How to move, unload and integrate very large data cheaply and quickly? What is pushdown optimization?
Any operation with big data requires large computational power. The usual transfer of data from the database to Hadoop can last for weeks or cost, like an airplane wing. Do not want to wait and spend money? Balance the load on different platforms. One way is pushdown optimization.
I asked Alexey Ananyev, Informatica Product Development and Administration Coach in Russia, to talk about pushdown optimization in Informatica Big Data Management (BDM). Once learned to work with products Informatica? Most likely Alexey told you the basics of PowerCenter and explained how to build mappings.
Alexey Ananiev, DIS Group Head of Training
What is pushdown?
Many of you are already familiar with Informatica Big Data Management (BDM). The product is able to integrate big data from different sources, move them between different systems, provides them with easy access, allows you to profile them and much more.
In the capable hands of BDM is able to work wonders: tasks will be performed quickly and with minimal computational resources.
Do you want it too? Learn how to use the pushdown function in BDM to distribute the computational load across different platforms. The pushdown technology allows you to turn mapping into a script and select the environment in which this script will run. The possibility of such a choice allows you to combine the strengths of different platforms and achieve their maximum performance.
To configure the script runtime, you need to select the type of pushdown. The script can be completely run on Hadoop or partially distributed between the source and the receiver. There are 4 possible types of pushdown. Mapping can not be turned into a script (native). Mapping can be performed as much as possible on the source (source) or completely on the source (full). You can also turn mapping into a Hadoop script (none).
Pushdown optimization
These 4 types can be combined in different ways - to optimize pushdown for the specific needs of the system. For example, it is often more expedient to extract data from a database using its own capabilities. And convert the data - by Hadoop, in order not to overload the database itself.
Let's consider the case when both the source and the receiver are in the database, and you can choose the conversion execution platform: depending on the settings, this will be Informatica, the database server or Hadoop. Such an example will allow us to most accurately understand the technical side of the work of this mechanism. Naturally, in real life, this situation does not arise, but it is best suited to demonstrate the functionality.
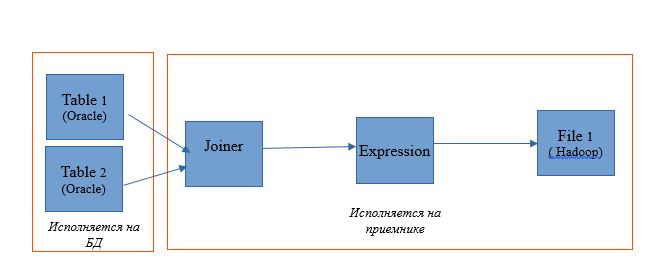
Take mapping to read two tables in a single Oracle database. And let the reading results be recorded in a table in the same database. The mapping scheme will be as follows:

In the form of mapping on Informatica BDM 10.2.1, it looks like this:
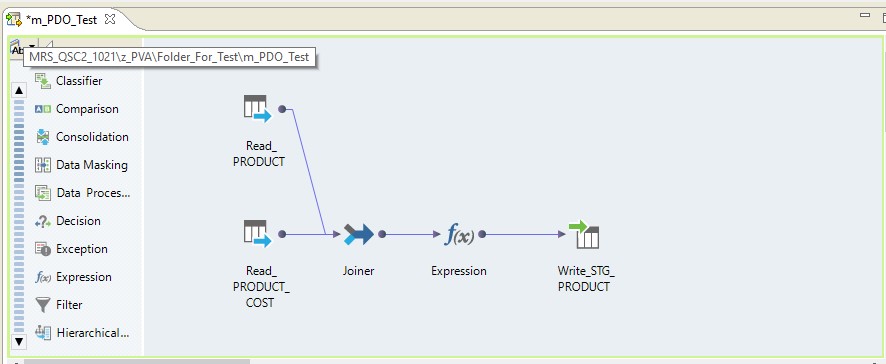
Pushdown type - native
If we select the pushdown native type, the mapping will be performed on the Informatica server. The data will be read from the Oracle server, transferred to the Informatica server, transformed there and transferred to Hadoop. In other words, we get the usual ETL process.
