PyDERASN: as I wrote the ASN.1 library with slots and blobs
ASN.1 is a standard (ISO, ITU-T, GOST) of a language describing structured information, as well as the coding rules for this information. For me, as a programmer, this is just another serialization and data presentation format, along with JSON, XML, XDR and others. It is extremely common in our normal life, and many people encounter it: in cellular, telephone, VoIP communications (UMTS, LTE, WiMAX, SS7, H.323), in network protocols (LDAP, SNMP, Kerberos), in everything that concerns cryptography (X.509, CMS, PKCS-standards), in bank cards and biometric passports, and in many other places.
This article discusses the PyDERASN : Python ASN.1 library that is actively used in projects related to cryptography in Atlas .

In general, it is not worthwhile to recommend ASN.1 for cryptographic tasks: ASN.1 and its codecs are complex. This means that the code will not be simple, and it is always an extra attack vector. Just look at the list of vulnerabilities in the ASN.1 libraries. Bruce Schneier in his Cryptography engineering also does not recommend using this standard because of its complexity: “The best-known TLV encoding is ASN.1, but it is incredibly complex and we’re shy away from it.” But, unfortunately, today we have public key infrastructures in which X.509 certificates , CRL, OCSP, TSP, CMP, CMC , CMS messages, and a lot of PKCS standards are actively used. Therefore, you have to be able to work with ASN.1 if you are doing something related to cryptography.
')
ASN.1 can be encoded in a variety of ways / codecs:
and a number of others. But in cryptographic tasks in practice, two are used: BER and DER. Even in signed XML documents ( XMLDSig , XAdES ) there will still be Base64-encoded ASN.1 DER objects, as in the JSON-oriented ACME protocol from Let's Encrypt. You can better understand all of these codecs and the BER / CER / DER encoding principles in articles and books: ASN.1 in simple words , ASN.1 - John Larmouth .
BER is a binary byte-oriented (for example, PER, popular in cellular communication - bit-oriented) TLV-format. Each element is encoded as: a tag ( T ag) identifying the type of element being encoded (integer, string, date, etc.), length ( L ength) of the content and the content itself ( V alue). BER optionally allows you to omit the length value, setting the particular indefinite length value and ending the message End-Of-Octets with a label. In addition to length coding, there is a lot of variability in BER in the method of coding data types, such as
Because of all of the above, it is not always possible to encode the data so that they are identical to the original form. Therefore, a subset of rules was invented: DER - tightly regulating only one acceptable encoding method, which is critical for cryptographic tasks, where, for example, changing one bit will make the signature or checksum invalid. DER has a significant drawback: the lengths of all elements must be known in advance during encoding, which prevents streamlined serialization of data. CER codec is devoid of this disadvantage, likewise guaranteeing an unambiguous presentation of data. Unfortunately (or fortunately, we don’t have even more complex decoders?), It didn’t become popular. Therefore, in practice, we encounter a “mixed” use of BER and DER encoded data. Since both CER and DER are a subset of BER, any BER decoder is able to process them.
At work, we write many Python programs related to cryptography. And a few years ago there was practically no choice of free libraries: either these are very low-level libraries that allow you to simply encode / decode, for example, an integer and a structure header, or this is the pyasn1 library. We lived there for several years and at first were very pleased, as it allows working with ASN.1 structures as high-level objects: for example, a decoded X.509 certificate object allows you to access your fields through the dictionary interface: cert ["tbsCertificate"] ["SerialNumber"] will show us the serial number of this certificate. Similarly, you can “collect” complex objects by working with them as with lists, dictionaries, and then simply call the pyasn1.codec.der.encoder.encode function and get a serialized view of the document.
However, flaws, problems and limitations were revealed. In pyasn1, there were and, unfortunately, errors still remain: at the time of this writing, in pyasn1, one of the basic types, GeneralizedTime, is incorrectly decoded and encoded.
In our projects, to save space, we often store only the file path, offset and length in bytes of the object we want to refer to. For example, an arbitrary signed file will most likely be located in the CMS SignedData ASN.1 structure:
and we can get the original signed file at an offset of 65 bytes, with a length of 751 bytes. pyasn1 does not store this information in its decoded objects. The so-called TLVSeeker was written - a small library that allows you to decode tags and object lengths, in the interface of which we commanded “go to the next tag”, “go inside the tag” (go inside the SEQUENCE of the object), “go to the next tag”, “tell your offset and the length of the object where we are. " This was a “manual” walk on ASN.1 DER-serialized data. But it was impossible to work this way with BER-serialized data, since, for example, the OCTET STRING byte string could be encoded in the form of several chunk.
