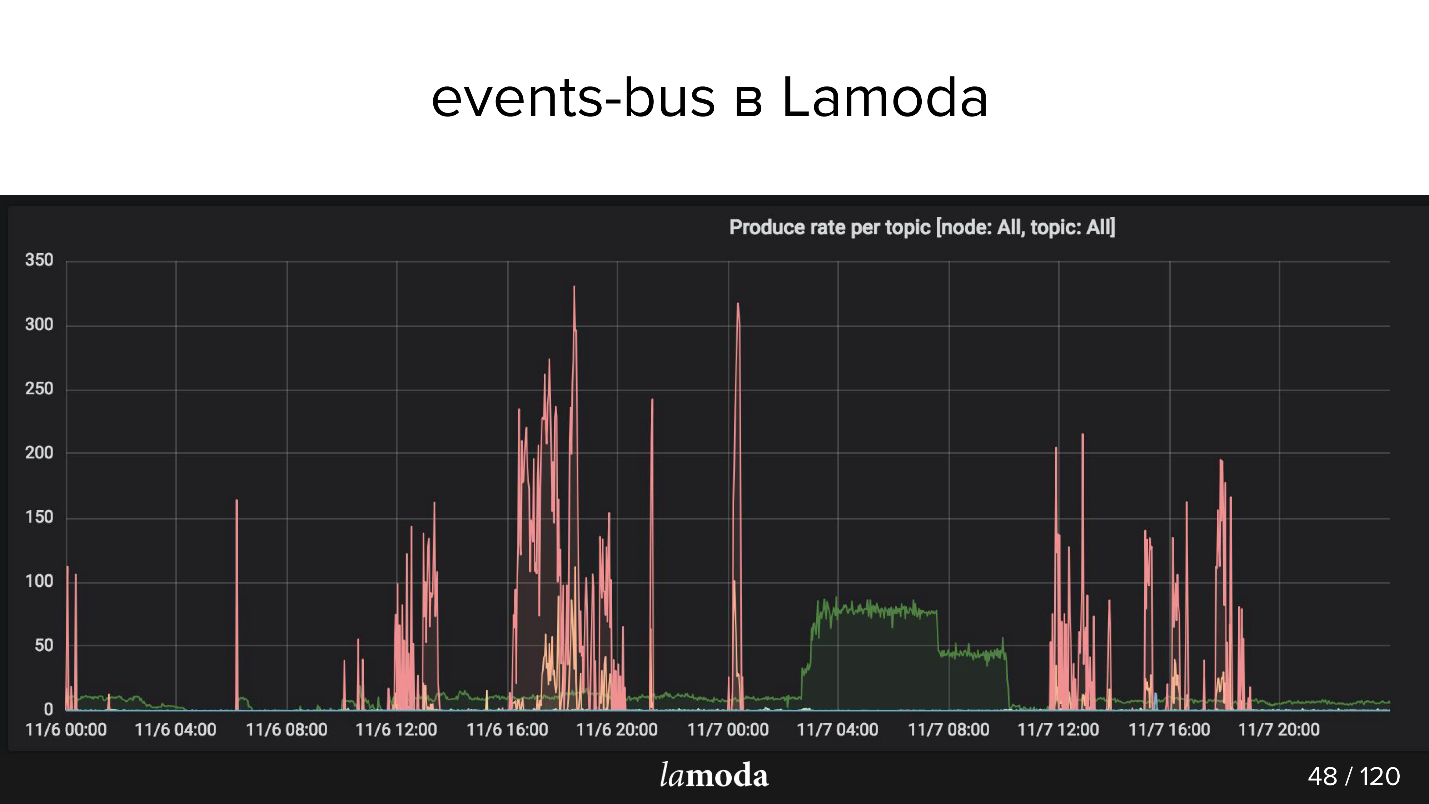
Today we are talking only about the last paragraph. In the events-bus we have not very large installations - 3 brokers (servers) and only 27 topics. As a rule, one topic is one process. But this is a delicate moment, and now we touch it.
The above rps chart. The process of refunds is marked with a turquoise line (yes, the one that lies on the X axis), and the pink line indicates the process of updating the content.