Pushdown type - source
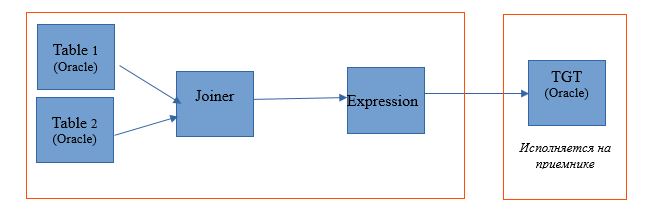
When choosing the type of source, we get the opportunity to distribute our process between the database server (DB) and Hadoop. When executing a process with this setting, queries will be sent to the database to fetch data from tables. And the rest will be performed as steps on Hadoop.
The execution scheme will look like this:
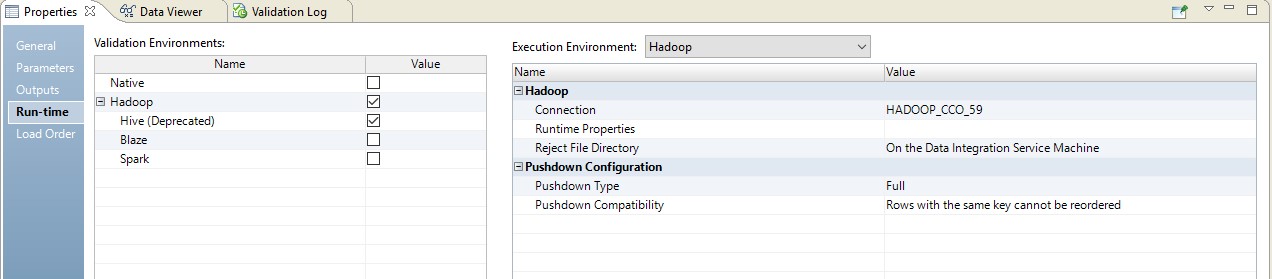
Below is an example of setting runtime.
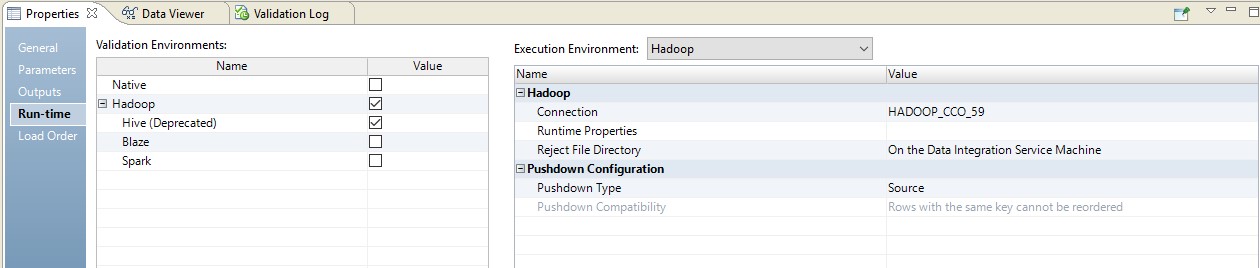
In this case, the mapping will be performed in two steps. In its settings, we will see that it has become a script that will be sent to the source. Moreover, the combination of tables and data conversion will be performed in the form of a redefined query on the source.
In the picture below, we see optimized mapping on BDM, and on the source, an over-defined query.
