TSDB Analysis in Prometheus 2

The time series database (TSDB, time series database) in Prometheus 2 is an excellent example of an engineering solution that offers significant improvements in comparison with the v2 storage in Prometheus 1 in terms of data acquisition and query performance, resource efficiency. We implemented Prometheus 2 in Percona Monitoring and Management (PMM), and I had the opportunity to deal with the performance of Prometheus 2 TSDB. In this article I will talk about the results of these observations.
Medium Prometheus workload
For those who are used to dealing with general-purpose databases, the usual Prometheus workload is rather curious. The rate of data accumulation tends to a stable value: usually the services that you monitor send approximately the same number of metrics, and the infrastructure changes relatively slowly.
Requests for information may come from different sources. Some of them, such as alerts, also tend to be stable and predictable. Others, such as user requests, can cause bursts, although this is not typical of most of the workload.
')
Load test
During testing, I focused on the ability to accumulate data. I deployed Prometheus 2.3.2 compiled with Go 1.10.1 (as part of PMM 1.14) on the Linode service using this script: StackScript . For the most realistic load generation, with the help of this StackScript I launched several MySQL nodes with real load (Sysbench TPC-C Test), each of which emulated 10 Linux / MySQL nodes.
All of the following tests were performed on a Linode server with eight virtual cores and 32 GB of memory running 20 load simulations of monitoring two hundred MySQL instances. Or, in terms of Prometheus, 800 targets (targets), 440 charges (scrapes) per second, 380 thousand records (samples) per second and 1.7 million active time series.
Design
The conventional approach to traditional databases, including the one that used Prometheus 1.x, is to limit the memory . If it is not enough to withstand the load, you will encounter large delays, and some requests will not be fulfilled.
Memory usage in Prometheus 2 is configured via the
storage.tsdb.min-block-duration key, which determines how long the recordings will be stored in memory before being flushed to disk (the default is 2 hours). The amount of memory needed will depend on the number of time series, labels, and the intensity of data collection (scrapes) in total with the net incoming flow. In terms of disk space, Prometheus tends to use 3 bytes per record (sample). On the other hand, the memory requirements are much higher.Although it is possible to configure the block size, it is not recommended to adjust it manually, so you are faced with the need to give Prometheus as much memory as it asks for your load.
If there is not enough memory to support the incoming flow of metrics, Prometheus will drop from out of memory or OOM killer will get to it.
Adding a swap to delay the fall, when Prometheus runs out of memory, doesn’t really help, because using this feature causes explosive memory consumption. I think it's about Go, his garbage collector and how he works with swap.
Another interesting approach is setting the reset of the head block to the disk at a certain time, instead of counting it from the start of the process.
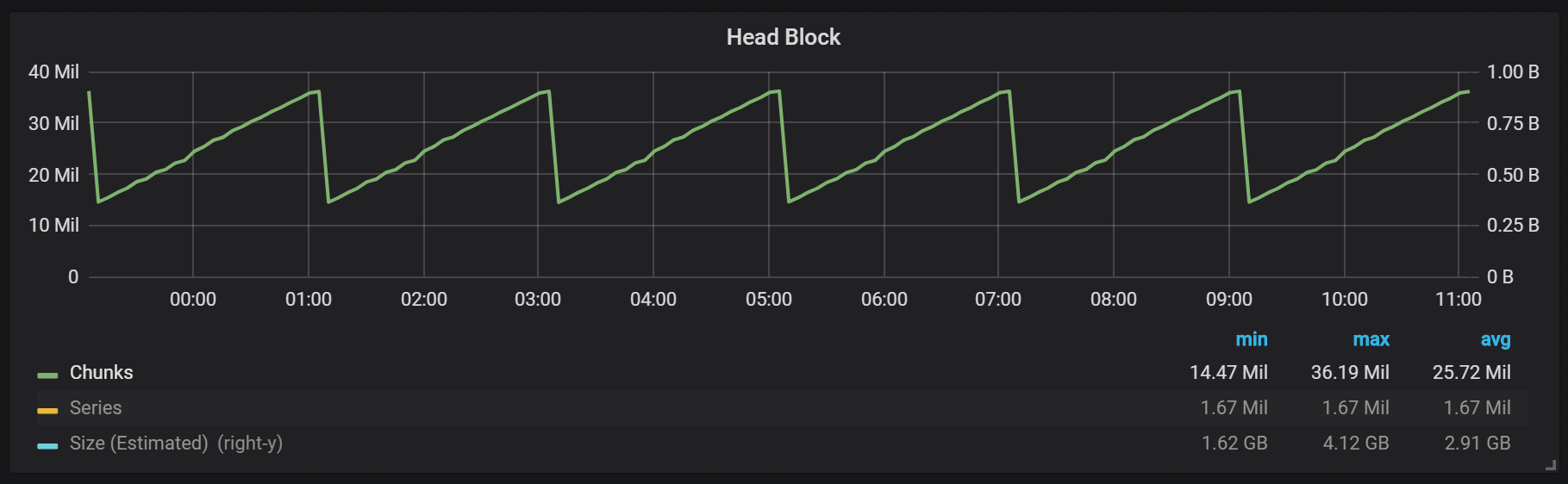
As you can see from the graph, flushes to disk occur every two hours. If you change the min-block-duration parameter for one hour, then these drops will occur every hour, starting in half an hour.
