New algorithm 200 times accelerates the automatic design of neural networks

ProxylessNAS directly optimizes the architecture of neural networks for a specific task and equipment, which can significantly increase performance compared to previous proxy approaches. On the ImageNet data set, the neural network is projected for 200 GPU-hours (200-378 times faster than analogs), and the automatically designed CNN model for mobile devices achieves the same level of accuracy as MobileNetV2 1.4, working 1.8 times faster.
Researchers at the Massachusetts Institute of Technology have developed an efficient algorithm for the automatic design of high-performance neural networks for specific hardware, writes MIT News .
')
Algorithms for the automatic design of machine learning systems - a new area of research in the field of AI. Such a technique is called “neural architecture search (NAS)” and is considered a difficult computational task.
Auto-designed neural networks have a more accurate and efficient design than those developed by humans. But the search for neural architecture requires really huge computations. For example, the modern NASNet-F algorithm, recently developed by Google for working on graphics processors, takes 48,000 hours of computing on the GPU to create a single convolutional neural network, which is used to classify and detect images. Of course, Google can simultaneously run hundreds of graphics processors and other specialized equipment. For example, on a thousand GPUs such a calculation will take only two days. But not all researchers have such opportunities, and if you run the algorithm in the Google computing cloud, it can cost you a lot.
MIT researchers prepared an article for the International Conference on Learning ( ICLR 2019 ), which will be held from 6 to 9 May 2019. The ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware article describes the ProxylessNAS algorithm, which can directly develop specialized convolutional neural networks for specific hardware platforms.
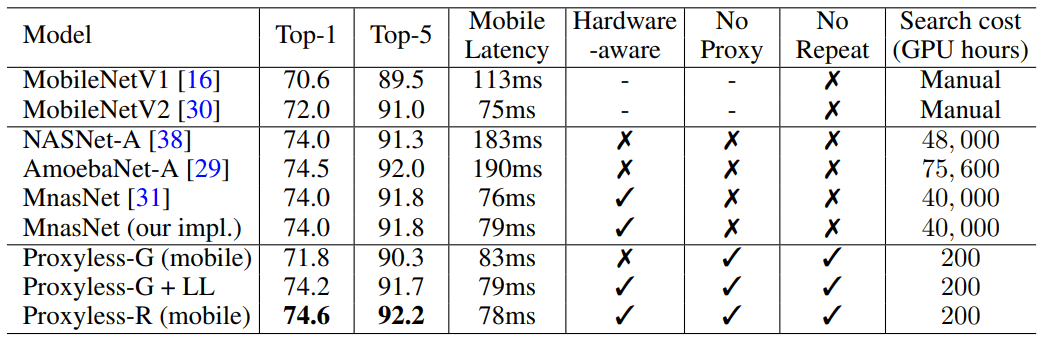
When running on a massive set of image data, the algorithm designed the optimal architecture in just 200 hours of GPU operation. This is two orders of magnitude faster than developing a CNN architecture using other algorithms (see table).
Benefit from the algorithm will get researchers and companies with limited resources. A more general goal is to “democratize AI,” says co-author of the research paper Son Han (Song Han), an assistant professor of electrical engineering and computer science at the Microsystems Technology Laboratories at MIT.
Khan added that such NAS algorithms will never replace the intellectual work of engineers: "The goal is to relieve the repetitive and tedious work that comes with designing and improving the architecture of neural networks."
In their work, the researchers found ways to remove unnecessary components of the neural network, reduce computation time and use only part of the hardware memory to run the NAS algorithm. This ensures that the CNN developed works more efficiently on specific hardware platforms: CPU, GPU and mobile devices.
The CNN architecture consists of layers with adjustable parameters, called “filters,” and possible links between them. Filters process image pixels in square grids — such as 3 × 3, 5 × 5, or 7 × 7 - where each filter covers one square. In fact, the filters move through the image and combine the grid colors of the pixels into one pixel. In different layers of filters of different sizes, which are differently connected for data exchange. The CNN output produces a compressed image combined with all filters. Since the number of possible architectures - the so-called “search space” - is very large, using NAS to create a neural network on massive image data sets requires huge resources. Typically, developers run the NAS on smaller data sets (proxies) and transfer the resulting CNN architectures to the target. However, this method reduces the accuracy of the model. In addition, the same architecture applies to all hardware platforms, leading to efficiency issues.
MIT researchers trained and tested a new algorithm on the task of classifying images directly in the ImageNet data set, which contains millions of images in a thousand classes. First, they created a search space that contains all the possible “paths” of CNN candidates so that the algorithm finds among them an optimal architecture. For the search space to fit into the GPU's memory, they used a method called “binarization at the path level” (path-level binarization), which saves only one path at a time and saves memory by an order of magnitude. Binarization is combined with “path-level pruning” - a method that traditionally studies which neurons in a neural network can be safely removed without harming the system. Only instead of removing neurons, the NAS algorithm removes entire paths, completely changing the architecture.
In the end, the algorithm cuts off all unlikely paths and saves only the path with the highest probability - this is the final CNN architecture.
The illustration shows samples of neural networks for classifying images that ProxylessNAS developed for the GPU, CPU, and mobile processors (top to bottom, respectively).

Source: https://habr.com/ru/post/444920/
All Articles