How I rewrote the search engine of air tickets with PHP on NodeJS
Hey. My name is Andrey, I am a graduate student in one of the technical universities of Moscow and part-time very modest novice entrepreneur and developer. In this article I decided to share my experience of transition from PHP (which I once liked because of its simplicity, but over time I became hated by me - I explain why under the cut) to NodeJS. Very banal and seemingly elementary tasks can be cited here, which, nevertheless, I personally was curious to solve during my acquaintance with NodeJS and the features of server-side development in JavaScript. I will try to explain and visually prove that PHP has finally gone to sunset and lost its place to NodeJS. It may even be useful for someone to learn some features of rendering HTML pages in Node, which is not originally adapted to this from the word at all.
Introduction
While writing the engine, I used the simplest techniques. No package managers, no routing. Only hardcore - the folders whose name corresponded to the requested route, and the index.php in each of them, configured by PHP-FPM to maintain a pool of processes. Later it became necessary to use Composer and Laravel, which was the last straw for me. Before turning to the story about why I even took to rewrite everything from PHP to NodeJS, I’ll tell you a little about the background.
Package manager
At the end of 2018, it was possible to work with one project written in Laravel. It was necessary to fix a few bugs, make changes to the existing functionality, add a few new buttons in the interface. The process began with the installation of the package manager and dependencies. In PHP, Composer is used for this. Then the customer provided a server with 1 core and 512 MB of RAM, and this was my first experience with Composer. When installing dependencies on a virtual private server with 512 megabytes of memory, the process ended abnormally due to a lack of memory.

For me, as a person familiar with Linux and having experience with Debian and Ubuntu, the solution to such a problem was obvious - installing a SWAP file (the paging file is for those who are not familiar with Linux administration). A beginner inexperienced developer who has installed his first Laravel distribution on Digital Ocean, for example, will simply go to the control panel and raise the tariff until the dependency installation stops completing with a memory segmentation error. And how are things going with NodeJS?
And NodeJS has its own package manager, npm. It is much easier to use, more compact, it can work even in an environment with a minimum amount of RAM. In general, Composer doesn’t blame NPO in the background, but if there are any errors when installing the packages, Composer will crash with an error like a regular PHP application and you will never know how much of the package was installed and whether it was installed at the end ends And in general, for the Linux administrator, the installation crashed = flashbacks in Rescue Mode and dpkg --configure -a . By the time I was overtaken by such "surprises", I didn’t like PHP, but these were the last nails in the coffin of my once great love for PHP.
Long-term support and versioning problem
Remember, what excitement and amazement caused PHP7, when the developers first presented it? More than 2 times performance increase, and in some components up to 5 times! Do you remember when PHP came up with the seventh version? And how quickly WordPress earned! It was December 2015. Did you know that PHP 7.0 is already considered an outdated version of PHP and it is highly recommended to upgrade it ... No, not to version 7.1, but to version 7.2. According to the developers, version 7.1 is already deprived of active support and receives only security updates. And after 8 months it will stop. It will stop, along with active support and version 7.2. It turns out that by the end of this year, PHP will have only one current version - 7.3.

In fact, it would not be a niggle and I would not attribute this to the reasons for my leaving PHP, if the projects written by me in PHP 7.0. * Already did not cause a deprecation warning when opening. Let's return to the project where the installation of dependencies took off. This was a project written in 2015 on Laravel 4 with PHP 5.6. It seemed that only 4 years had passed, but en-no - a bunch of deprecation-warnings, outdated modules, the inability to properly upgrade to Laravel 5 due to a heap of root engine updates.
And this concerns not only Laravel itself. Try to take any PHP application written in the days of active support for the first versions of PHP 7.0 and be prepared to spend your evening looking for solutions to problems encountered in obsolete PHP modules. Finally, an interesting fact: support for PHP 7.0 was discontinued earlier than support for PHP 5.6. For a moment.
How are things with NodeJS? I would not say that everything is much better here, and that the terms of support for NodeJS are radically different from PHP. No, everything is about the same here - each LTS version is supported for 3 years. Only NodeJS has a bit more of these most current versions.
