DOTS stack: C ++ & C #

This is a brief introduction to our new data-oriented technology stack ( DOTS ). We will share some insights to help us understand how and why Unity today has become such, and also we will tell you in which direction we are planning to develop. In the future, we plan to publish new DOTS articles on the Unity blog.
Let's talk about C ++. This is the language in which modern Unity is written.
One of the most difficult problems of a game developer that one has to deal with one way or another is the following: a programmer must provide an executable file with instructions that the target processor understands and when the processor executes these instructions, the game should start.
In the part of the code that is sensitive to performance, we know in advance what the final instructions should be. We just need a simple way to consistently describe our logic, and then check and make sure that the instructions we need are generated.
')
We believe that the C ++ language is not too good for this task. For example, I want my cycle to be vectorized, but there may be a million reasons why the compiler will not be able to vectorize it. Either today it is vectorized, and tomorrow it is not, because of some seemingly trivial change. It's hard to even make sure that all my C / C ++ compilers will even begin to vectorize my code.
We decided to develop our own “quite convenient way of generating machine code”, which would meet all our wishes. It would have been possible to spend a lot of time to slightly bend the entire sequence of C ++ design in the right direction, but we decided that it would be much wiser to invest in the development of the toolchain, which would completely solve all the design problems that we face. We would develop it taking into account exactly the tasks that the game developer has to solve.
What factors do we give priority attention to?
- Performance = correct. I should be able to say: “if for some reason this cycle is not vectorized, then this must be a compiler error, and not a situation from the discharge” oh, the code began to work only eight times slower, but still produces correct values, business! ".
- Cross-platform. The input code that I write must remain exactly the same regardless of the target platform - be it iOS or Xbox.
- We need to have a neat iteration loop in which I can easily view the machine code generated for any architectures as I change my source code. The machine code “viewer” should help well with learning / explaining when you need to figure out what all these machine instructions are doing.
- Security. As a rule, game developers do not put security on high positions in their list of priorities, but we believe that one of the coolest features of Unity is that it’s really very difficult to damage memory. There should be a mode in which we run any code - and we unambiguously fix the error, in which the main letters display a message about what happened here: for example, I went beyond the boundaries when reading / writing or tried to dereference zero.
So, having figured out what is important for us, let us proceed to the next question: in what language is it better to write programs, from which such machine code will be then generated? Suppose we have the following options:
- Own language
- Some adaptation or subset of C or C ++
- C # subset
What what, C #? For our internal cycles, which performance is especially critical? Yes. C # is a completely natural choice, which in the Unity context involves a lot of very nice things:
- This is the language that our users already work with.
- It is perfectly equipped with IDE, both for editing / refactoring, and for debugging.
- There is already a compiler that converts C # to an intermediate IL (this is Roslyn compiler for C # from Microsoft), and you can simply use it rather than writing your own. We have a wealth of experience in converting an intermediate language to IL, so we just need to perform code generation and post-processing of a specific program.
- C # is devoid of many C ++ problems (hell including headers, PIMPL patterns, long compilation time)
I myself really like writing C # code. However, traditional C # is not the best language in terms of performance. The C # development team, the teams responsible for the standard library and the execution environment over the last couple of years have made tremendous progress in this area. However, working with C #, it’s impossible to control exactly where your data is stored in memory. Namely, we need to solve this problem to improve performance.
In addition, the standard library of this language is organized around “objects on the heap” and “objects that have links to other objects”.
At the same time, working with a code fragment in which performance is critical, you can almost completely dispense with the standard library (goodbye Linq, StringFormatter, List, Dictionary), prohibit selection operations (= no classes, only structures), reflection, disable garbage collection and virtual calls, as well as add a few new containers that are allowed to use (NativeArray and company). In this case, the remaining elements of the C # language already look very good. For examples, see Aras’s blog, where he describes a handicraft project of the path scanner.
Such a subset will help us to easily cope with all the tasks that are relevant when working with hot cycles. Since this is a complete subset of C #, you can work with it as you would with regular C #. We can get errors related to going abroad when trying to access, we get excellent error messages, the debugger will not be supported, and the compilation speed will be the one you forgot about when working with C ++. We often call such a subset “High-Performance C #” or HPC #.
Compiler Burst: what is today?
We wrote a code generator / compiler called Burst. It is available in Unity version 2018.1 and above as a package in the "preview" mode. Much work remains to be done with him, but we are pleased with him today.
