GraphQL and Golang
GraphQL technology over the past few years, after the Facebook company transferred it to the category of open-source, has become very popular. The author of the material, the translation of which we are publishing today, says that he tried to work with GraphQL in the Node.js environment and was convinced from his own experience that this technology, thanks to its remarkable capabilities and simplicity, attracts so much attention to itself. Recently, he was engaged in a new project, moved from Node.js to Golang. Then he decided to try the joint work of Golang and GraphQL.

From the official definition of GraphQL, you can find out that this is a query language for APIs and a runtime environment for executing such queries on existing data. GraphQL provides a complete and understandable description of the data in some kind of API, allows customers to request exactly the information they need, and nothing more, simplifies the development of the API over time and gives developers powerful tools.
There are not many GraphQL libraries for Golang. In particular, I have tested such libraries as Thunder , graphql , graphql-go , and gqlgen . I should note that the gqlgen library has become the best I've ever tried.
')
The gqlgen library is still at the beta stage, at the time of writing this material it was version 0.7.2 . The library is rapidly evolving. Here you can learn about plans for its development. Now the official sponsor of gqlgen is the 99designs project, which means that this library, quite possibly, will develop even faster than before. The main developers of this library are vektah and neelance , while neelance is also working on the graphql-go library.
Let's talk about the gqlgen library on the assumption that you already have some basic knowledge of GraphQL.
In the description of gqlgen, you can find out what is in front of us is a library for quickly creating strongly typed GraphQL servers on Golang. This phrase seems to me very promising, as it means that while working with this library I will not come across something like
In addition, this library uses an approach based on a data scheme. This means that the API is described using GraphQL Schema Definition Language . Related to this language are its own powerful code-generation tools, which automatically create GraphQL code. The programmer can only implement the basic logic of the relevant interface methods.
This article is divided into two parts. The first is devoted to the basic techniques of work, and the second - advanced.
We, as an experimental application, will use a site where users can post videos, add screenshots and reviews, search for videos and view lists of records associated with other records. Let's start working on this project:
Create the following data schema file (
This describes the basic data models, one mutation (
If you need to use your own types, you can declare them in
It should be noted that in the latest version of the library one important change has appeared. Namely, the dependency on compiled binary files was removed from it. Therefore, in the project, you need to add the
After that, you need to initialize
Now it's time to take advantage of the code generation library. They allow you to create all the boring sample code, which, however, can not be called very very uninteresting. To start the mechanism of automatic code generation, execute the following command:
As a result of its execution, the following files will be created:
Let's take a look at the generated model for the
Here you can see that
For example, I use PostgreSQL in this demo application, so, of course, I need the
Let us indicate to the library that it should use these models (the
The point of all this is that we now have our own definitions for
Now it's time to implement the application logic. Open the
Now let's test the mutation.
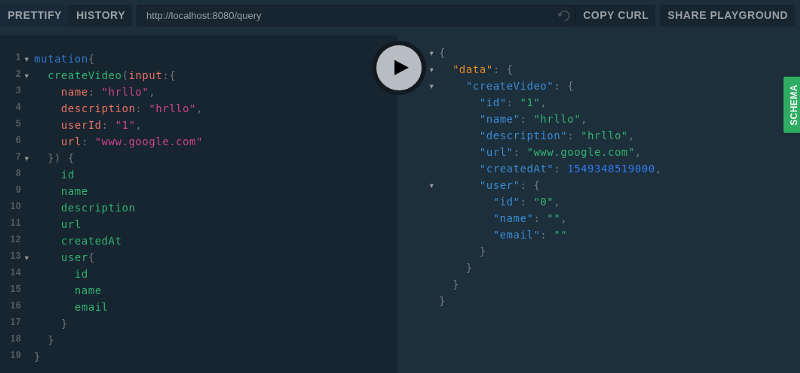 CreateVideo mutation
CreateVideo mutation
Works! But why is there nothing in the user information (
I suggested to the team in the organization where I work the following “golden rule” applied when working with gqlgen: “Do not include the fields in the model that need to be loaded only if they are requested by the client.”
In our case, I only need to download data about related video clips (and even information about users) if the client requests these fields. But since we included these fields in the model, gqlgen assumes that we provide this data by getting information about the video. As a result, we now get empty structures.
Sometimes it happens that data of a certain type is needed every time, so it is inappropriate to load it with a separate request. To do this, for the sake of improving performance, you can use something like SQL unions. One day (this, however, does not apply to the example considered here), I needed to have his metadata loaded with the video as well. These entities were stored in different places. As a result, if my system received a request to download a video, I had to make another request to receive metadata. But, since I knew about this requirement (that is, I knew that on the client side both the video and its metadata are always needed), I preferred to use the “greedy” loading technique to improve performance.
Let's rewrite the model and generate the gqlgen code again. In order not to complicate the narration, we will write only methods for the
We added a
Thanks to this command, the following interface methods will be created to resolve undefined structures. In addition, you will need to define the following in the resolver (
Here is the definition (
Now the results of the test mutations will look as shown below.
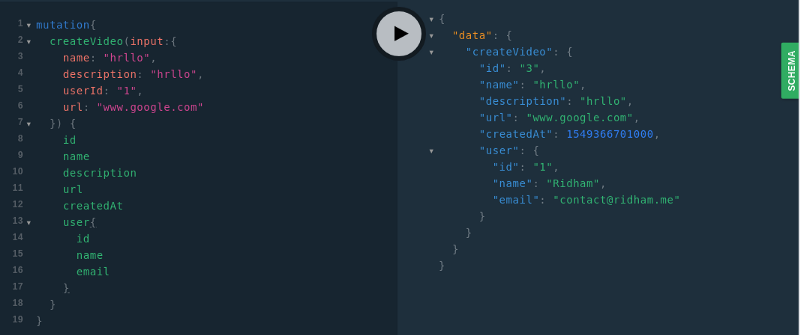
CreateVideo mutation
What we have just discussed is the basis of GraphQL, having mastered that, you can already write something of your own. However, before you dive into experiments with GraphQL and Golang, it will be useful to talk about subscriptions (subscription), which are directly related to what we are doing here.