The Lamoda catalog contains millions of products, and the data is updated all the time. Some collections go out of fashion, new ones are released instead, new models constantly appear in the catalog. We try to predict what will be interesting to our customers tomorrow, so we constantly buy new things, photograph them and update the shop window.
Pink peaks are product update, that is, changes by product. It is evident that the guys took pictures, took pictures, and then again! - downloaded a pack of events.
Lamoda Events use cases
We use the built architecture for such operations:
- Return status tracking : call-to-action and status tracking from all involved systems. Payment, statuses, fiscalization, notifications. Here we tried the approach, made the tools, collected all the bugs, wrote the documentation and told colleagues how to use it.
- Update product cards: configuration, meta-data, characteristics. Reads one system (which displays), and write a few.
- Email, push and sms : order is assembled, order is reached, return is accepted, etc., there are a lot of them.
- Stock, warehouse update - quantitative update of items, just numbers: delivery to the warehouse, return. It is necessary that all systems associated with the reservation of goods, operated with the most relevant data. Now the system of updating the drain is quite complicated, Kafka will allow to simplify it.
- Data Analysis (R & D department), ML-tools, analytics, statistics. We want the information to be transparent - for this Kafka is well suited.
Now the more interesting part about stuffed bumps and interesting discoveries that occurred in six months.
Design problems
Suppose we want to make a new thing - for example, transfer the entire delivery process to Kafka. Now part of the process is implemented in Order Processing at BOB. After the transfer of the order to the delivery service, moving to the intermediate warehouse and other things, there is a status model. There is a whole monolith, even two, plus a bunch of APIs dedicated to delivery. They know much more about delivery.
These seem to be similar areas, but for Order Processing at BOB and for the delivery system, the statuses are different. For example, some courier services do not send intermediate statuses, but only final ones: “delivered” or “lost”. Others, on the contrary, report in great detail on the movement of goods. Everyone has their own validation rules: for someone, email is valid, so it will be processed; for others, it is not valid, but the order will still be processed, because there is a telephone for communication, and someone will say that such an order will not be processed at all.
Data stream
In the case of Kafka, the question of organizing the data flow arises. This task is connected with the choice of strategy on several points, we will go over all of them.
In one topic or in different?
We have an event specification. In BOB we write that such an order must be delivered, and we indicate: the order number, its composition, some SKU and bar codes, etc. When the goods arrive at the warehouse, the delivery will be able to get the status, timestamps and everything you need. But then we want to receive updates on this data in BOB. We have a reverse process of receiving data from the delivery. Is this the same event? Or is it a separate exchange that deserves a separate topic?
Most likely, they will be very similar, and the temptation to make one topic is not unreasonable, because a separate topic is separate concumers, separate configs, a separate generation of all this. But not a fact.
New field or new event?
But if you use the same events, another problem arises. For example, not all delivery systems can generate a DTO that can generate BOBs. We send them an id, but they don’t save them, because they don’t need them, and from the point of view of starting the event-bus process, this field is mandatory.
If we introduce a rule for event-bus that this field is mandatory, then we are forced to set additional validation rules in the BOB or in the handler of the start event. Validation begins to creep away on service - it is not very convenient.
Another problem is the temptation of incremental development. We are told that we need to add something to the event, and maybe, if you think well, it should have been a separate event. But in our scheme, a separate event is a separate topic. A separate topic is the whole process that I described above. The developer is tempted to simply add another field to the JSON schema and regenerate it.
In case of refunds, we came to the event of the event in six months. We had one meta event called refund update, in which there was a type field describing what this update itself actually is. From this, we had “beautiful” switches with validators, who said how to validate this event with this type.
Event versioning
Avro can be used to validate messages in Kafka, but it was necessary to immediately lay it out and use Confluent. In our case, with versioning you have to be careful. It will not always be possible to re-read messages from replication log, because the model has "left." Basically, it turns out to build versions so that the model is backward compatible: for example, to make the field temporarily optional. If the differences are too strong, we start writing in a new topic, and the clients are transplanted when they finish reading the old one.
Guaranteed reading order partitions
Topics inside Kafka are divided into partitions. This is not very important while we design entities and exchanges, but it is important when we decide how to conclude and scale this.
