From parser posters of the theater in Python to Telegram-bot. Part 1

I love opera and ballet, but not very much - to give a lot of money for tickets. The daily viewing of the theater site with a poke into each button was terribly tiring, and the suddenly appearing tickets of 170 rubles for the super-trains stirred up the soul.
To automate this business a script appeared, which runs along the billboard and collects information on the cheapest tickets for the selected month. Inquiries from the series “give out a list of all operas in March on the old and new stages up to 1000 rubles”. A friend dropped "and you do not Telegram-bot?". This was not the plan, but why not. The bot was born, although it was spinning on a home laptop.
Then Telegram blocked. The idea of pushing a bot to a working server has melted away, and the interest to bring the functionality to mind has died away. Under the cut, I tell about the fate of a cheap ticket detective from the very beginning and about what happened to him after a year of use.
1. The origin of the idea and the formulation of the problem
In the original formulation, the whole story had one task - to form a list of performances filtered by price, in order to save time on manually viewing each performance of the poster separately. The only theater whose billboard interested, was and remains the Mariinsky. Personal experience quickly showed that the budget "gallery" opens on random days for random performances, and bought up quickly enough (if the composition is worthwhile). To not miss anything, and you need an automatic collector.
View of the poster with the buttons that you had to manually navigate
I wanted to get a limited set of interesting performances for running the script. The main criterion, as already mentioned, was the price of the ticket.
The API of the site and the ticket system is not in the public domain, so it was decided (without further ado) to parse the HTML pages, pulling out the necessary tags. Open the main one, press F12 and study the structure. It looked adequate, so it quickly came to the 1st implementation.
It is clear that this approach does not scale to other sites with posters and will fall down if the current structure is decided to change. If readers have ideas on how to make it more stable without an API, write in the comments.
2. First implementation. Minimum functionality
She came to the implementation with experience in working with Python only for solving problems related to machine learning. Yes, and some deep understanding of html and web-architecture was not (and did not appear). Therefore, everything was done according to the principle “I know where I am going, but we will find how to go now”
For the first sketches it took 4 evening hours and familiarity with the modules of requests and Beautiful Soup 4 (not without the help of a good article , thanks to the author). To finish the sketch - still a day off. I'm not sure that the modules are the most optimal in their segment, but they have closed the current needs. That's what happened in the first stage.
What information and where to pull can be understood by the structure of the site. First of all - we collect addresses of representations which are in the poster for the chosen month.
The structure of the poster page in the browser, everything is conveniently highlighted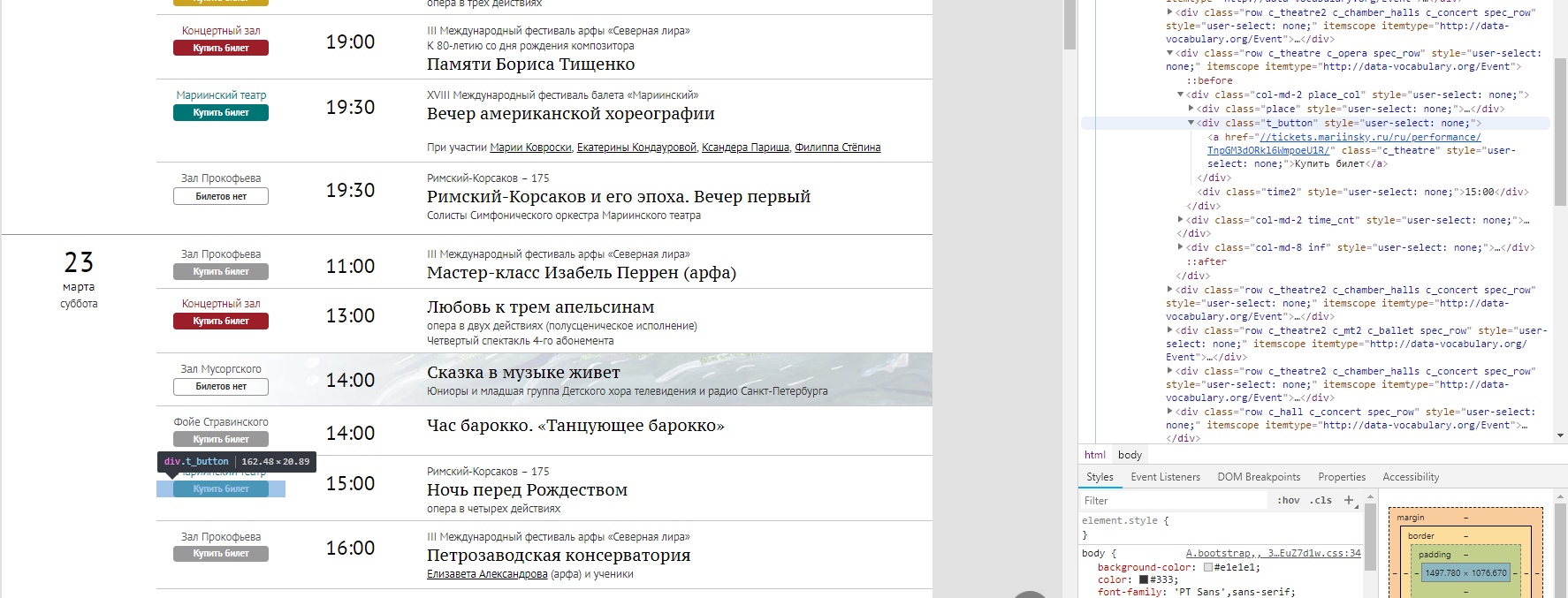
From the html page, we need to read the blank URLs, then to go over them and see the price tag. This is how the link list is built.
