Spark Structured Streaming Applications on Kubernetes. Experience FASTEN RUS
Today I will tell you how we managed to solve the problem of porting Spark Structured Streaming Applications to Kubernetes (K8s) and implement CI streaming.
Streaming is a key component of the FASTEN RUS BI platform. Real-time data is used by the date analysis team to build operational reports.
Streaming applications are implemented using Spark Structured Streaming . This framework provides a convenient API for data transformation, which meets our needs in terms of speed of refinement.
The streams themselves went up on the AWS EMR cluster. Thus, when raising a new stream to the cluster, an ssh script was laid out on the Spark-Jobs submission, after which the application was launched. And at first everything seemed to suit us. But with the growing number of streams, the need for CI streaming implementation became more and more obvious, which would increase the autonomy of the analysis date command when launching applications to deliver data to new entities.
')
And now we will look at how we managed to solve this problem by porting streaming to Kubernetes.
Kubernetes as a resource manager has been most responsive to our needs. This is a warm-up without a downtime, and a wide range of CI implementation tools on Kubernetes, including Helm. In addition, our team had sufficient expertise in implementing the CI pipelines on the K8s. Therefore, the choice was obvious.

Client launches spark-submit on K8s. A pod application driver is created. Kubernetes Scheduler binds pod to a cluster node. The driver then sends a request to create pod's for running executors, scams are created and bound to the cluster nodes. After that, a standard set of operations is performed with subsequent conversion of the application code into the DAG, decomposition into stages, breakdown into tasks and their execution on executors.
This model works quite successfully with the manual start of Spark-applications. However, the approach to running spark-submit outside the cluster did not suit us in terms of implementing CI. It was necessary to find a solution that would allow Spark-jobs to be run (perform spark-submit) directly on the nodes of the cluster. And here our model was fully met by the model Kubernetes Operator.
Kubernetes Operator - the concept of managing statefull applications in Kubernetes, proposed by CoreOS , which involves the automation of operational tasks, such as deploying applications, restarting applications in the case of files, and updating application configurations. One of the key patterns of Kubernetes Operator is CRD ( CustomResourceDefinitions ), which involves adding custom resources to the K8s cluster, which, in turn, allows you to work with these resources as native Kubernetes objects.
Operator is a demon that lives in the cluster pod and responds to the creation / change of the state of a custom resource.
Consider this concept in relation to the management of the life cycle of Spark-applications.
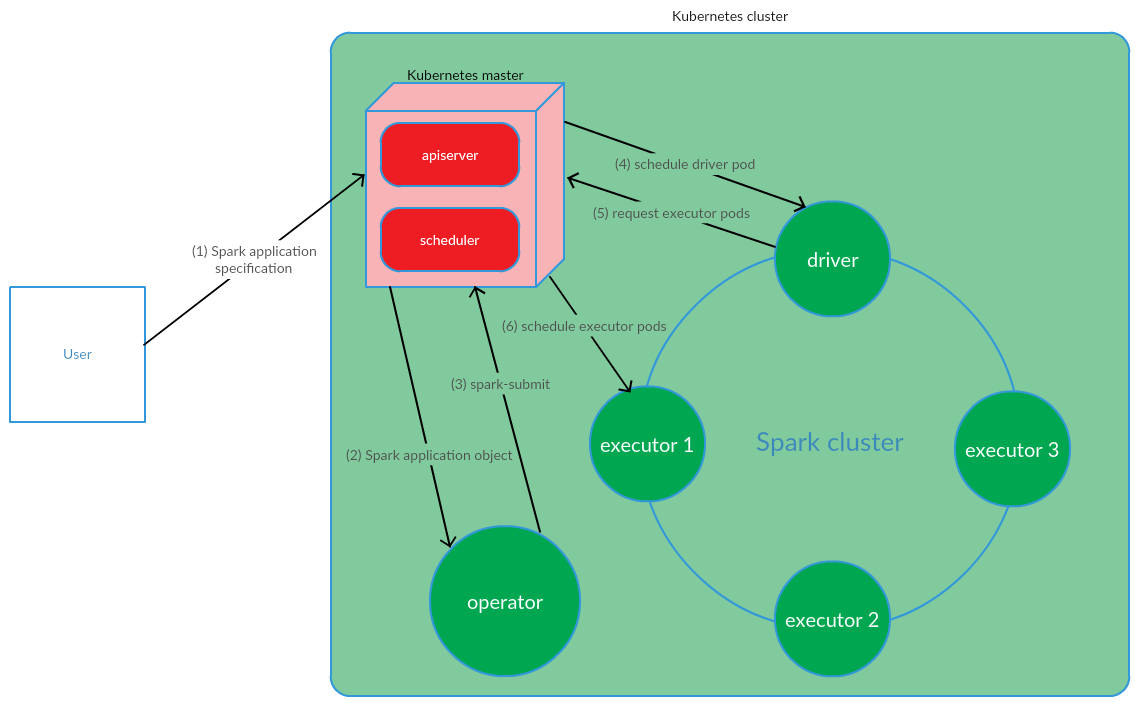
The user executes the kubectl apply -f spark-application.yaml command, where spark-application.yaml is the Spark application specification. Operator receives a Spark application object and executes spark-submit.
