Design classes: what is good?

Author: Denis Tsyplakov , Solution Architect, DataArt
Over the years I have found that programmers repeat the same mistakes from time to time. Unfortunately, books devoted to theoretical aspects of development do not help to avoid them: books usually lack concrete, practical advice. And I even guess why ...
')
The first recommendation that comes to mind when it comes to, for example, logging or class design, is very simple: “Do not make outright nonsense.” But experience shows that it is definitely not enough. Just the design of classes in this case is a good example - an eternal headache, arising from the fact that everyone looks at this question in his own way. That's why I decided to collect basic tips in one article, following which you will avoid a number of typical problems, and most importantly, save your colleagues from them. If some principles seem banal to you (because they are really banal!) - well, it means that they are already in your subcortex, and your team can be congratulated.
I will make a reservation, in fact, we will focus on classes solely for simplicity. Almost the same can be said about the functions or any other building blocks of the application.
If the application works and performs the task, then its design is good. Or not? Depends on the target function of the application; that which is quite suitable for a mobile application, which must be shown once at an exhibition, may not be suitable at all for a trading platform that some bank has been developing for years. To some extent, the answer to this question can be called the principle of SOLID , but it is too general - I want some more specific instructions that can be referred to in a conversation with colleagues.
Target application
Since there can be no universal answer, I suggest narrowing the scope. Let's assume that we are writing a standard business application that accepts requests via HTTP or another interface, implements some logic above them and then either makes a request to the next service in the chain, or saves the received data somewhere. For simplicity, let's assume that we use the Spring IoC Framework, since it’s quite common now and the other frameworks are pretty much like it. What can we say about this application?
- The time that the processor spends processing a single request is important, but not critical - an increase of 0.1% of the weather will not do.
- We do not have terabytes of memory, but if the application takes an extra 50–100 KB, it will not be a disaster.
- Of course, the shorter the start time, the better. But there is no fundamental difference between 6 seconds and 5.9 seconds either.
Optimization criteria
What is important for us in this case?
The project code will most likely be used by the business for several, or more than ten years.
The code at different times will be modified by several unfamiliar developers.
It is quite possible that in a few years the developers will want to use the new library LibXYZ or the framework FrABC.
At some point, part of the code or the entire project may be merged with the code base of another project.
It is generally accepted among managers that such issues are resolved through documentation. Documentation is certainly good and useful, because it’s so great when you start working on a project, you have five open tickets hanging on you, a project manager asks how you progress with it, and you need to read (and remember) some 150 pages of text written by no means brilliant writers. You, of course, had a few days or even a couple of weeks to inject into the project, but, if you use simple arithmetic, on the one hand 5,000,000 bytes of code, on the other, say, 50 business hours. It turns out that, on average, you had to inject 100 KB of code per hour. And here everything is very dependent on the quality of the code. If it is clean: easy to assemble, well structured and predictable, then an infusion into the project seems to be a noticeably less painful process. Not the last role in this is the design of classes. Far from the last.
What do we want from class design
From all of the above, you can make a lot of interesting conclusions about the overall architecture, technology stack, development process, etc. But from the very beginning we decided to talk about class design, let's see what we can learn from what was said earlier with respect to it.
- It would be desirable, that the developer, thoroughly not familiar with the application code, could, looking at a class, understand what this class does. And vice versa - looking at a functional or non-functional requirement, one could quickly guess where the classes are located in the application for which they are responsible. Well, it is desirable that the implementation of the requirements was not spread over the entire application, but was concentrated in one class or a compact group of classes. Let me explain with an example that I mean exactly the anti-pattern. Suppose we need to check that 10 requests of a certain type can only be executed by users who have more than 20 points in their account (no matter what that means). A bad way to implement such a requirement is to insert a check at the beginning of each request. Then the logic will be spread over 10 methods in different controllers. A good way is to create a filter or WebRequestInterceptor and check everything in one place.
- It would be desirable that changes in one class that do not affect the class contract do not affect, well, or (let's be realistic!) At least other classes are not even very strongly affected. In other words, I want to encapsulate the implementation of a class contract.
- It would be desirable, that at change of the contract of a class it was possible, having passed on a call chain and having made find usages, to find classes which this change affects. That is, I want classes to have no indirect dependencies.
- If possible, I would like the request processing processes consisting of several single-level steps not to be spread over the code of several classes, but described on the same level. It is quite good if the code describing such a processing process fits on one screen inside one method with a clear name. For example, we need to find all the words in a line, make a call to a third-party service for each word, get a description of the word, apply formatting to the description and save the results in the database. This is one sequence of actions from 4 steps. It is very convenient to understand the code and change its logic, when there is a method, where these steps go one after another.