Sometimes we manage to work faster than in C ++, often - still more slowly than in C ++. The second category includes performance bugs, which, we are convinced, we will manage to cope with.
However, a simple performance comparison is not enough. Equally important is what has to be done to achieve this kind of performance. Example: we took the culling code from our current C ++ renderer and ported it to Burst. Productivity has not changed, but in the C ++ version we had to deal with an incredible balancing act to persuade our C ++ compilers to do vectorization. The version with Burst was about four times smaller.
Honestly, the whole story with “you should rewrite your code that is critical in terms of performance to C #” didn’t attract anyone in the internal Unity team at first glance. For most of us, it sounded like “closer to the gland!” When working with C ++. But now the situation has changed. Using C #, we completely control the whole process from compiling the source code right through to generating the machine code, and if we don’t like any part, we just take it and fix it.
We are going to slowly but surely port all code critical in performance from C ++ to HPC #. In this language, it is easier to achieve the performance we need, it is harder to write a bug and easier to work.
Here is a screenshot of the Burst inspector, where you can easily see which build instructions were generated for your various hot cycles:
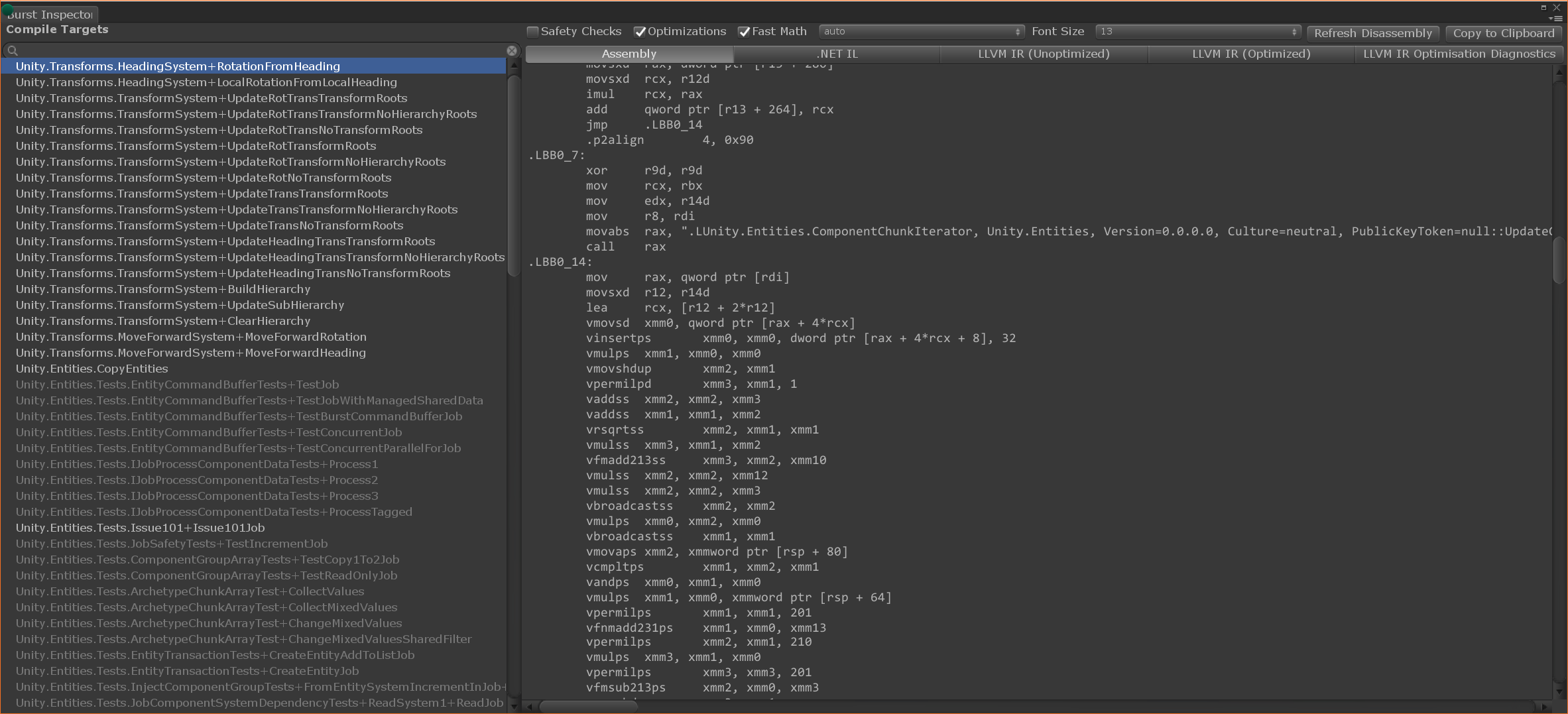
Unity has many different users. Some may, from memory, list the entire set of instructions arm64, others simply create with enthusiasm, even without a PhD in computer science.