If you want to use this and other graphs in your Prometheus installation, you can use this dashboard . It was designed for PMM, but, with minor modifications, fits any Prometheus installation.
We have an active block, called a head block, which is stored in memory; blocks with older data are available via
mmap() . This removes the need to configure the cache separately, but also means that you need to leave enough space for the operating system cache if you want to make requests to data older than those that the head block holds.And it also means that the consumption of Prometheus virtual memory will look quite high, which is not worth worrying about.

Another interesting design point is the use of WAL (write ahead log). As can be seen from the documentation on the repository, Prometheus uses WAL to avoid losses during falls. Specific mechanisms to ensure data survivability, unfortunately, are not well documented. Prometheus version 2.3.2 resets WAL to disk every 10 seconds, and this parameter is not user configurable.
Seals (Compactions)
Prometheus TSDB is designed in the same way as LSM storage (Log Structured merge - log-structured tree with merge): the head block is flushed periodically to disk, while the compaction mechanism combines several blocks together to avoid scanning too many blocks when queried. Here you can see the number of blocks that I observed on the test system after a day of load.
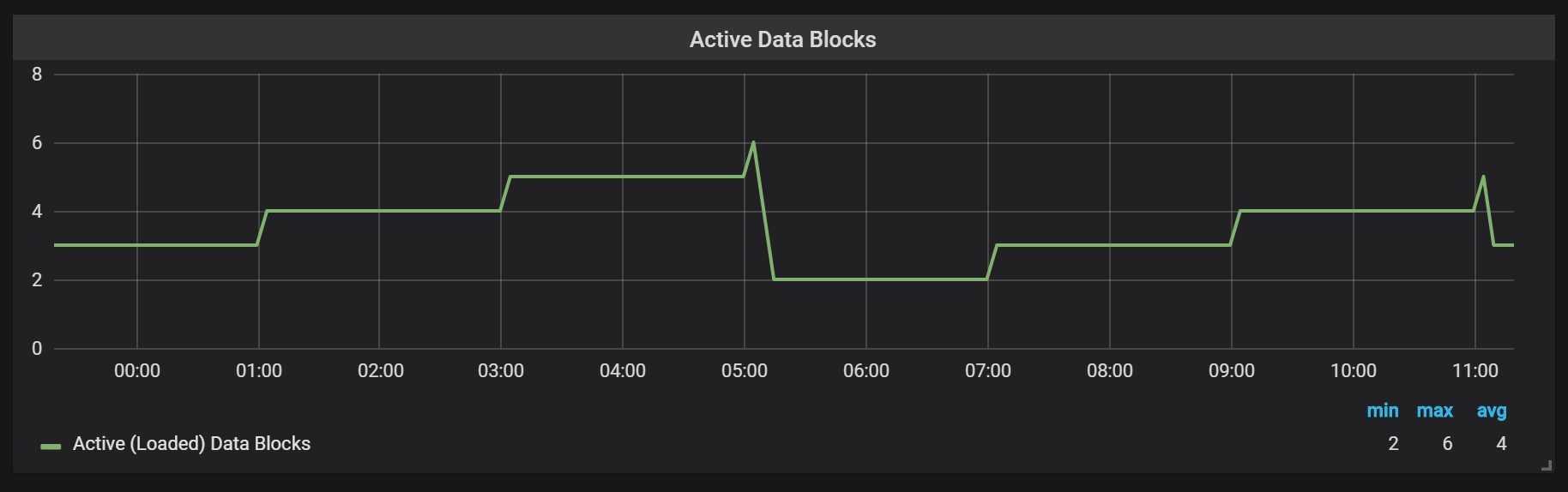
If you want to learn more about the repository, you can examine the meta.json file, which has information about the available blocks and how they appeared.