Another drawback for our pyasn1 tasks is the impossibility to understand by decoded objects whether the specified field was present in the SEQUENCE or not. For example, if a structure contains a Field SEQUENCE OF Smth OPTIONAL field, then it could be completely absent in the incoming data (OPTIONAL), but could be present, but at the same time be of zero length (empty list). In general, this could not be figured out. And this is necessary for a strict check of the validity of the incoming data. Imagine that any certification authority would issue a certificate with “not quite” valid data from the point of view of ASN.1-schemes! For example, the certification center “TÜRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı” in its root certificate went beyond the allowable RFC 5280 boundaries of the length of the subject component - it cannot be honestly decoded according to the scheme. The DER codec requires that a field whose value is equal to DEFAULT should not be encoded during transmission — such documents occur in life, and the first version of PyDERASN even consciously allowed such invalid behavior (from the DER point of view) for the sake of backward compatibility.
Another limitation is the impossibility of easily finding out in which form (BER / DER) one or another object in the structure was encoded. For example, the CMS standard says that the message is BER-encoded, but the signedAttrs field over which the cryptographic signature is generated must be in DER. If we decode DER, then we will fall on the processing of the CMS itself; if we decode with BER, we will not know what kind of signedAttrs was. As a result, it is necessary for TLVSeeker (which has no analogue in pyasn1) to search for the location of each of the signedAttrs fields, and decode it separately, from the serialized view, with DER.
The possibility of automatic processing of DEFINED BY fields, which are very common, was very welcome for us. After decoding an ASN.1 structure, we may have many ANY fields left to be processed further according to a scheme chosen on the basis of the OBJECT IDENTIFIER specified in the structure field. In Python code, this means writing an if and then calling the decoder for the ANY field.
In the Atlas, we regularly, having found some problems or modifying used free programs, send patches to the top. In pyasn1, we sent improvements a few times, but the pyasn1 code is not the easiest to understand, and sometimes there were incompatible API changes that hit us. Plus, we are used to writing tests with generative testing, which was not in pyasn1.
One day I decided to suffice it to endure and it’s time to try to write your own library with __slot __s, offset and perfectly displayed blobs! Just creating an ASN.1 codec would not be enough - you need to transfer all our dependent projects to each other, and these are hundreds of thousands of lines of code that are fully working with ASN.1 structures. That is one of the requirements for it: the ease of translation of the current pyasn1 code. Having spent my entire vacation, I wrote this library, transferred all the projects to it. Since they have almost 100% coverage with tests, this also meant the full performance of the library.
PyDERASN, similarly, has almost 100% test coverage. Generative testing is used with a remarkable hypothesis library. Fuzzing py-afl was also conducted on 32 nuclear machines. Despite the fact that we have almost no Python2 code left, PyDERASN still maintains compatibility with it and because of this it has only six dependencies. In addition, it has been tested against the ASN.1: 2008 compliance test suite .
The principle of working with it is similar to pyasn1 - working with high-level Python objects. The description of the ASN.1 schema is similar.
However, PyDERASN has some sort of strong typing. In pyasn1, if the field was of the type CMSVersion (INTEGER), then it could be assigned an int or INTEGER. PyDERASN strictly requires that the object being assigned be exactly CMSVersion. Besides the fact that we are writing Python3 code, we use typing annotations , so our functions will not have incomprehensible arguments like def func (serial, contents), but def func (serial: CertificateSerialNumber, contents: EncapsulatedContentInfo), and PyDERASN helps to observe such code.
At the same time, PyDERASN has extremely convenient indulgences of this very typification. pyasn1 did not allow the SubjectKeyIdentifier (). subtype (implicitTag = Tag (...)) field to assign the SubjectKeyIdentifier () object (without the necessary IMPLICIT TAG-a) and had to frequently copy and recreate objects only because of the changed IMPLICIT / EXPLICIT tags. PyDERASN strictly keeps only the base type - it will automatically insert tags from the existing ASN.1 scheme of the structure. This greatly simplifies the application code.
