We work with neural networks: checklist for debugging

The code for machine learning software products is often complex and rather confusing. Detection and elimination of bugs in it is a resource-intensive task. Even the simplest neural networks with direct connection require a serious approach to the network architecture, initialization of weights, network optimization. A small mistake can lead to unpleasant problems.
This article focuses on the debugging algorithm of your neural networks.
Skillbox recommends: Practical course Python-developer from scratch .
')
We remind: for all readers of "Habr" - a discount of 10,000 rubles when recording for any Skillbox course on the promotional code "Habr".
The algorithm consists of five stages:
- simple start;
- loss confirmation;
- checking intermediate results and connections;
- diagnostics of parameters;
- control work.
If something seems more interesting to you than the rest, you can skip ahead to these sections.
Easy start
A neural network with a complex architecture, regularization, and a learning speed planner is much harder to debug than a normal one. We are a little tricky here, since the point itself is indirectly related to debugging, but this is still an important recommendation.
A simple start is to create a simplified model and train it on one set (point) of data.
First create a simplified model.
For a quick start, we create a small network with a single hidden layer and check that everything works correctly. Then we gradually complicate the model, checking every new aspect of its structure (additional layer, parameter, etc.), and move on.
We teach the model on a single set (point) of data
As a quick test of the performance of your project, you can use one or two data points for training to confirm whether the system is working correctly. The neural network should show 100% accuracy of training and verification. If this is not the case, then either the model is too small, or you already have a bug.
Even if everything is fine, prepare the model for the passage of one or several eras before moving on.
Loss assessment
Loss assessment is the main way to clarify model performance. You need to make sure that the loss corresponds to the task, and the loss functions are evaluated on the correct scale. If you use more than one type of loss, then make sure that they are all of the same order and correctly scaled.
It is important to be attentive to initial losses. Check how close the actual result to the expected, if the model started with a random assumption. The work of Andrey Karpati suggests the following : “Make sure that you get the result you expect when you start working with a small number of parameters. It is better to check the data loss immediately (with setting the degree of regularization to zero). For example, for CIFAR-10 with the Softmax classifier, we expect the initial loss to be 2.302, because the expected diffuse probability is 0.1 for each class (since there are 10 classes), and the loss of Softmax is the negative logarithmic probability of the correct class as - ln (0.1) = 2.302 ".
For a binary example, a similar calculation is simply done for each of the classes. Here, for example, data: 20% 0's and 80% 1's. The expected initial loss will be up to –0.2ln (0.5) –0.8ln (0.5) = 0.693147. If the result is greater than 1, this may indicate that the weights of the neural network are not properly balanced or the data is not normalized.
We check intermediate results and connections
To debug a neural network, it is necessary to understand the dynamics of the processes within the network and the role of separate intermediate layers, since they are connected. Here are some common errors you may encounter:
- incorrect expressions for gradient updates;
- weight updates do not apply;
- disappearing or exploding gradients (exploding gradients).
If the gradient values are zero, this means that the learning rate in the optimizer is too low, or that you are faced with an incorrect expression for updating the gradient.
In addition, it is necessary to monitor the values of the functions of activations, weights and updates of each of the layers. For example, the value of parameter updates (weights and offsets) should be 1-e3 .
There is a phenomenon called “Dying ReLU” or “vanishing gradient problem” when ReLU neurons will display zero after studying a large negative bias value for its weights. These neurons are never activated anywhere else in the data.
You can use gradient checking to identify these errors by approximating the gradient using a numerical approach. If it is close to the calculated gradients, then the backward propagation was implemented correctly. To create a gradient check, check out these wonderful resources from CS231 here and here , as well as the Andrew Nga lesson on this topic.
Faizan Sheikh points out three main methods for visualizing a neural network:
- Preliminary - simple methods that show us the general structure of the trained model. They include the output of forms or filters of individual layers of the neural network and parameters in each layer.
- Based on activation. In them we decipher the activation of individual neurons or groups of neurons in order to understand their functions.
- Based on gradients. These methods tend to manipulate the gradients that are formed from going forward and backward when training a model (including significance maps and class activation maps).
There are several useful tools for visualizing the activations and connections of individual layers, for example, ConX and Tensorboard .
Parameter diagnostics
Neural networks have a lot of parameters that interact with each other, which complicates optimization. Actually, this section is the subject of active research by specialists; therefore, the suggestions below should be considered only as tips, starting points from which to proceed.
Packet size (batch size) - if you want the packet size to be large enough to get accurate estimates of the error gradient, but small enough so that the stochastic gradient descent (SGD) can order your network. Small package sizes will lead to a rapid convergence due to noise in the learning process and further to optimization difficulties. This is described in more detail here .
Learning speed — too low will result in slow convergence or the risk of getting stuck in local minima. At the same time, a high learning rate will cause a discrepancy in optimization, since you risk “jumping” through a deep, but narrow part of the loss function. Try using speed planning to reduce it in the process of learning a neural network. There is a large section on CS231n on this issue .
Gradient clipping - cropping of parameter gradients during back propagation at the maximum value or limit rate. Useful for solving problems with any exploding gradients that you may encounter in the third paragraph.
Batch normalization - used to normalize the input data of each layer, which allows to solve the problem of internal covariate shift. If you use Dropout and Batch Norma together, read this article .
