Autocentric ranking. Yandex's report on finding a relevant audience for Zen authors
The most important thing for the Yandex.Dzen service is to develop and maintain a platform that connects the audience with the authors. To be an attractive platform for good authors, Zen must be able to find the relevant audience for channels writing on any topic, including the narrowest ones. The head of the authors happiness group, Boris Sharchilev, spoke about author-centered rankings, which selects the most relevant users for the authors. From the report you can learn about how this approach differs from the selection of relevant items - more popular in recommender systems.
- Colleagues, hello everyone. My name is Boria. I do quality rankings in Zen. I am sure that this is one of the most interesting services of Yandex, we have very cool machine learning, and in the next 17 minutes I will try to convince you of this.
What is Zen? If it is very simple, Zen is a service of personal recommendations. We try to recommend to users relevant content based on what we know about the interests of these users. Our high-level goal is for users to want to spend time in Zen. And what is very important is that they do not regret this time.
')
This is approximately our main form of content consumption. This is an endless tape of recommendations. And here it is clear that we, in principle, try to recommend very materials on very different topics. There are different themes: something about business, something about humor, even something about fantasy. That is, in the tape you can find both educational and educational articles, as well as more entertaining ones. And, of course, personalization. Zen tape for everyone looks different - depending on what the user is interested. Plus, of course, a bit of advertising.

A very important point. At the very beginning, when we first appeared, we were, in fact, an aggregator of content from the Internet. That is, we went around existing sites, took content from them, and showed it to the user depending on interests. Now the situation is different. Now Zen is a whole blogger platform on which each person can start their own channel, be it a well-known blogger or novice author who has something to tell. New authors see such a nice welcome screen, in which we talk about the service - that Zen itself will select the audience, and all that is required of it is to write good materials.
Now the platform accounts for more than half of the total traffic in Zen. And this figure will only grow. We understand that everyone can rank existing content. Of course, we will do it better than anyone. But not everyone has unique content, and we believe that this will be our competitive advantage.

It is important to understand that Zen is already very big. According to Yandex.Radar, at the end of last year we have about 10–12 million daily readers, about 35 million readers per month, and even according to some sources, from Yandex.Radar, we were last year first walked around the audience Yandeks.Novosti. This means that we are seriously doing the Internet, we have very serious tasks, there are many of them, and we are looking forward to your help.
Let's talk about the details of how this works, and discuss what we can do with the intern, how to help our service.
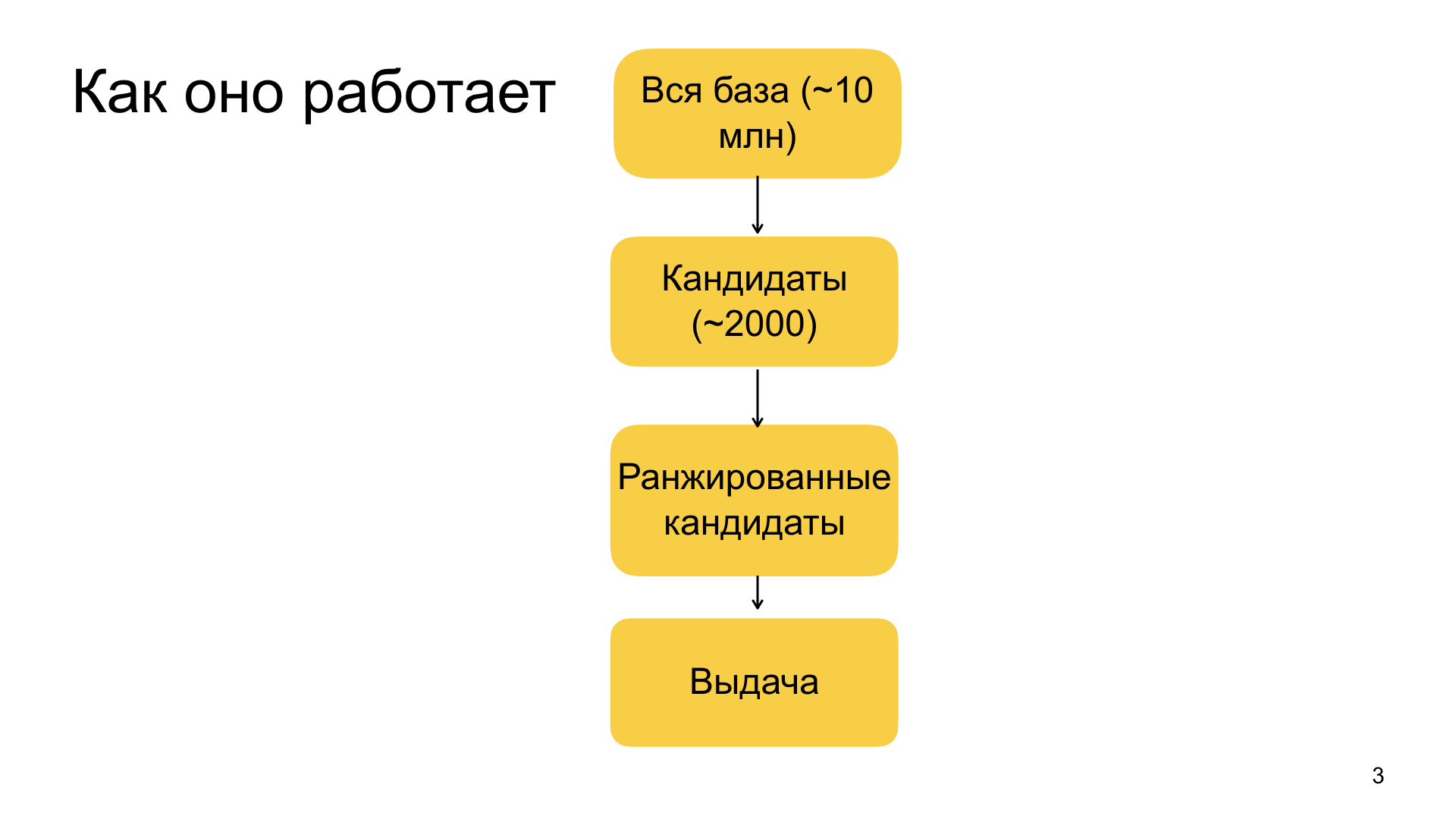