If an error occurs during decoding, then in pyasn1 it is not easy to understand exactly where it occurred. For example, in the above-mentioned Turkish certificate we get the following error: UTF8String (tbsCertificate: issuer: rdnSequence: 3: 0: value: DEFINED BY 2.5.4.10:utf8String) (at 138) unsatisfied bounds: 1 ⇐ 77 64 When writing ASN .1 structures can make mistakes, and this makes it easier to debug applications or figure out the problems of coded documents from the opposite side.
The first version of PyDERASN did not support BER encoding. Appeared much later and still does not support UTCTime / GeneralizedTime processing with time zones. This will come in the future, because the project is written mainly in his free time.
Also in the first version there was no work with DEFINED BY fields. A few months later, this opportunity appeared and began to be actively used, significantly reducing the application code - in one decoding operation it was possible to get the entire structure disassembled to the very depth. For this, the scheme defines which fields that “define”. For example, the description of the CMS scheme:
says that if the contentType contains an OID with the id_signedData value, then the content field (located in the same SEQUENCE) needs to be decoded using the SignedData scheme. Why so many brackets? A field can “define” several fields at the same time, as is the case with EnvelopedData structures. The defined fields are identified by the so-called decode path - it defines the exact location of any element in all structures.
Not always want or not always have the opportunity to immediately in the scheme to make these defines. There may be application-specific cases where OIDs and structures are known only in a third-party project. PyDERASN provides the ability to specify these directly at the time of decoding the structure:
Here we say that in CMS SignedData for all attached certificates, decode all their extensions (AuthorityKeyIdentifier, BasicConstraints, SubjectSignTool, etc.). We specify through the decode path, what element should be “substituted” defines, as if it were specified in the scheme.
Finally, PyDERASN has the ability to work from the command line to decode ASN.1 files and has a rich pretty printing . You can decode an arbitrary ASN.1, or you can define a well-defined scheme and see something like this:
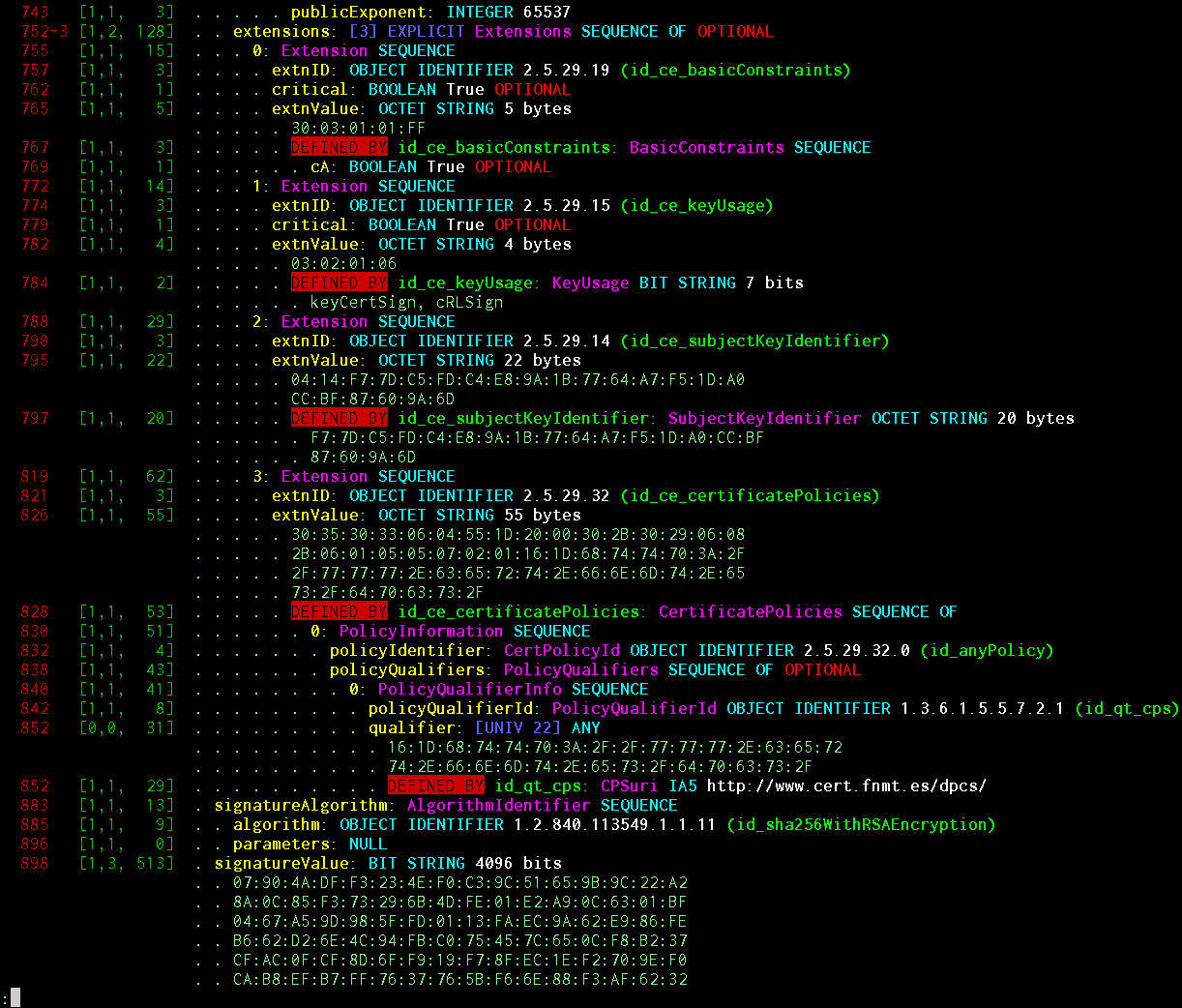
Displayed information: object offset, tag length, length length, content length, presence of EOC (end-of-octets), BER encoding feature, encoding indefinite-length indication, EXPLICIT tag length and offset (if any), object nesting depth structures, IMPLICIT / EXPLICIT tag value, object name according to the scheme, its basic ASN.1 type, sequence number within SEQUENCE / SET OF, CHOICE value (if any), human readable INTEGER / ENUMERATED / BIT STRING number according to the scheme, value of any basic type , DEFAULT / OPTIONAL flag from the circuit, the sign that the object was automatically decoded as DEFINED BY and for with gm of OID-and it happened, chelovekochitaemy OID.