GraphQL provides the ability to subscribe to changes in data that occur in real time. The gqlgen library allows, in real time, using web sockets to work with subscription events.
The subscription must be described in the
Now, again, run the automatic code generation:
As already mentioned, during the automatic generation of code in the
Now, when creating a new video, you need to trigger an event. In our example, this is done in the
Now it's time to check out the subscription.
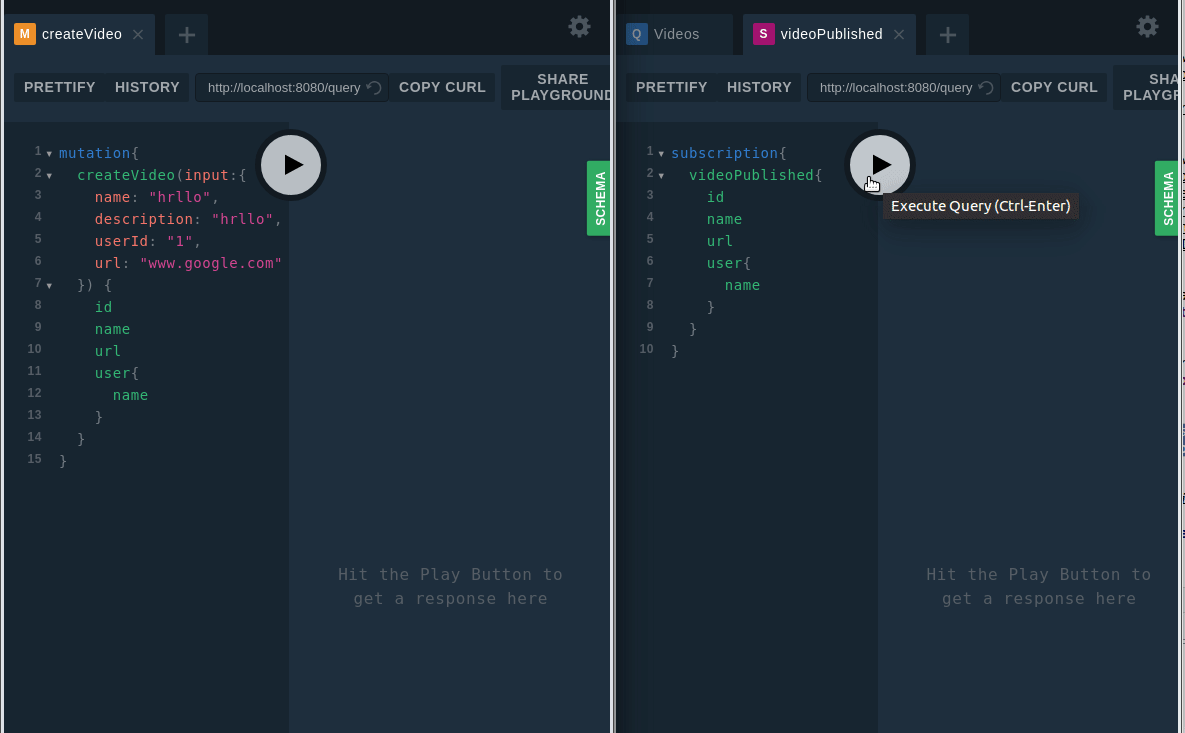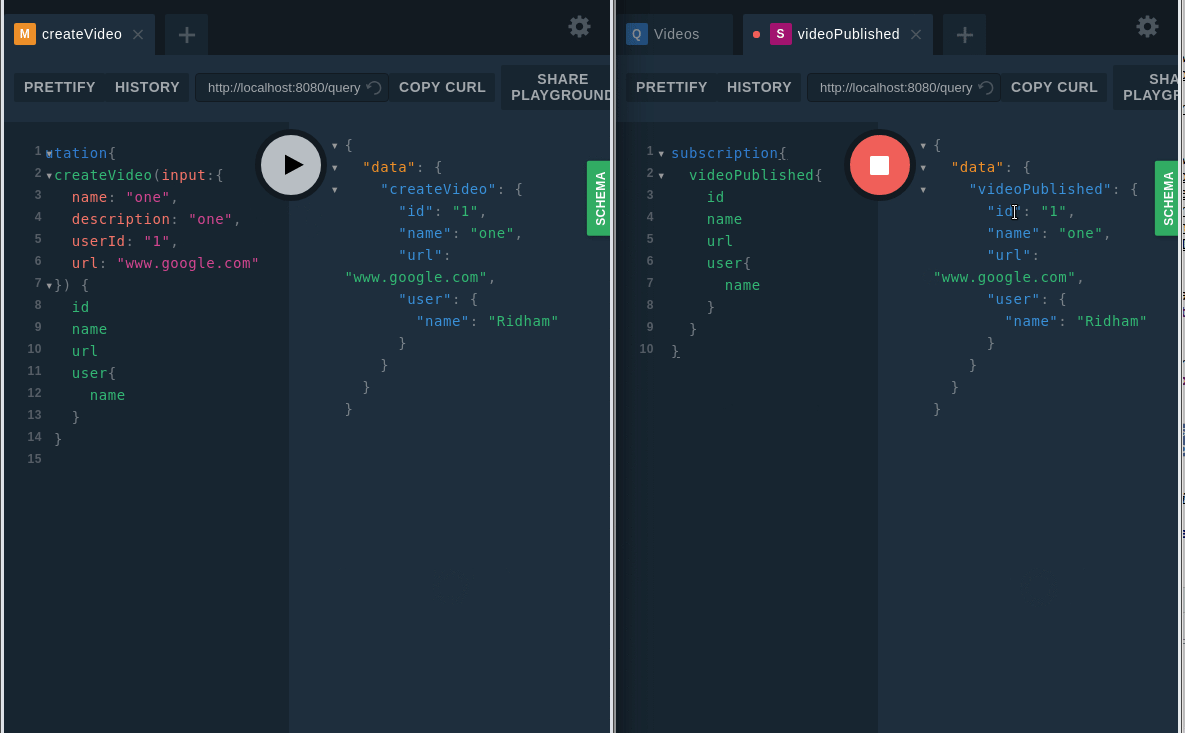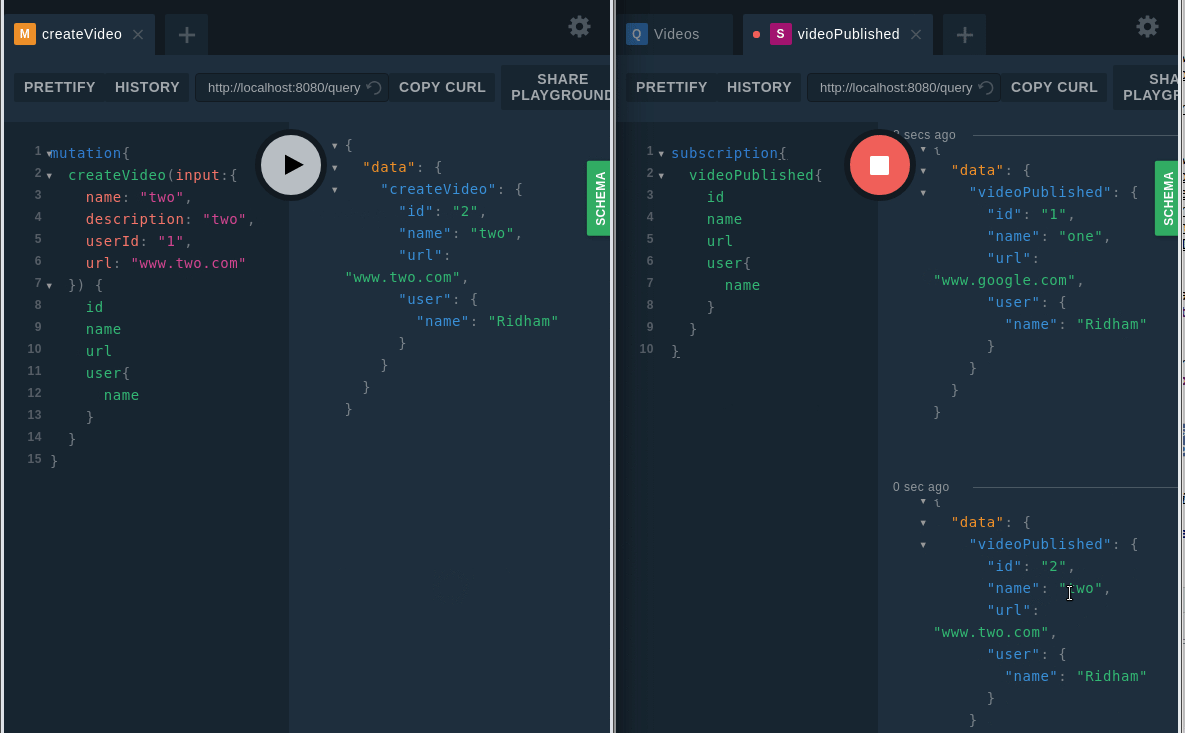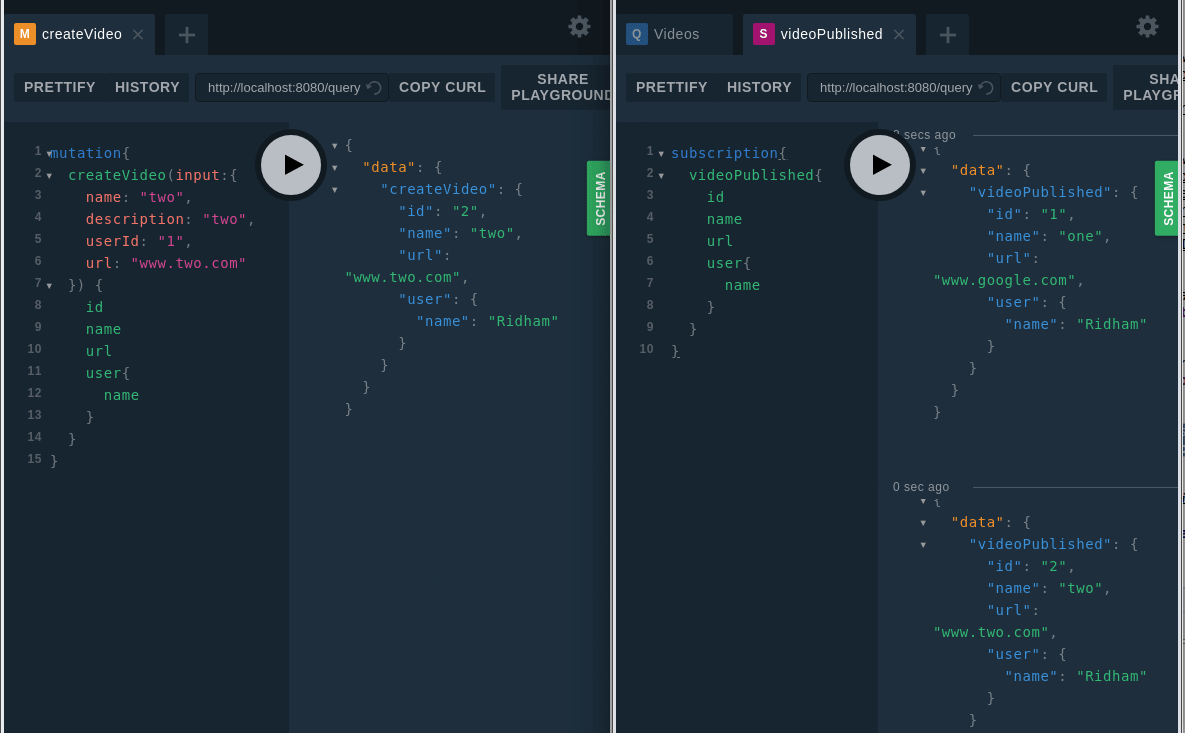
Subscription check
GraphQL, of course, has certain valuable features, but, as they say, not all is gold that glitters. Namely, we are talking about the fact that those who use GraphQL need to take care of authorization, query complexity, caching, the problem of N + 1 queries, limiting the speed of query execution and some other things. Otherwise, the system developed using GraphQL may face a serious drop in performance.
Every time I read manuals like this, I get a feeling that, having mastered them, I will learn everything I need to know about a certain technology and get the ability to solve problems of any complexity.
