As we predicted an outflow, approaching it as a natural disaster.
Sometimes, in order to solve a problem, you just have to look at it from a different angle. Even if the last 10 years have solved such problems in the same way with different effects, it is not a fact that this method is the only one.
There is such a topic as customer churn. A thing is inevitable, because customers of any company can, for a variety of reasons, take and stop using its products or services. Of course, for a company, the outflow is a natural, but not the most desirable, action, so everyone tries to minimize this outflow. And even better is to predict the likelihood of an outflow of a particular category of users, or a specific user, and suggest some steps to hold.
Analyze and try to keep the client, if possible, you need, at least for the following reasons:
')
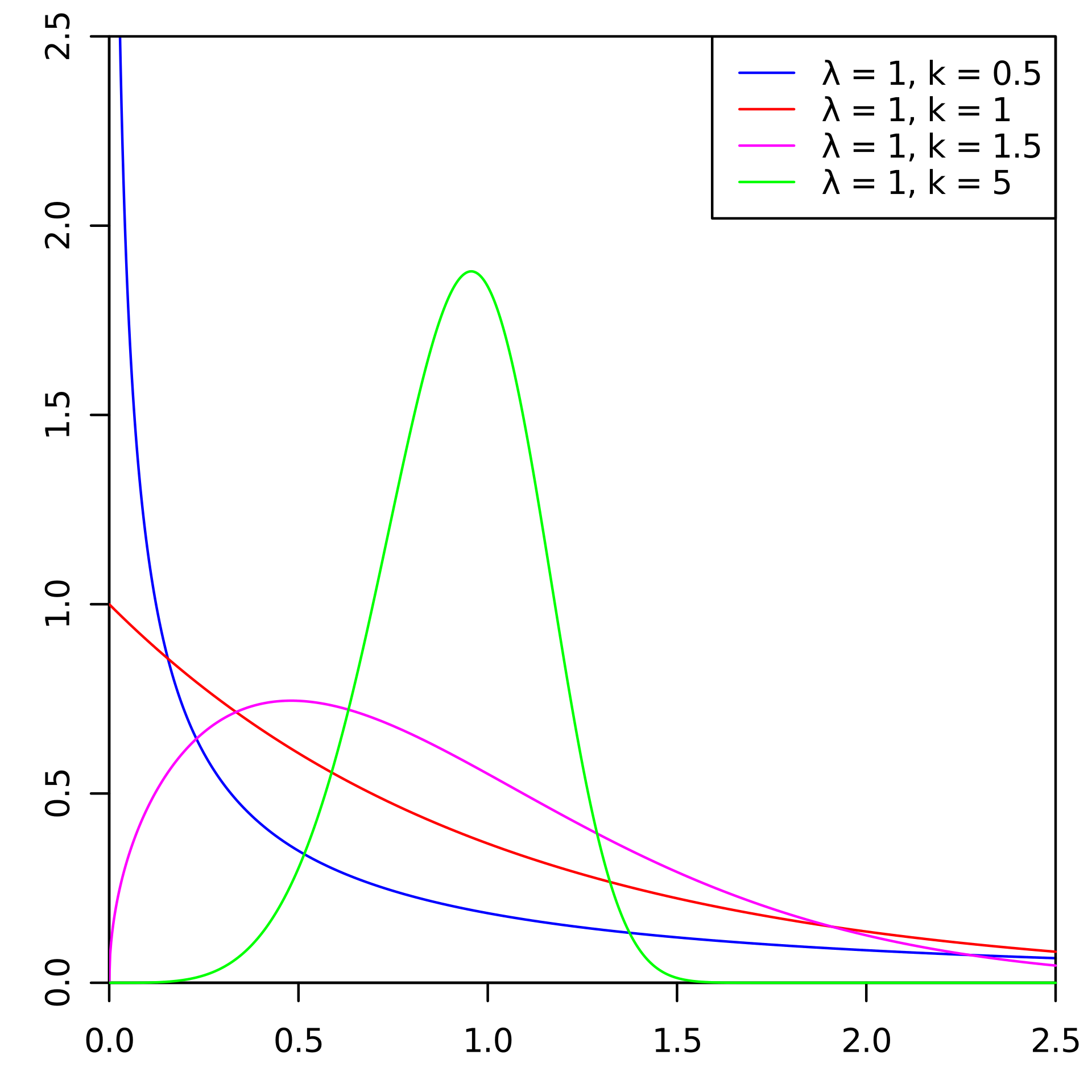
There are standard approaches to predict churn. But at one of the championships on AI, we decided to take and try the Weibull distribution for this. It is most often used for survival analysis, weather forecasting, disaster analysis, industrial engineering, and the like. Weibull distribution is a special distribution function, parameterized by two parameters and .
