SNA Hackathon 2019: we complicate architecture - we simplify features

In this article I will tell you about my solution to the text part of the SNA Hackathon 2019 task. Some of the proposed ideas will be useful to the participants in the full-time part of the hackathon, which will be held in the Moscow office of Mail.ru Group from March 30 to April 1. In addition, this story may be interesting and readers who solve practical problems of machine learning. Since I cannot claim prizes (I work at Odnoklassniki), I tried to offer the simplest, but at the same time effective and interesting solution.
Reading about new models of machine learning, I want to understand how the author reasoned while working on the task. Therefore, in this article I will try to substantiate in detail all the components of my decision. In the first part I will talk about the formulation of the problem and limitations. In the second - about the evolution of the model. The third part is devoted to the results and analysis of the model. Finally, in the comments I will try to answer any questions that may arise. Impatient readers can immediately look at the final architecture .
Task
The hackathon organizers offered us to solve the problem of forming a smart tape. For each user, it is necessary to sort the set of posts so that the maximum number of posts to which the user has set the “class” are at the top of the list. To adjust the ranking algorithm, it was supposed to use historical data of the form (user, post, feedback). The table gives a brief description of the data from the text part and the notation that I will use in this article.
')
| A source | Designation | Type of | Description |
|---|---|---|---|
| user | user_id | categorical | user ID |
| fast | post_id | categorical | post ID |
| fast | text | list categorical | list of normalized words |
| fast | features | categorical | post feature group (author, language, etc.) |
| Feedback | feedback | list binary | various actions that the user could spend with the post (view, class, comment, etc.) |
Before starting to build a model, I introduced several restrictions on the future solution. It was necessary to meet the requirements of simplicity and practicality, my interests and reduce the number of possible options. Here are the most important of these restrictions.
Predicting the probability of "class . " I immediately decided that I would solve this problem as a classification task. It would be possible to apply the methods used in the ranking, for example, to predict the order in pairs of posts. But I stopped at a simpler formulation in which posts are sorted according to the predicted probability of getting a “class”. It is worth noting that the approach described below can be expanded to formulate rankings.
Monolithic model . Despite the fact that model ensembles tend to win competitions, supporting an ensemble on a combat system is more difficult than a single model. In addition, I wanted to have at least some non-black box interpretation possibilities.
Differentiable computational graph . First, models of this class (neural networks) determine state-of-the-art in many tasks, including those associated with the analysis of textual data . Secondly, modern frameworks, in my case Apache MXNet , allow implementing very diverse architectures. Therefore, you can experiment with different models by changing just a few lines of code.
Minimum of work with signs . I wanted the model to be easily extended with new data. This may be necessary in the internal part, where the time to prepare the signs will be short. Therefore, I stopped at the simplest approach to the selection of signs:
- binary data is represented by a sign with a value of 1 or 0;
- numeric data either remains as it is or is discretized into categories;
- categorical data are submitted by embeddings.
Having decided on a common strategy, I began to try different models.
Model evolution
The starting point was the matrix factorization approach, often used in recommendation tasks:
In the language of computational graphs, this means that the estimate of the probability that user i will put a “class” to post j is a sigmoid from the scalar product of embeddings of the user ID and the post ID. The same can be expressed in the diagram:

This model is not very interesting: it does not use all the signs, it is not very useful for low-frequency identifiers and suffers from a cold start problem. But, having formulated the task in the form of a computational graph, we “untied our hands” and can now solve problems in stages. First of all, for low frequency values, we will start a single embedding of Out-Of-Vocabulary . Next, we will get rid of the need to have embeddings of the same dimension. To do this, we replace the scalar product by a shallow perceptron that accepts concatenated attributes as input. The result is shown in the diagram:

As soon as we get rid of the fixed dimension, nothing prevents us from starting to add new features. By presenting the post with all sorts of characteristics (language, author, text, ...), we will solve the problem of the cold start of posts. The model will learn, for example, that a user with user_id = 42 puts “classes” to posts in Russian containing the word “carpet”. In the future, we will be able to recommend all Russian-language posts about carpets to this user, even if they did not appear in the training data. For embedding, for the time being, we will simply average the embeddings of the words in it. As a result, the model looks like this:
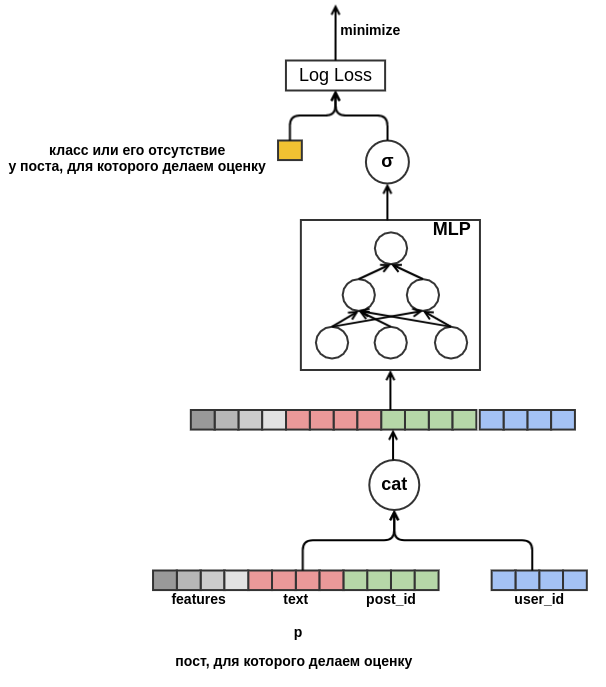
Finally I would like to deal with the cold start of users. It would be possible to construct features from historical data about user views of posts. This approach does not satisfy the chosen strategy: we decided to minimize the manual creation of features. Therefore, I provided the model with the opportunity to independently learn the user's view from a sequence of posts viewed before the post for which the “class” probability estimate is made. Unlike the post being evaluated, all feedback is known for each of the posts in the sequence. This means that the model will be available information about whether the user has put the previous posts "class" or vice versa deleted them from the tape.

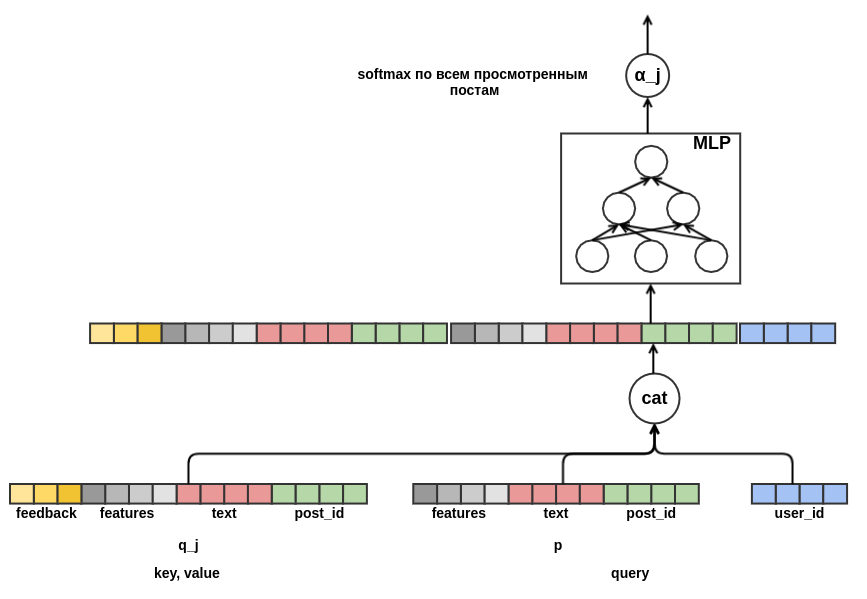
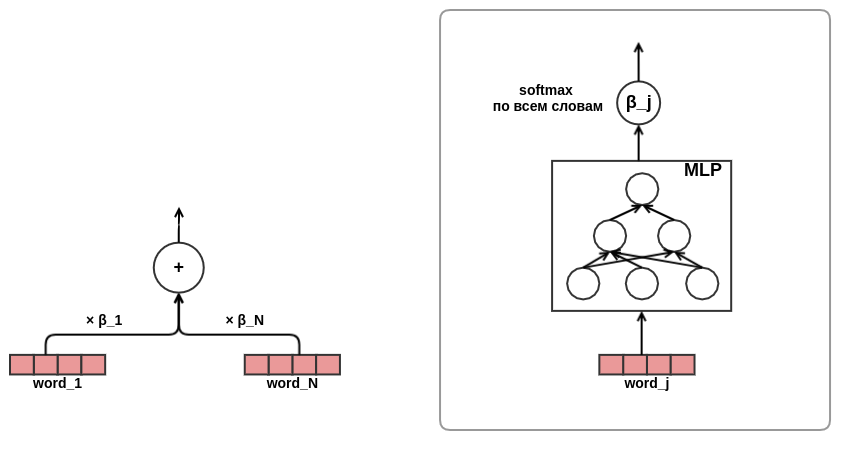
It remains to determine how to combine a sequence of posts of different lengths into a fixed-width representation. As such a combination, I used a weighted sum of the views of each of the posts. In the diagram, the weight of the post j is denoted by α_j . Weights were calculated using the query-key-value attention mechanism, similar to the one used in the transformer or NMT . In this way, the learned user's view is also configured for the post for which the evaluation is being conducted. Here is a piece of the graph responsible for calculating α_j :
After I
At this development of the architecture of the model was completed. As a result, I went from the classical matrix factorization to a rather complex sequence-model.