- I really want the same things in the code to be implemented in the same way. For example, if we access the database directly from the controller, it is better to do this everywhere (although I would not call such a design good practice). And if we have already introduced the levels of services and repositories, it is better not to contact directly from the controller to the database.
- It would be desirable that the number of classes / interfaces that are not directly responsible for functional and non-functional requirements is not very large. Working with a project in which there are two interfaces for each class with logic, a complex inheritance hierarchy of five classes, a class factory and an abstract class factory, is quite hard.
Practical recommendations
Having formulated our wishes, we can outline concrete steps that will enable us to achieve our goals.
Static methods
As a warm-up, I'll start with a relatively simple rule. You should not create static methods except when they are needed for the operation of one of the used libraries (for example, you need to make a serializer for the data type).
In principle, there is nothing wrong with using static methods. If the behavior of a method completely depends on its parameters, why not really make it static. But we must take into account the fact that we use Spring IoC, which serves to bind the components of our application. Spring IoC uses the concepts of bins (Beans) and their areas of applicability (Scope). This approach can be mixed with static methods grouped into classes, but to understand such an application and moreover to change something in it (if, for example, you need to pass a global parameter to a method or class) can be very difficult.
At the same time, static methods in comparison with IoC-bins give a very insignificant advantage in the speed of a method call. And at this, perhaps, the benefits and end.
If you do not build a business function that requires a large number of ultra-fast calls between different classes, it is better not to use static methods.
Here the reader may ask: “But what about the StringUtils and IOUtils classes?” Indeed, there is a tradition in the Java world — to take auxiliary functions of working with strings and I / O streams into static methods and assemble SomethingUtils classes under an umbrella. But to me, such a tradition seems quite subtle. If you follow it, much harm, of course, is not expected - all Java programmers are used to it. But there is no sense in such a ritual action. On the one hand, why not make the StringUtils bean, on the other, if you do not make the bean and all the helper methods static, let's make the static umbrella classes StockTradingUtils and BlockChainUtils. Having started to make logic in static methods, it is difficult to draw a line and stop. I advise you not to start.
Finally, we should not forget that for Java 11, many auxiliary methods that have been wandering for decades from developer to project have either become part of the standard library or have been combined into libraries, for example, in Google Guava.
Atomic, compact class contract
There is a simple rule applicable to the design of any software system. Looking at any class, you should be able to quickly and compactly, without resorting to long excavations, to explain what this class is doing. If you fit the explanation in one paragraph (not necessarily, however, expressed in one sentence) does not work, it may be worthwhile to think about and break this class into several atomic classes. For example, the class “Searches for text files on a disk and counts the number of Z letters in each of them” is a good candidate for the decomposition “searches on a disk” + “counts the number of letters”.
On the other hand, you should not make too small classes, each of which is designed for one action. But how big should the class be then? The basic rules are:
- Ideally, when a class contract matches the description of a business function (or subfunctions, depending on how the requirements are arranged). This is not always possible: if an attempt to comply with this rule leads to the creation of bulky, non-obvious code, it is better to break the class into smaller parts.
- A good metric for assessing the quality of a class contract is the ratio of its internal complexity to the complexity of the contract. For example, a very good (albeit fantastic) class contract may look like this: “A class has one method that receives as input a line describing subjects in Russian and as a result it composes a qualitative story or even a story on a given topic”. Here the contract is simple and generally understandable. Its implementation is extremely complex, but the complexity is hidden inside the class.
Why is this rule important?
- First, the ability to clearly explain to oneself what each of the classes does is always useful. Unfortunately, not every project developers can do this. You can often hear something like: “Well, this is such a wrapper over the Path class, which we somehow made and sometimes use instead of Path. It still has a method that can double all File.separator on the way - we need this method when saving reports to the cloud, and for some reason it ended up in the Path class. ”
- The human brain is capable of simultaneously operating with no more than five to ten objects. Most people have no more than seven. Accordingly, if the developer needs to operate with more than seven objects to solve the problem, he will either miss something or will be forced to pack several objects under one logical umbrella. And if you still have to pack, why not do it immediately, consciously, and not give this umbrella a meaningful name and a clear contract.
How to check that you have everything quite granular? Ask a colleague to give you 5 (five) minutes. Take the part of the application you are currently working on. For each of the classes, explain to a colleague what exactly this class does. If you do not fit in 5 minutes, or a colleague can not understand why this or that class is needed - perhaps you should change something. Well, or not to change and conduct the experience again, already with another colleague.