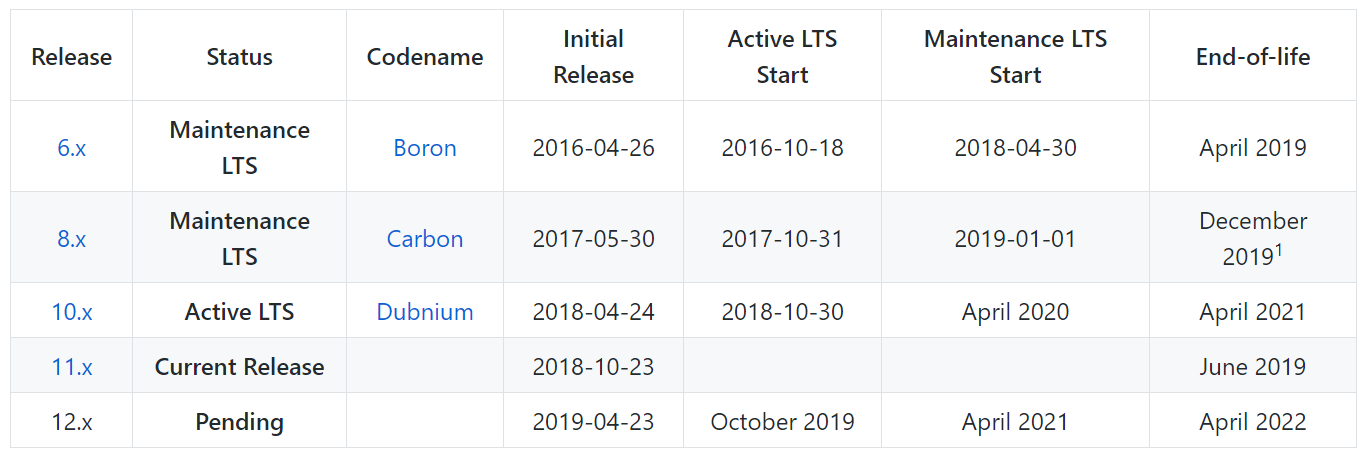
If you need to deploy an application written in 2016, you can be sure that you will have absolutely no problems with it. Incidentally, version 6. * will no longer be supported only in April of this year. And there are still 8, 10, 11 and upcoming 12.
On the difficulties and surprises in the transition to NodeJS
I will begin, perhaps, with the most exciting question of how to render HTML pages in NodeJS. But let's start by remembering how this is done in PHP:
- Embed HTML directly into PHP code. So do all the novices who have not yet reached MVC. And so done in WordPress, which is absolutely terrifying.
- Use MVC, which should simplify the interaction of the developer and provide some sort of breaking up the project into parts, but in reality this approach only complicates everything at times.
- Use a template engine. The most convenient option, but not in PHP. Just look at the syntax suggested in Twig or Blade with braces and percentages.
I am an ardent opponent of combining or merging several technologies together. HTML should exist separately, styles for it - separately, JavaScript-separately (in React it generally looks monstrous - HTML and JavaScript mixed together). That is why the ideal option for developers with preferences like mine is a template engine. It didn’t take long to search for a web application on NodeJS and I made a choice in favor of Jade (PugJS). Just appreciate the simplicity of its syntax:
div.row.links div.col-lg-3.col-md-3.col-sm-4 h4.footer-heading . div.copyright div.copy-text 2017 - #{current_year} . div.contact-link span : a(href='mailto:hello@flaut.ru') hello@flaut.ru Everything is quite simple here: I wrote the template, loaded it into the application, compiled it once and then used in any convenient place at any convenient time. I feel that PugJS’s performance is about 2 times better than rendering with the help of embedding HTML in PHP code. If earlier in PHP a static page was generated by the server in about 200-250 milliseconds, now this time is about 90-120 milliseconds (this is not about rendering in PugJS, but about the time taken from the page request to the server response to the client with ready HTML ). This is how the loading and compilation of templates and their components looks like at the stage of application launch:
const pugs = {} fs.readdirSync(__dirname + '/templates/').forEach(file => { if(file.endsWith('.pug')) { try { var filepath = __dirname + '/templates/' + file pugs[file.split('.pug')[0]] = pug.compile(fs.readFileSync(filepath, 'utf-8'), { filename: filepath }) } catch(e) { console.error(e) } } }) // return pugs.tickets({ ...config }) It looks incredibly simple, but with Jade there was a little difficulty at the stage of working with already compiled HTML. The fact is that for the introduction of scripts on the page an asynchronous function is used, which takes all the .js files from the directory and adds to each of them the date of their last change. The function is as follows:
for(let i = 0; i < files.length; i++) { let period = files[i].lastIndexOf('.') // get last dot in filename let filename = files[i].substring(0, period) let extension = files[i].substring(period + 1) if(extension === 'js') { let fullFilename = filename + '.' + extension if(env === 'production') { scripts.push({ path: paths.production.web + fullFilename, mtime: await getMtime(paths.production.code + fullFilename)}) } else { if(files[i].startsWith('common') || files[i].startsWith('search')) { scripts.push({ path: paths.developer.scripts.web + fullFilename, mtime: await getMtime(paths.developer.scripts.code + fullFilename)}) } else { scripts.push({ path: paths.developer.vendor.web + fullFilename, mtime: await getMtime(paths.developer.vendor.code + fullFilename)}) } } } } At the output we get an array of objects with two properties - the path to the file and the time it was last edited in the timestamp (for updating the client cache). The problem is that even at the stage of collecting script files from a directory, they are all loaded into memory strictly alphabetically (as they are located in the directory itself, and the collection of files in it is done from top to bottom - from first to last). This led to the fact that the app.js file was loaded first, and after it the core.min.js file came with the polyfills, and at the very end, vendor.min.js . This problem was solved quite simply - a very banal sorting:
scripts.sort((a, b) => { if(a.path.includes('core.min.js')) { return -1 } else if(a.path.includes('vendor.min.js')) { return 0 } return 1 }) In PHP, this all had a monstrous appearance in the form of pre-recorded paths to the JS-files. Simple but impractical.