In the usual case, you write one topic in Kafka. By default, one partition is used, and all messages from this topic fall into it. And the consumer accordingly sequentially reads these messages. Suppose now that you need to expand the system so that the messages read two different consumer accounts. If you, for example, send SMS, then you can tell Kafka to make an additional partition, and Kafka will begin to decompose the messages into two parts - half there, half here.
How does Kafka divide them? Each message has a body (in which we store JSON) and there is a key. To this key, you can attach a hash function that will determine which partition will get the message.
In our case with refunds, this is important if we take two partitions, then there is a chance that a parallel account will process the second event before the first and there will be trouble. The hash function ensures that messages with the same key fall into the same partition.
Events vs commands
This is another problem we are facing. An event is a kind of event: we say that something happened somewhere (something_happened), for example, item canceled or there was a refund. If someone listens to these events, then by “item canceled” the essence of the refund will be created, and “a refund has occurred” will be written somewhere in the setup.
But usually, when you design events, you do not want to write them in vain - you are laying on the fact that someone will read them. It is tempting to write not something_happened (item_canceled, refund_refunded), but something_should_be_done. For example, item is ready to be returned.
On the one hand, it tells you how the event will be used. On the other hand, it is much less like a normal event name. In addition, it is not far from here to the do_something command. But you have no guarantee that someone has read this event; and if read, then read successfully; and if I read successfully, I did something, and this something went well. The moment the event becomes do_something, feedback becomes necessary, and this is a problem.
In the asynchronous exchange in RabbitMQ, when you read the message, went to http, you have a response — at least that the message was received. When you recorded in Kafka, there is a message that you recorded in Kafka, but you know nothing about how it was processed.
Therefore, in our case, we had to enter a response event and set up monitoring on the fact that if so many events took off, after a certain time, the same number of response events should arrive. If this did not happen, then it seems that something went wrong. For example, if we sent the event “item_ready_to_refund”, we expect that the refund will be created, the client will get the money back, the event “money_refunded” will fly to us. But this is not accurate, so monitoring is needed.
Nuances
There is a fairly obvious problem: if you read from a topic consistently, and you have a bad message, the customer falls and you will not go on. You need to stop all the consummers, commit the offset further to continue reading.
We knew about it, it was laid on it, and still it happened. This happened because the event was valid from the point of view of events-bus, the event was valid from the point of view of the validator of the application, but it was not valid from the point of view of PostgreSQL, because we have UNSIGNED INT in one MySQL system, and The system was PostgreSQL just with int. His size is a little smaller, and Id did not fit. Symfony died with an exception. We, of course, caught the exception, because we laid on it, and were going to commit this offset, but before that we wanted to increment the problem counter, since the message was processed unsuccessfully. The counters in this project are also in the database, and Symfony has already closed communication with the database, and the second exception killed the whole process without a chance to commit the offset.
For a while the service had lain - fortunately, with Kafka it is not so bad, because the messages remain. When work is restored they can be read. It's comfortable.
Kafka has an opportunity through tooling to set an arbitrary offset. But in order to do this, you need to stop all consumer accountants - in our case, prepare a separate release, which will not have consumer accounts, redeployments. Then, with Kafka, tooling can offset the offset, and the message will pass.
Another nuance - replication log vs rdkafka.so - is related to the specifics of our project. We have PHP, and in PHP, as a rule, all the libraries communicate with Kafka via the rdkafka.so repository, and then some kind of wrapper follows. Perhaps these are our personal difficulties, but it turned out that simply re-reading a piece of what has already been read is not so easy. In general, there were software problems.
Coming back to the specifics of working with partitions, consumers are right in the documentation for the >> topic partitions . But I learned about it much later than I would like. If you want to scale and have two consumers, you need at least two partitions. That is, if you had one partition in which 20 thousand messages accumulated, and you made a fresh one, the number of messages will not even out evenly. Therefore, to have two parallel concumer, it is necessary to deal with partitions.
Monitoring
I think, by the way we monitor, it will be even clearer what problems there are in the existing approach.