But when I start working on my own projects, I usually find myself in unforeseen situations that look like server errors or requests that have been running for ages, or some other deadlock situation. As a result, in order to do business, I had to better understand what had only recently seemed completely understandable. In the same manual, I hope this can be avoided. That is why in this section we will look at some advanced techniques for working with GraphQL.
When working with the REST API, we have an authentication system and standard authorization tools when working with a certain endpoint. But when using GraphQL, only one endpoint is used, so the authentication tasks can be solved using schema directives. Edit the
We created an
Here is the
We read the user
Now we need to describe our own intermediate authentication mechanism to obtain authentication data from the request and verify it.
No logic is defined here. Instead, as authorization data, for demonstration purposes, the user
Now the description of the directive makes sense. We do not process requests of unauthorized users in the code of the intermediate layer, since such requests will be processed by the directive. Here's what it looks like.
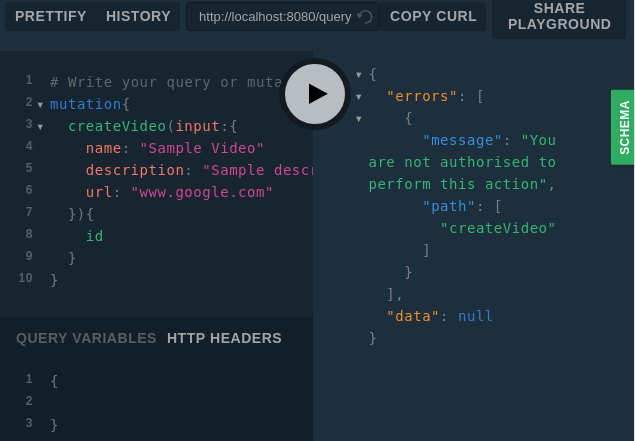
Work with unauthorized user
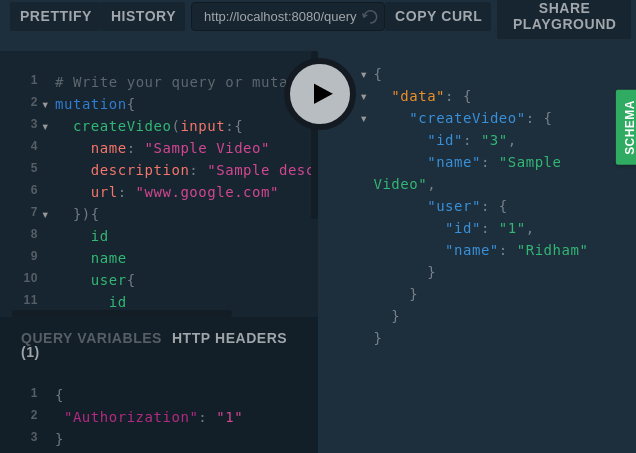
Work with authorized user
When working with schema directives, you can even pass arguments:
It seems to me that all this looks quite interesting. You load data when you need it. Customers have the ability to manage data from the storage takes exactly what you need. But everything has its price.
What have to "pay" for these opportunities? Take a look at the logs download all videos. Namely, we are talking about the fact that we have 8 videos and 5 users.
Video Upload Information
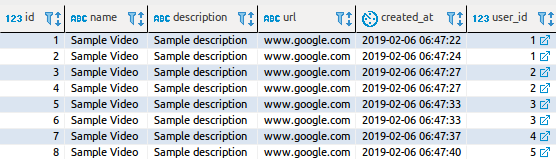
What's going on here? Why are there 9 requests (1 request is associated with the video table and 8 with the user table)? It looks awful. My heart almost stopped when I thought that our existing API would have to be replaced with this ... However, data loaders help to completely cope with this problem.
This is known as the N + 1 problem. The point is that there is one query to get all the data and for each data fragment (N) there will be another database query.