NodeJS keeps its application in RAM
This is a huge plus. I have everything arranged so that on the server in parallel and independently from each other there are two separate sites - the developer version and the production version. Imagine that I made some changes to the PHP files on the development site and I need to roll out these changes to production. To do this, you need to stop the server or set the "sorry, tech. Work" stub and at this time copy the files separately from the developer folder to the production folder. This causes some kind of simple and can lead to a loss of conversions. The advantage of the in-memory application in NodeJS is for me that all changes to the engine files will be made only after rebooting it. This is very convenient, since you can copy all the necessary files with changes and only then restart the server. The process takes no more than 1-2 seconds and will not cause downtime.
The same approach is used in nginx, for example. You first edit the configuration, check it with nginx -t and only then make changes with service nginx reload
NodeJS application clustering
NodeJS has a very handy tool - the pm2 process manager . How do we usually run applications in Node? We come into the console and we write node index.js . As soon as we close the console, the application closes. At least that's what happens on the server with Ubuntu. To avoid this and keep the application running at all, just add it to pm2 with a simple command pm2 start index.js --name production . But that is not all. The tool allows monitoring ( pm2 monit ) and application clustering.
Let's remember how processes are organized in PHP. Suppose we have a nginx servicing http requests and we need to send a request to PHP. You can either do this directly, and then with each request, the new PHP process will spawn, and when it is completed, it will be killed. And you can use a fastcgi server. I think everyone knows what it is and there is no need to go into details, but just in case, I’ll clarify that PHP-FPM is most often used as fastcgi and its task is to drop many PHP processes that are ready to accept and process a new request at any time. What is the disadvantage of this approach?
The first is that you never know how much memory your application will consume. Secondly, you will always be limited in the maximum number of processes, and accordingly, with a sharp jump in traffic, your PHP application either uses all the available memory and drops, or rests on the permissible limit of processes and starts to kill old ones. This can be prevented by setting a not-remember-some parameter in the PHP-FPM configuration file to dynamic and then there will be as many processes as needed at this time. But again, the elementary DDoS attack will take out all the RAM and put your server. Or, for example, a bugged script will eat up all the RAM and the server will hang for a while (there were precedents in the development process).
The fundamental difference in NodeJS is that the application can not consume more than 1.5 gigabytes of RAM. There are no restrictions on the processes, there is only a limit on memory. It stimulates to write the most lightweight programs. In addition, it is very easy to calculate the number of clusters that we can afford, depending on the available CPU resource. It is recommended to “hang” no more than one cluster on each core (exactly as in nginx - no more than one worker per CPU core).

The advantage of this approach is that PM2 reboots all clusters in turn. Returning to the previous paragraph, which spoke about a 1-2 second downtime at reboot. In Cluster-Mode, when the server is restarted, your application will not experience a millisecond downtime.
NodeJS is a good Swiss knife
Now there is a situation where PHP acts as a language for writing sites, and Python acts as a tool for crawling these same sites. NodeJS is 2 in 1, on the one hand a fork, on the other - a spoon. You can write fast and productive applications and web crawlers on the same server within the same application. It sounds tempting. But how can this be realized, you ask? Google itself rolled out the official API from Chromium - Puppeteer. You can run Headless Chrome (a browser without a user interface - "headless" Chrome) and get the widest possible access to the API browser to crawl pages. The most simple and accessible about the work of Puppeteer .
