C # is a low level language?
I am a big fan of everything that Fabien Sanglard does, I like his blog, and I read both of his books from cover to cover (they were told about in a recent podcast by Hansleminutes ).
Recently, Fabien wrote a great post, where he deciphered a tiny raytracer , deobfusing the code and explaining mathematics in a fantastically beautiful way. I really recommend taking the time to read this!
But it made me think, is it possible to transfer this C ++ code to C # ? Since I have been writing quite a lot in C ++ in my main job lately, I thought that I could try.
')
But more importantly, I wanted to get a better idea of whether C # is a low-level language ?
A slightly different, but related question: how suitable is C # for “system programming”? On this topic, I really recommend Joe Duffy's excellent post from 2013 .
I started with a simple transfer of deobfuscated C ++ code line by line in C #. It was quite simple: it seems that the truth is that C # is C ++++ !!!
The example shows the basic data structure - 'vector', here’s a comparison, C ++ on the left, C # on the right:

So, there are a few syntactic differences, but since .NET allows you to define your own value types , I was able to get the same functionality. This is important because processing 'vector' as structures means that we can get better “data locality”, and there is no need to involve the .NET garbage collector, since the data will go to the stack (yes, I know this is an implementation detail).
For more information about
In particular, in the last post of Eric Lippert we find such a useful quotation, which makes it clear what the “types of values” really are:
Now let's see how some other methods look like in comparison (again C ++ on the left, C # on the right), first
Then
(see Fabian’s post for an explanation of what these two functions do)
But again, the fact is that C # makes it very easy to write C ++ code! In this case, the
Now sometimes using
But the most important thing is that such a script provides our C # port with the same behavior as the C ++ source code. Although I want to note that the so-called "managed links" are not quite the same as "pointers", in particular, you cannot do arithmetic on them, for more details, see here:
Thus, the code is well ported, but performance also matters. Especially in the raytracer, which can cheat a frame a few minutes. The C ++ code contains the

Clearly not very realistic!
But when you get to

But running with
To meaningfully compare C ++ and C #, I used the time-windows tool, this is the port of the unix command
Initially, we see that the C # code is a bit slower than the C ++ version, but it gets better (see below).
But let's first see what the .NET JIT is doing to us, even with this “naive” line-by-line port. First, it does a good job of embedding smaller “helper methods”. This is evident in the output of the magnificent tool Inlining Analyzer (green = embedded):
However, it does not embed all methods, for example, because of the complexity,
Another function of the .NET Just-In-Time (JIT) compiler is to convert certain method calls to the corresponding CPU instructions. We can see this in action with the
And here is the assembler code that generates the .NET JIT: there is no call to
(To get this issue, follow these instructions , use the Disasmo VS2019 add-in or look at SharpLab.io )
These replacements are also known as intrinsics , and in the code below we can see how JIT generates them. This snippet shows mapping for
As you can see, some methods are implemented as, for example,
This whole process is very well explained in the article “How is Math.Pow () implemented in the .NET Framework?” , It can also be seen in the CoreCLR source code:
I wonder whether it is possible to improve on the go naive line-by-line port. After some profiling, I made two major changes:
These changes are explained in more detail below.
For more information on why this is necessary, see this excellent answer to Stack Overflow from Andrei Akinshin , along with benchmarks and assembler code. He comes to the following conclusion:
Changes can be seen in this diff .
Secondly, and most importantly, I have significantly improved performance by making the following changes:
Beginning with .NET Standard 2.1, there are specific implementations of
After these changes, the difference in performance of C # and C ++ code was reduced to about 10%:
TC - layered compilation, Tiered Compilation ( I suppose it will be enabled by default in .NET Core 3.0)
For completeness, here are the results of several runs:
Note : the difference between the .NET Core and the .NET Framework is due to the absence of the MathF API in the .NET Framework 4.7.2, for more information, see the .Net Framework Support Ticket (4.8?) For netstandard 2.1 .
I am sure that the code can still be improved!
If you are interested in eliminating the performance difference, here is the C # code . For comparison, you can watch the C ++ assembler code from the excellent Compiler Explorer service.