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 } Prometheus seals are tied to the time the head block is flushed to disk. At this point there may be several such operations.
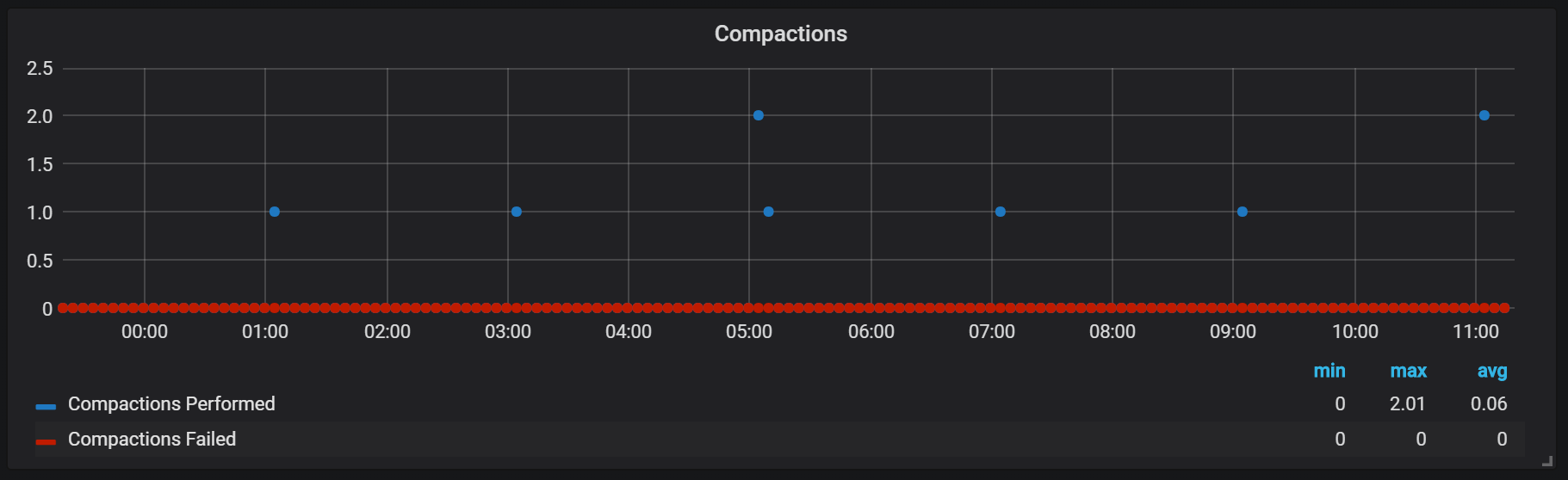
Apparently, seals are in no way limited and can cause large disk I / O jumps during execution.

CPU downloads

Of course, this rather negatively affects the speed of the system, and is also a serious challenge for LSM storages: how to make seals to support high-speed queries and at the same time not cause a too strong overhead?
Memory usage in the process of seals also looks pretty curious.

We can see how, after compression, most of the memory changes its state from Cached to Free: it means that potentially valuable information was removed from there. It is curious whether
fadvice() or some other minimization technique is used here, or is it caused by the fact that the cache was freed from the blocks destroyed during compaction?Disaster recovery
Recovery from failure takes time, and it is justified. For an incoming stream of one million records per second, I had to wait about 25 minutes while the recovery was taking into account the SSD disk.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests." The main problem of the recovery process is high memory consumption. Despite the fact that in a normal situation, the server can work stably with the same amount of memory, if it falls, it may not rise due to OOM. The only solution I found was to disable data collection, raise the server, allow it to recover and reboot already with the collection turned on.