Wikipedia
In general, the thing is entertaining, but for predicting the outflow, and indeed in Fintech, which is not used so often. Under the cut, we’ll tell you how we (the Laboratory of Data Mining) did this by winning gold in the Artificial Intelligence Championship in the nomination “AI in banks”.
Let's take a quick look at what a customer churn is and why it is so important. For business, customer base is important. New clients come to this base, for example, having learned about a product or service from advertising, they live for some time (they actively use products) and after a while cease to use. This period is called the “Customer Lifecycle” (English Customer Lifecycle) is a term describing the steps that a customer goes through when he becomes aware of a product, makes a purchase decision, pays, uses and becomes a loyal consumer, and ultimately stops using one reason or another products. Accordingly, the outflow is the final stage of the client's life cycle, when the client ceases to use the services, and for business this means that the client has ceased to make a profit and in general any benefit.
Each bank customer is a specific person who chooses a particular bank card specifically for his needs. Often travels - useful card with miles. Buys a lot - hello, card with cashback. Buys a lot in specific stores - and for this there is already a special affiliate plastic. Of course, sometimes the card is selected and the criterion of "The cheapest service." In general, there are enough variables.
And another person chooses the bank itself - is there any point in choosing a bank card whose branches are only in Moscow and the region when you are from Khabarovsk? Whether the card of such a bank is at least 2 times more profitable, the presence of bank branches nearby is still an important criterion. Yes, 2019 is already here and digital is our everything, but a number of issues with some banks can be solved only in the branch. Plus, again, some part of the population trusts a physical bank much more, and not an application in a smartphone, this should also be taken into account.
As a result, a person may have many reasons for rejecting bank products (or the bank itself). I changed jobs, and the card rate changed from payroll to "For mere mortals", which is less profitable. Moved to another city where there are no bank branches. Did not like communication with unqualified cashier in the office. That is, there may even be much more reasons for closing an account than for using a product.
And the client can not just explicitly express his intention - to come to the bank and write a statement, but simply stop using the products without terminating the contract. Here, to understand these problems, it was decided to use machine learning and AI.
Moreover, customer churn can occur in any industry (telecom, Internet service providers, insurance companies, in general, wherever there is a customer base and periodic transactions).
First of all, it was necessary to describe a clear boundary - how long do we begin to consider the client gone? From the point of view of the bank that provided us with the data for work, the client's activity status was binary - it is either active or not. There was an ACTIVE_FLAG flag in the “Activity” table, the value of which could be either “0” or “1” (respectively, “Inactive” and “Active”). And everything is good, but the person is such that he can actively use some time, and then fall out of the number of active people for a month - he fell ill, went to another country to rest, or even went to test a card of another bank. Or after a long period of inactivity, once again start using the services of the bank
Therefore, we decided to call the inactivity period a certain continuous period of time, during which the flag for it was set to “0”.
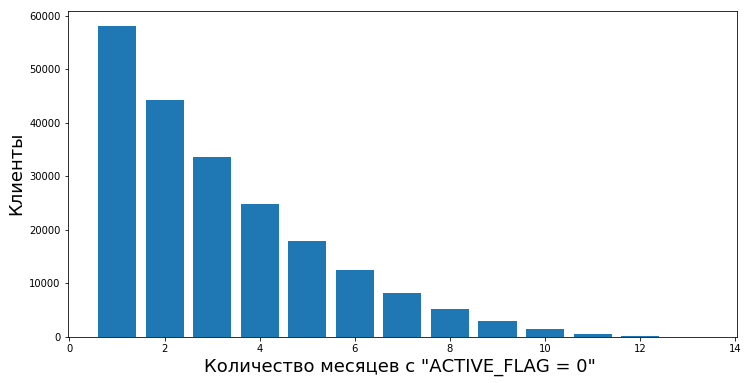
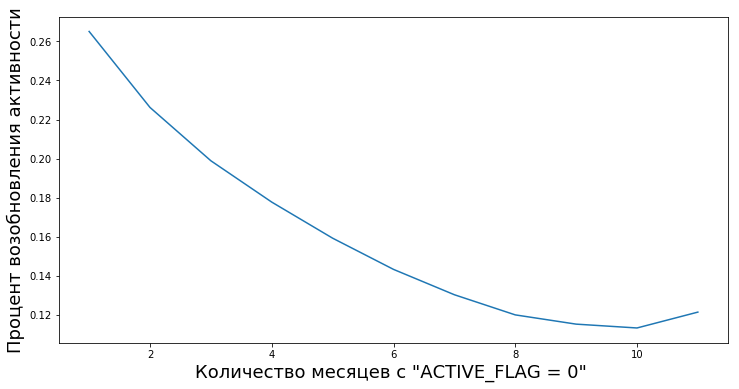
Clients transition from inactive to active after periods of inactivity of various lengths. We have an opportunity to calculate the degree of empirical value “reliability of periods of inactivity” - that is, the probability that a person will again begin using the products of the bank after temporary inactivity.