import requests import numpy as np from bs4 import BeautifulSoup def get_text(url): # URL html r = requests.get(url) text=r.text return text def get_items(text,top_name,class_name): """ html- "" url-, .. - . top_name class_name - <a class="c_theatre2 c_chamber_halls" href="//tickets.mariinsky.ru/ru/performance/WWpGeDRORFUwUkRjME13/"> </a> """ soup = BeautifulSoup(text, "lxml") film_list = soup.find('div', {'class': top_name}) items = film_list.find_all('div', {'class': [class_name]}) dirty_link=[] for item in items: dirty_link.append(str(item.find('a'))) return dirty_link def get_links(dirty_list,start,end): # "" URL- links=[] for row in dirty_list: if row!='None': i_beg=row.find(start) i_end=row.rfind(end) if i_beg!=-1 & i_end!=-1: links.append(row[i_beg:i_end]) return links # , , num=int(input(' : ')) #URL . , =) url ='https://www.mariinsky.ru/ru/playbill/playbill/?year=2019&month='+str(num) # top_name='container content gr_top' class_name='t_button' start='tickets' end='/">' # text=get_text(url) dirty_link=get_items(text,top_name,class_name) # URL-, links=get_links(dirty_link,start,end) After studying the structure of the page with the purchase of tickets, in addition to the threshold for the price, I decided to allow the user to also choose:
- type of performance (1-opera, 2-ballet, 3-concert, 4-lecture)
- venue (1-old stage, 2-new stage, 3-concert hall, 4-chamber halls)
Information is entered through the console in a numeric format, you can select multiple numbers. Such variability is dictated by the difference in the pricing policy for opera and ballet (opera is cheaper) and the desire to watch their lists separately.
The result is 4 questions and 4 filters per data — a month, a threshold by price, type, location.
')
Next we go through all the links received. We make get_text and look for a lower price on it, and also pull out the related information. Due to the fact that you have to look at each URL and convert it to text, the program’s running time is not instantaneous. It would be nice to optimize, but I did not think of how.
I will not give the code itself; it will turn out to be rather long, but there everything is really adequate and “intuitively clear” with Beautiful Soup 4.
If the price is less than the one declared by the user and the type-place corresponds to the set, then the console displays a message about the performance. There was another option to save all this in .xls, but it did not stick. It is more convenient to look in the console and immediately follow the links than to poke into the file.

About 150 lines of code are out. In this variant, with the described minimal functions, the script is more alive than all the living and runs regularly with a period of a couple of days. All other modifications were either not finished (the awl died down) and therefore inactive, or no more advantageous in function.
3. Expansion of functionality
At the second stage, I decided to track the price change, keeping the links to the performances of interest in a separate file (more precisely, the URL to them). First of all, this is true for ballets - they are rarely very cheap and will not fall into the overall budget issue. But from 5 thousand to 2x the fall is significant, especially if the performance is with a star composition, and it wanted to be tracked.
To do this, you must first add the URLs for tracking, and then periodically “shake up” them and compare the new price with the old one.
def add_new_URL(user_id,perf_url): #user_id , - WAITING_FILE = "waiting_list.csv" with open(WAITING_FILE, "a", newline="") as file: curent_url='https://'+perf_url text=get_text(curent_url) # - , ,, minP, name,date,typ,place=find_lowest(text) user = [str(user_id), perf_url,str(m)] writer = csv.writer(file) writer.writerow(user) def update_prices(): # print(' ') WAITING_FILE = "waiting_list.csv" with open(WAITING_FILE, "r", newline="") as file: reader = csv.reader(file) gen=[] for row in reader: gen.append(list(row)) L=len(gen) lowest={} with open(WAITING_FILE, "w", newline="") as fl: writer = csv.writer(fl) for i in range(L): lowest[gen[i][1]]=gen[i][2] # URL for k in lowest.keys(): text=get_text('https://'+k) minP, name,date,typ,place=find_lowest(text) if minP==0: # , "" minP=100000 if int(minP)<int(lowest[k]): # , lowest[k]=minP for i in range(L): if gen[i][1]==k: # - URL gen[i][2]=str(minP) print(' '+k+' '+str(minP)) writer.writerows(gen) add_new_URL('12345','tickets.mariinsky.ru/ru/performance/ZVRGZnRNbmd3VERsNU1R/') update_prices() The price update was launched at the beginning of the main script, it was not separately submitted. Maybe not as elegant as we would like, but it solves its problem. So the second additional functionality was the monitoring of price cuts for interesting performances.
Next was born Telegram-bot, not so easily, quickly, defiantly, but still born. In order not to collect everything in one pile, the story about it (as well as about unrealized ideas and an attempt to do this with the Bolshoi Theater website) will be in the second part of the article.
RESULT: the idea was a success, the user (s) are satisfied. It took a couple of days off to figure out how to interact with html pages. The benefit of Python is a language for almost everything and ready-made modules help drive a nail without thinking about the physics of the hammer.
I hope the case will be useful to habravchanam and, perhaps, will work as a magic Pendel, to finally make a wishlist that has long been sitting in my head.
Source: https://habr.com/ru/post/444460/
All Articles