Warming up
Another behavior that should be remembered during warm-up is the ratio of low productivity and high resource consumption right after the start. During some, but not all starts, I observed a serious load on the CPU and memory.
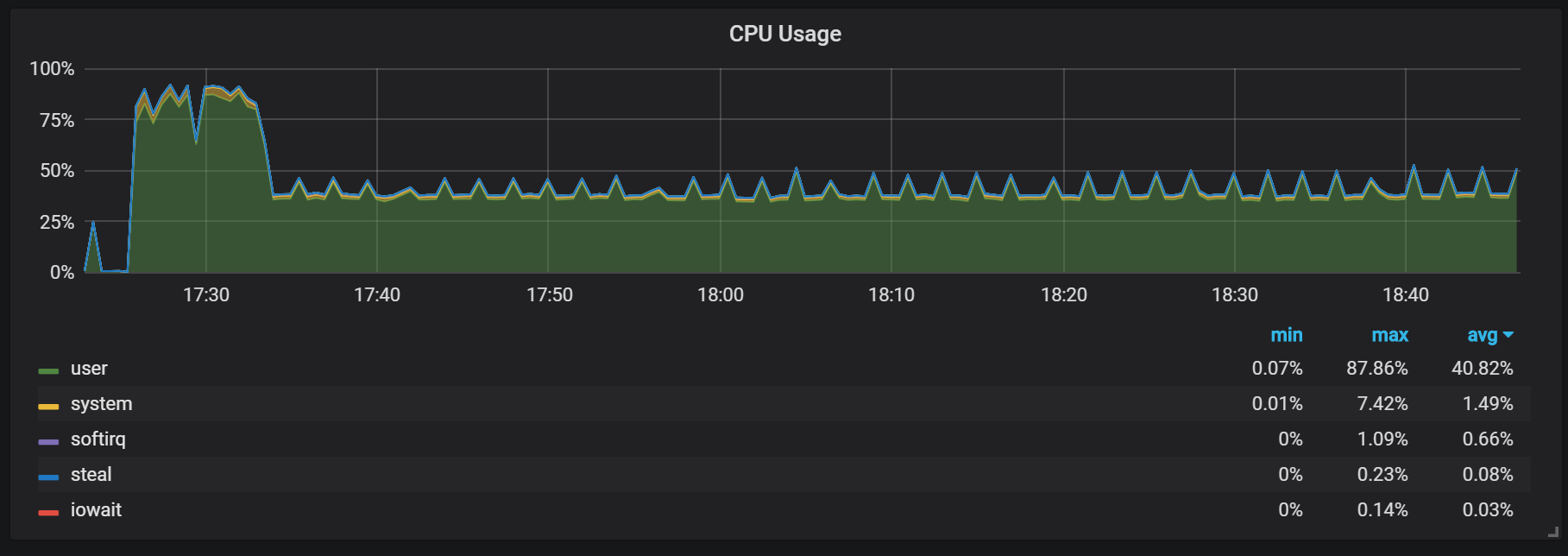

Memory failures suggest that Prometheus cannot configure all charges from the start, and some information is lost.
I did not find out the exact reasons for the high load on the processor and memory. I suspect that this is due to the creation of new time series in the head block with a high frequency.
CPU load jumps
In addition to the seals, which create a rather high I / O load, I noticed serious processor load jumps every two minutes. The bursts last longer with high incoming flow and it looks like they are caused by the Go garbage collector, at least some of the cores are fully loaded.