For example, this graph shows the resumption of activity (ACTIVE_FLAG = 1) of clients after several months of inactivity (ACTIVE_FLAG = 0).
Here we will slightly clarify the data set we started working with. So, the bank provided aggregated information for 19 months in the following tables:
To work we needed all the tables, except for the "Map".
The difficulty here was more than that - in these data the bank did not indicate what kind of activity was carried out on the cards. That is, we could understand whether there were transactions or not, but we could no longer determine their type. Therefore, it was unclear whether the client was withdrawing cash, whether he was paid a salary, or whether he was spending money on purchases. And we did not have data on account balances, which would be useful.
The sample itself was unbiased - at this time for 19 months the bank did not make any attempts to retain customers and minimize churn.
So, about the periods of inactivity.
To formulate the definition of outflow, you must select the period of inactivity. To create an outflow prediction at time , you must have a customer history of at least 3 months in the interval . Our history was limited to 19 months, so we decided to take a period of inactivity of 6 months, if it exists. And for the minimum period for a qualitative forecast they took 3 months. Figures in 3 and 6 months we took empirically based on the analysis of the behavior of customer data.
We formulated the definition of churn as follows: client churn month this is the first month with ACTIVE_FLAG = 0, where at least six zeros from this month go in the field ACTIVE_FLAG, in other words, the month since which the client has been inactive for 6 months.

Number of customers left

Number of customers remaining
In such competitions, and indeed in practice, the outflow is often predicted in this way. The client uses products and services at different time intervals, data on interaction with him are represented as a feature vector of fixed length n. Most often this information includes:
And after that, the definition of churn is derived, its own for each task. Then use the machine learning algorithm, which predicts the likelihood of leaving the client based on a vector of factors . For learning the algorithm, use one of the well-known frameworks for the construction of ensembles of decision trees, XGBoost , LightGBM , CatBoost, or their modifications.
The algorithm itself is not bad, but it is precisely in terms of forecasting outflow that it has several serious drawbacks.
We decided right away that we would not use standard approaches. In the championship, in addition to us, another 497 people registered, each of whom had a good experience behind them. So trying to do something in a standard way under such conditions is not a good idea.
And we began to solve the problems facing the binary classification model by predicting the probability distribution of customer churn time. A similar approach can be seen here , it allows you to more flexibly predict the outflow and test more complex hypotheses than in the classical approach. We chose the Weibull distribution for its widespread use in survival analysis as a family of distributions modeling time outflows. Customer behavior can be viewed as a kind of survival.
Here are examples of Weibull probability density distributions depending on parameters. and :
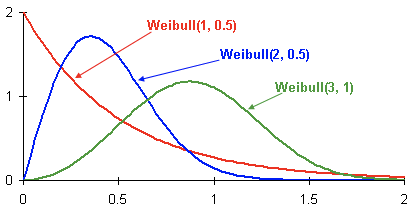
This is the probability distribution density of a customer’s outflow of three different customers over time. Time is presented in months. In other words, this graph shows when the outflow of a client is likely to occur in the next two months. As you can see, a client with a distribution has a greater potential to leave before clients with Weibull (2, 0.5) and Weibull (3.1) distributions.
The result is a model that for each client for any
Month predicts the parameters of the Weibull distribution, which best reflects the onset of the probability of an outflow over time. If more:
Here are the advantages of this method:
But it is not enough to create a good model, you also need to properly assess its quality.