As we can see, the Kubernetes Operator model involves managing the lifecycle of a Spark application directly in the Kubernetes cluster, which was a serious argument for this model in the context of solving our problems.
As Kubernetes Operator for controlling streaming applications, it was decided to use a spark-on-k8s-operator . This operator offers a fairly convenient API, and also has the flexibility to configure the Spark application restart policy (which is quite important in the context of support for streaming applications).
To implement CI streaming, GitLab CI / CD was used . Spark applications are deployed on K8s using Helm .
Pipeline itself involves 2 stages:
Let us consider these stages in more detail.
At the test stage, the Helm-template of Spark-applications (CRD - SparkApplication ) is rendered with media-specific values.
The key sections of the Helm-template are:
After the application template has been rendered, it is applied to the dev test environment using Helm.
Worked out CI pipeline.
After that, run the job deploy-prod - launch applications in production.
We are convinced of the successful implementation of Joba.
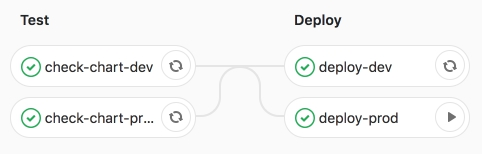
As we can see below, applications are running, while they are running in the RUNNING status.

The porting of Spark Structured Streaming Applications to K8s and the subsequent implementation of CI made it possible to automate the launch of streams for the delivery of data on new entities. To raise the next stream, it is enough to prepare a Merge Request with a description of the configuration of the Spark application in the yaml-file of values and when launching the deploy-prod data, data delivery to DWH ( Redshift ) / Data Lake (S3) is initiated. This solution ensured the autonomy of the date analysis command when performing tasks related to adding new entities to the repository. In addition, streaming porting to K8s and, in particular, management of Spark-applications using Kubernetes Operator spark-on-k8s-operator significantly increased the resiliency of streaming. But about this in the next article.
How it all began?
Streaming is a key component of the FASTEN RUS BI platform. Real-time data is used by the date analysis team to build operational reports.
Streaming applications are implemented using Spark Structured Streaming . This framework provides a convenient API for data transformation, which meets our needs in terms of speed of refinement.
The streams themselves went up on the AWS EMR cluster. Thus, when raising a new stream to the cluster, an ssh script was laid out on the Spark-Jobs submission, after which the application was launched. And at first everything seemed to suit us. But with the growing number of streams, the need for CI streaming implementation became more and more obvious, which would increase the autonomy of the analysis date command when launching applications to deliver data to new entities.
')
And now we will look at how we managed to solve this problem by porting streaming to Kubernetes.
Why Kubernetes?
Kubernetes as a resource manager has been most responsive to our needs. This is a warm-up without a downtime, and a wide range of CI implementation tools on Kubernetes, including Helm. In addition, our team had sufficient expertise in implementing the CI pipelines on the K8s. Therefore, the choice was obvious.
How is the Kubernetes-based Spark application management model organized?