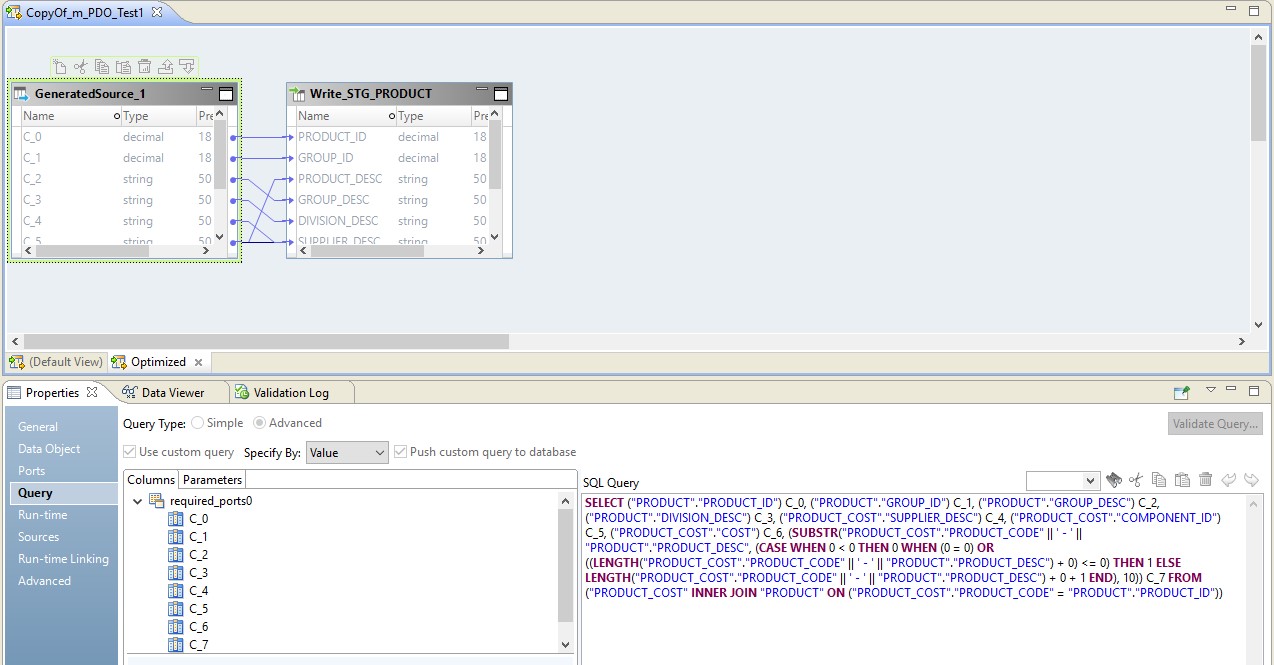
The role of Hadoop in this configuration will be reduced to managing the flow of data - conducting them. The result of the query will be sent to Hadoop. After completion of reading the file from Hadoop will be written to the receiver.
Pushdown type - full
If you select the full type, the mapping will completely turn into a query on the database. And the result of the query will be sent to Hadoop. A diagram of this process is presented below.
An example setup is shown below.
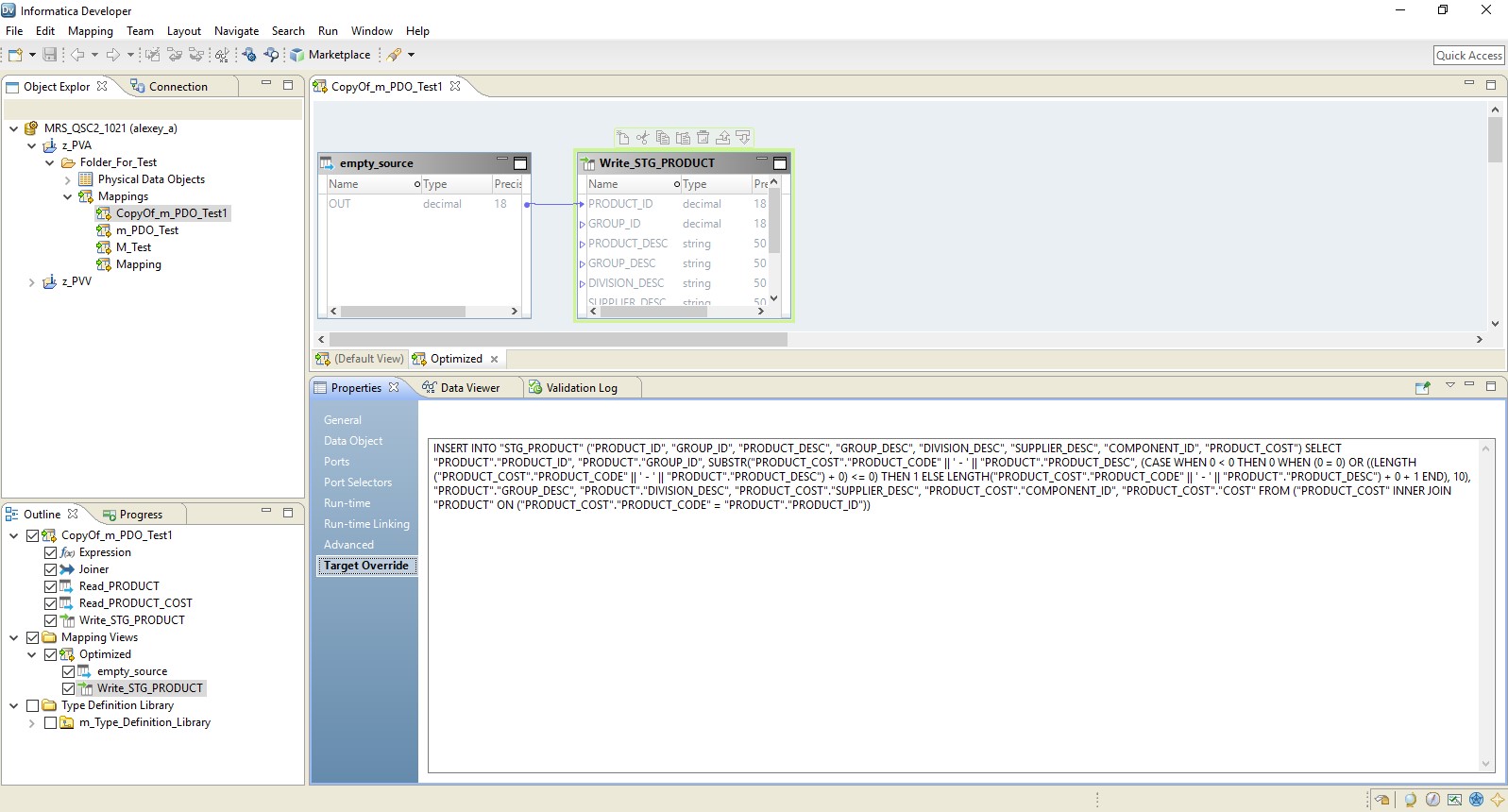
As a result, we get an optimized mapping similar to the previous one. The only difference is that all logic is transferred to the receiver as a redefinition of its insertion. An example of optimized mapping is presented below.