We chose Lift Curve as a metric. It is used in business for such cases due to clear interpretation, it is well described here and here . If we describe the meaning of this metric in one sentence, it will turn out “How many times the algorithm makes a better prediction at the first % than randomly. "
The competition conditions did not establish a specific quality metric by which one can compare different models and approaches. Moreover, the definition of the concept of outflow may be different and may depend on the formulation of the problem, which, in turn, is determined by business goals. Therefore, in order to understand which method is better, we have trained two models:
The test sample consisted of 500 pre-selected customers who were not in the training sample. For the model, hyper-parameters were selected using cross-validation broken down by customers. For training each model used the same sets of features.
Due to the fact that the model does not have a memory, special features were taken for it, showing the ratio of changes in the parameters of one month to the average value of the parameters over the past three months. What characterized the rate of change of values over the last period of three months. Without this, the Random Forest-based model would be in a losing position relative to Weibull-LSTM.
It's all just a couple of pictures visually.
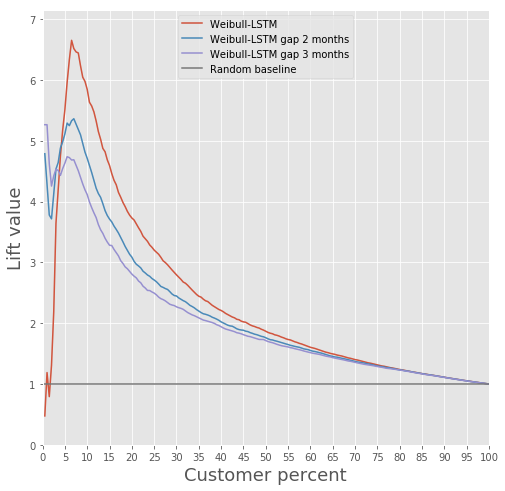
Lift Curve comparison for classic algorithm and Weibull-LSTM
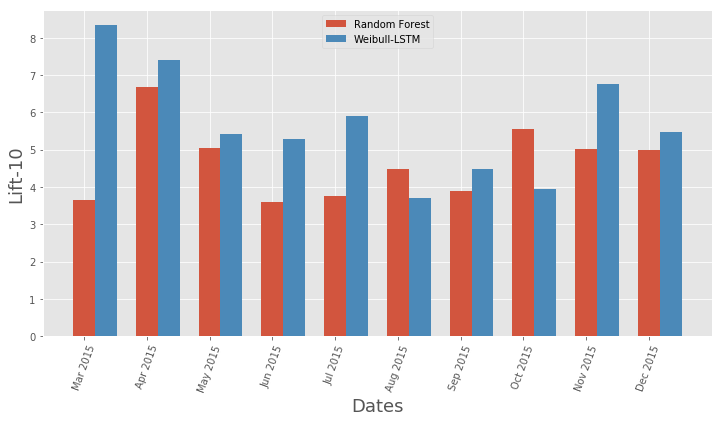
Monthly Lift Curve metric comparison for classic algorithm and Weibull-LSTM
In general, LSTM does the classic algorithm in almost all cases.
The model based on the recurrent neural neural network with LSTM-cells with Weibull distribution can predict outflow in advance, for example, predict the client’s departure within the next n months. Consider the case for n = 3. In this case, for each month the neural network must correctly determine whether the client leaves, starting from the next month and up to the n-th month. In other words, it must correctly determine whether the client will remain after n months. This can be considered a prediction in advance: the prediction of the moment when the client has just started thinking about leaving.
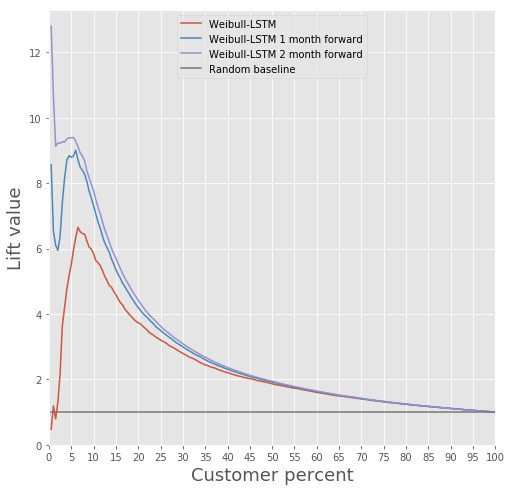
Compare the Lift Curve for Weibull-LSTM 1, 2 and 3 months before the outflow:
We have already written above that the forecasts that are made for clients who are not active for some time are also important. Therefore, here we will add to the sample such cases when a departed client has already been inactive for one or two months, and check that Weibull-LSTM correctly classifies such cases as outflow. Since such cases were present in the sample, we expect the network to cope well with them:
Actually, this is the main thing that can be done with the information that such and such clients are preparing to stop using the product. Speaking of building a model that could offer something useful to customers in order to keep them - this will not work if you don’t have a history of such attempts that would end well.