Client launches spark-submit on K8s. A pod application driver is created. Kubernetes Scheduler binds pod to a cluster node. The driver then sends a request to create pod's for running executors, scams are created and bound to the cluster nodes. After that, a standard set of operations is performed with subsequent conversion of the application code into the DAG, decomposition into stages, breakdown into tasks and their execution on executors.
This model works quite successfully with the manual start of Spark-applications. However, the approach to running spark-submit outside the cluster did not suit us in terms of implementing CI. It was necessary to find a solution that would allow Spark-jobs to be run (perform spark-submit) directly on the nodes of the cluster. And here our model was fully met by the model Kubernetes Operator.
Kubernetes Operator as a lifecycle management model Spark applications
Kubernetes Operator - the concept of managing statefull applications in Kubernetes, proposed by CoreOS , which involves the automation of operational tasks, such as deploying applications, restarting applications in the case of files, and updating application configurations. One of the key patterns of Kubernetes Operator is CRD ( CustomResourceDefinitions ), which involves adding custom resources to the K8s cluster, which, in turn, allows you to work with these resources as native Kubernetes objects.
Operator is a demon that lives in the cluster pod and responds to the creation / change of the state of a custom resource.
Consider this concept in relation to the management of the life cycle of Spark-applications.
The user executes the kubectl apply -f spark-application.yaml command, where spark-application.yaml is the Spark application specification. Operator receives a Spark application object and executes spark-submit.
As we can see, the Kubernetes Operator model involves managing the lifecycle of a Spark application directly in the Kubernetes cluster, which was a serious argument for this model in the context of solving our problems.
As Kubernetes Operator for controlling streaming applications, it was decided to use a spark-on-k8s-operator . This operator offers a fairly convenient API, and also has the flexibility to configure the Spark application restart policy (which is quite important in the context of support for streaming applications).
CI implementation
To implement CI streaming, GitLab CI / CD was used . Spark applications are deployed on K8s using Helm .
Pipeline itself involves 2 stages:
- test - checks the syntax and renders the Helm-templates;
- deploy - deploying streaming applications to test (dev) and product (prod) environments.
Let us consider these stages in more detail.
At the test stage, the Helm-template of Spark-applications (CRD - SparkApplication ) is rendered with media-specific values.
The key sections of the Helm-template are:
- spark:
- version - Apache Spark version
- image - used Docker image
- nodeSelector - contains a list (key → value) corresponding to the labels of the pods.
- tolerations - specifies the list of Spark-application tolerance.
- mainClass - Spark application class
- applicationFile - the local path where the Spark application jar is located
- restartPolicy - Spark application restarts policy
- Never - the completed Spark application is not restarted.
- Always - the completed Spark application is restarted regardless of the reason for the stop.
- OnFailure - Spark-application is restarted only in the case of file
- maxSubmissionRetries - the maximum number of submit Spark-applications
- driver / executor:
- cores - the number of cores allocated to the driver / executor
- instances (used only for configuration of executors) - the number of executors
- memory - the amount of memory allocated to the process driver / executor
- memoryOverhead - the amount of off-heap memory allocated to the driver / executor
- streams:
- name - the name of the streaming application
- arguments - arguments of the streaming application
- sink - the path to datasets Data Lake on S3
After the application template has been rendered, it is applied to the dev test environment using Helm.
Worked out CI pipeline.
After that, run the job deploy-prod - launch applications in production.
We are convinced of the successful implementation of Joba.
As we can see below, applications are running, while they are running in the RUNNING status.
Conclusion
The porting of Spark Structured Streaming Applications to K8s and the subsequent implementation of CI made it possible to automate the launch of streams for the delivery of data on new entities. To raise the next stream, it is enough to prepare a Merge Request with a description of the configuration of the Spark application in the yaml-file of values and when launching the deploy-prod data, data delivery to DWH ( Redshift ) / Data Lake (S3) is initiated. This solution ensured the autonomy of the date analysis command when performing tasks related to adding new entities to the repository. In addition, streaming porting to K8s and, in particular, management of Spark-applications using Kubernetes Operator spark-on-k8s-operator significantly increased the resiliency of streaming. But about this in the next article.
Source: https://habr.com/ru/post/445352/
All Articles