Class dependencies
Suppose we need for PDF-file, packed in a ZIP-archive, select the associated sections of text longer than 100 bytes and save them to the database. A popular anti-pattern in such cases looks like this:
- There is a class that opens a ZIP archive, looks for a PDF file in it and returns it in the form of an InputStream.
- This class has a link to a class that searches text paragraph paragraphs in PDF.
- The class that works with PDF, in turn, has a link to the class that stores the data in the database.
On the one hand, everything looks logical: received data, directly called the next class in the chain. But at the same time, contracts and dependencies of all classes that go in the chain behind it are mixed into the class contract at the top of the chain. It is much more correct to make these classes atomic and independent of each other, and to create another class that actually implements the processing logic, connecting these three classes to each other.
How to do it is not necessary:
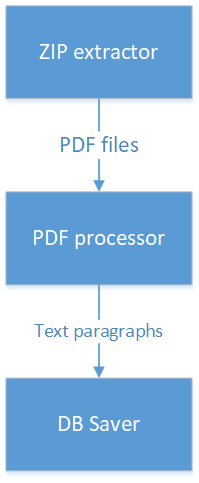
What is wrong here? A class that works with ZIP files transfers data to a class that processes PDF, and that, in turn, transfers it to a class that works with a database. So, the class that works with ZIP, as a result, for some reason depends on the classes that work with the database. In addition, the processing logic is spread over three classes, and in order to understand it, it is necessary to run over all three classes. What to do if you need text paragraphs, received from PDF, to transfer to a third-party service through a REST call? You will need to change the class that works with PDF, and pull into it and work with REST.
How to do it:
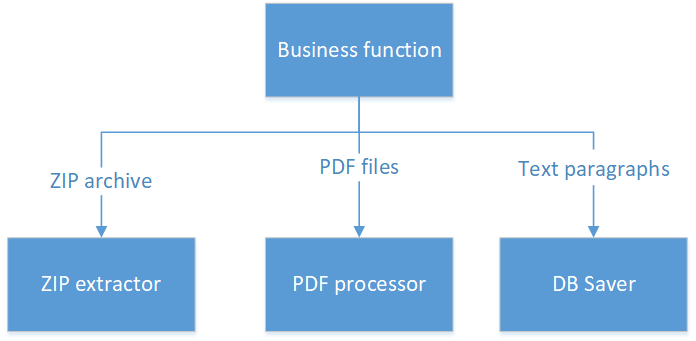
Here we have four classes:
- A class that works only with a ZIP-archive and returns a list of PDF-files (here you can argue - to return files badly - they are big and will break the application. But let's read the word “returns” in a broad sense. For example, returns Stream from the InputStream ).
- The second class is responsible for working with PDF.
- The third class does not know anything and can not, except for the preservation of paragraphs in the database.
- And the fourth class, which consists of literally several lines of code, contains all the business logic that fits on one screen.
I emphasize again, in 2019 in Java there are at least two good ones (and some less
good) ways not to transfer files and a complete list of all paragraphs as objects in memory. It:
- Java Stream API.
- Callbacks. That is, a class with a business function does not transfer data directly, but ZIP Extractor says: here's a callback for you, look for PDF files in a ZIP file, create an InputStream for each file and call the transferred callback with it.
Implicit behavior
When we are not trying to solve a completely new, previously unsolved task, but on the contrary, we are doing something that other developers have already done several hundred (or hundreds of thousands) of times, all team members have certain expectations about the cyclomatic complexity and resource intensity of the solution. . For example, if we need to find all the words beginning with the letter z in the file, this is a sequential, single-time reading of the file in blocks from the disk. That is, if you focus on https://gist.github.com/jboner/2841832 — this operation will take a few microseconds for 1 MB, well, depending on the programming environment and the system load, maybe a few dozen or even a hundred microseconds, but not a second. In memory, it will take several tens of kilobytes (we leave behind the brackets the question of what we do with the results, this is a concern of another class), and the code will most likely take about one screen. At the same time, we expect that no other resources of the system will be used. That is, the code will not create threads, write data to disk, send packets over the network and save data to the database.
This is the usual wait from the method call:
zWordFinder.findZWords(inputStream). ... If the code of your class does not meet these requirements for some reasonable reason, for example, to classify a word into z and not z, you need to call the REST method every time (I don’t know why this may be necessary, but let's imagine this), this it is necessary to prescribe very carefully in the class contract, and it’s very good if the method name indicates that the method runs somewhere to consult.
If you have no reasonable reason for implicit behavior, rewrite the class.
How to understand the expectations from the complexity and resource intensity of the method? You need to resort to one of these simple ways:
- With experience to get a wide enough outlook.
- Ask a colleague - it can always be done.