The general scheme of recommendations we have something like this. It all starts with our large database of documents, from which we select materials for recommendations. It consists of tens of millions of documents. Moreover, this database is constantly updated - about a million new documents arrive every day. Ideally, we would like to apply our entire machine learning machine to all these tens of millions of documents personally for each user, and choose the most relevant for him. But, unfortunately, in practice, this can not be done, because Zen is a service that works in real time. We have very tough guarantees on how quickly we are ready to respond, so for practical reasons we have to narrow down the database from tens of millions of documents to thousands of potential recommendations, which we can already fully otranzhirovat our model and choose the most relevant. This stage of narrowing the base from tens of millions to about thousands in our country is called candidate selection or easy ranking.
When we have this set, we apply our complex large machine learning model to it, which at the top level is a gradient boosting. Everything is without surprises, but the factors are very diverse - from some simple ones that characterize, for example, how relevant the domain is to the user, the source, how often he enters it, clicks, leaves feedback, likes and dislikes. So are more complex factors that are based, for example, on neural network features. We process the text of the article, we process pictures, other data sources, and use such composite features too. All this scheme is quite complicated, I will not have time to tell in details.
After we have ranked our 2 thousand candidates, we select the top of them. The size of the stamp depends on how much we need to recommend the materials. It is always defined in different ways. And so we form the final issue.
It looks like a scheme at a high level. Now let's talk about what components of the whole process we are interested in improving.

It turns out that we are interested in doing just about everything. There are a lot of tasks. We want to increase the speed of data delivery for ranking: the fresher our data is, the more relevant we make recommendations. I want to speed up the service time: the faster we work, the better the user experience. We want to increase the reliability of the service.
It is important for us to improve the ranking. That is, we need to apply new machine learning models and improve our current models in other countries. We are recommended not only in Russia, but also in many other countries of the world.
We also want to take into account regionality and recommend people content that relates to their region.
And it is very important - we need to develop our author's platform. This is our future, we need to invest in it. There are a lot of tasks here too. In particular, we need to be able to find and launch quality content. It is important for us to show good materials, not trash. We need to be able to rank new content formats. We have not only articles, but also short videos, and posts that users watch right in the feed. All these formats need to be able to rank.
And a very important point about which I want to talk a little more in more technical details - it is important for us to be able for each author to find the relevant audience, even if we are talking about rather niche authors and topics. Let's talk in more detail, what is the problem here and how we solve it.
Let's look at this with an example.