Finally, if it helps, here’s the output of the Visual Studio profiler with the “hot path” display (after the performance improvements described above):
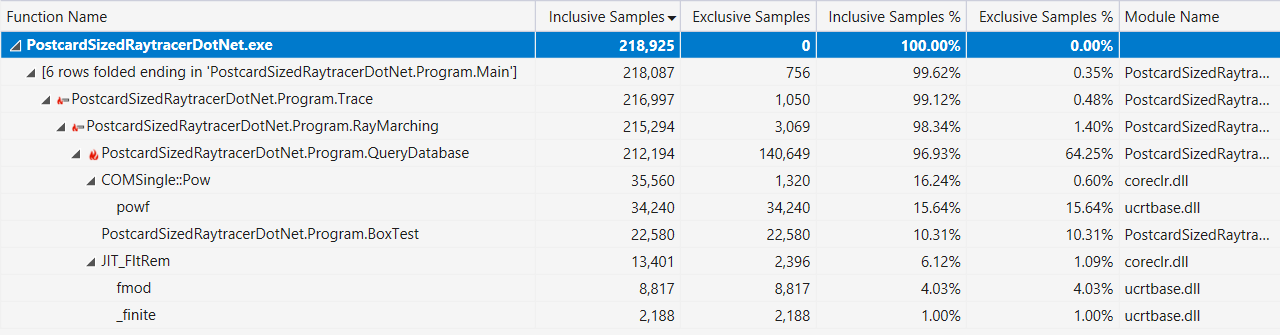
Or more specifically:
* Yes, I understand that “low level” is a subjective term.
Note: each C # developer has his own idea of what “low level” is, these functions will be taken for granted by C ++ or Rust programmers.
Here is the list I made:
I also threw a cry on Twitter and got a lot more options for inclusion in the list:
So in the end, I would say that C # certainly allows you to write code that looks like C ++ and, in combination with the runtime and base class libraries, provides many low-level functions.
Unity Burst Compiler:
Recently, Fabien wrote a great post, where he deciphered a tiny raytracer , deobfusing the code and explaining mathematics in a fantastically beautiful way. I really recommend taking the time to read this!
But it made me think, is it possible to transfer this C ++ code to C # ? Since I have been writing quite a lot in C ++ in my main job lately, I thought that I could try.
')
But more importantly, I wanted to get a better idea of whether C # is a low-level language ?
A slightly different, but related question: how suitable is C # for “system programming”? On this topic, I really recommend Joe Duffy's excellent post from 2013 .
Line by line
I started with a simple transfer of deobfuscated C ++ code line by line in C #. It was quite simple: it seems that the truth is that C # is C ++++ !!!
The example shows the basic data structure - 'vector', here’s a comparison, C ++ on the left, C # on the right:
So, there are a few syntactic differences, but since .NET allows you to define your own value types , I was able to get the same functionality. This is important because processing 'vector' as structures means that we can get better “data locality”, and there is no need to involve the .NET garbage collector, since the data will go to the stack (yes, I know this is an implementation detail).
For more information about
structs or “value types” in .NET, see here:- Heap vs. Stack, Value Type vs. Reference Type
- Value Types vs. Reference Types
- Memory in .NET: what's where
- The truth about value types
- The stack is an implementation detail, part one
In particular, in the last post of Eric Lippert we find such a useful quotation, which makes it clear what the “types of values” really are:
Of course, the most important fact about the types of values is not the implementation details, as they stand out , but rather the original semantic meaning of the “ value type”, but that it is always copied “by value” . If the allocation information were important, we would call them "heap types" and "stack types." But in most cases it does not matter. Most of the time, the semantics of copying and identification is relevant.