We did not have such a story, so we decided this.
The usual A / B testing can be used as a test of the quality of such retention - we divide clients who potentially leave into two groups. We offer products to one based on our retention model; we offer nothing to the second. We decided to train a model that could be useful already at point 1 of our example.
We wanted to make segmentation as interpretable as possible. To do this, we chose several signs that could be easily interpreted: the total number of transactions, wages, total turnover of the account, age, gender. The signs from the “Maps” table were not taken into account as uninformative, and the signs from Table 3 “Contracts” were not considered because of the complexity of processing in order to avoid data leakage between the validation set and the training set.
Clustering was carried out using Gaussian mixture models. Information criterion Akaike allowed to determine 2 optimum. The first optimum corresponds to 1 cluster. The second optimum, less pronounced, corresponds to 80 clusters. For this result, we can draw the following conclusion: it is extremely difficult to divide the data into clusters without a priori given information. For better clustering, we need data that describes each client in detail.
Therefore, the task of training with a teacher was considered in order to offer each individual client a product. The following products were considered: “Term Deposit”, “Credit Card”, “Overdraft”, “Consumer Credit”, “Car Loan”, “Mortgage”.
In the data there was another type of product: “Current Account”. But we did not consider him because of the low information content. For users who are bank customers, i.e. did not stop using his products; a model was built that predicted what product they might be interested in. A logistic regression was chosen as a model, and the Lift value for the first 10 percentiles was used as a quality assessment metric.
The quality of the model can be estimated in the figure.
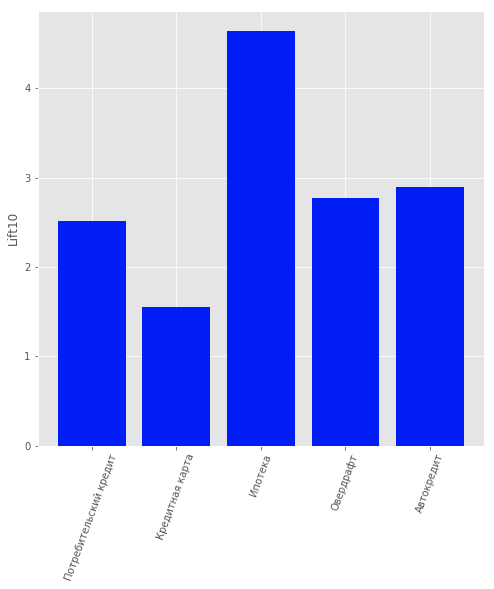
Results of product recommendation model for customers
This approach brought us the first place in the nomination “AI in banks” in the Championship on AI of the RAIF-Challenge 2017.

Apparently, the main thing was still to approach the problem from the not very familiar side, and to use the method that is customarily used for other situations.
Although a massive user outflow may well be a disaster for services.
This method can be noted and for any other area where it is important to take into account the outflow, not a single bank. For example, we used it to calculate our own outflow - in the Siberian and St. Petersburg branches of Rostelecom.
"Laboratory of Data Mining" company "Search portal" Sputnik "
There is such a topic as customer churn. A thing is inevitable, because customers of any company can, for a variety of reasons, take and stop using its products or services. Of course, for a company, the outflow is a natural, but not the most desirable, action, so everyone tries to minimize this outflow. And even better is to predict the likelihood of an outflow of a particular category of users, or a specific user, and suggest some steps to hold.
Analyze and try to keep the client, if possible, you need, at least for the following reasons:
')
- attracting new customers is more expensive than retention procedures . To attract new customers, as a rule, you need to spend some money (advertising), while existing customers can be activated with a special offer with special conditions;
- understanding customer care reasons is key to improving products and services .
There are standard approaches to predict churn. But at one of the championships on AI, we decided to take and try the Weibull distribution for this. It is most often used for survival analysis, weather forecasting, disaster analysis, industrial engineering, and the like. Weibull distribution is a special distribution function, parameterized by two parameters and .