The pretty printing system is specially designed so that it generates a sequence of PP objects, which are already visualized by separate means. The screenshot shows the renderer in plain color text. There are renderer in JSON / HTML format, so that it can be backlit in an ASN.1 browser as in an asn1js project.
This was not the goal, but PyDERASN was much faster than pyasn1. For example, decoding CRL files of megabyte sizes can take so long that you have to think about intermediate data storage formats (fast) and change the architecture of applications. pyasn1 decodes the CRL CACert.org CRL on my laptop in more than 20 minutes, whereas PyDERASN in just 28 seconds! There is an asn1crypto project aimed at quick work with cryptographic structures: it decodes (completely, not lazily) the same CRL in 29 seconds, but consumes almost twice as much RAM when running under Python3 (983 MiB versus 498 mi), and 3.5 times under Python2 (1677 against 488), while pyasn1 consumes 4.3 times as much (2093 against 488).
asn1crypto, which I mentioned, we did not consider, because the project was still in its infancy, and we did not hear about it. Now they would not have looked at him either, since I immediately discovered that the same GeneralizedTime does not accept an arbitrary form, and when serialized, it silently removes a split second. This is acceptable for working with X.509 certificates, but in general it will not work.
At the moment, PyDERASN is the strictest free Python / Go DER decoder known to me. In the encoding / asn1 library of my favorite Go, I do not have strict OBJECT IDENTIFIER and UTCTime / GeneralizedTime string checking . Sometimes severity can interfere (primarily due to backward compatibility with old applications that no one will fix), so various settings for debugging checks can be sent to PyDERASN during decoding.
The project code tries to be as simple as possible. The entire library is one file. The code is written with an emphasis on ease of understanding, without unnecessary optimization of performance and DRY-code. There is no, as I said, there is no support for full-BER decoding of UTCTime / GeneralizedTime strings, as well as REAL, RELATIVE OID, EXTERNAL, INSTANCE OF, EMBEDDED PDV, CHARACTER STRING data types. In all other cases, I personally see no reason to use other libraries in Python.
Like all my projects, such as PyGOST , GoGOST , NNCP , GoVPN , PyDERASN is completely free software , distributed under the LGPLv3 + , and is available for free download. Examples of use are here and in the PyGOST tests .
Sergey Matveyev , Shifropank , a member of the SPO Foundation , Python / Go-developer, Chief Specialist of the Federal State Unitary Enterprise NTC Atlas .
This article discusses the PyDERASN : Python ASN.1 library that is actively used in projects related to cryptography in Atlas .
