Machine orientation over long distances with automated reinforcement learning
Only in the United States alone there are 3 million people with limited mobility who cannot leave their homes. Auxiliary robots that can automatically navigate long distances can make such people more independent by bringing them food, medicine, and packages. Studies show that deep reinforcement learning (OP) is well suited for comparing raw input data and actions, for example, for learning to capture objects or moving robots , but usually OP agents have no understanding of large physical spaces necessary for safe orientation to distant distances without human help and adaptation to the new environment.
In three recent works, " Learning to Oriente from the Ground with AOP ", " PRM-RL: Implementing Robotic Orientation over Long Distances with a Combination of Learning with Reinforcement and Sample-Based Planning " and " Long-Range Orientation with PRM-RL We study autonomous robots that easily adapt to the new environment, combining deep EP with long-term planning. We train local scheduling agents to perform basic actions necessary for orientation, and to move over short distances without colliding with moving objects. Local planners make noisy observations of the environment using sensors such as one-dimensional lidars, giving the distance to the obstacle, and give linear and angular velocities to control the robot. We train the local scheduler in simulations using automated reinforcement learning (AOP), a method that automates the search for rewards for the OP and neural network architecture. Despite the limited radius of action, 10–15 m, local planners adapt well both to use in real robots and to new, previously unknown environments. This allows them to be used as building blocks for orientation in large spaces. Then we build a roadmap, a graph where the nodes are separate sections, and the edges connect the nodes only if the local planners, who imitate real robots well with the help of noisy sensors and controls, can move between them.
In our first job, we train the local scheduler in a static environment of small size. However, when learning with a standard deep OT algorithm, for example, a deep deterministic gradient ( DDPG ), you can encounter several obstacles. For example, the real goal of local planners is to achieve a given goal, with the result that they receive rare rewards. In practice, this requires researchers to spend considerable time on the step-by-step implementation of the algorithm and the manual adjustment of rewards. Also, researchers have to make decisions about the architecture of neural networks, not having clear successful recipes. And finally, algorithms such as DDPG are unstable and often demonstrate catastrophic forgetfulness .
To overcome these obstacles, we have automated deep learning with reinforcements. AOP is an evolutionary automatic wrapper around a deep OP, looking for rewards and neural network architecture with the help of large-scale optimization of hyper-parameters . It works in two stages, the search for awards and the search for architecture. During the search for rewards, AOP simultaneously trains a population of DDPG agents for several generations, and each one has its own slightly modified reward function optimized for the true task of the local scheduler: reaching the end point of the path. At the end of the reward search phase, we choose the one that most often leads agents to the goal. In the search phase of the neural network architecture, we repeat this process for this race using the chosen reward and adjusting the network layers, optimizing the cumulative reward.
')
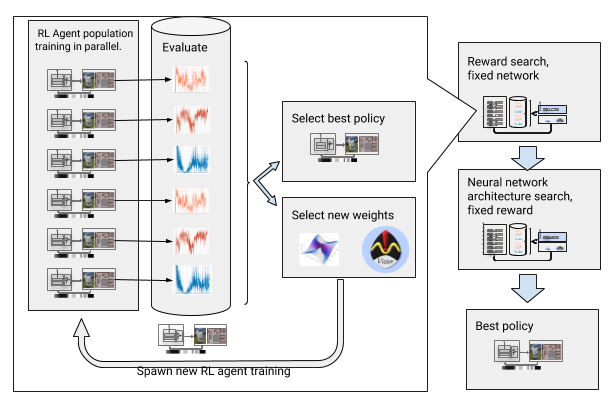
AOP with search awards and neural network architecture
However, this step-by-step process makes AOP ineffective in terms of the number of samples. Training AOP with 10 generations of 100 agents requires 5 billion samples, equivalent to 32 years of training! The advantage is that after AOP, the manual learning process is automated, and DDPG does not have a catastrophic forgetting. Most importantly, the quality of the resulting policies is higher - they are resistant to noise from the sensor, drive and localization, and are well generalized to new environments. Our best policy is 26% more successful than other orienteering methods at our test sites.