- Before starting the development, talk with the team members about the implementation plan.
- To ask myself the question: “But am I using _ too much _ in this method a lot of redundant resources?” Usually this happens enough.
You shouldn't get too carried away with optimization either - saving 100 bytes with 100,000 used by the class does not make much sense for most applications.
This rule opens us a window into the rich world of overinering, which hides answers to questions like "why you shouldn’t spend a month to save 10 bytes of memory in an application that requires 10 GB to work." But I will not develop this topic here. She deserves a separate article.
Implicit method names
In Java programming, there are currently several implicit conventions about class names and their behavior. They are not so many, but it is better not to break them. Let me try to list those that come to my mind:
- The constructor creates an instance of the class, it can create some fairly extensive data structures, but it does not work with the database, does not write to disk, does not send data over the network (I’ll make a reservation, the built-in logger can do all this, but this is a separate story in anyway it lies on the conscience of the logging configurator).
- Getter - getSomething () - returns some kind of memory structure from the depths of the object. Again, it does not write to disk, does not do complex calculations, does not send data over the network, does not work with the database (except for the case when it is a lazy ORM field, and this is just one of the reasons why lazy fields should be used with great care) .
- Setter - setSomething (Something something) - sets the value of the data structure, does not do complex calculations, does not send data over the network, does not work with the database. Usually, the setter is not expected to implicitly behave or consume any significant computational resources.
- equals () and hashcode () - nothing is expected at all except simple calculations and comparisons in a quantity that is linearly dependent on the size of the data structure. That is, if we call hashcode for an object of three primitive fields, it is expected that N * 3 simple computational instructions will be executed.
- toSomething () is also expected to be a method that converts one data type to another, and it only needs a memory amount comparable to the size of the structures and a processor time linearly dependent on the size of the structures. It should be noted here that it is not always possible to do type conversion linearly, say, converting a pixel image to an SVG format can be a very nontrivial action, but in this case it is better to call the method differently. For example, the name computeAndConvertToSVG () looks somewhat awkward, but immediately suggests that significant calculations are taking place inside.
I will give an example. I recently did an application audit. Logically, I know that the application somewhere in the code subscribes to the RabbitMQ queue. I go on the code from top to bottom - I can not find this place. I am looking for an immediate appeal to the rabbit, I begin to climb up, I reach the place in the business flow, where the subscription actually takes place - I start to swear. How it looks in code:
- The service.getQueueListener (tickerName) method is called - the returned result is ignored. This could be alarming, but such a code fragment, where the results of the method’s work are ignored, is not the only one in the application.
- Inside, the tickerName is checked for null and another getQueueListenerByName (tickerName) method is called.
- Inside it, an instance of the QueueListener class is taken from the hash by the name of the ticker (if not, it is created), and the getSubscription () method is called.
- But already inside the getSubscription () method, the subscription actually takes place. And it happens somewhere in the middle of the method with the size of three screens.
Frankly speaking, without having run through the whole chain and without reading a careful dozen of code screens, it was unrealistic to guess where the subscription was taking place. If the method were called subscribeToQueueByTicker (tickerName), it would save me a lot of time.
Utility Classes
There is an excellent book Design Patterns: Elements of Reusable Object-Oriented Software (1994), it is often called GOF (Gang of Four, by the number of authors). The benefit of this book is primarily in the fact that it gave developers from different countries a single language for describing class design patterns. Now, instead of “the class is guaranteed to exist in only one instance and has a static access point,” we can say “singleton”. The same book caused significant damage to the fragile minds. This harm is well described by a quote from one of the forums "Colleagues, I need to make a web store, tell me, with what templates should I use." In other words, some programmers tend to misuse design patterns, and where it was possible to do with one class, sometimes they create five or six at once — just in case, “for greater flexibility.”
How to decide whether you need an abstract class factory (or another pattern is more complicated than the interface) or not? There are a few simple considerations:
- If you are writing an application to Spring, in 99% of cases it is not needed. Spring offers you higher-level building blocks, use them. The most that can be useful to you is an abstract class.
- If point 1 still did not give you a clear answer - remember that each template is +1000 points to the complexity of the application. Carefully consider whether the benefits of using the template outweigh the harm from it. Referring to the metaphor, remember, each medicine not only heals, but also harms a little. Do not drink all the pills at once.
A good example of how not to do, you can see here .
Conclusion
Summing up, I want to note that I listed the most basic recommendations. I would not make them in the form of an article at all - they are so obvious. But over the past year I have too often come across applications in which many of these recommendations were violated. Let's write simple code that is easy to read and easy to maintain.
Source: https://habr.com/ru/post/443756/
All Articles