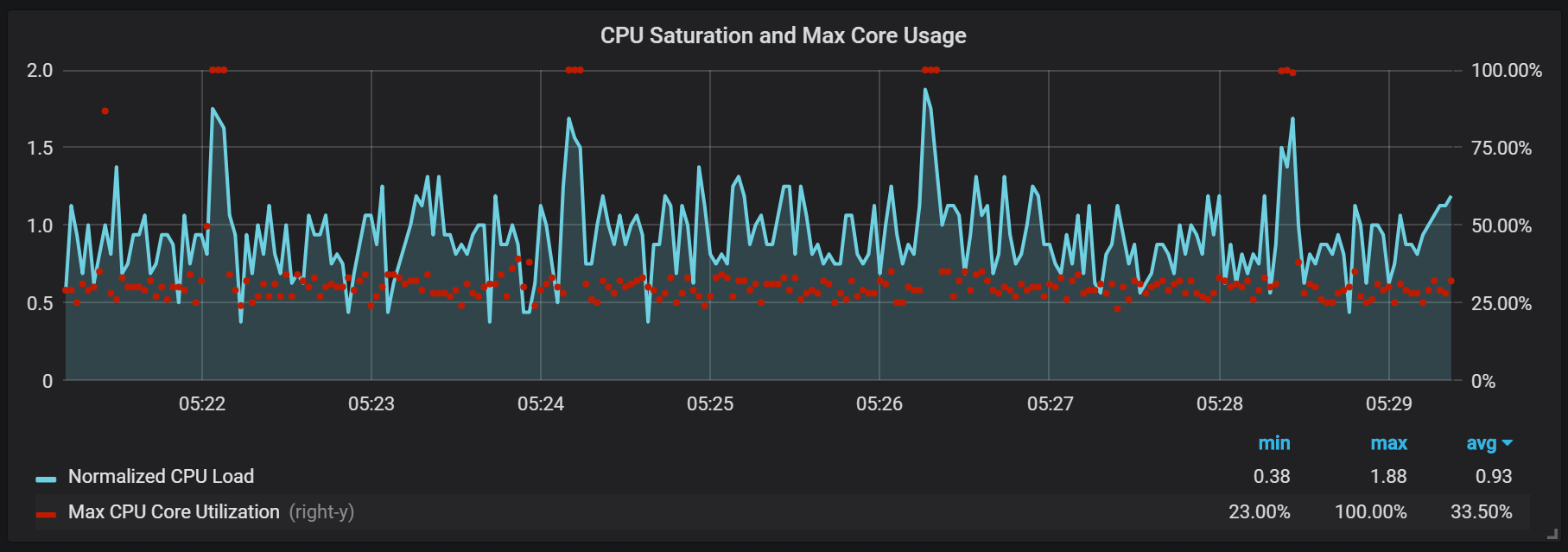
These races are not so insignificant. It appears that when they occur, the internal entry point and the Prometheus metrics become inaccessible, which causes data gaps at the same time intervals.
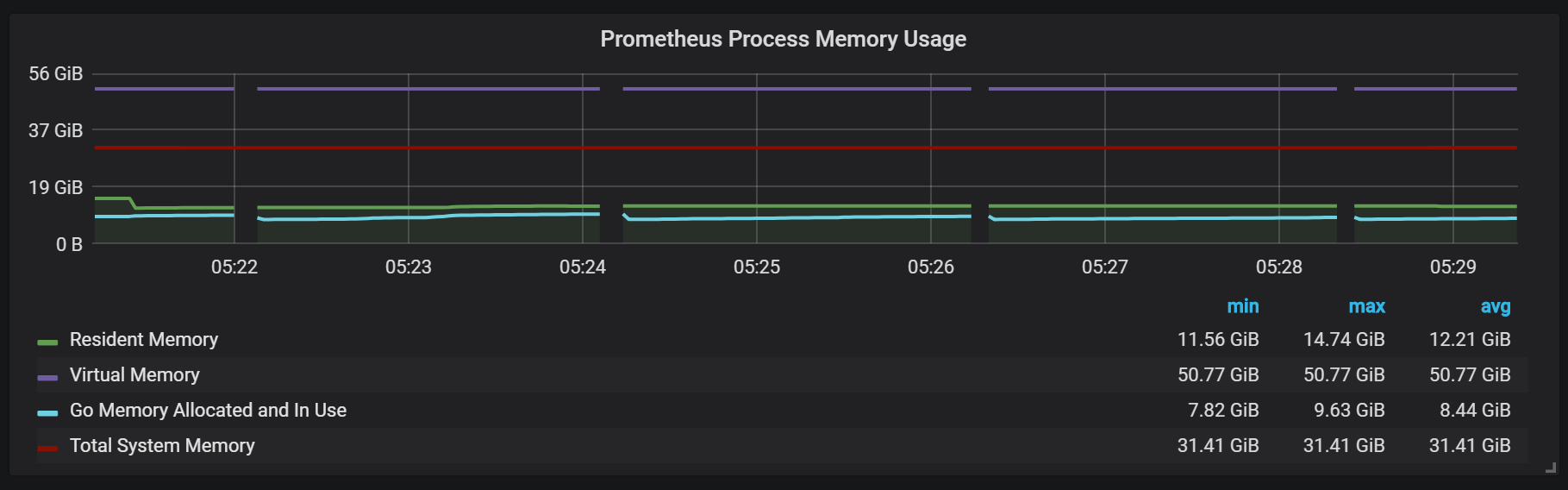
You may also notice that the exporter Prometheus shuts down for one second.