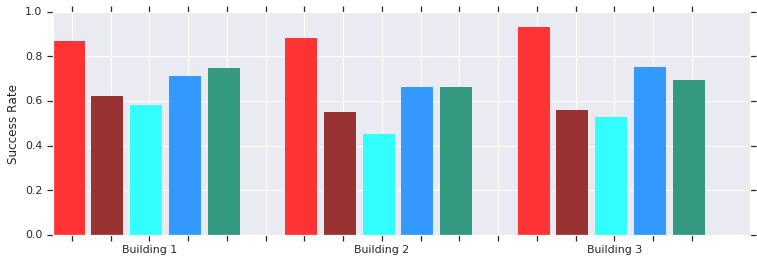
Red - AOP successes at short distances (up to 10 m) in several unknown buildings. Comparison with manually trained DDPG (dark red), artificial potential fields (blue), dynamic window (blue) and behavior cloning (green).
The local AOP scheduler policy works well with robots in real unstructured environments.
And although these policies are only capable of local orientation, they are resistant to moving obstacles and are well tolerated on real robots in unstructured environments. And although they were trained in simulations with static objects, they effectively cope with moving objects. The next step is to combine AOP policies with sample-based layout to expand their field of work and teach them how to navigate long distances.
Sample-based planners work with orientation over long distances, approximating the movements of the robot. For example, the robot builds probabilistic roadmaps (PRM), passing realizable transition paths between sections. In our second job , which won an award at the ICRA 2018 conference, we combine PRM with manually adjusted local OP planners (without AOP) to train robots locally, and then adapt them to other environments.
First, for each robot, we teach the local scheduler policy in a generalized simulation. Then we create PRM taking into account this policy, the so-called PRM-RL, based on the map of the environment where it will be used. The same card can be used for any robot we wish to use in the building.
To create a PRM-RL, we merge nodes from samples only if the local OP-scheduler can reliably and repeatedly move between them. This is done in a Monte Carlo simulation. The resulting map adapts to the capabilities and geometry of a particular robot. Cards for robots with the same geometry, but different sensors and actuators, will have different connectivity. Since the agent can turn the corner, you can include nodes that are not in direct line of sight. However, nodes located near walls and obstacles will be included in the map with a lower probability due to noise from sensors. During execution, the OP agent moves on the map from one site to another.

A map is created with three Monte-Carlo simulations for each randomly selected pair of nodes.
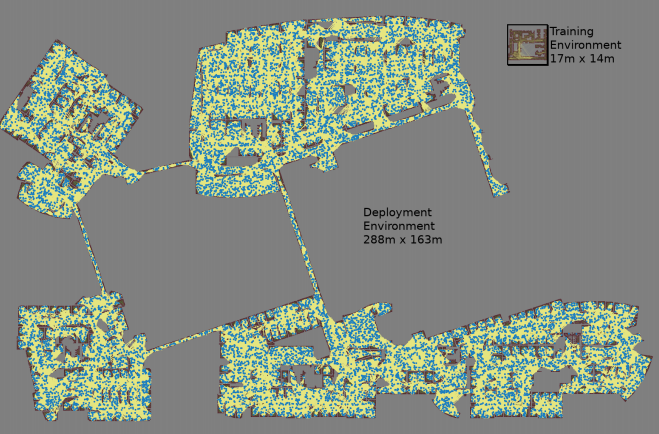
The largest map was 288x163 m in size and contained almost 700,000 ribs. 300 workers collected it for 4 days, having spent 1.1 billion collision checks.
The third work provides several improvements to the original PRM-RL. First, we replace the manually adjusted DDPG with local schedulers with AOP, which gives an improvement in orientation over long distances. Secondly, simultaneous localization and markup maps ( SLAM ) are added, which robots use at runtime as a source for building roadmaps. SLAM cards are subject to noise, and this closes the “gap between the simulator and reality”, a problem known in robotics, due to which agents trained in simulations behave much worse in the real world. Our level of success in the simulation coincides with the level of success of real robots. And finally, we added distributed building maps, so we can create very large maps containing up to 700,000 nodes.
We evaluated this method with the help of our AOP agent, who created maps based on blueprints of buildings that were 200 times more than the training environment, including only edges, which were successfully completed in 90% of cases in 20 attempts. We compared the PRM-RL with various methods at distances of up to 100 m, seriously exceeding the range of the local scheduler. PRM-RL achieved success 2-3 times more often than usual methods due to the correct connection of nodes, suitable for the capabilities of the robot.