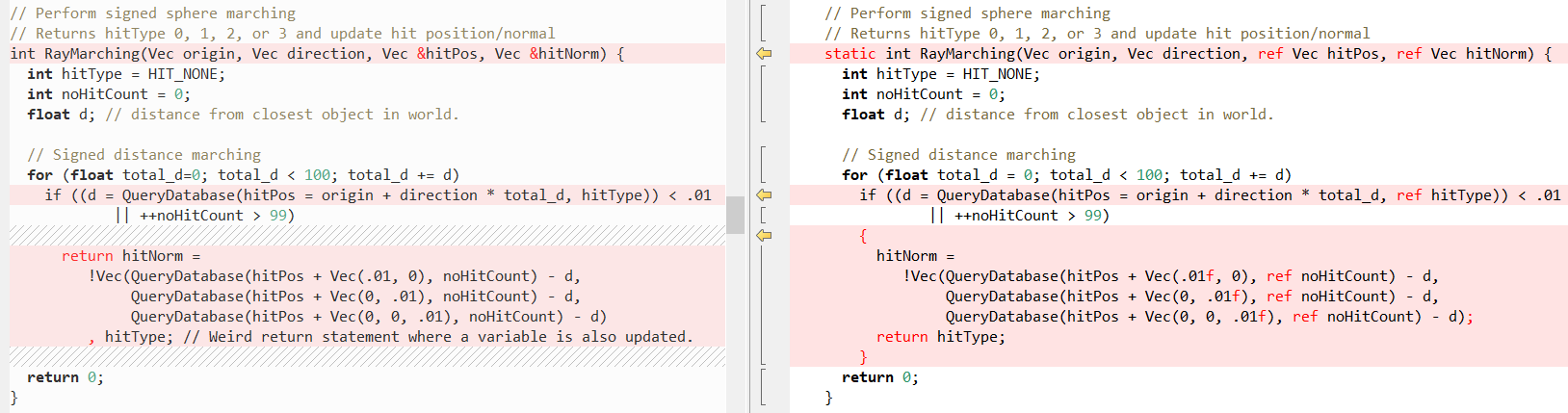
Now let's see how some other methods look like in comparison (again C ++ on the left, C # on the right), first
RayTracing(..) :Then
QueryDatabase (..) :(see Fabian’s post for an explanation of what these two functions do)
But again, the fact is that C # makes it very easy to write C ++ code! In this case, the
ref keyword helps us the most. It allows you to pass a value by reference . We have been using ref for quite some time in method calls, but recently efforts have been made to allow ref in other places:Now sometimes using
ref will improve performance, because then the structure does not need to be copied, see benchmarks in the post of Adam Stinix and “Performance traps ref locals and ref returns to C #” for more information.But the most important thing is that such a script provides our C # port with the same behavior as the C ++ source code. Although I want to note that the so-called "managed links" are not quite the same as "pointers", in particular, you cannot do arithmetic on them, for more details, see here:
Performance
Thus, the code is well ported, but performance also matters. Especially in the raytracer, which can cheat a frame a few minutes. The C ++ code contains the
sampleCount variable, which controls the final image quality, while sampleCount = 2 looks like this:Clearly not very realistic!
But when you get to
sampleCount = 2048 , everything looks much better:But running with
sampleCount = 2048 takes a lot of time, so all the other runs are performed with a value of 2 in order to keep at least a minute. Changing sampleCount affects only the number of iterations of the outermost loop of the code, see this gist for an explanation.Results after the “naive” progressive port
To meaningfully compare C ++ and C #, I used the time-windows tool, this is the port of the unix command
time . Initial results looked like this:| C ++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) | |
|---|---|---|---|
| Time (sec) | 47.40 | 80.14 | 78.02 |
| In the core (s) | 0.14 (0.3%) | 0.72 (0.9%) | 0.63 (0.8%) |
| In user space (sec) | 43.86 (92.5%) | 73.06 (91.2%) | 70.66 (90.6%) |
| Number of page fault errors | 1143 | 4818 | 5945 |
| Work Set (KB) | 4232 | 13,624 | 17,052 |
| Memory preemptive (KB) | 95 | 172 | 154 |
| Non-preemptive memory | 7 | 14 | sixteen |
| Page File (KB) | 1460 | 10,936 | 11,024 |
Initially, we see that the C # code is a bit slower than the C ++ version, but it gets better (see below).