Here, as in the previous case, Hadoop plays the role of a conductor. But here the source is read entirely, and then at the receiver level the processing logic is executed.
Pushdown type - null
And the last option is the pushdown type, within which our mapping will turn into a script on Hadoop.
The optimized mapping will now look like this:
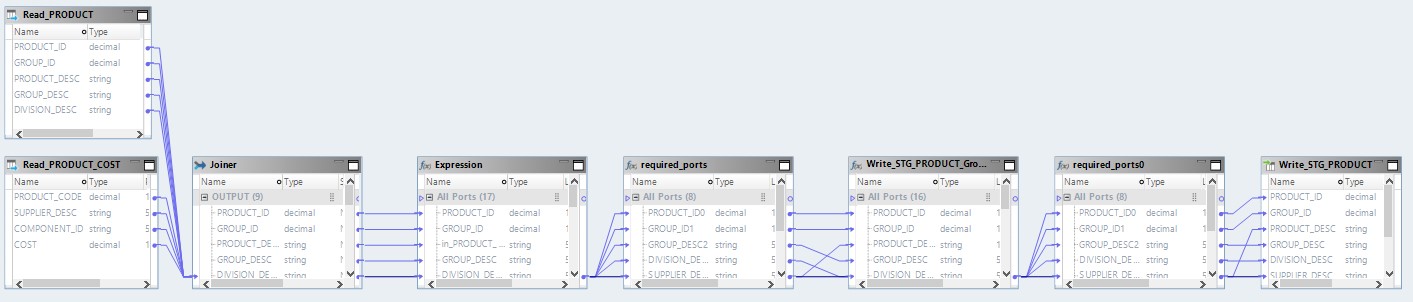
Here, the data from the source files will first be read on Hadoop. Then by his means these two files will be merged. After that, the data will be converted and uploaded to the database.
Understanding the principles of pushdown optimization, you can very effectively organize many processes for working with big data. So, quite recently, a large company just in a few weeks unloaded large data from storage in Hadoop, which had previously been collected for several years.
')
Source: https://habr.com/ru/post/445240/
All Articles