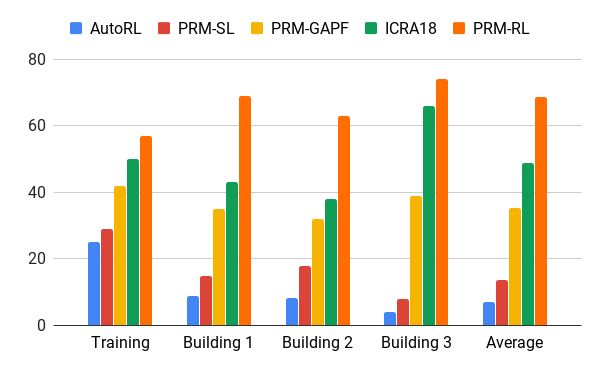
The percentage of success in moving 100 meters in different buildings. Blue - local AOP scheduler, first job; red - original PRM; yellow - artificial potential fields; green is the second job; red is the third job, PRM with AOP.
We tested PRM-RL on a variety of real robots in a variety of buildings. Below is one of the test suites; the robot moves reliably almost everywhere, except for the most erratic places and areas beyond the SLAM card.

Machine orientation can seriously increase the independence of people with reduced mobility. This can be achieved by developing autonomous robots that can easily adapt to the environment, and the methods available for implementation in the new environment based on the information already available. This can be done by automating basic orientation training for small distances with AOP, and then use the acquired skills together with the SLAM maps to create roadmaps. Road maps consist of nodes connected by edges, along which robots can safely move. As a result, a policy of robot behavior is developed, which, after one training, can be used in different environments and issue roadmaps specially adapted for a specific robot.
In three recent works, " Learning to Oriente from the Ground with AOP ", " PRM-RL: Implementing Robotic Orientation over Long Distances with a Combination of Learning with Reinforcement and Sample-Based Planning " and " Long-Range Orientation with PRM-RL We study autonomous robots that easily adapt to the new environment, combining deep EP with long-term planning. We train local scheduling agents to perform basic actions necessary for orientation, and to move over short distances without colliding with moving objects. Local planners make noisy observations of the environment using sensors such as one-dimensional lidars, giving the distance to the obstacle, and give linear and angular velocities to control the robot. We train the local scheduler in simulations using automated reinforcement learning (AOP), a method that automates the search for rewards for the OP and neural network architecture. Despite the limited radius of action, 10–15 m, local planners adapt well both to use in real robots and to new, previously unknown environments. This allows them to be used as building blocks for orientation in large spaces. Then we build a roadmap, a graph where the nodes are separate sections, and the edges connect the nodes only if the local planners, who imitate real robots well with the help of noisy sensors and controls, can move between them.
Automatic reinforcement learning (AOP)
In our first job, we train the local scheduler in a static environment of small size. However, when learning with a standard deep OT algorithm, for example, a deep deterministic gradient ( DDPG ), you can encounter several obstacles. For example, the real goal of local planners is to achieve a given goal, with the result that they receive rare rewards. In practice, this requires researchers to spend considerable time on the step-by-step implementation of the algorithm and the manual adjustment of rewards. Also, researchers have to make decisions about the architecture of neural networks, not having clear successful recipes. And finally, algorithms such as DDPG are unstable and often demonstrate catastrophic forgetfulness .
To overcome these obstacles, we have automated deep learning with reinforcements. AOP is an evolutionary automatic wrapper around a deep OP, looking for rewards and neural network architecture with the help of large-scale optimization of hyper-parameters . It works in two stages, the search for awards and the search for architecture. During the search for rewards, AOP simultaneously trains a population of DDPG agents for several generations, and each one has its own slightly modified reward function optimized for the true task of the local scheduler: reaching the end point of the path. At the end of the reward search phase, we choose the one that most often leads agents to the goal. In the search phase of the neural network architecture, we repeat this process for this race using the chosen reward and adjusting the network layers, optimizing the cumulative reward.