For example, in our VKontakte group there is a regular posting of discounts and special offers for various destinations from cities of the CIS. We generate images for posts in automatic mode, and to make them more beautiful, we need beautiful pictures. I don’t like to be tied to various APIs and have accounts on dozens of sites, so I wrote a simple application that simulates a regular user with Google Chrome browser, which walks around the site with stock images and randomly picks up the image found by the keyword. I used to use Python and BeautifulSoup for this, but now this is no longer necessary. And the most important feature and advantage of Puppeteer is that you can easily steal even SPA-sites, because you have at your disposal a full-fledged browser that understands and executes JavaScript-code on sites. It is painfully simple:
const browser = await puppeteer.launch({headless: true, args:['--no-sandbox']}) const page = (await browser.pages())[0] await page.goto(`https://pixabay.com/photos/search/${imageKeyword}/?cat=buildings&orientation=horizontal`, { waitUntil: 'networkidle0' }) So in 3 lines of code, we launched a browser and opened a page of the site with stock images. Now we can choose a random block with an image on the page and add a class to it, by which we can later apply in the same way and go directly to the page directly with the image itself for its further loading:
var imagesLength = await page.evaluate(() => { var photos = document.querySelectorAll('.search_results > .item') if(photos.length > 0) { photos[Math.floor(Math.random() * photos.length)].className += ' --anomaly_selected' } return photos.length }) Remember how much code it would take to write something like this on PhantomJS (which, by the way, closed and entered into close cooperation with the development team Puppeteer). Is the presence of such a wonderful tool can stop someone from moving to NodeJS?
NodeJS has asynchrony at the fundamental level
This can be considered a huge advantage of NodeJS and JavaScript, especially with the arrival of async / await in ES2017. Unlike PHP, where any call is executed synchronously. I will give a simple example. Previously, in our search engine, pages were generated on the server, but something needed to be displayed on the page already in the client using JavaScript, and at that time Yandex was not yet able to use JavaScript on the sites and had to implement the snapshot mechanism (snapshots) for it using Prerender. Snapshots were stored on our server and issued to the robot upon request. The dilemma was that these images were generated within 3-5 seconds, which is completely unacceptable and may affect the ranking of the site in the search results. To solve this problem, a simple algorithm was invented: when a robot requests some page, we already have a snapshot, we simply give it a snapshot that we already have, after which we perform an operation to create a new snapshot and replace them already available. How it was done in PHP:
exec('/usr/bin/php ' . __DIR__ . '/snapshot.php -a ' . $affiliation_type . ' -l ' . urlencode($full_uri) . ' > /dev/null 2>/dev/null &'); Never do that.
In NodeJS, this can be achieved by calling an asynchronous function:
async function saveSnapshot() { getSnapshot().then((res) => { db.saveSnapshot().then((status) => { if(status.err) console.error(err) }) }) } /** * await * .. resolve() */ saveSnapshot() In short, you are not trying to bypass synchronization, but you decide when to use synchronous code execution, and when it is asynchronous. And it is really convenient. Especially when you learn about Promise.all () features .
The ticket search engine itself is designed in such a way that it sends a request to the second server, which collects and aggregates data, and then refers to it for data that is already ready for issue. To attract traffic from organic use page directions.
For example, at the request "Flights Moscow St. Petersburg" a page with the address / tickets / moscow / saint-petersburg / will be issued, and on it you need the data:
- Prices of air tickets in this direction for the current month
- Airfare prices in this area for the year ahead (average price for each month for the next 12 months)
- Flight schedule for this destination
- Popular destinations from the city of dispatch - from Moscow (for re-linking)
- Popular destinations from the city of arrival - from St. Petersburg (for relink)
In PHP, all these requests were executed synchronously - one by one. The average API response time for one request is 150-200 milliseconds. Multiply 200 by 5 and get on average a second only to fulfill requests to the server with data. NodeJS has a great function Promise.all , which executes all requests in parallel, but records the result one by one. For example, the code to execute all five of the above queries would look like this:
var [montlyPrices, yearlyPrices, flightsSchedule, originPopulars, destPopulars] = await Promise.all([ getMontlyPrices(), getYearlyPrices(), getFlightSchedule(), getOriginPopulars(), getDestPopulars() ]) And we get all the data in 200-300 milliseconds, reducing the time of data generation for a page from 1-1.5 seconds to ~ 500 milliseconds.
Conclusion
Switching from PHP to NodeJS helped me to get acquainted with asynchronous JavaScript better, to learn how to work with promises and async / await. After the engine was rewritten, the page loading speed was optimized and differed dramatically from the results that the PHP engine showed. In this article, you could still tell how easy it is to use modules for working with cache (Redis) and pg-promise (PostgreSQL) in NodeJS and compare them with Memcached and php-pgsql, but this article turned out to be quite voluminous. And knowing my "talent" for writing, it turned out to be also poorly structured. The purpose of writing this article is to attract the attention of developers who are still working with PHP and are not aware of the virtues of NodeJS and the development of web-based applications using the example of a real-life project that was once written in PHP, but because of preferences its owner went to another platform.
I hope that I managed to convey my thoughts and more or less structured to present them in this material. At least I tried :)
Write any comments - benevolent or angry. I will respond to any constructive.
')
Source: https://habr.com/ru/post/444400/
All Articles