In general, it is not worthwhile to recommend ASN.1 for cryptographic tasks: ASN.1 and its codecs are complex. This means that the code will not be simple, and it is always an extra attack vector. Just look at the list of vulnerabilities in the ASN.1 libraries. Bruce Schneier in his Cryptography engineering also does not recommend using this standard because of its complexity: “The best-known TLV encoding is ASN.1, but it is incredibly complex and we’re shy away from it.” But, unfortunately, today we have public key infrastructures in which X.509 certificates , CRL, OCSP, TSP, CMP, CMC , CMS messages, and a lot of PKCS standards are actively used. Therefore, you have to be able to work with ASN.1 if you are doing something related to cryptography.
')
ASN.1 can be encoded in a variety of ways / codecs:
- BER (Basic Encoding Rules)
- CER (Canonical Encoding Rules)
- DER (Distinguished Encoding Rules)
- GSER (Generic String Encoding Rules)
- JER (JSON Encoding Rules)
- LWER (Light Weight Encoding Rules)
- OER (Octet Encoding Rules)
- PER (Packed Encoding Rules)
- SER (Signaling specific Encoding Rules)
- XER (XML Encoding Rules)
and a number of others. But in cryptographic tasks in practice, two are used: BER and DER. Even in signed XML documents ( XMLDSig , XAdES ) there will still be Base64-encoded ASN.1 DER objects, as in the JSON-oriented ACME protocol from Let's Encrypt. You can better understand all of these codecs and the BER / CER / DER encoding principles in articles and books: ASN.1 in simple words , ASN.1 - John Larmouth .
BER is a binary byte-oriented (for example, PER, popular in cellular communication - bit-oriented) TLV-format. Each element is encoded as: a tag ( T ag) identifying the type of element being encoded (integer, string, date, etc.), length ( L ength) of the content and the content itself ( V alue). BER optionally allows you to omit the length value, setting the particular indefinite length value and ending the message End-Of-Octets with a label. In addition to length coding, there is a lot of variability in BER in the method of coding data types, such as
- INTEGER, OBJECT IDENTIFIER, BIT STRING, and element length can be unnormalized (not encoded in minimal form);
- BOOLEAN is true for any non-zero content;
- BIT STRING may contain “extra” zero bits;
- BIT STRING, OCTET STRING and all their derived string types, including date / time, can be broken into chunks of variable length, the length of which during (de) coding is not known in advance;
- UTCTime / GeneralizedTime can have different ways of setting the time zone offset and “extra” zero fractions of seconds;
- DEFAULT SEQUENCE values may or may not be encoded;
- Named values of the last bits in BIT STRING can optionally not be encoded;
- SEQUENCE (OF) / SET (OF) can have an arbitrary order of elements.
Because of all of the above, it is not always possible to encode the data so that they are identical to the original form. Therefore, a subset of rules was invented: DER - tightly regulating only one acceptable encoding method, which is critical for cryptographic tasks, where, for example, changing one bit will make the signature or checksum invalid. DER has a significant drawback: the lengths of all elements must be known in advance during encoding, which prevents streamlined serialization of data. CER codec is devoid of this disadvantage, likewise guaranteeing an unambiguous presentation of data. Unfortunately (or fortunately, we don’t have even more complex decoders?), It didn’t become popular. Therefore, in practice, we encounter a “mixed” use of BER and DER encoded data. Since both CER and DER are a subset of BER, any BER decoder is able to process them.
Problems with pyasn1
At work, we write many Python programs related to cryptography. And a few years ago there was practically no choice of free libraries: either these are very low-level libraries that allow you to simply encode / decode, for example, an integer and a structure header, or this is the pyasn1 library. We lived there for several years and at first were very pleased, as it allows working with ASN.1 structures as high-level objects: for example, a decoded X.509 certificate object allows you to access your fields through the dictionary interface: cert ["tbsCertificate"] ["SerialNumber"] will show us the serial number of this certificate. Similarly, you can “collect” complex objects by working with them as with lists, dictionaries, and then simply call the pyasn1.codec.der.encoder.encode function and get a serialized view of the document.
However, flaws, problems and limitations were revealed. In pyasn1, there were and, unfortunately, errors still remain: at the time of this writing, in pyasn1, one of the basic types, GeneralizedTime, is incorrectly decoded and encoded.