This is a very serious problem when it comes to performance and resources: although these requests are parallel, they drain system resources.
To solve this problem, we will use the dataloaden library from the author of the gqlgen library. This library allows you to generate go code. First, generate the data loader for the
We will have a
Now we need to define the
Here we expect for 1 ms. before executing the request and collect requests in packages of up to 100 requests. Now, instead of performing a request for each user individually, the loader will wait for the specified time before accessing the database. Next, you need to change the logic of the recognizer, reconfiguring it using the request to use the data loader (
Here is how the logs look after this in a situation similar to the above:
Here, only two database queries are executed; as a result, everyone is happy now. , 5 , 8 . , .
GraphQL API , . , API DOS-.
, .
, — :
100, . (, , ) , .
gqlgen , . , (
, , . 12. , , , ( , , , , ).
, , .

, ,
, , GitHub . . , , .
Dear readers! GraphQL , Go?

Preliminary Information
From the official definition of GraphQL, you can find out that this is a query language for APIs and a runtime environment for executing such queries on existing data. GraphQL provides a complete and understandable description of the data in some kind of API, allows customers to request exactly the information they need, and nothing more, simplifies the development of the API over time and gives developers powerful tools.
There are not many GraphQL libraries for Golang. In particular, I have tested such libraries as Thunder , graphql , graphql-go , and gqlgen . I should note that the gqlgen library has become the best I've ever tried.
')
The gqlgen library is still at the beta stage, at the time of writing this material it was version 0.7.2 . The library is rapidly evolving. Here you can learn about plans for its development. Now the official sponsor of gqlgen is the 99designs project, which means that this library, quite possibly, will develop even faster than before. The main developers of this library are vektah and neelance , while neelance is also working on the graphql-go library.
Let's talk about the gqlgen library on the assumption that you already have some basic knowledge of GraphQL.
Gqlgen features
In the description of gqlgen, you can find out what is in front of us is a library for quickly creating strongly typed GraphQL servers on Golang. This phrase seems to me very promising, as it means that while working with this library I will not come across something like
map[string]interface{} , since it uses an approach based on strong typing.In addition, this library uses an approach based on a data scheme. This means that the API is described using GraphQL Schema Definition Language . Related to this language are its own powerful code-generation tools, which automatically create GraphQL code. The programmer can only implement the basic logic of the relevant interface methods.
This article is divided into two parts. The first is devoted to the basic techniques of work, and the second - advanced.
Basic techniques of work: setup, requests for data acquisition and change, subscriptions
We, as an experimental application, will use a site where users can post videos, add screenshots and reviews, search for videos and view lists of records associated with other records. Let's start working on this project:
mkdir -p $GOPATH/src/github.com/ridhamtarpara/go-graphql-demo/ Create the following data schema file (
schema.graphql ) in the project root directory: type User { id: ID! name: String! email: String! } type Video { id: ID! name: String! description: String! user: User! url: String! createdAt: Timestamp! screenshots: [Screenshot] related(limit: Int = 25, offset: Int = 0): [Video!]! } type Screenshot { id: ID! videoId: ID! url: String! } input NewVideo { name: String! description: String! userId: ID! url: String! } type Mutation { createVideo(input: NewVideo!): Video! } type Query { Videos(limit: Int = 25, offset: Int = 0): [Video!]! } scalar Timestamp This describes the basic data models, one mutation (
Mutation , a description of the data change request), which is used to publish new video files on the site, and one query ( Query ) to get a list of all video files. You can read more about GraphQL scheme here . In addition, here we declared one own scalar data type. The 5 standard scalar data types ( Int , Float , String , Boolean and ID ) that are in GraphQL are not enough.If you need to use your own types, you can declare them in
schema.graphql (in our case, the type is Timestamp ) and provide their definitions in code. When using the gqlgen library, you need to provide marshaling and unmarshaling methods for all of your own scalar types and configure mapping with gqlgen.yml .It should be noted that in the latest version of the library one important change has appeared. Namely, the dependency on compiled binary files was removed from it. Therefore, in the project, you need to add the
scripts/gqlgen.go file scripts/gqlgen.go following content: // +build ignore package main import "github.com/99designs/gqlgen/cmd" func main() { cmd.Execute() } After that, you need to initialize
dep : dep init Now it's time to take advantage of the code generation library. They allow you to create all the boring sample code, which, however, can not be called very very uninteresting. To start the mechanism of automatic code generation, execute the following command:
go run scripts/gqlgen.go init As a result of its execution, the following files will be created:
gqlgen.yml: configuration file for managing code generation.generated.go: generated code.models_gen.go: all models and data types of the provided schema.resolver.go: here will be the code that the programmer creates.server/server.go: entry point withhttp.Handlerto start GraphQL server.