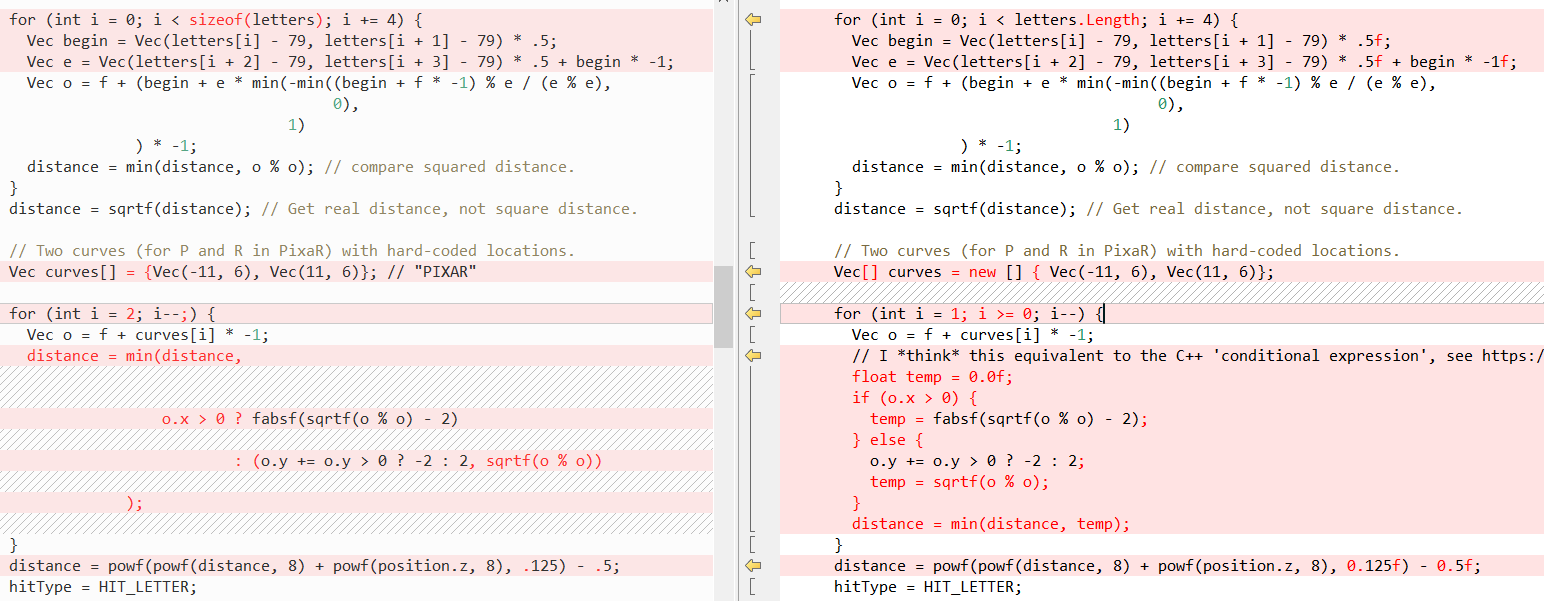
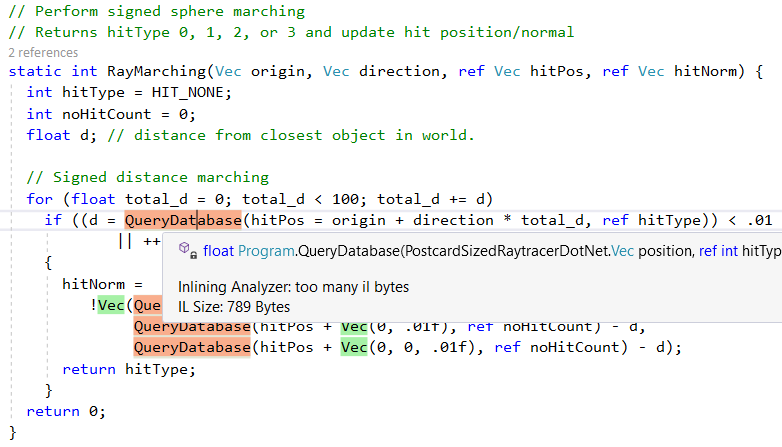
But let's first see what the .NET JIT is doing to us, even with this “naive” line-by-line port. First, it does a good job of embedding smaller “helper methods”. This is evident in the output of the magnificent tool Inlining Analyzer (green = embedded):
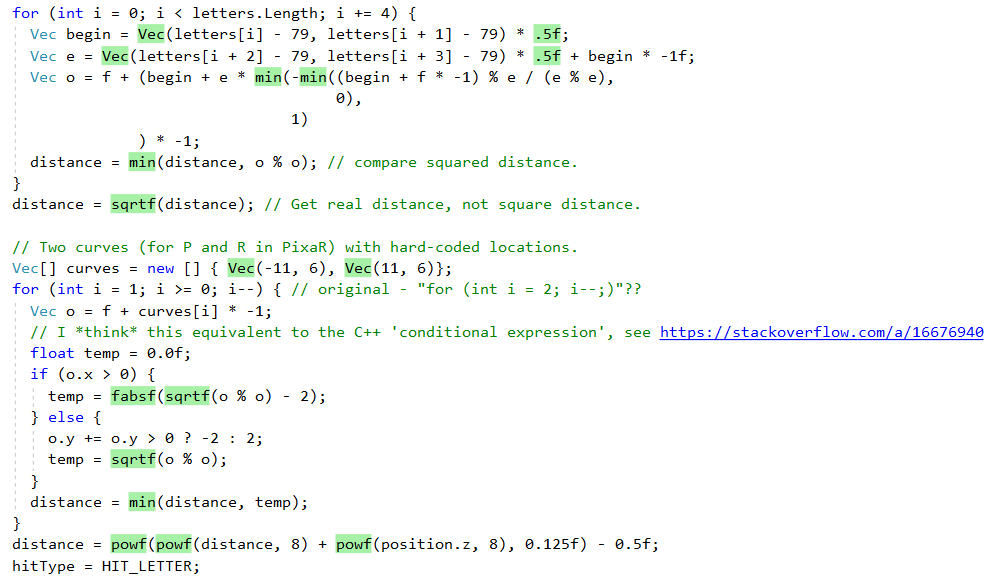
However, it does not embed all methods, for example, because of the complexity,
QueryDatabase(..) skipped:Another function of the .NET Just-In-Time (JIT) compiler is to convert certain method calls to the corresponding CPU instructions. We can see this in action with the
sqrt shell function, here is the C # source code (notice the Math.Sqrt call): // intnv square root public static Vec operator !(Vec q) { return q * (1.0f / (float)Math.Sqrt(q % q)); } And here is the assembler code that generates the .NET JIT: there is no call to
Math.Sqrt and the Math.Sqrt processor instruction is used : ; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================ (To get this issue, follow these instructions , use the Disasmo VS2019 add-in or look at SharpLab.io )
These replacements are also known as intrinsics , and in the code below we can see how JIT generates them. This snippet shows mapping for
AMD64 only, but JIT also targets X86 , ARM and ARM64 , the full method here . bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) { // AMD64/x86 has SSE2 instructions to directly compute sqrt/abs and SSE4.1 // instructions to directly compute round/ceiling/floor. // // TODO: Because the x86 backend only targets SSE for floating-point code, // it does not treat Sine, Cosine, or Round as intrinsics (JIT32 // implemented those intrinsics