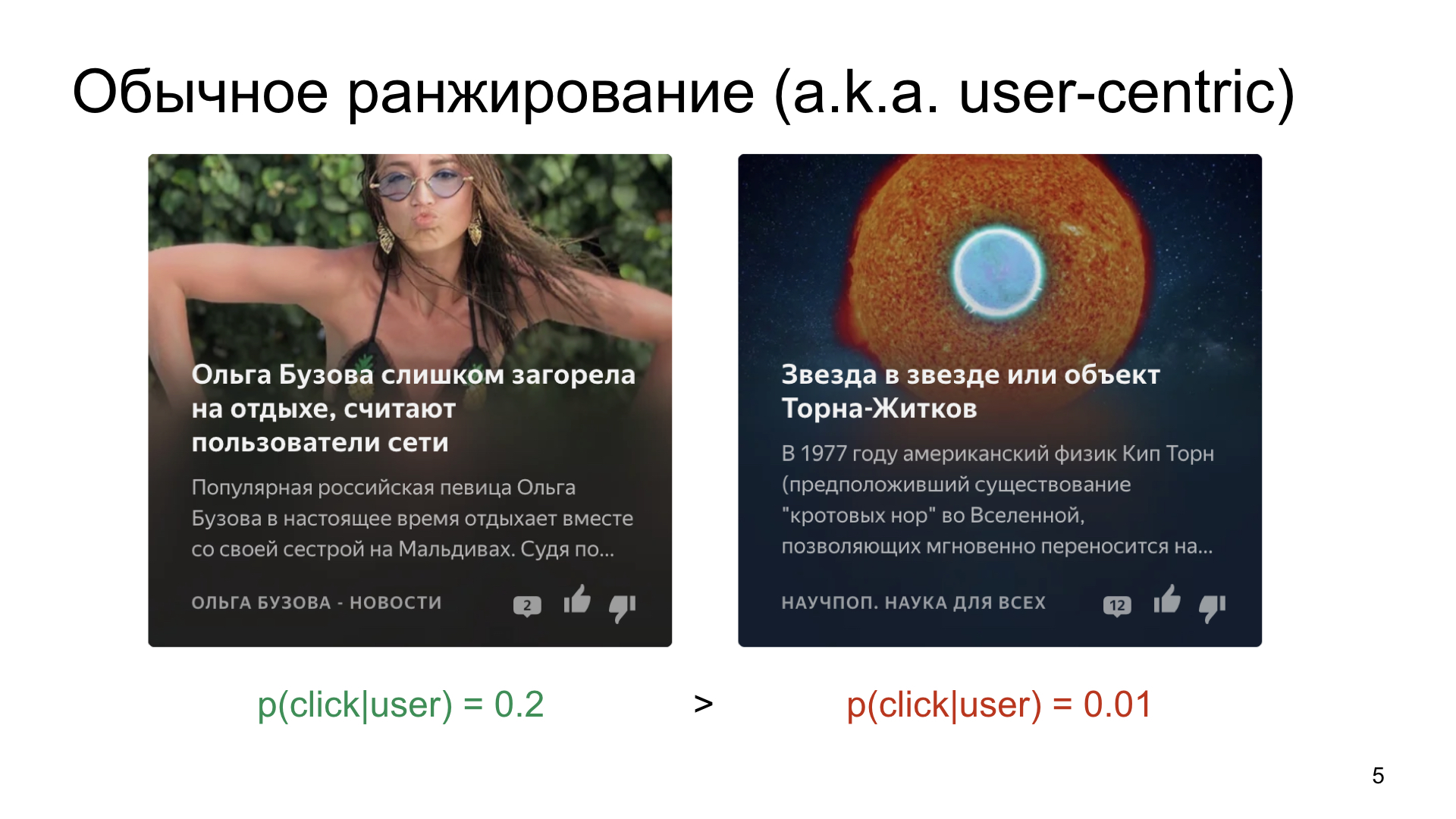
We choose, suppose, from two cards that we want to show to the user.
This is how the world works and this is how a person works, that there is something more popular, where the probability of a click is on average 20 percent, and there is something more niche, for example, articles about science or space.
If we simply rank the cards according to the probability of a click, then, of course, more clickable and simpler content will collect a very large number of impressions, and even a very good article about science will not. Of course, we do not want this. We want to find an interested audience, even for niche channels.

Why do you want to do this? In fact, there are two reasons. The first is grocery. That is, we want Zen to be a slice of the Internet. So that everything that the user can find and what he is interested in on the Internet is presented in Zen. And so that he gets what he is interested.
Scientific channels have their own audience. But there is such a nuance. If science lovers show science and popular content, they are more likely to click on it than science. But if they show only science, they will click on science too, and they will not even regret it at all. The question is how to find such people and how to show content, focusing not on the user, but on the author.

How to do it? The usual ranking formula, which predicts the likelihood of clicks, will not help us here, because on average, more niche articles will lose. But you can go another way - to allocate a certain quota, and in it more or less evenly give shows to the authors, give them a sort of minimum guarantee. This can be done, and it will make the authors a little happier, but unfortunately, it will make our users less happy. Users will click less, get more upset and leave. We certainly do not want this.
How to be here?
We thought for a long time and came up with a new concept. We called it autorocentric ranking or screenings for the author.