In our projects, to save space, we often store only the file path, offset and length in bytes of the object we want to refer to. For example, an arbitrary signed file will most likely be located in the CMS SignedData ASN.1 structure:
0 [1,3,1018] ContentInfo SEQUENCE 4 [1,1, 9] . contentType: ContentType OBJECT IDENTIFIER 1.2.840.113549.1.7.2 (id_signedData) 19-4 [0,0,1003] . content: [0] EXPLICIT [UNIV 16] ANY 19 [1,3, 999] . . DEFINED BY id_signedData: SignedData SEQUENCE 23 [1,1, 1] . . . version: CMSVersion INTEGER v3 (03) 26 [1,1, 19] . . . digestAlgorithms: DigestAlgorithmIdentifiers SET OF [...] 47 [1,3, 769] . . . encapContentInfo: EncapsulatedContentInfo SEQUENCE 51 [1,1, 8] . . . . eContentType: ContentType OBJECT IDENTIFIER 1.3.6.1.5.5.7.12.2 (id_cct_PKIData) 65-4 [1,3, 751] . . . . eContent: [0] EXPLICIT OCTET STRING 751 bytes OPTIONAL 751 820 [1,2, 199] . . . signerInfos: SignerInfos SET OF 823 [1,2, 196] . . . . 0: SignerInfo SEQUENCE 826 [1,1, 1] . . . . . version: CMSVersion INTEGER v3 (03) 829 [0,0, 22] . . . . . sid: SignerIdentifier CHOICE subjectKeyIdentifier [...] 956 [1,1, 64] . . . . . signature: SignatureValue OCTET STRING 64 bytes . . . . . . C1:B3:88:BA:F8:92:1C:E6:3E:41:9B:E0:D3:E9:AF:D8 . . . . . . 47:4A:8A:9D:94:5D:56:6B:F0:C1:20:38:D2:72:22:12 . . . . . . 9F:76:46:F6:51:5F:9A:8D:BF:D7:A6:9B:FD:C5:DA:D2 . . . . . . F3:6B:00:14:A4:9D:D7:B5:E1:A6:86:44:86:A7:E8:C9 and we can get the original signed file at an offset of 65 bytes, with a length of 751 bytes. pyasn1 does not store this information in its decoded objects. The so-called TLVSeeker was written - a small library that allows you to decode tags and object lengths, in the interface of which we commanded “go to the next tag”, “go inside the tag” (go inside the SEQUENCE of the object), “go to the next tag”, “tell your offset and the length of the object where we are. " This was a “manual” walk on ASN.1 DER-serialized data. But it was impossible to work this way with BER-serialized data, since, for example, the OCTET STRING byte string could be encoded in the form of several chunk.
Another drawback for our pyasn1 tasks is the impossibility to understand by decoded objects whether the specified field was present in the SEQUENCE or not. For example, if a structure contains a Field SEQUENCE OF Smth OPTIONAL field, then it could be completely absent in the incoming data (OPTIONAL), but could be present, but at the same time be of zero length (empty list). In general, this could not be figured out. And this is necessary for a strict check of the validity of the incoming data. Imagine that any certification authority would issue a certificate with “not quite” valid data from the point of view of ASN.1-schemes! For example, the certification center “TÜRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı” in its root certificate went beyond the allowable RFC 5280 boundaries of the length of the subject component - it cannot be honestly decoded according to the scheme. The DER codec requires that a field whose value is equal to DEFAULT should not be encoded during transmission — such documents occur in life, and the first version of PyDERASN even consciously allowed such invalid behavior (from the DER point of view) for the sake of backward compatibility.
Another limitation is the impossibility of easily finding out in which form (BER / DER) one or another object in the structure was encoded. For example, the CMS standard says that the message is BER-encoded, but the signedAttrs field over which the cryptographic signature is generated must be in DER. If we decode DER, then we will fall on the processing of the CMS itself; if we decode with BER, we will not know what kind of signedAttrs was. As a result, it is necessary for TLVSeeker (which has no analogue in pyasn1) to search for the location of each of the signedAttrs fields, and decode it separately, from the serialized view, with DER.
The possibility of automatic processing of DEFINED BY fields, which are very common, was very welcome for us. After decoding an ASN.1 structure, we may have many ANY fields left to be processed further according to a scheme chosen on the basis of the OBJECT IDENTIFIER specified in the structure field. In Python code, this means writing an if and then calling the decoder for the ANY field.