as x87 instructions). If this poses // a CQ problem, it may be necessary to change the implementation of // the helper calls to decrease call overhead or switch back to the // x87 instructions. This is tracked by #7097. case CORINFO_INTRINSIC_Sqrt: case CORINFO_INTRINSIC_Abs: return true; case CORINFO_INTRINSIC_Round: case CORINFO_INTRINSIC_Ceiling: case CORINFO_INTRINSIC_Floor: return compSupports(InstructionSet_SSE41); default: return false; } ... } As you can see, some methods are implemented as, for example,
Sqrt and Abs , while for others, functions of the C ++ runtime are used, for example, powf .This whole process is very well explained in the article “How is Math.Pow () implemented in the .NET Framework?” , It can also be seen in the CoreCLR source code:
- The implementation of
COMSingle::Pow, that is, the method that is executed if you callMathF.Pow(..)from C # code - Mapping in runtime method implementation C
- Cross-platform version of the implementation of powf , which provides the same behavior in different operating systems
Results after simple performance improvements.
I wonder whether it is possible to improve on the go naive line-by-line port. After some profiling, I made two major changes:
- Remove initialization of embedded array
- Replacing
Math.XXX(..)functions with analogs ofMathF.()
These changes are explained in more detail below.
Remove initialization of embedded array
For more information on why this is necessary, see this excellent answer to Stack Overflow from Andrei Akinshin , along with benchmarks and assembler code. He comes to the following conclusion:
Conclusion
- Is .NET caching hard-coded local arrays? Like those that put the Roslyn compiler in the metadata.