Let's take a look at the generated model for the
Video type ( generated_video.go file): type Video struct { ID string `json:"id"` Name string `json:"name"` User User `json:"user"` URL string `json:"url"` CreatedAt string `json:"createdAt"` Screenshots []*Screenshot `json:"screenshots"` Related []Video `json:"related"` } Here you can see that
ID is a string, CreatedAt is also a string. Other related models are configured accordingly. However, in real applications it is not necessary. If you use any type of SQL data, then you need, for example, that the ID field would have an int or int64 type, depending on the database used.For example, I use PostgreSQL in this demo application, so, of course, I need the
ID field to be of type int , and the field of CreatedAt is of type time.Time . This leads to the fact that we need to define our own model and tell gqlgen to use our model instead of generating a new one. Here is the contents of the models.go file: type Video struct { ID int `json:"id"` Name string `json:"name"` Description string `json:"description"` User User `json:"user"` URL string `json:"url"` CreatedAt time.Time `json:"createdAt"` Related []Video } // int ID func MarshalID(id int) graphql.Marshaler { return graphql.WriterFunc(func(w io.Writer) { io.WriteString(w, strconv.Quote(fmt.Sprintf("%d", id))) }) } // func UnmarshalID(v interface{}) (int, error) { id, ok := v.(string) if !ok { return 0, fmt.Errorf("ids must be strings") } i, e := strconv.Atoi(id) return int(i), e } func MarshalTimestamp(t time.Time) graphql.Marshaler { timestamp := t.Unix() * 1000 return graphql.WriterFunc(func(w io.Writer) { io.WriteString(w, strconv.FormatInt(timestamp, 10)) }) } func UnmarshalTimestamp(v interface{}) (time.Time, error) { if tmpStr, ok := v.(int); ok { return time.Unix(int64(tmpStr), 0), nil } return time.Time{}, errors.TimeStampError } Let us indicate to the library that it should use these models (the
gqlgen.yml file): schema: - schema.graphql exec: filename: generated.go model: filename: models_gen.go resolver: filename: resolver.go type: Resolver models: Video: model: github.com/ridhamtarpara/go-graphql-demo/api.Video ID: model: github.com/ridhamtarpara/go-graphql-demo/api.ID Timestamp: model: github.com/ridhamtarpara/go-graphql-demo/api.Timestamp The point of all this is that we now have our own definitions for
ID and Timestamp with marshaling and unmarshaling methods and their mapping in the gqlgen.yml file. Now, when the user provides the string as an ID , the UnmarshalID() method converts the string to an integer. When sending a response, the MarshalID() method converts the number to a string. The same happens with the Timestamp or with any other scalar type declared by the programmer.Now it's time to implement the application logic. Open the
resolver.go file and enter descriptions of mutations and requests into it. There is already an automatically generated template code that we need to fill with meaning. Here is the code for this file: func (r *mutationResolver) CreateVideo(ctx context.Context, input NewVideo) (api.Video, error) { newVideo := api.Video{ URL: input.URL, Name: input.Name, CreatedAt: time.Now().UTC(), } rows, err := dal.LogAndQuery(r.db, "INSERT INTO videos (name, url, user_id, created_at) VALUES($1, $2, $3, $4) RETURNING id", input.Name, input.URL, input.UserID, newVideo.CreatedAt) defer rows.Close() if err != nil || !rows.Next() { return api.Video{}, err } if err := rows.Scan(&newVideo.ID); err != nil { errors.DebugPrintf(err) if errors.IsForeignKeyError(err) { return api.Video{}, errors.UserNotExist } return api.Video{}, errors.InternalServerError } return newVideo, nil } func (r *queryResolver) Videos(ctx context.Context, limit *int, offset *int) ([]api.Video, error) { var video api.Video var videos []api.Video rows, err := dal.LogAndQuery(r.db, "SELECT id, name, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2", limit, offset) defer rows.Close(); if err != nil { errors.DebugPrintf(err) return nil, errors.InternalServerError } for rows.Next() { if err := rows.Scan(&video.ID, &video.Name, &video.URL, &video.CreatedAt, &video.UserID); err != nil { errors.DebugPrintf(err) return nil, errors.InternalServerError } videos = append(videos, video) } return videos, nil } Now let's test the mutation.
Works! But why is there nothing in the user information (
user object)? When working with GraphQL, concepts similar to “lazy” (lazy) and “greedy” (eager) loading are applicable. Since this system is expandable, you need to specify which fields need to be filled “greedily” and which ones are “lazy”.I suggested to the team in the organization where I work the following “golden rule” applied when working with gqlgen: “Do not include the fields in the model that need to be loaded only if they are requested by the client.”
In our case, I only need to download data about related video clips (and even information about users) if the client requests these fields. But since we included these fields in the model, gqlgen assumes that we provide this data by getting information about the video. As a result, we now get empty structures.
Sometimes it happens that data of a certain type is needed every time, so it is inappropriate to load it with a separate request. To do this, for the sake of improving performance, you can use something like SQL unions. One day (this, however, does not apply to the example considered here), I needed to have his metadata loaded with the video as well. These entities were stored in different places. As a result, if my system received a request to download a video, I had to make another request to receive metadata. But, since I knew about this requirement (that is, I knew that on the client side both the video and its metadata are always needed), I preferred to use the “greedy” loading technique to improve performance.
Let's rewrite the model and generate the gqlgen code again. In order not to complicate the narration, we will write only methods for the
user field (file models.go ): type Video struct { ID int `json:"id"` Name string `json:"name"` Description string `json:"description"` UserID int `json:"-"` URL string `json:"url"` CreatedAt time.Time `json:"createdAt"` } We added a
UserID and removed the User structure. Now re-generate the code: go run scripts/gqlgen.go -v Thanks to this command, the following interface methods will be created to resolve undefined structures. In addition, you will need to define the following in the resolver (
generated.go file): type VideoResolver interface { User(ctx context.Context, obj *api.Video) (api.User, error) Screenshots(ctx context.Context, obj *api.Video) ([]*api.Screenshot, error) Related(ctx context.Context, obj *api.Video, limit *int, offset *int) ([]api.Video, error) } Here is the definition (
resolver.go file): func (r *videoResolver) User(ctx context.Context, obj *api.Video) (api.User, error) { rows, _ := dal.LogAndQuery(r.db,"SELECT id, name, email FROM users where id = $1", obj.UserID) defer rows.Close() if !rows.Next() { return api.User{}, nil } var user api.User if err := rows.Scan(&user.ID, &user.Name, &user.Email); err != nil { errors.DebugPrintf(err) return api.User{}, errors.InternalServerError } return user, nil } Now the results of the test mutations will look as shown below.