PyDERASN appearance
In the Atlas, we regularly, having found some problems or modifying used free programs, send patches to the top. In pyasn1, we sent improvements a few times, but the pyasn1 code is not the easiest to understand, and sometimes there were incompatible API changes that hit us. Plus, we are used to writing tests with generative testing, which was not in pyasn1.
One day I decided to suffice it to endure and it’s time to try to write your own library with __slot __s, offset and perfectly displayed blobs! Just creating an ASN.1 codec would not be enough - you need to transfer all our dependent projects to each other, and these are hundreds of thousands of lines of code that are fully working with ASN.1 structures. That is one of the requirements for it: the ease of translation of the current pyasn1 code. Having spent my entire vacation, I wrote this library, transferred all the projects to it. Since they have almost 100% coverage with tests, this also meant the full performance of the library.
PyDERASN, similarly, has almost 100% test coverage. Generative testing is used with a remarkable hypothesis library. Fuzzing py-afl was also conducted on 32 nuclear machines. Despite the fact that we have almost no Python2 code left, PyDERASN still maintains compatibility with it and because of this it has only six dependencies. In addition, it has been tested against the ASN.1: 2008 compliance test suite .
The principle of working with it is similar to pyasn1 - working with high-level Python objects. The description of the ASN.1 schema is similar.
class TBSCertificate(Sequence): schema = ( ("version", Version(expl=tag_ctxc(0), default="v1")), ("serialNumber", CertificateSerialNumber()), ("signature", AlgorithmIdentifier()), ("issuer", Name()), ("validity", Validity()), ("subject", Name()), ("subjectPublicKeyInfo", SubjectPublicKeyInfo()), ("issuerUniqueID", UniqueIdentifier(impl=tag_ctxp(1), optional=True)), ("subjectUniqueID", UniqueIdentifier(impl=tag_ctxp(2), optional=True)), ("extensions", Extensions(expl=tag_ctxc(3), optional=True)), ) However, PyDERASN has some sort of strong typing. In pyasn1, if the field was of the type CMSVersion (INTEGER), then it could be assigned an int or INTEGER. PyDERASN strictly requires that the object being assigned be exactly CMSVersion. Besides the fact that we are writing Python3 code, we use typing annotations , so our functions will not have incomprehensible arguments like def func (serial, contents), but def func (serial: CertificateSerialNumber, contents: EncapsulatedContentInfo), and PyDERASN helps to observe such code.
At the same time, PyDERASN has extremely convenient indulgences of this very typification. pyasn1 did not allow the SubjectKeyIdentifier (). subtype (implicitTag = Tag (...)) field to assign the SubjectKeyIdentifier () object (without the necessary IMPLICIT TAG-a) and had to frequently copy and recreate objects only because of the changed IMPLICIT / EXPLICIT tags. PyDERASN strictly keeps only the base type - it will automatically insert tags from the existing ASN.1 scheme of the structure. This greatly simplifies the application code.
If an error occurs during decoding, then in pyasn1 it is not easy to understand exactly where it occurred. For example, in the above-mentioned Turkish certificate we get the following error: UTF8String (tbsCertificate: issuer: rdnSequence: 3: 0: value: DEFINED BY 2.5.4.10:utf8String) (at 138) unsatisfied bounds: 1 ⇐ 77 64 When writing ASN .1 structures can make mistakes, and this makes it easier to debug applications or figure out the problems of coded documents from the opposite side.
The first version of PyDERASN did not support BER encoding. Appeared much later and still does not support UTCTime / GeneralizedTime processing with time zones. This will come in the future, because the project is written mainly in his free time.
Also in the first version there was no work with DEFINED BY fields. A few months later, this opportunity appeared and began to be actively used, significantly reducing the application code - in one decoding operation it was possible to get the entire structure disassembled to the very depth. For this, the scheme defines which fields that “define”. For example, the description of the CMS scheme:
class ContentInfo(Sequence): schema = ( ("contentType", ContentType(defines=((("content",), { id_authenticatedData: AuthenticatedData(), id_digestedData: DigestedData(), id_encryptedData: EncryptedData(), id_envelopedData: EnvelopedData(), id_signedData: SignedData(), }),))), ("content", Any(expl=tag_ctxc(0))), ) says that if the contentType contains an OID with the id_signedData value, then the content field (located in the same SEQUENCE) needs to be decoded using the SignedData scheme. Why so many brackets? A field can “define” several fields at the same time, as is the case with EnvelopedData structures. The defined fields are identified by the so-called decode path - it defines the exact location of any element in all structures.