- In this case there will be overhead costs? Unfortunately, yes: for each JIT call, it will copy the contents of the array from the metadata, which takes extra time compared to a static array. The runtime also allocates objects and creates traffic in memory.
- Should I worry about it? Maybe. If this is a hot method and you want to achieve a good level of performance, you need to use a static array. If this is a cold method that does not affect the performance of the application, you probably need to write “good” source code and place the array in the method area.
Changes can be seen in this diff .
Using MathF Functions Instead of Math
Secondly, and most importantly, I have significantly improved performance by making the following changes:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0 // intnv square root public static Vec operator !(Vec q) { return q * (1.0f / MathF.Sqrt(q % q)); } #else public static Vec operator !(Vec q) { return q * (1.0f / (float)Math.Sqrt(q % q)); } #endif Beginning with .NET Standard 2.1, there are specific implementations of
float common math functions. They are located in the System.MathF class. For more information about this API and its implementation, see here:- New API for mathematics with single precision
- Adding math functions with single precision
- Providing a suite of unit tests for new single-precision math APIs
- System.Math and System.MathF should be implemented in managed code, not FCALL for C runtime.
- Move Math.Abs (double) and Math.Abs (float) for implementation in managed code
- Design and process for adding platform-specific embedded tools in .NET
After these changes, the difference in performance of C # and C ++ code was reduced to about 10%:
| C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON | |
|---|---|---|---|---|
| Time (sec) | 41.38 | 58,89 | 46.04 | 44.33 |
| In the core (s) | 0.05 (0.1%) | 0.06 (0.1%) | 0.14 (0.3%) | 0.13 (0.3%) |
| In user space (sec) | 41.19 (99.5%) | 58.34 (99.1%) | 44.72 (97.1%) | 44.03 (99.3%) |
| Number of page fault errors | 1119 | 4749 | 5776 | 5661 |
| Work Set (KB) | 4136 | 13,440 | 16 788 | 16 652 |
| Memory preemptive (KB) | 89 | 172 | 150 | 150 |
| Non-preemptive memory | 7 | 13 | sixteen | sixteen |
| Page File (KB) | 1428 | 10 904 | 10,960 | 11,044 |
TC - layered compilation, Tiered Compilation ( I suppose it will be enabled by default in .NET Core 3.0)
For completeness, here are the results of several runs:
| Run | C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|---|---|---|---|
| TestRun-01 | 41.38 | 58,89 | 46.04 | 44.33 |
| TestRun-02 | 41.19 | 57.65 | 46.23 | 45.96 |
| TestRun-03 | 42.17 | 62.64 | 46.22 | 48.73 |
Note : the difference between the .NET Core and the .NET Framework is due to the absence of the MathF API in the .NET Framework 4.7.2, for more information, see the .Net Framework Support Ticket (4.8?) For netstandard 2.1 .
Further increase in productivity
I am sure that the code can still be improved!
If you are interested in eliminating the performance difference, here is the C # code . For comparison, you can watch the C ++ assembler code from the excellent Compiler Explorer service.
Finally, if it helps, here’s the output of the Visual Studio profiler with the “hot path” display (after the performance improvements described above):
Is C # a low level language?
Or more specifically:
What language features of C # / F # / VB.NET or BCL / Runtime functionality mean “low level” * programming?
* Yes, I understand that “low level” is a subjective term.
Note: each C # developer has his own idea of what “low level” is, these functions will be taken for granted by C ++ or Rust programmers.
Here is the list I made:
- ref returns and ref locals
- “Transfer and return by reference to avoid copying large structures. Safe types and memory can be even faster than insecure ones! ”
- Unsafe code in .NET
- “The main language of C #, as defined in previous chapters, is very different from C and C ++ in that it lacks pointers as a data type. Instead, C # provides links and the ability to create objects that are regulated by the garbage collector. This design in combination with other functions makes C # a much more secure language than C or C ++. ”
- Managed Pointers in .NET
- “There is another type of pointer in the CLR — a managed pointer. It can be defined as a more general type of link, which may indicate other locations, and not just the beginning of the object. ”
- C # 7 Series, Part 10: Span <T> and Universal Memory Management
- “System.Span <T> is only a stack type (
ref struct) that wraps all memory access patterns; it is a type for universal continuous memory access. You can imagine a Span implementation with a dummy reference and a length that accepts all three types of memory access. ”
- “System.Span <T> is only a stack type (
- Compatibility ("C # Programming Guide")
- "The .NET Framework provides interoperability with unmanaged code through platform call services, the
System.Runtime.InteropServices, C ++ compatibility, and COM compatibility (COM interoperability)."
