Why serverless technology is a revolution in product management

Serverless architectures fundamentally affect the limiting factors that constrain product development.
Product managers in an organization perform in a variety of roles. Sometimes they are called “customer voice”, sometimes they are assigned the role of “corporate private security” . These are thick-skinned brethren, people who inexorably lead you to surrender a product, despite all ethics or excuses. A good product manager rarely becomes someone's idol, but it is thanks to the work of such people that most of the technological solutions that you have ever used are embodied.
PM always looks for the best possible tools for solving the problem. We know that competitors are constantly stepping on their heels, customers are tired of waiting, so we constantly have to act smarter, faster and more efficiently. With the advent of serverless technologies, it was not immediately clear how they would fit into the product management wish list. However, after working with these technologies for a year, I see that they solve some software development problems that seemed eternal to us.
Paradox: team size and performance
The first rule of product management states: the volume of work to execution is constantly growing. Baclog continues to swell, and it collapses to zero in only one case: when the product is abolished. The most difficult thing is to turn the most important elements of your backlog into a product ready for delivery. Other things being equal, it is considered that the following relationship should be observed:
')
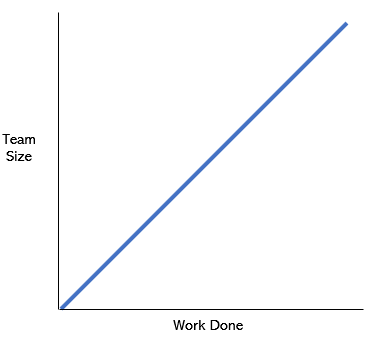
If one excavator can recycle 1 ton of soil per day - it is assumed that 10 excavators can recycle 10 tons. As a rule, resource management in companies is built precisely on this principle: if you want to increase sales, hire more sales people. When developing software, when backlog grows, it is tempting to simply increase the command. However, in the case of complex products and services, a graph like this usually emerges over time:
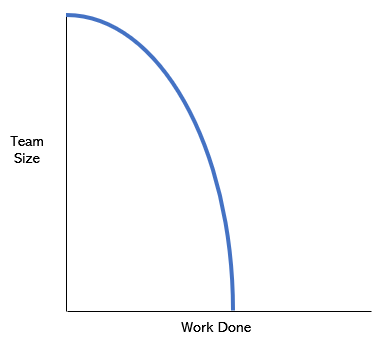
You will rarely see how a huge team works at the Stakhanov pace; but much more often it happens that a small team with enviable constancy progresses by leaps and bounds.
Many startups are characterized by such an error: as soon as the product becomes successful, all new developers and managers are added to the staff. Soon, suddenly it turns out that the speed starts to fall. What is the matter? That the first developers were more talented, that the bureaucracy grew in the company, how the architecture was planned?
I think all these are just symptoms, not the root of the problem. The problem itself boils down to the interaction of three critical factors, only two of which can be directly controlled:
- Fragility - the impact of new changes. If a new feature affects only part of the machine, then it is easy to test and implement. If it affects all elements of the machine, then testing becomes more complicated and more important at the same time, and the implementation requires an order of magnitude more time.
- The amount of work is the minimum piece of work that can be performed by a team and gives a productive feature at the exit. For example, the productive result is “Pay with Alexa,” rather than “get together and discuss how to make payments with Alexa.”
- Difficulty - how much knowledge is required to implement a feature. Can a developer who knows how to write a feature on his own to do the same within an organization? What additional changes must occur to make progress gradually slow down, and the product will no longer be cluttered with features valuable from a client’s point of view?
It especially takes me, why at the dawn of existence all these factors are optimally balanced: there is nothing fragile there, the amount of work is not particularly large (and you can usually agree with the customer), and the complexity is almost absent. So, if a team has to create a GDPR-compatible site, then they will have time to research this problem, the solution will be made quickly, and the team will be confident that the site works exactly as planned.
In larger companies, these factors are combined, with the result that the team size increases, and the amount of work done is reduced. To create a GDPR-compatible website in such a company, a lawyer’s signature, marketing approval, project approval at the board level, A / B testing of the least disruptive implementation, approval of development gaps with the team of administrators, coordination with other teams are required. - the list goes on. Even with this amount of control and the number of processes, the team is much less confident that it will succeed because of the fragility of the entire system and the many unknowns in the ecosystem.
Expanding this example to the size of a real project, in which there may be dozens of features and hundreds of changes, it is easy to understand how, due to the mutual influence of these factors, the “team size / workload” schedule turns from first to second. As the team grows, you are doomed to do less and less work per unit of time, no matter how hard you try to outwit the organizational colossus. Or it only seems so - but what, then, is to be done?
How to hack all three factors
This problem has been haunting me for many years, which prompted me to take up the study of its possible causes. Is it possible only at startups rapid progress? For a while, I thought so, facing the difficulties of product management in large organizations. However, then I looked at all three factors more closely.
Fragility is always to your detriment - it provokes ever-growing technical debt in any project of any size. The situation is reminiscent of the “half-life in reverse”: any element of the program grows with time and because of this (during development) it becomes more fragile, and all this is compounded with each new line of code.
The amount of work is not related to a specific feature of the product (“Pay with Alexa”), but rather with differences in the outlines of the infrastructure, if we compare the “before” and “after” states. The more difficult it becomes “after”, the more the work is reduced. That is why in many companies, when planning work, the emphasis is shifted from the client's needs (“Pay with Alexa”) to the needs of the organization (“Meet and discuss who should deal with the implementation of the“ Pay with Alexa ”feature).