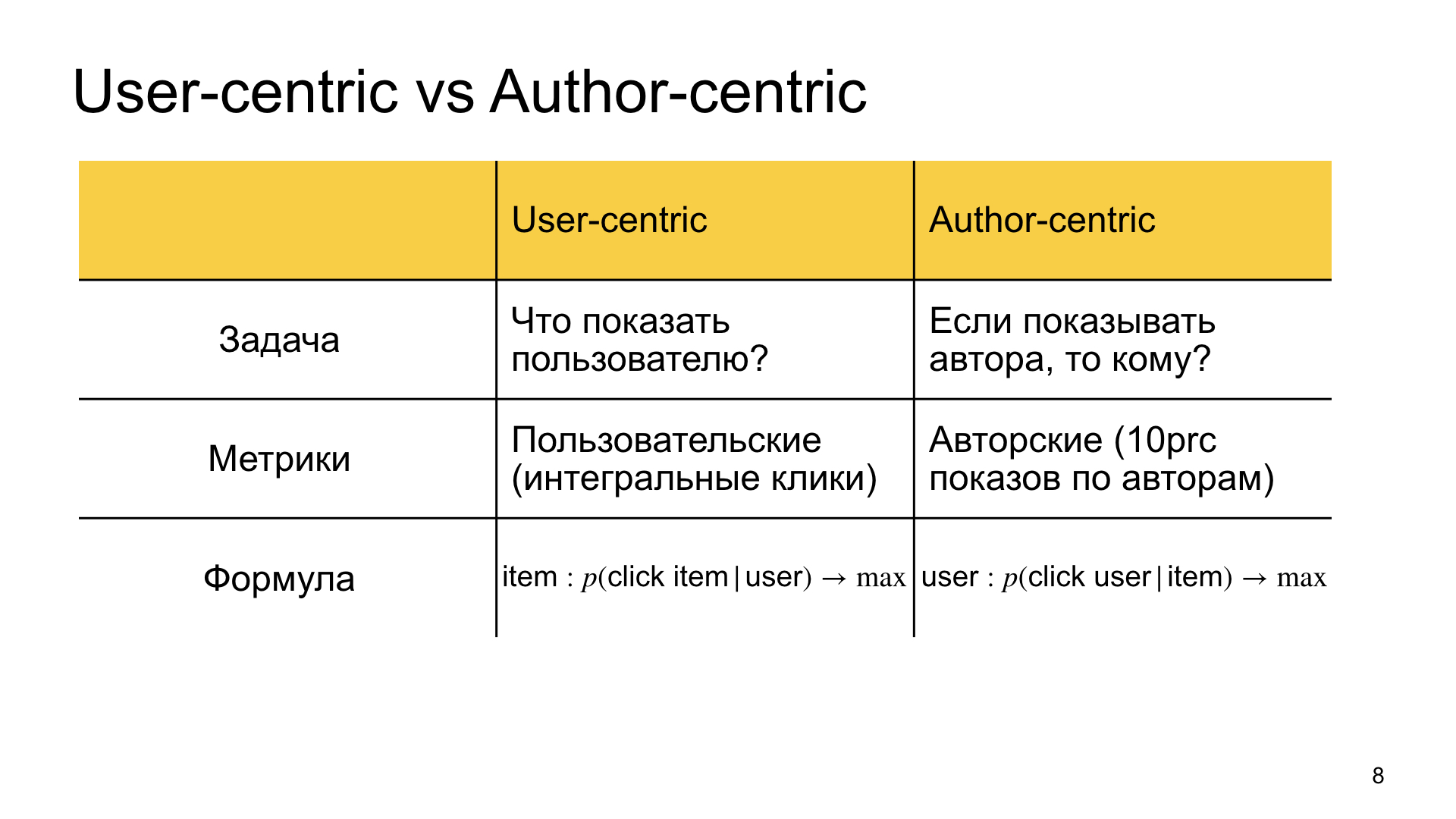
What is our goal in the usual ranking, which we call user-centric? Find the material that is most relevant to the user. We answer the question what to show the user.
In the author-centered ranking, we seem to overturn the formulation of the problem and say that we want to show the given author, and the question is to whom to show him, to whom he is most relevant. Hence the difference in metrics. In the first case, we are more interested in user metrics, that is, integral clicks, integral time in Zen, and so on. In the second case, we are interested in the so-called author's metrics. For example, we measure how well we live in Zen, for example, bottom 10% of authors. If they live well enough, then everyone else is happy too.

How do we do it? Suppose we have the usual ranking formula. For simplicity, suppose that it predicts the probability of a user clicking on a given item, on a given card. What will we do? Now let's fix it for each article and apply our model for this article, ideally - to all users, in practice - to some user sample. And build the distribution of our scores, that is, estimates of the probability of clicking on an article for each article by users. Now for each article we have such a distribution, as in the graph (slide above - approx. Ed.). After that, let's rank the articles for the user and choose the top not only by the probability of a click, but by the percentile into which the given user falls for this article. That is, we estimate the probability of a click, see where the user falls in this distribution, and rank by this value.

Here we have the same two cards, one of them is more clickable, 20%, the other - less, 1%. Now, if we take a particular user, it is possible that he has a more likely click rate on a more popular card than on a less popular, say, 10% versus 3%. But since, on average, the probability of clicking on a popular card is 20%, and the user has 10%, then it is, on average, less relevant to this publication than the average Zen user. And in another situation, on the contrary: he has a probability of a click of 3%, but on average, the article has 1%. Therefore, it is a more relevant audience for the article on average than other Zen users. Therefore, the key insight here is that even if the probability of clicking on an article is less, with the help of such a framework, we have the chance to show a less popular article if the user enters the most trusted core for this publication.