- "The .NET Framework provides interoperability with unmanaged code through platform call services, the
I also threw a cry on Twitter and got a lot more options for inclusion in the list:
- Ben Adams : “Embedded Platform Tools (CPU Instructions)”
- Mark Graywell : “SIMD via Vector (which goes well with Span) is * pretty * low; .NET Core should (soon?) Offer direct embedded CPUs for more explicit use of specific CPU instructions. ”
- Mark Graywell : “Powerful JIT: things like range skipping (range elision) on arrays / intervals, and using per-struct-T rules to remove large pieces of code that the JIT knows for certain that they are not available for this T or on your particular CPU (BitConverter.IsLittleEndian, Vector.IsHardwareAccelerated, etc.) »
- Kevin Jones : “I would especially mention the
MemoryMarshalandUnsafeclasses, and maybe a few other things in theSystem.Runtime.CompilerServices” - Theodoros Chatsigiannakis : "You can also include
__makerefand the rest" - damageboy : “The ability to dynamically generate a code that exactly matches the expected input, given that the latter will be known only at run time and can change periodically?”
- Robert Hacken : “Dynamic IL Emission”
- Victor Baibekov : “Stackalloc was not mentioned. It is also possible to write pure IL (not dynamic, therefore it is saved on a function call), for example, use cached
ldftnand call them viacalli. VS2017 has a proj template that makes it trivial by rewriting the extern + MethodImplOptions.ForwardRef + ilasm.exe methods. - Viktor Baibekov : “MethodImplOptions.AggressiveInlining also“ activates low-level programming ”in the sense that it allows you to write high-level code with many small methods and still control the behavior of JIT to get an optimized result. Otherwise, copy-paste hundreds of LOC-methods ... "
- Ben Adams : “Using the same calling conventions (ABI) as the base platform, and p / invokes to interact?”
- Viktor Baibekov : “Also, since you mentioned #fsharp - it has the keyword
inline, which performs work at the IL level to JIT, therefore, it was considered important at the language level. C # lacks this (still) for lambdas, which are always virtual calls, and workarounds are often strange (limited generics). ” - Alexandre Mutel : “New built-in SIMD, post-processing Unsafe Utility class / IL (for example, custom, Fody, etc.). For C # 8.0, upcoming function pointers ... "
- Alexandre Mutel : “With regard to IL, F # directly supports IL in a language, for example”
- OmariO : “ BinaryPrimitives . Low level but safe
- Kozy (Kozy) Matsui : “What about your own inline assembler? This is difficult for both the toolkit and the runtime, but it can replace the current p / invoke solution and implement embedded code, if one is available. ”
- Frank A. Kruger : “Ldobj, stobj, initobj, initblk, cpyblk”
- Konrad Kokosa : “Maybe streaming local storage? Fixed size buffers? You should probably mention uncontrollable constraints and blittable types :) ”
- Sebastiano Mandala : “Just a small addition to everything said: how about something simple, such as layout of structures and how filling and aligning memory and the order of fields can affect cache performance? This is something that I myself must explore. ”
- Nino Floris : “Constants embedded via readonlyspan, stackalloc, finalizers, WeakReference, open delegates, MethodImplOptions, MemoryBarriers, TypedReference, varargs, SIMD, Unsafe.AsRef, can set the structure types in exact match to the layout (used for TaskAwaiter and its version)”
So in the end, I would say that C # certainly allows you to write code that looks like C ++ and, in combination with the runtime and base class libraries, provides many low-level functions.
Further reading
- Templates for high performance C #. Federico Andres Lois
- Performance Quiz # 6 - Chinese-English Dictionary (since 2005, two Microsoft bloggers are leading the battle of C ++ performance against C #)
- Performance Quiz # 6 - Conclusion, Exploring Space
- How much C ++ is faster than C #?
- Optimized Managed C # and Native C ++ Code (2005)
Unity Burst Compiler:
Source: https://habr.com/ru/post/443804/
All Articles