Complexity is a combination of social, organizational and technical factors that directly affect the duration of the search for a suitable developer, the ability to treat programmers as multi-users who can be assigned to any work. Moreover, it is the complexity - the very aspect that is likely to remain invisible, undocumented and misunderstood. A developer can write a React-application at home and execute his release himself, but in an organization he will have to take about a dozen extra steps that will take time away from him, and the features interesting to the user will not change at all. The programmer will spend on them most of the working day.
Together, these three factors form a vicious circle, so that the amount of work done decreases, brittleness increases, the developer manages to complete fewer and fewer features, and your product becomes clumsy as invisible mud. Consequently, the growth of the team does not help, and the speed can be increased only deliberately sly with numbers and indicators. The classic symptom: in the reports on the sprints appears the position "held a meeting."
In large companies, I had to observe a couple of flawed approaches designed to break this cycle. The first one is “Large-scale Agile”, which results in huge meetings in which absolutely all participants of the development of a particular feature participate and attempts are made to coordinate the work. Thus, they are trying to coordinate the work and understand the complexity. Such an approach is a boon for food distribution companies delivering fabulous lunches, but in our case does not work. The fact is that as the number of priority projects increases, the number of priority projects becomes more and more, and they themselves decrease. Therefore, it is fundamentally impossible to solve the problems of fragility and complexity. Over time, the large-scale Agile gives a tactical list of tasks resembling a shopping list, and less and less like a holistic path from one thoughtful feature to another.
Secondly, intra-corporate “innovation groups” often try to promote peripheral changes, in the hope that this work will take root in a fragile machine, and the whole structure will change for the better. Such an approach gives a bizarre side effect: it consolidates the conviction that only such “innovation groups” are entitled to make changes in the process. Therefore, this method also does not solve problems with organizational complexity.
Having seen many different years of dips, I came to the conclusion that it was necessary to hack all three factors in order to prevent their cumulative effect on the work being done and to cope with inertia:
- Fragility should not increase in subsequent versions or as the product ages.
- A piece of work should not be less than is required to create a feature that is significant from the user's point of view.
- The complexity should not affect the work of a single developer.
If you manage to adopt these ideas, then you will be saved from rock, pursuing all software products in the history of mankind. It sounds great, but how to achieve this?
If you manage to adopt these ideas, then you will be saved from rock, pursuing all software products in the history of mankind. It sounds great, but how to achieve this?
Serverless technologies break limitations
Due to the emergence of cloud technologies, it was possible to lay important trails to the new “hacked” state. In general, with the advent of clouds, the process of delivering a software product has become more compact, since the provider has begun to do a lot of routine things for you. Before the advent of clouds, if you needed to implement a new user feature, you had to order servers, install equipment on racks, arrange networking in a data center, and then maintain this equipment, which eventually wears out. In the cloud, all of this can be rented, thus getting rid of dozens of organizing documents and saving entire months.
In addition, eliminating the need to upgrade equipment in the data center and providing access to hardware on demand, we reduce both the fragility and complexity. Launching programs is much easier than in the old days. However, over time, the burden associated with administering a vast virtual infrastructure has increased significantly, and many outdated delivery methods have remained unchanged. Using the clouds, the team can significantly increase, before work starts to slow down - however, it starts to slow down, one way or another.
Serverless technologies radically change this dynamic. A serverless application consists of small code fragments written by your team (the so-called “glue”) and functional “black boxes” managed by the cloud provider. The black box simply accepts the configuration and responds to changes. In an application with high-quality architecture, a significant part of the operational work associated with the operation of the application rests on the standard black boxes. The application itself is no longer a monolithic function, but a federal structure of functions and black boxes.
In practice, this dramatically affects the three factors I mentioned above:
- Fragility is reduced due to zero infrastructure management costs and weak binding. In our own projects, it has been observed that the code base as a result of such changes can sometimes be reduced tenfold.
- The size of the “piece of work” is usually comparable to the cost of creating a new feature, since it becomes trivial to create new versions of functions or completely new functions that were not previously required.
- The complexity does not affect the developer - if he can write a function that processes payment from a credit card, then practically nothing more than this code in a serverless application will not have to be done, no organizational wraps and no ecosystem accounting, due to which work could be slowed down.
When managing even very large serverless applications, the product manager can easily look at those read items that were affected by the changes made. In addition, it is easy to run two versions competitively by setting the feature flags. Moreover, it is usually not even necessary to demolish old versions of the code.
In serverless applications, the infrastructure is always completed on the periphery, and you write only the necessary minimum of code that combines fully managed services. Think about them from the operational point of view is never necessary. We are not trying to control the monolith, tidy up the old code or look at the whole system from a bird's eye view.
Why it is immensely important
As the rate of change increases, it becomes more difficult to predict how your program will look in the future, or what users want from you. Therefore, attempts to write code “for centuries”, such that it must work in the future, in spite of any changes, are becoming increasingly fruitless. We have seen how badly most companies reuse their code, and how their commitment to aging platforms impedes progress.
Now everything is arranged so that the old system is developed and maintained as long as possible, until its support begins to take away from the programmer almost all the time. After that, the company starts everything from scratch with the new system, solemnly promising not to repeat the mistakes made in the old one. When three factors sooner or later suffocate a new system, a technological “forest fire” occurs, after which again everything has to be started anew.
We are rotated to combat the symptoms of complexity, which is why so many paradigms come and go without leaving a significant mark in the history of product management. Serverless development, in turn, allows the team to minimize the increase in complexity and continue to produce a valuable product at a fairly smooth pace, without falling into the classic traps, which have been a scourge of any software development for decades.
Serverless paradigm is just beginning to develop, but it seems extremely promising. At a time when a client requires new features from you like never before, product managers can finally acquire a platform that allows them to think based on the preparation of new features. This process is not hampered by increasing organizational complexity, and also does not stop due to excessive fragility.
Source: https://habr.com/ru/post/444730/
All Articles