Stochastic Gradient Descent (SGD) —There are several varieties of SGD that use momentum, adaptive learning rates, and the Nesterov method. At the same time, none of them has a clear advantage both in terms of learning efficiency and generalization ( see details here ).
Regularization is crucial for building a generalized model, because it adds a penalty for the complexity of the model or extreme values of the parameters. This is a way to reduce the dispersion of the model without significantly increasing its displacement. More information here .
To evaluate everything yourself, you need to disable regularization and check the data loss gradient yourself.
Dropout is another method of streamlining your network to prevent congestion. During training, the prolapse is carried out only by maintaining the activity of the neuron with a certain probability p (hyper parameter) or by setting it to zero in the opposite case. As a result, the network must use a different subset of parameters for each training batch, which reduces changes in certain parameters that become dominant.
Important: if you use both dropout and packet normalization, be careful with the order of these operations or even with their sharing. All this is still actively discussed and supplemented. Here are two important discussions on this topic on Stackoverflow and Arxiv .
Work control
It's about documenting workflows and experiments. If you do not document anything, you can forget, for example, what training speed or weight of classes is used. Thanks to the control, you can easily view and play back previous experiments. This reduces the number of duplicate experiments.
True, manual documentation can be a daunting task in case of a large amount of work. Tools like Comet.ml come to the rescue to help you automatically log data sets, code changes, experiment history and production models, including key information about your model (hyperparameters, model performance indicators, and environment information).
The neural network can be very sensitive to small changes, and this will lead to a drop in model performance. Tracking and documenting work is the first step to take in standardizing the environment and modeling.
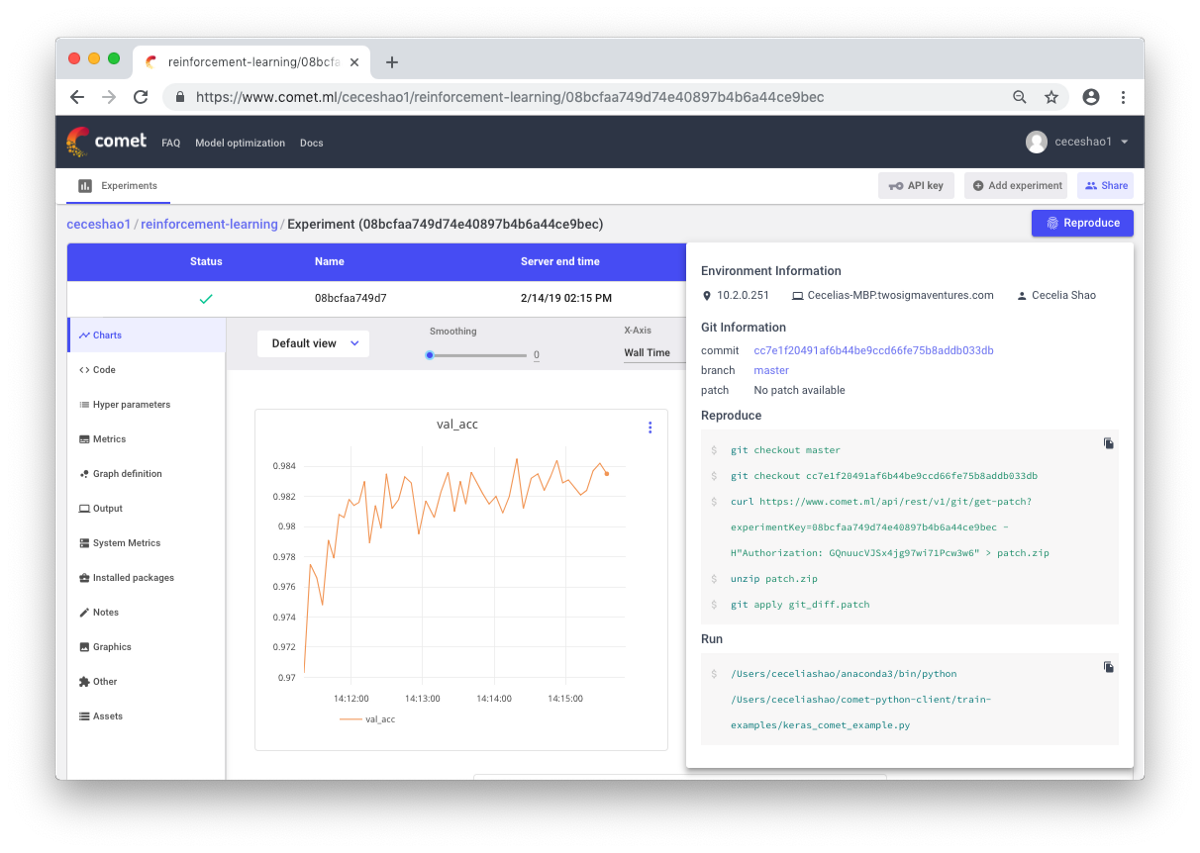
I hope that this post can be the starting point from which you will begin debugging your neural network.
Skillbox recommends:
- Two-year practical course "I am a web developer PRO" .
- Online course "C # developer with 0" .
- Practical annual course "PHP developer from 0 to PRO" .
Source: https://habr.com/ru/post/444684/
All Articles