Wikipedia
In general, the thing is entertaining, but for predicting the outflow, and indeed in Fintech, which is not used so often. Under the cut, we’ll tell you how we (the Laboratory of Data Mining) did this by winning gold in the Artificial Intelligence Championship in the nomination “AI in banks”.
About outflow in general
Let's take a quick look at what a customer churn is and why it is so important. For business, customer base is important. New clients come to this base, for example, having learned about a product or service from advertising, they live for some time (they actively use products) and after a while cease to use. This period is called the “Customer Lifecycle” (English Customer Lifecycle) is a term describing the steps that a customer goes through when he becomes aware of a product, makes a purchase decision, pays, uses and becomes a loyal consumer, and ultimately stops using one reason or another products. Accordingly, the outflow is the final stage of the client's life cycle, when the client ceases to use the services, and for business this means that the client has ceased to make a profit and in general any benefit.
Each bank customer is a specific person who chooses a particular bank card specifically for his needs. Often travels - useful card with miles. Buys a lot - hello, card with cashback. Buys a lot in specific stores - and for this there is already a special affiliate plastic. Of course, sometimes the card is selected and the criterion of "The cheapest service." In general, there are enough variables.
And another person chooses the bank itself - is there any point in choosing a bank card whose branches are only in Moscow and the region when you are from Khabarovsk? Whether the card of such a bank is at least 2 times more profitable, the presence of bank branches nearby is still an important criterion. Yes, 2019 is already here and digital is our everything, but a number of issues with some banks can be solved only in the branch. Plus, again, some part of the population trusts a physical bank much more, and not an application in a smartphone, this should also be taken into account.
As a result, a person may have many reasons for rejecting bank products (or the bank itself). I changed jobs, and the card rate changed from payroll to "For mere mortals", which is less profitable. Moved to another city where there are no bank branches. Did not like communication with unqualified cashier in the office. That is, there may even be much more reasons for closing an account than for using a product.
And the client can not just explicitly express his intention - to come to the bank and write a statement, but simply stop using the products without terminating the contract. Here, to understand these problems, it was decided to use machine learning and AI.
Moreover, customer churn can occur in any industry (telecom, Internet service providers, insurance companies, in general, wherever there is a customer base and periodic transactions).
What we did
First of all, it was necessary to describe a clear boundary - how long do we begin to consider the client gone? From the point of view of the bank that provided us with the data for work, the client's activity status was binary - it is either active or not. There was an ACTIVE_FLAG flag in the “Activity” table, the value of which could be either “0” or “1” (respectively, “Inactive” and “Active”). And everything is good, but the person is such that he can actively use some time, and then fall out of the number of active people for a month - he fell ill, went to another country to rest, or even went to test a card of another bank. Or after a long period of inactivity, once again start using the services of the bank
Therefore, we decided to call the inactivity period a certain continuous period of time, during which the flag for it was set to “0”.
Clients transition from inactive to active after periods of inactivity of various lengths. We have an opportunity to calculate the degree of empirical value “reliability of periods of inactivity” - that is, the probability that a person will again begin using the products of the bank after temporary inactivity.
For example, this graph shows the resumption of activity (ACTIVE_FLAG = 1) of clients after several months of inactivity (ACTIVE_FLAG = 0).
Here we will slightly clarify the data set we started working with. So, the bank provided aggregated information for 19 months in the following tables:
- “Activity” - monthly transactions of clients (via cards, in the Internet bank and in a mobile bank), including payroll and turnover information.
- "Cards" - data on all the cards that the customer has, with a detailed tariff scale.
- "Contracts" - information about the client's contracts (both open and closed): loans, deposits, etc., with an indication of the parameters of each.
- "Clients" - a set of demographic data (gender and age) and the availability of contact information.
To work we needed all the tables, except for the "Map".
The difficulty here was more than that - in these data the bank did not indicate what kind of activity was carried out on the cards. That is, we could understand whether there were transactions or not, but we could no longer determine their type. Therefore, it was unclear whether the client was withdrawing cash, whether he was paid a salary, or whether he was spending money on purchases. And we did not have data on account balances, which would be useful.
The sample itself was unbiased - at this time for 19 months the bank did not make any attempts to retain customers and minimize churn.
So, about the periods of inactivity.