All users win when it accelerates the fraction of frame time that is spent on executing the engine code (usually it is 90% +). The share of work with the executable code of the Asset Store package is really accelerating, since the authors of the Asset Store package are adopting HPC #.
Advanced users will additionally benefit from the fact that they themselves will be able to write their own high-performance code on HPC #.
Spot optimization
In C ++ it is very difficult to get the compiler to make different compromise decisions on code optimization in different parts of your project. The most detailed optimization that you can count on - per-file indication of the level of optimization.
Burst is designed so that you can take at the input the only method of this program, namely: the entry point to the hot cycle. Burst will compile this function, as well as all that it calls (such callable elements must be guaranteed to be known in advance: we do not allow virtual functions or function pointers).
Since Burst operates with only a relatively small part of the program, we set an optimization level of 11. Burst embeds almost every call site. Delete if-checks that would otherwise not be deleted, since in the embedded form we get more complete information about the function arguments.
How it helps solve common threading problems
C ++ (as well as C #) does not particularly help developers write thread-safe code.
Even today, more than a decade later, after a typical gaming processor has been equipped with two or more cores, it is very difficult to write programs that effectively use several cores.
Data races, non-determinism and interlocks are the main challenges that make it so difficult to write multi-threaded code. In this context, we need features from the category “to make sure that this function and everything that it calls will never read or write a global state”. We want all violations of this rule to give compiler errors, and not remain "rules, which, we hope, all programmers will adhere to." Burst throws a compilation error.
We strongly recommend Unity users (and adhere to the same in our circle) to write code so that all the data transformations planned in it are divided into tasks. Each task is “functional,” and, as a side effect, it is free. It clearly indicates read-only buffers and read / write buffers with which it has to work. Any attempt to access other data will cause a compilation error.
The Task Scheduler ensures that no one will write to your read-only buffer while your task is running. And we guarantee that for the duration of the assignment no one will read from your buffer intended for reading and writing.
Whenever you assign a task that violates these rules, you will get a compilation error. Not only in such a bad case as race conditions. The error message will explain that you are trying to assign a job that needs to be read from buffer A, but earlier you have already assigned a job that will write to A. Therefore, if you really want to do this, you must specify the previous job as a dependency .
We believe that such a safety mechanism helps to catch a lot of bugs before they are fixed, therefore, ensures the effective use of all the cores. It becomes impossible to provoke race conditions or deadlock. The results are guaranteed to be deterministic, regardless of how many threads you have, or how many times the stream is interrupted due to the intervention of some other process.
Mastering the whole stack
When we can get to all these components, we can also ensure that they know about each other. For example, the common cause of a breakdown of vectorization is this: the compiler cannot guarantee that two pointers will not point to the same memory point (aliasing). We know that two NativeArray will not overlap each other in any way because we wrote the collection library, and we can use this knowledge in Burst, so we will not give up optimization only for fear that two indicators may be sent to one and the same room.
Similarly, we wrote the Unity.Mathematics math library. Burst it is known “thoroughly”. Burst (in the future) will be able to point out optimization from point-to-point in cases like math.sin (). Since for Burst math.sin () is not just an ordinary C # method that needs to be compiled, it will "understand" and the trigonometric properties of sin (), it will understand that sin (x) == x for small x values (which Burst can independently prove ), will understand that it can be replaced by decomposition in a Taylor series, partly sacrificing at the same time accuracy. In the future, Burst also plans to realize cross-platform and design floating-point determinism - we believe that such goals are quite achievable.
The differences between the game engine code and the game code are erased.
When we write Unity runtime code on HPC #, the game engine and the game as such are written in the same language. We can distribute in the form of the source code of the runtime system, which we have converted to HPC #. Everyone can learn from them, improve them, adapt them for themselves. We will have a playing field of a certain level, and nothing will prevent our users from writing a higher-quality particle system, game physics or renderer than we wrote. By bringing together our internal development processes with user development processes, we will also be able to better feel ourselves in the shoes of the user, so we will throw all our strength on building a single workflow, rather than two different ones.
Source: https://habr.com/ru/post/444526/
All Articles