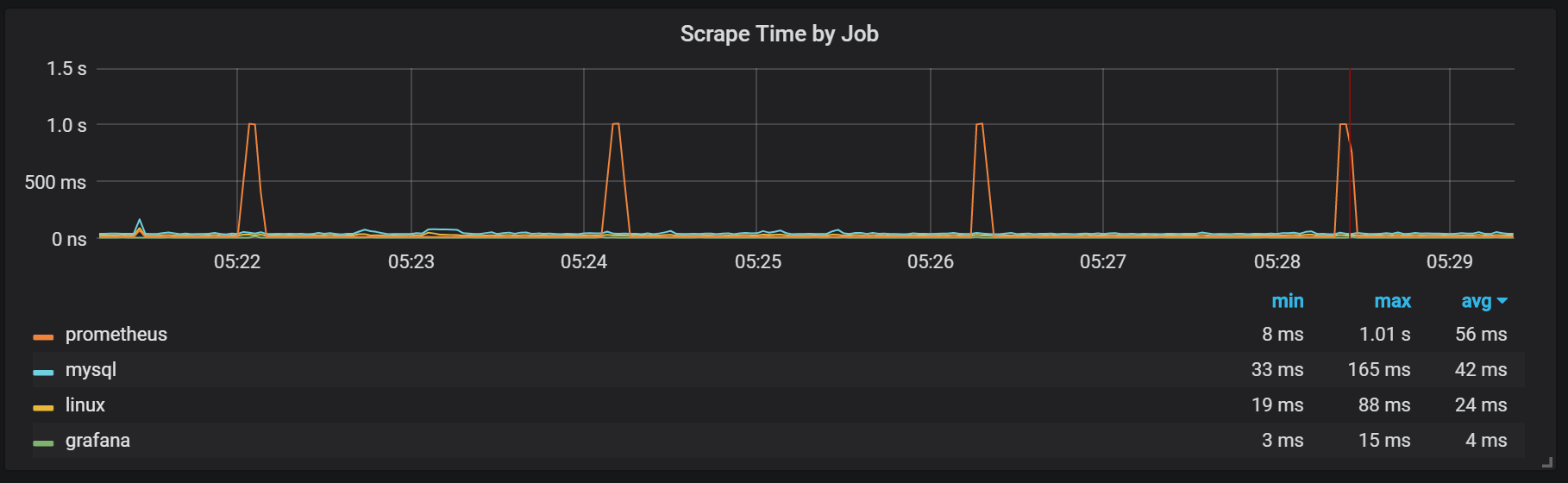
We may notice correlations with garbage collection (GC).

Conclusion
TSDB in Prometheus 2 is fast, able to cope with millions of time series and at the same time with thousands of records per second, using rather modest hardware. Recycling the CPU and disk I / O is also impressive. My example showed up to 200,000 metrics per second per core used.
To plan expansion, you need to remember about enough memory, and it must be real memory. The amount of used memory, which I observed, was about 5 GB per 100,000 entries per second of the incoming stream, which in total with the operating system cache was about 8 GB of occupied memory.
Of course, there is still a lot of work to be done to tackle CPU bursts and disk I / O, and this is not surprising considering how young the TSDB Prometheus 2 is still compared to InnoDB, TokuDB, RocksDB, WiredTiger, but they all had similar problems at the beginning of the life cycle.
Source: https://habr.com/ru/post/445370/
All Articles