To formulate the definition of outflow, you must select the period of inactivity. To create an outflow prediction at time , you must have a customer history of at least 3 months in the interval . Our history was limited to 19 months, so we decided to take a period of inactivity of 6 months, if it exists. And for the minimum period for a qualitative forecast they took 3 months. Figures in 3 and 6 months we took empirically based on the analysis of the behavior of customer data.
We formulated the definition of churn as follows: client churn month this is the first month with ACTIVE_FLAG = 0, where at least six zeros from this month go in the field ACTIVE_FLAG, in other words, the month since which the client has been inactive for 6 months.
Number of customers left
Number of customers remaining
How is considered to be outflow
In such competitions, and indeed in practice, the outflow is often predicted in this way. The client uses products and services at different time intervals, data on interaction with him are represented as a feature vector of fixed length n. Most often this information includes:
- User-specific data (demographic data, marketing segment).
- The history of using banking products and services (these are actions of customers that are always tied to a specific time or period of the interval we need).
- External data, if they managed to get - for example, reviews from social networks.
And after that, the definition of churn is derived, its own for each task. Then use the machine learning algorithm, which predicts the likelihood of leaving the client based on a vector of factors . For learning the algorithm, use one of the well-known frameworks for the construction of ensembles of decision trees, XGBoost , LightGBM , CatBoost, or their modifications.
The algorithm itself is not bad, but it is precisely in terms of forecasting outflow that it has several serious drawbacks.
- He does not possess the so-called "memory . " The input of the model receives a specified number of signs that correspond to the current point in time. In order to lay information on the history of changes in parameters, it is necessary to calculate special features that characterize changes in parameters over time, for example, the number or amount of banking transactions over the past 1,2,3 months. Such an approach can only partially reflect the nature of temporary changes.
- Fixed horizon prediction. The model is able to predict the outflow of clients only for a predetermined period of time, for example, the forecast for one month ahead. If a forecast is required for a different period of time, for example, for three months, then you need to rebuild the training sample and retrain the new model.
Our approach
We decided right away that we would not use standard approaches. In the championship, in addition to us, another 497 people registered, each of whom had a good experience behind them. So trying to do something in a standard way under such conditions is not a good idea.
And we began to solve the problems facing the binary classification model by predicting the probability distribution of customer churn time. A similar approach can be seen here , it allows you to more flexibly predict the outflow and test more complex hypotheses than in the classical approach. We chose the Weibull distribution for its widespread use in survival analysis as a family of distributions modeling time outflows. Customer behavior can be viewed as a kind of survival.
Here are examples of Weibull probability density distributions depending on parameters. and :
This is the probability distribution density of a customer’s outflow of three different customers over time. Time is presented in months. In other words, this graph shows when the outflow of a client is likely to occur in the next two months. As you can see, a client with a distribution has a greater potential to leave before clients with Weibull (2, 0.5) and Weibull (3.1) distributions.
The result is a model that for each client for any
Month predicts the parameters of the Weibull distribution, which best reflects the onset of the probability of an outflow over time. If more:
- Target features on the training set are the time remaining until the outflow in a particular month for a particular client.
- If there is no outflow indicator for the client, we assume that the outflow time is more than the number of months, starting from the current and to the end of our history.
- Model used: recurrent neural network with LSTM-layer.
- As a loss function, we use the negative logarithmic likelihood function for the Weibull distribution.
Here are the advantages of this method:
- The probabilistic distribution, in addition to the obvious possibility of binary classification, allows to predict different events flexibly, for example, will the client cease to use the services of a bank for 3 months. Also, if necessary, various metrics can be averaged over this distribution.
- The recurrent neural network LSTM has a memory and effectively uses the entire history available. With the expansion or refinement of history accuracy increases.
- The approach can be easily scaled when splitting time intervals into smaller ones (for example, when splitting months into weeks).
But it is not enough to create a good model, you also need to properly assess its quality.
How to evaluate the quality
We chose Lift Curve as a metric. It is used in business for such cases due to clear interpretation, it is well described here and here . If we describe the meaning of this metric in one sentence, it will turn out “How many times the algorithm makes a better prediction at the first % than randomly. "
We train models
The competition conditions did not establish a specific quality metric by which one can compare different models and approaches. Moreover, the definition of the concept of outflow may be different and may depend on the formulation of the problem, which, in turn, is determined by business goals. Therefore, in order to understand which method is better, we have trained two models:
- Frequently used binary classification approach using a decisive tree ensemble machine learning algorithm ( LightGBM );
- Model Weibull-LSTM
The test sample consisted of 500 pre-selected customers who were not in the training sample. For the model, hyper-parameters were selected using cross-validation broken down by customers. For training each model used the same sets of features.