If users come to us more or less evenly, then the score for which we rank, that is, the percentile in which each user falls, will be distributed evenly among users. This means that if all articles are ranked in this way, then all of them will collect more or less the same number of impressions. There will be no emissions of tens of millions of hits versus 10 hits for any less relevant cards. Thus, by balancing user-centered and autorocentric rankings, we can achieve that ratio of users 'happiness and authors' happiness, which we consider correct.
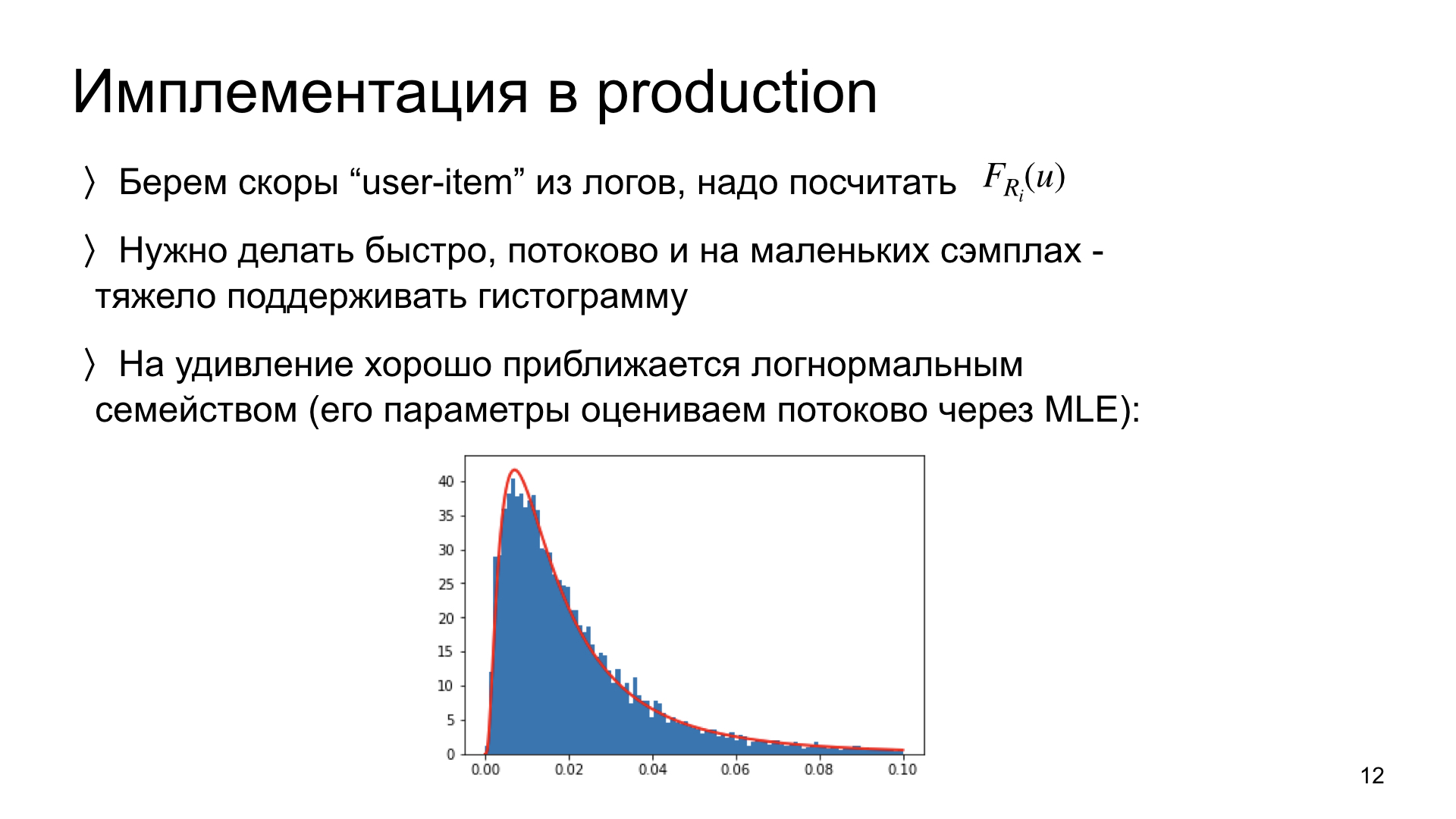
A few words about how we implement this in production. We need to look at our logs and count the distribution for each article. An important limitation: we need to be able to do it, firstly, quickly, and secondly, in streaming mode. That is, ideally, in order to update the distribution estimate for the new data, we need to keep in mind not all previous data, but only the current estimate. Such a system is scaled, such a scheme works. Ideally, we need to be able to do this on small data. If any article has only 300 impressions, then we need to be able to adequately estimate the distribution for such a number of observations.
We conducted experiments and found that such distribution scores surprisingly well approach log-normal distributions. That is, this empirical observation. And if so, then instead of estimating the entire distribution histogram not parametrically, we can estimate only two parameters of this distribution. Moreover, we can do this in the stream, using only the current estimation of parameters and new observations. This scheme is very fast and works very well. Now she is in production.