CreateVideo mutation
What we have just discussed is the basis of GraphQL, having mastered that, you can already write something of your own. However, before you dive into experiments with GraphQL and Golang, it will be useful to talk about subscriptions (subscription), which are directly related to what we are doing here.
▍Following
GraphQL provides the ability to subscribe to changes in data that occur in real time. The gqlgen library allows, in real time, using web sockets to work with subscription events.
The subscription must be described in the
schema.graphql file. Here is the description of a subscription to a video posting event: type Subscription { videoPublished: Video! } Now, again, run the automatic code generation:
go run scripts/gqlgen.go -v As already mentioned, during the automatic generation of code in the
generated.go file, an interface is created that needs to be implemented in the resolver. In our case it looks like this ( resolver.go file): var videoPublishedChannel map[string]chan api.Video func init() { videoPublishedChannel = map[string]chan api.Video{} } type subscriptionResolver struct{ *Resolver } func (r *subscriptionResolver) VideoPublished(ctx context.Context) (<-chan api.Video, error) { id := randx.String(8) videoEvent := make(chan api.Video, 1) go func() { <-ctx.Done() }() videoPublishedChannel[id] = videoEvent return videoEvent, nil } func (r *mutationResolver) CreateVideo(ctx context.Context, input NewVideo) (api.Video, error) { // ... for _, observer := range videoPublishedChannel { observer <- newVideo } return newVideo, nil } Now, when creating a new video, you need to trigger an event. In our example, this is done in the
for _, observer := range videoPublishedChannel line for _, observer := range videoPublishedChannel .Now it's time to check out the subscription.
Subscription check
GraphQL, of course, has certain valuable features, but, as they say, not all is gold that glitters. Namely, we are talking about the fact that those who use GraphQL need to take care of authorization, query complexity, caching, the problem of N + 1 queries, limiting the speed of query execution and some other things. Otherwise, the system developed using GraphQL may face a serious drop in performance.
Advanced work practices: authentication, data loaders, query complexity
Every time I read manuals like this, I get a feeling that, having mastered them, I will learn everything I need to know about a certain technology and get the ability to solve problems of any complexity.
But when I start working on my own projects, I usually find myself in unforeseen situations that look like server errors or requests that have been running for ages, or some other deadlock situation. As a result, in order to do business, I had to better understand what had only recently seemed completely understandable. In the same manual, I hope this can be avoided. That is why in this section we will look at some advanced techniques for working with GraphQL.
▍ Authentication
When working with the REST API, we have an authentication system and standard authorization tools when working with a certain endpoint. But when using GraphQL, only one endpoint is used, so the authentication tasks can be solved using schema directives. Edit the
schema.graphql file as follows: type Mutation { createVideo(input: NewVideo!): Video! @isAuthenticated } directive @isAuthenticated on FIELD_DEFINITION We created an
isAuthenticated directive and applied it to the createVideo subscription. After the next session of automatic code generation, you need to define a definition for this directive. Now directives are implemented as methods of structures, and not as interfaces, so we need to describe them. I edited the automatically generated code in the server.go file and created a method that returns the GraphQL configuration for the server.go file. Here is the resolver.go file: func NewRootResolvers(db *sql.DB) Config { c := Config{ Resolvers: &Resolver{ db: db, }, } // c.Directives.IsAuthenticated = func(ctx context.Context, obj interface{}, next graphql.Resolver) (res interface{}, err error) { ctxUserID := ctx.Value(UserIDCtxKey) if ctxUserID != nil { return next(ctx) } else { return nil, errors.UnauthorisedError } } return c } Here is the
server.go file: rootHandler:= dataloaders.DataloaderMiddleware( db, handler.GraphQL( go_graphql_demo.NewExecutableSchema(go_graphql_demo.NewRootResolvers(db) ) ) http.Handle("/query", auth.AuthMiddleware(rootHandler)) We read the user
ID from the context. Doesn't it seem strange to you? How did this meaning fit into the context and why did it even appear in the context? The fact is that gqlgen provides request contexts only at the implementation level, so we are not able to read any HTTP request data, such as headers or cookies, in recognizers or directives. As a result, you need to add your own intermediate mechanisms to the system, obtain this data and put it in context.Now we need to describe our own intermediate authentication mechanism to obtain authentication data from the request and verify it.
No logic is defined here. Instead, as authorization data, for demonstration purposes, the user
ID simply transmitted here. This mechanism is then integrated into server.go with a new configuration loading method.Now the description of the directive makes sense. We do not process requests of unauthorized users in the code of the intermediate layer, since such requests will be processed by the directive. Here's what it looks like.
Work with unauthorized user
Work with authorized user
When working with schema directives, you can even pass arguments:
directive @hasRole(role: Role!) on FIELD_DEFINITION enum Role { ADMIN USER } ▍Data Loaders
It seems to me that all this looks quite interesting. You load data when you need it. Customers have the ability to manage data from the storage takes exactly what you need. But everything has its price.