Due to the fact that the model does not have a memory, special features were taken for it, showing the ratio of changes in the parameters of one month to the average value of the parameters over the past three months. What characterized the rate of change of values over the last period of three months. Without this, the Random Forest-based model would be in a losing position relative to Weibull-LSTM.
Than LSTM with Weibull distribution is better than approach based on ensemble of decision trees
It's all just a couple of pictures visually.
Lift Curve comparison for classic algorithm and Weibull-LSTM
Monthly Lift Curve metric comparison for classic algorithm and Weibull-LSTM
In general, LSTM does the classic algorithm in almost all cases.
Outflow prediction
The model based on the recurrent neural neural network with LSTM-cells with Weibull distribution can predict outflow in advance, for example, predict the client’s departure within the next n months. Consider the case for n = 3. In this case, for each month the neural network must correctly determine whether the client leaves, starting from the next month and up to the n-th month. In other words, it must correctly determine whether the client will remain after n months. This can be considered a prediction in advance: the prediction of the moment when the client has just started thinking about leaving.
Compare the Lift Curve for Weibull-LSTM 1, 2 and 3 months before the outflow:
We have already written above that the forecasts that are made for clients who are not active for some time are also important. Therefore, here we will add to the sample such cases when a departed client has already been inactive for one or two months, and check that Weibull-LSTM correctly classifies such cases as outflow. Since such cases were present in the sample, we expect the network to cope well with them:
Customer retention
Actually, this is the main thing that can be done with the information that such and such clients are preparing to stop using the product. Speaking of building a model that could offer something useful to customers in order to keep them - this will not work if you don’t have a history of such attempts that would end well.
We did not have such a story, so we decided this.
- We build a model that defines interesting products for each client.
- In each month we run the classifier and determine potentially leaving customers.
- Parts of customers offer a product, according to the model of paragraph 1, we remember our actions.
- A few months later, we are looking at which of these potentially leaving customers have left and who have remained. Thus we form a learning sample.
- We teach the model on the story obtained in paragraph 4.
- Optionally, repeat the procedure, replacing the model from clause 1 with the model obtained in clause 5.
The usual A / B testing can be used as a test of the quality of such retention - we divide clients who potentially leave into two groups. We offer products to one based on our retention model; we offer nothing to the second. We decided to train a model that could be useful already at point 1 of our example.
We wanted to make segmentation as interpretable as possible. To do this, we chose several signs that could be easily interpreted: the total number of transactions, wages, total turnover of the account, age, gender. The signs from the “Maps” table were not taken into account as uninformative, and the signs from Table 3 “Contracts” were not considered because of the complexity of processing in order to avoid data leakage between the validation set and the training set.
Clustering was carried out using Gaussian mixture models. Information criterion Akaike allowed to determine 2 optimum. The first optimum corresponds to 1 cluster. The second optimum, less pronounced, corresponds to 80 clusters. For this result, we can draw the following conclusion: it is extremely difficult to divide the data into clusters without a priori given information. For better clustering, we need data that describes each client in detail.
Therefore, the task of training with a teacher was considered in order to offer each individual client a product. The following products were considered: “Term Deposit”, “Credit Card”, “Overdraft”, “Consumer Credit”, “Car Loan”, “Mortgage”.
In the data there was another type of product: “Current Account”. But we did not consider him because of the low information content. For users who are bank customers, i.e. did not stop using his products; a model was built that predicted what product they might be interested in. A logistic regression was chosen as a model, and the Lift value for the first 10 percentiles was used as a quality assessment metric.
The quality of the model can be estimated in the figure.
Results of product recommendation model for customers
Total
This approach brought us the first place in the nomination “AI in banks” in the Championship on AI of the RAIF-Challenge 2017.
Apparently, the main thing was still to approach the problem from the not very familiar side, and to use the method that is customarily used for other situations.
Although a massive user outflow may well be a disaster for services.
This method can be noted and for any other area where it is important to take into account the outflow, not a single bank. For example, we used it to calculate our own outflow - in the Siberian and St. Petersburg branches of Rostelecom.
"Laboratory of Data Mining" company "Search portal" Sputnik "
Source: https://habr.com/ru/post/444694/
All Articles