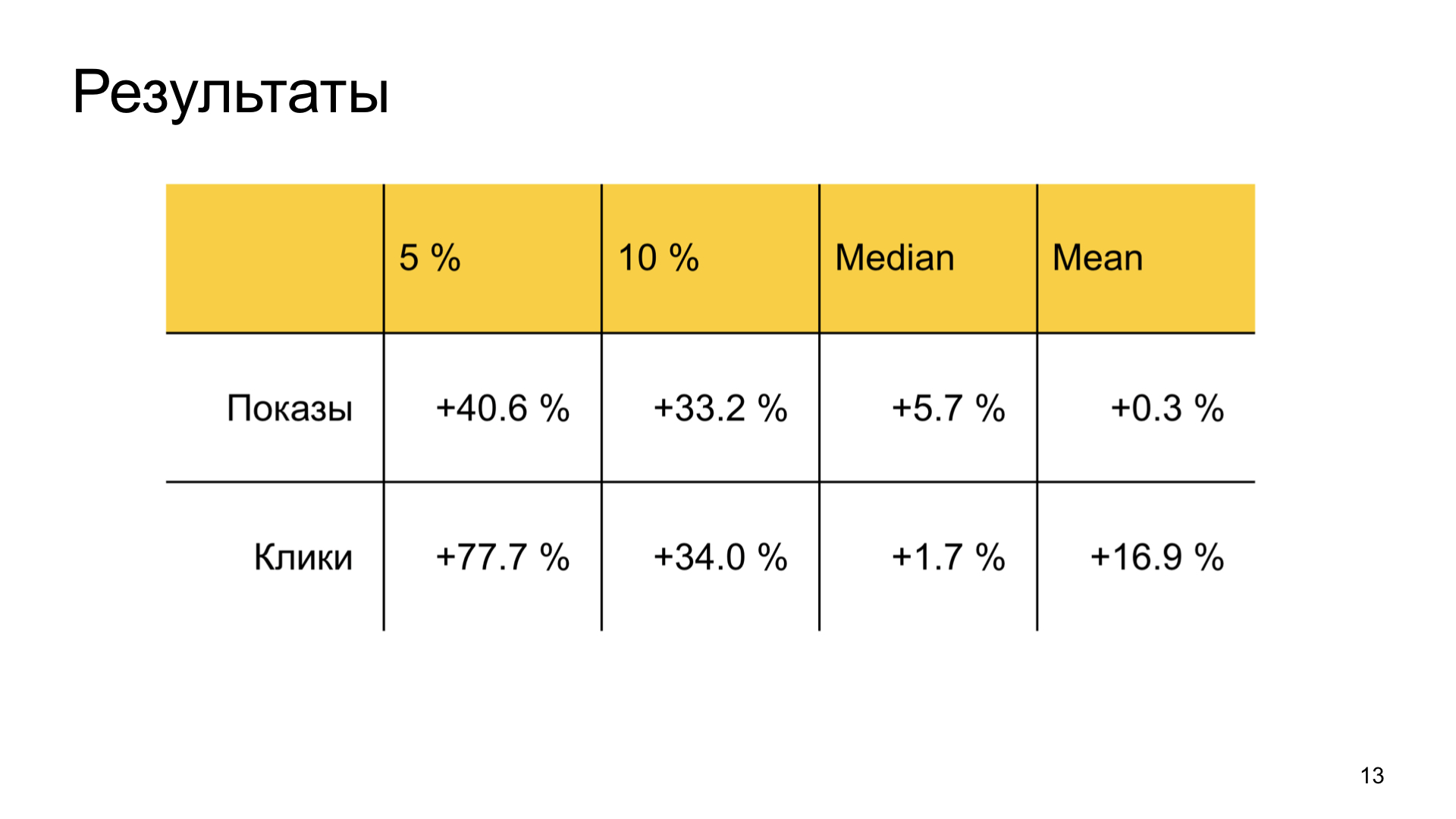
The results are also good. We greatly increase the happiness of the good authors in Zen who are deprived of the attention and at the same time do not squander the common user metrics. That is, the business problem is fully achieved.
I have now shown one of the examples of tasks that we can do. Of course, these tasks are many, and with each of them we need your help. We hope that you want to work with us . Finally, I will say a few words about what we expect from the interns and what we do not expect from them. From the intern we are waiting for the most important thing - the ability to write code. In our service, there are no pure Scientists. We have everything - ML-engineers, they should be able to do a full cycle of tasks. They must be able and implement their solution in production, and apply ML. That is, we expect that you can write code at a basic level, understand the approaches, know the algorithms, data structures, the basics of machine learning.
What we do not expect from the interns? First of all, we do not expect deep knowledge of any languages or frameworks. That is, if you do not know how Korutin work in Python - do not worry, we will teach you everything. And we do not expect much experience from you. We are waiting for your knowledge, desire to work. If there is no experience - do not worry. We will teach everything, and everything will be fine. Thank!