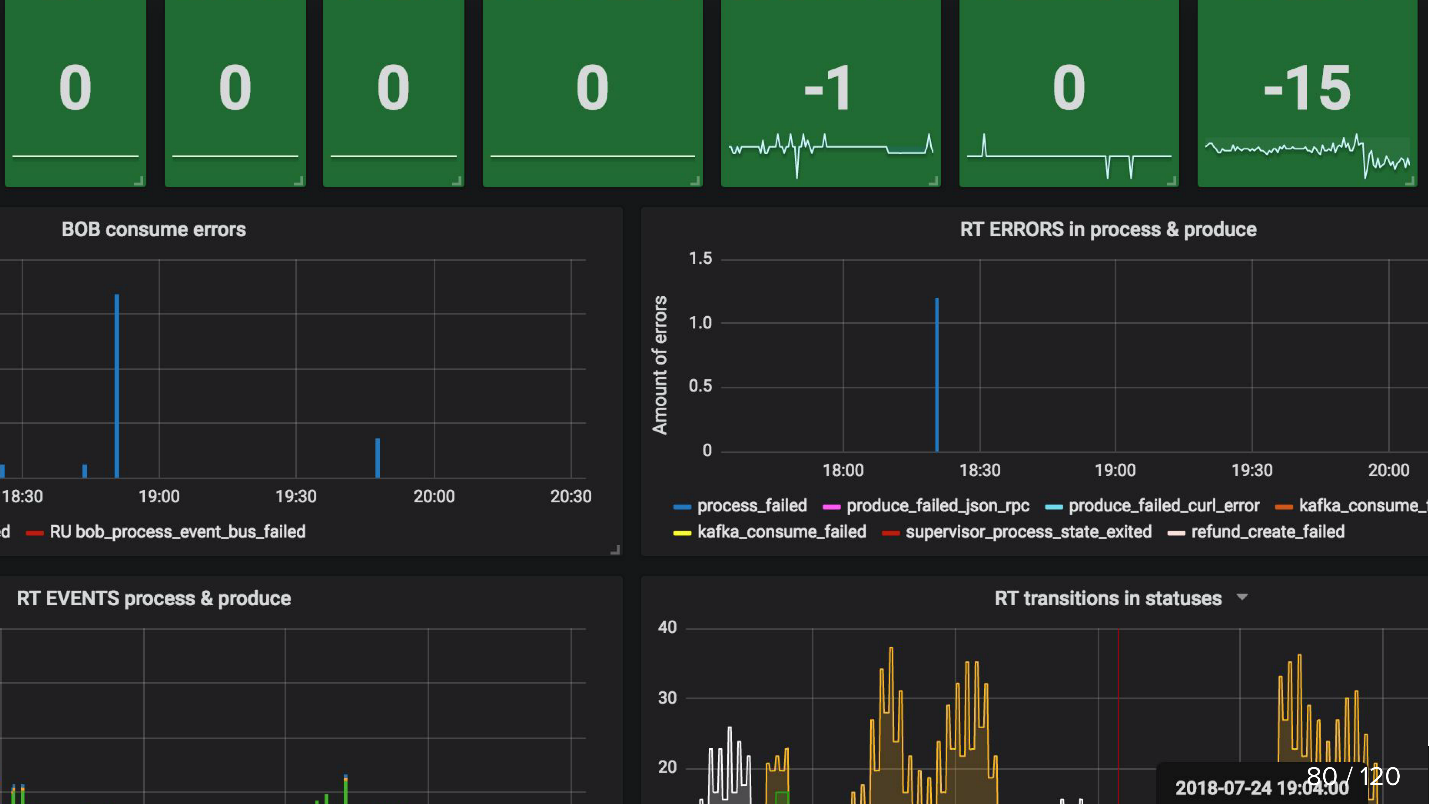
For example, we consider how many goods in the database have recently changed their status, and, accordingly, events should have happened due to these changes, and send this number to our monitoring system. Kafka , . , .
, , , events-bus , . , Refund Tool , BOB - ( ).
consumer-group lag. , . , 0, . Kafka , .
Burrow , Kafka. API consumer-group , . Failed warning, , — , . , .
API. bob-live-fifa, partition refund.update.v1, , lag 0 — offset -.
updated_at SLA (stuck) . , , . Cron, , 5 refund ( ), - , . Cron, , 0, .
, , :
- ;
- ;
- .
, — API Kafka, .
-, HighLoad++ , , .
-, KnowledgeConf . , 26 , .
PHP Russia ++ ( DevOpsConf ) — , .
Source: https://habr.com/ru/post/445424/
All Articles