What have to "pay" for these opportunities? Take a look at the logs download all videos. Namely, we are talking about the fact that we have 8 videos and 5 users.
query{ Videos(limit: 10){ name user{ name } } } Video Upload Information
Query: Videos : SELECT id, name, description, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2 Resolver: User : SELECT id, name, email FROM users where id = $1 Resolver: User : SELECT id, name, email FROM users where id = $1 Resolver: User : SELECT id, name, email FROM users where id = $1 Resolver: User : SELECT id, name, email FROM users where id = $1 Resolver: User : SELECT id, name, email FROM users where id = $1 Resolver: User : SELECT id, name, email FROM users where id = $1 Resolver: User : SELECT id, name, email FROM users where id = $1 Resolver: User : SELECT id, name, email FROM users where id = $1 What's going on here? Why are there 9 requests (1 request is associated with the video table and 8 with the user table)? It looks awful. My heart almost stopped when I thought that our existing API would have to be replaced with this ... However, data loaders help to completely cope with this problem.
This is known as the N + 1 problem. The point is that there is one query to get all the data and for each data fragment (N) there will be another database query.
This is a very serious problem when it comes to performance and resources: although these requests are parallel, they drain system resources.
To solve this problem, we will use the dataloaden library from the author of the gqlgen library. This library allows you to generate go code. First, generate the data loader for the
User entity: go get github.com/vektah/dataloaden dataloaden github.com/ridhamtarpara/go-graphql-demo/api.User We will have a
userloader_gen.go file userloader_gen.go methods like Fetch , LoadAll and Prime .Now we need to define the
Fetch method ( dataloader.go file) to get general results: func DataloaderMiddleware(db *sql.DB, next http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { userloader := UserLoader{ wait : 1 * time.Millisecond, maxBatch: 100, fetch: func(ids []int) ([]*api.User, []error) { var sqlQuery string if len(ids) == 1 { sqlQuery = "SELECT id, name, email from users WHERE id = ?" } else { sqlQuery = "SELECT id, name, email from users WHERE id IN (?)" } sqlQuery, arguments, err := sqlx.In(sqlQuery, ids) if err != nil { log.Println(err) } sqlQuery = sqlx.Rebind(sqlx.DOLLAR, sqlQuery) rows, err := dal.LogAndQuery(db, sqlQuery, arguments...) defer rows.Close(); if err != nil { log.Println(err) } userById := map[int]*api.User{} for rows.Next() { user:= api.User{} if err := rows.Scan(&user.ID, &user.Name, &user.Email); err != nil { errors.DebugPrintf(err) return nil, []error{errors.InternalServerError} } userById[user.ID] = &user } users := make([]*api.User, len(ids)) for i, id := range ids { users[i] = userById[id] i++ } return users, nil }, } ctx := context.WithValue(r.Context(), CtxKey, &userloader) r = r.WithContext(ctx) next.ServeHTTP(w, r) }) } Here we expect for 1 ms. before executing the request and collect requests in packages of up to 100 requests. Now, instead of performing a request for each user individually, the loader will wait for the specified time before accessing the database. Next, you need to change the logic of the recognizer, reconfiguring it using the request to use the data loader (
resolver.go file): func (r *videoResolver) User(ctx context.Context, obj *api.Video) (api.User, error) { user, err := ctx.Value(dataloaders.CtxKey).(*dataloaders.UserLoader).Load(obj.UserID) return *user, err } Here is how the logs look after this in a situation similar to the above:
Query: Videos : SELECT id, name, description, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2 Dataloader: User : SELECT id, name, email from users WHERE id IN ($1, $2, $3, $4, $5) Here, only two database queries are executed; as a result, everyone is happy now. , 5 , 8 . , .
▍
GraphQL API , . , API DOS-.
, .
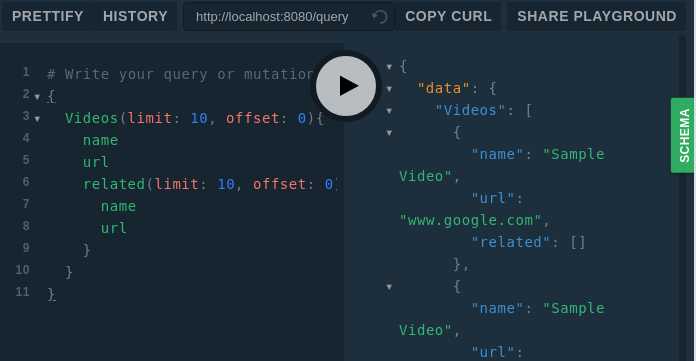
Video , . GraphQL Video . . — ., — :
{ Videos(limit: 10, offset: 0){ name url related(limit: 10, offset: 0){ name url related(limit: 10, offset: 0){ name url related(limit: 100, offset: 0){ name url } } } } } 100, . (, , ) , .
gqlgen , . , (
handler.ComplexityLimit(300) ) GraphQL (300 ). , ( server.go ): rootHandler:= dataloaders.DataloaderMiddleware( db, handler.GraphQL( go_graphql_demo.NewExecutableSchema(go_graphql_demo.NewRootResolvers(db)), handler.ComplexityLimit(300) ), ) , , . 12. , , , ( , , , , ).
resolver.go : func NewRootResolvers(db *sql.DB) Config { c := Config{ Resolvers: &Resolver{ db: db, }, } // countComplexity := func(childComplexity int, limit *int, offset *int) int { return *limit * childComplexity } c.Complexity.Query.Videos = countComplexity c.Complexity.Video.Related = countComplexity // c.Directives.IsAuthenticated = func(ctx context.Context, obj interface{}, next graphql.Resolver) (res interface{}, err error) { ctxUserID := ctx.Value(UserIDCtxKey) if ctxUserID != nil { return next(ctx) } else { return nil, errors.UnauthorisedError } } return c } , , .
, ,
related . , , , , .Results
, , GitHub . . , , .
Dear readers! GraphQL , Go?
Source: https://habr.com/ru/post/444346/
All Articles