By balancing user-centered and auto-centered rankings, we can achieve the right mix of user happiness and authors happiness.
- Colleagues, hello everyone. My name is Boria. I do quality rankings in Zen. I am sure that this is one of the most interesting services of Yandex, we have very cool machine learning, and in the next 17 minutes I will try to convince you of this.
What is Zen? If it is very simple, Zen is a service of personal recommendations. We try to recommend to users relevant content based on what we know about the interests of these users. Our high-level goal is for users to want to spend time in Zen. And what is very important is that they do not regret this time.
')
This is approximately our main form of content consumption. This is an endless tape of recommendations. And here it is clear that we, in principle, try to recommend very materials on very different topics. There are different themes: something about business, something about humor, even something about fantasy. That is, in the tape you can find both educational and educational articles, as well as more entertaining ones. And, of course, personalization. Zen tape for everyone looks different - depending on what the user is interested. Plus, of course, a bit of advertising.
A very important point. At the very beginning, when we first appeared, we were, in fact, an aggregator of content from the Internet. That is, we went around existing sites, took content from them, and showed it to the user depending on interests. Now the situation is different. Now Zen is a whole blogger platform on which each person can start their own channel, be it a well-known blogger or novice author who has something to tell. New authors see such a nice welcome screen, in which we talk about the service - that Zen itself will select the audience, and all that is required of it is to write good materials.
Now the platform accounts for more than half of the total traffic in Zen. And this figure will only grow. We understand that everyone can rank existing content. Of course, we will do it better than anyone. But not everyone has unique content, and we believe that this will be our competitive advantage.
It is important to understand that Zen is already very big. According to Yandex.Radar, at the end of last year we have about 10–12 million daily readers, about 35 million readers per month, and even according to some sources, from Yandex.Radar, we were last year first walked around the audience Yandeks.Novosti. This means that we are seriously doing the Internet, we have very serious tasks, there are many of them, and we are looking forward to your help.
Let's talk about the details of how this works, and discuss what we can do with the intern, how to help our service.
The general scheme of recommendations we have something like this. It all starts with our large database of documents, from which we select materials for recommendations. It consists of tens of millions of documents. Moreover, this database is constantly updated - about a million new documents arrive every day. Ideally, we would like to apply our entire machine learning machine to all these tens of millions of documents personally for each user, and choose the most relevant for him. But, unfortunately, in practice, this can not be done, because Zen is a service that works in real time. We have very tough guarantees on how quickly we are ready to respond, so for practical reasons we have to narrow down the database from tens of millions of documents to thousands of potential recommendations, which we can already fully otranzhirovat our model and choose the most relevant. This stage of narrowing the base from tens of millions to about thousands in our country is called candidate selection or easy ranking.
When we have this set, we apply our complex large machine learning model to it, which at the top level is a gradient boosting. Everything is without surprises, but the factors are very diverse - from some simple ones that characterize, for example, how relevant the domain is to the user, the source, how often he enters it, clicks, leaves feedback, likes and dislikes. So are more complex factors that are based, for example, on neural network features. We process the text of the article, we process pictures, other data sources, and use such composite features too. All this scheme is quite complicated, I will not have time to tell in details.
After we have ranked our 2 thousand candidates, we select the top of them. The size of the stamp depends on how much we need to recommend the materials. It is always defined in different ways. And so we form the final issue.
It looks like a scheme at a high level. Now let's talk about what components of the whole process we are interested in improving.
It turns out that we are interested in doing just about everything. There are a lot of tasks. We want to increase the speed of data delivery for ranking: the fresher our data is, the more relevant we make recommendations. I want to speed up the service time: the faster we work, the better the user experience. We want to increase the reliability of the service.
It is important for us to improve the ranking. That is, we need to apply new machine learning models and improve our current models in other countries. We are recommended not only in Russia, but also in many other countries of the world.
We also want to take into account regionality and recommend people content that relates to their region.
And it is very important - we need to develop our author's platform. This is our future, we need to invest in it. There are a lot of tasks here too. In particular, we need to be able to find and launch quality content. It is important for us to show good materials, not trash. We need to be able to rank new content formats. We have not only articles, but also short videos, and posts that users watch right in the feed. All these formats need to be able to rank.
And a very important point about which I want to talk a little more in more technical details - it is important for us to be able for each author to find the relevant audience, even if we are talking about rather niche authors and topics. Let's talk in more detail, what is the problem here and how we solve it.
Let's look at this with an example.
We choose, suppose, from two cards that we want to show to the user.
This is how the world works and this is how a person works, that there is something more popular, where the probability of a click is on average 20 percent, and there is something more niche, for example, articles about science or space.
If we simply rank the cards according to the probability of a click, then, of course, more clickable and simpler content will collect a very large number of impressions, and even a very good article about science will not. Of course, we do not want this. We want to find an interested audience, even for niche channels.