')
AOP with search awards and neural network architecture
However, this step-by-step process makes AOP ineffective in terms of the number of samples. Training AOP with 10 generations of 100 agents requires 5 billion samples, equivalent to 32 years of training! The advantage is that after AOP, the manual learning process is automated, and DDPG does not have a catastrophic forgetting. Most importantly, the quality of the resulting policies is higher - they are resistant to noise from the sensor, drive and localization, and are well generalized to new environments. Our best policy is 26% more successful than other orienteering methods at our test sites.
Red - AOP successes at short distances (up to 10 m) in several unknown buildings. Comparison with manually trained DDPG (dark red), artificial potential fields (blue), dynamic window (blue) and behavior cloning (green).
The local AOP scheduler policy works well with robots in real unstructured environments.
And although these policies are only capable of local orientation, they are resistant to moving obstacles and are well tolerated on real robots in unstructured environments. And although they were trained in simulations with static objects, they effectively cope with moving objects. The next step is to combine AOP policies with sample-based layout to expand their field of work and teach them how to navigate long distances.
Long-range orientation with PRM-RL
Sample-based planners work with orientation over long distances, approximating the movements of the robot. For example, the robot builds probabilistic roadmaps (PRM), passing realizable transition paths between sections. In our second job , which won an award at the ICRA 2018 conference, we combine PRM with manually adjusted local OP planners (without AOP) to train robots locally, and then adapt them to other environments.
First, for each robot, we teach the local scheduler policy in a generalized simulation. Then we create PRM taking into account this policy, the so-called PRM-RL, based on the map of the environment where it will be used. The same card can be used for any robot we wish to use in the building.
To create a PRM-RL, we merge nodes from samples only if the local OP-scheduler can reliably and repeatedly move between them. This is done in a Monte Carlo simulation. The resulting map adapts to the capabilities and geometry of a particular robot. Cards for robots with the same geometry, but different sensors and actuators, will have different connectivity. Since the agent can turn the corner, you can include nodes that are not in direct line of sight. However, nodes located near walls and obstacles will be included in the map with a lower probability due to noise from sensors. During execution, the OP agent moves on the map from one site to another.
A map is created with three Monte-Carlo simulations for each randomly selected pair of nodes.
The largest map was 288x163 m in size and contained almost 700,000 ribs. 300 workers collected it for 4 days, having spent 1.1 billion collision checks.
The third work provides several improvements to the original PRM-RL. First, we replace the manually adjusted DDPG with local schedulers with AOP, which gives an improvement in orientation over long distances. Secondly, simultaneous localization and markup maps ( SLAM ) are added, which robots use at runtime as a source for building roadmaps. SLAM cards are subject to noise, and this closes the “gap between the simulator and reality”, a problem known in robotics, due to which agents trained in simulations behave much worse in the real world. Our level of success in the simulation coincides with the level of success of real robots. And finally, we added distributed building maps, so we can create very large maps containing up to 700,000 nodes.
We evaluated this method with the help of our AOP agent, who created maps based on blueprints of buildings that were 200 times more than the training environment, including only edges, which were successfully completed in 90% of cases in 20 attempts. We compared the PRM-RL with various methods at distances of up to 100 m, seriously exceeding the range of the local scheduler. PRM-RL achieved success 2-3 times more often than usual methods due to the correct connection of nodes, suitable for the capabilities of the robot.
The percentage of success in moving 100 meters in different buildings. Blue - local AOP scheduler, first job; red - original PRM; yellow - artificial potential fields; green is the second job; red is the third job, PRM with AOP.
We tested PRM-RL on a variety of real robots in a variety of buildings. Below is one of the test suites; the robot moves reliably almost everywhere, except for the most erratic places and areas beyond the SLAM card.
Conclusion
Machine orientation can seriously increase the independence of people with reduced mobility. This can be achieved by developing autonomous robots that can easily adapt to the environment, and the methods available for implementation in the new environment based on the information already available. This can be done by automating basic orientation training for small distances with AOP, and then use the acquired skills together with the SLAM maps to create roadmaps. Road maps consist of nodes connected by edges, along which robots can safely move. As a result, a policy of robot behavior is developed, which, after one training, can be used in different environments and issue roadmaps specially adapted for a specific robot.
Source: https://habr.com/ru/post/444372/
All Articles