Results and analysis
I developed my solution and debugged it on one seventh of the data on a laptop with 16 GB of memory and a GeForce 930MX video card. Experiments on complete data were run on a dedicated server with 256 GB of memory and a Tesla T4 card. For optimization, the Adam algorithm was used with default parameters from MXNet. The table presents the results for the trimmed model - the length of the sequence of posts was limited to ten. In competitive submission, I used sequences of length fifty.
| Model | Log loss | Improvement from the previous line | Studying time |
|---|---|---|---|
| Random | 0.4374 ± 0.0009 | ||
| Perceptron | 0.4330 ± 0.0010 | 0.0043 ± 0.0002 | 7 min |
| Featured perceptron | 0.4119 ± 0.0008 | 0.0212 ± 0.0003 | 44 min |
| Perceptron with a sequence of posts | 0.3873 ± 0.0008 | 0.0247 ± 0.0003 | 4 hours 16 minutes |
| Perceptron with a sequence of posts and attention in the texts | 0.3874 ± 0.0008 | 0.0001 ± 0.0001 | 4 hours 43 minutes |
The last line was the most unexpected for me: the use of attention in the presentation of texts does not give a visible improvement in the result. I expected the attention-network to learn the weights of words in texts, something like idf . Perhaps this did not happen, because the organizers removed the stop words in advance, and in the prepared lists there were words of about one importance. Therefore, “smart” weighing did not give a tangible advantage compared to simple averaging. Another possible reason is that the attention-network for words was rather small: it contained only one narrow hidden layer. Perhaps she did not have enough representation capacity to learn something useful.
The query-key-value attention mechanism gives you the opportunity to look inside the model and find out what it “pays attention to” when making a decision. To illustrate this, I selected a few examples:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g The first line shows the text of the post that needs to be assessed, next - the posts that have been scanned before and the corresponding attention score. We are relieved to note that the model has learned not to pay attention to padding. The most important model found posts about the types of souls and about Windows. It should be borne in mind that attention can be both positive (the user will react to the post about the aura, just like the post about the types of souls) and negative (we estimate the post about the aura - therefore the reaction will not be the same as the reaction to the post about technology). The following example - attention "in all its glory":
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ... Here the model clearly saw the theme of the summer holiday. Even the children and kittens went into the background. The following example shows that it is not always possible to interpret attention. Sometimes even absolutely nothing is clear:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300 After viewing a number of similar lists, I concluded that the model was able to learn what I expected. The next thing I did was look at the embedding of words. In our task, we cannot expect embeddings to be just as beautiful as when learning the language model : we are trying to predict a rather noisy variable, besides we do not have a small context window - embeddingings of all words are simply averaged without taking into account their order in the text. Examples of tokens and their closest neighbors in the embedding space:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , , Something from this list is easy to explain (program - bl), something causes confusion (iphone - yoki), but in general, the result again met my expectations.
Conclusion
I like the model building approach based on differentiable graphs ( many agree ). It allows you to get away from the tedious manual selection of features and focus on the correct formulation of the problem and the design of interesting architectures. And although my model took only second place in the SNA Hackathon 2019 text task, I am quite pleased with this result, given its simplicity and almost unlimited expansion options. I am sure that in the future there will appear more and more interesting and applicable models in combat systems based on similar ideas.
Source: https://habr.com/ru/post/445348/
All Articles