Why do you want to do this? In fact, there are two reasons. The first is grocery. That is, we want Zen to be a slice of the Internet. So that everything that the user can find and what he is interested in on the Internet is presented in Zen. And so that he gets what he is interested.
Scientific channels have their own audience. But there is such a nuance. If science lovers show science and popular content, they are more likely to click on it than science. But if they show only science, they will click on science too, and they will not even regret it at all. The question is how to find such people and how to show content, focusing not on the user, but on the author.
How to do it? The usual ranking formula, which predicts the likelihood of clicks, will not help us here, because on average, more niche articles will lose. But you can go another way - to allocate a certain quota, and in it more or less evenly give shows to the authors, give them a sort of minimum guarantee. This can be done, and it will make the authors a little happier, but unfortunately, it will make our users less happy. Users will click less, get more upset and leave. We certainly do not want this.
How to be here?
We thought for a long time and came up with a new concept. We called it autorocentric ranking or screenings for the author.
What is our goal in the usual ranking, which we call user-centric? Find the material that is most relevant to the user. We answer the question what to show the user.
In the author-centered ranking, we seem to overturn the formulation of the problem and say that we want to show the given author, and the question is to whom to show him, to whom he is most relevant. Hence the difference in metrics. In the first case, we are more interested in user metrics, that is, integral clicks, integral time in Zen, and so on. In the second case, we are interested in the so-called author's metrics. For example, we measure how well we live in Zen, for example, bottom 10% of authors. If they live well enough, then everyone else is happy too.
How do we do it? Suppose we have the usual ranking formula. For simplicity, suppose that it predicts the probability of a user clicking on a given item, on a given card. What will we do? Now let's fix it for each article and apply our model for this article, ideally - to all users, in practice - to some user sample. And build the distribution of our scores, that is, estimates of the probability of clicking on an article for each article by users. Now for each article we have such a distribution, as in the graph (slide above - approx. Ed.). After that, let's rank the articles for the user and choose the top not only by the probability of a click, but by the percentile into which the given user falls for this article. That is, we estimate the probability of a click, see where the user falls in this distribution, and rank by this value.
Here we have the same two cards, one of them is more clickable, 20%, the other - less, 1%. Now, if we take a particular user, it is possible that he has a more likely click rate on a more popular card than on a less popular, say, 10% versus 3%. But since, on average, the probability of clicking on a popular card is 20%, and the user has 10%, then it is, on average, less relevant to this publication than the average Zen user. And in another situation, on the contrary: he has a probability of a click of 3%, but on average, the article has 1%. Therefore, it is a more relevant audience for the article on average than other Zen users. Therefore, the key insight here is that even if the probability of clicking on an article is less, with the help of such a framework, we have the chance to show a less popular article if the user enters the most trusted core for this publication.
If users come to us more or less evenly, then the score for which we rank, that is, the percentile in which each user falls, will be distributed evenly among users. This means that if all articles are ranked in this way, then all of them will collect more or less the same number of impressions. There will be no emissions of tens of millions of hits versus 10 hits for any less relevant cards. Thus, by balancing user-centered and autorocentric rankings, we can achieve that ratio of users 'happiness and authors' happiness, which we consider correct.
A few words about how we implement this in production. We need to look at our logs and count the distribution for each article. An important limitation: we need to be able to do it, firstly, quickly, and secondly, in streaming mode. That is, ideally, in order to update the distribution estimate for the new data, we need to keep in mind not all previous data, but only the current estimate. Such a system is scaled, such a scheme works. Ideally, we need to be able to do this on small data. If any article has only 300 impressions, then we need to be able to adequately estimate the distribution for such a number of observations.
We conducted experiments and found that such distribution scores surprisingly well approach log-normal distributions. That is, this empirical observation. And if so, then instead of estimating the entire distribution histogram not parametrically, we can estimate only two parameters of this distribution. Moreover, we can do this in the stream, using only the current estimation of parameters and new observations. This scheme is very fast and works very well. Now she is in production.
The results are also good. We greatly increase the happiness of the good authors in Zen who are deprived of the attention and at the same time do not squander the common user metrics. That is, the business problem is fully achieved.
I have now shown one of the examples of tasks that we can do. Of course, these tasks are many, and with each of them we need your help. We hope that you want to work with us . Finally, I will say a few words about what we expect from the interns and what we do not expect from them. From the intern we are waiting for the most important thing - the ability to write code. In our service, there are no pure Scientists. We have everything - ML-engineers, they should be able to do a full cycle of tasks. They must be able and implement their solution in production, and apply ML. That is, we expect that you can write code at a basic level, understand the approaches, know the algorithms, data structures, the basics of machine learning.
What we do not expect from the interns? First of all, we do not expect deep knowledge of any languages or frameworks. That is, if you do not know how Korutin work in Python - do not worry, we will teach you everything. And we do not expect much experience from you. We are waiting for your knowledge, desire to work. If there is no experience - do not worry. We will teach everything, and everything will be fine. Thank!
Source: https://habr.com/ru/post/444040/
All Articles