Not always want or not always have the opportunity to immediately in the scheme to make these defines. There may be application-specific cases where OIDs and structures are known only in a third-party project. PyDERASN provides the ability to specify these directly at the time of decoding the structure:
ContentInfo().decode(data, ctx={"defines_by_path": (( ( "content", DecodePathDefBy(id_signedData), "certificates", any, "certificate", "tbsCertificate", "extensions", any, "extnID", ), ((("extnValue",), { id_ce_authorityKeyIdentifier: AuthorityKeyIdentifier(), id_ce_basicConstraints: BasicConstraints(), [...] id_ru_subjectSignTool: SubjectSignTool(), }),), ),)}) Here we say that in CMS SignedData for all attached certificates, decode all their extensions (AuthorityKeyIdentifier, BasicConstraints, SubjectSignTool, etc.). We specify through the decode path, what element should be “substituted” defines, as if it were specified in the scheme.
Finally, PyDERASN has the ability to work from the command line to decode ASN.1 files and has a rich pretty printing . You can decode an arbitrary ASN.1, or you can define a well-defined scheme and see something like this:
Displayed information: object offset, tag length, length length, content length, presence of EOC (end-of-octets), BER encoding feature, encoding indefinite-length indication, EXPLICIT tag length and offset (if any), object nesting depth structures, IMPLICIT / EXPLICIT tag value, object name according to the scheme, its basic ASN.1 type, sequence number within SEQUENCE / SET OF, CHOICE value (if any), human readable INTEGER / ENUMERATED / BIT STRING number according to the scheme, value of any basic type , DEFAULT / OPTIONAL flag from the circuit, the sign that the object was automatically decoded as DEFINED BY and for with gm of OID-and it happened, chelovekochitaemy OID.
The pretty printing system is specially designed so that it generates a sequence of PP objects, which are already visualized by separate means. The screenshot shows the renderer in plain color text. There are renderer in JSON / HTML format, so that it can be backlit in an ASN.1 browser as in an asn1js project.
Other libraries
This was not the goal, but PyDERASN was much faster than pyasn1. For example, decoding CRL files of megabyte sizes can take so long that you have to think about intermediate data storage formats (fast) and change the architecture of applications. pyasn1 decodes the CRL CACert.org CRL on my laptop in more than 20 minutes, whereas PyDERASN in just 28 seconds! There is an asn1crypto project aimed at quick work with cryptographic structures: it decodes (completely, not lazily) the same CRL in 29 seconds, but consumes almost twice as much RAM when running under Python3 (983 MiB versus 498 mi), and 3.5 times under Python2 (1677 against 488), while pyasn1 consumes 4.3 times as much (2093 against 488).
asn1crypto, which I mentioned, we did not consider, because the project was still in its infancy, and we did not hear about it. Now they would not have looked at him either, since I immediately discovered that the same GeneralizedTime does not accept an arbitrary form, and when serialized, it silently removes a split second. This is acceptable for working with X.509 certificates, but in general it will not work.
At the moment, PyDERASN is the strictest free Python / Go DER decoder known to me. In the encoding / asn1 library of my favorite Go, I do not have strict OBJECT IDENTIFIER and UTCTime / GeneralizedTime string checking . Sometimes severity can interfere (primarily due to backward compatibility with old applications that no one will fix), so various settings for debugging checks can be sent to PyDERASN during decoding.
The project code tries to be as simple as possible. The entire library is one file. The code is written with an emphasis on ease of understanding, without unnecessary optimization of performance and DRY-code. There is no, as I said, there is no support for full-BER decoding of UTCTime / GeneralizedTime strings, as well as REAL, RELATIVE OID, EXTERNAL, INSTANCE OF, EMBEDDED PDV, CHARACTER STRING data types. In all other cases, I personally see no reason to use other libraries in Python.
Like all my projects, such as PyGOST , GoGOST , NNCP , GoVPN , PyDERASN is completely free software , distributed under the LGPLv3 + , and is available for free download. Examples of use are here and in the PyGOST tests .
Sergey Matveyev , Shifropank , a member of the SPO Foundation , Python / Go-developer, Chief Specialist of the Federal State Unitary Enterprise NTC Atlas .
Source: https://habr.com/ru/post/444272/
All Articles