Neural networks have a surprisingly simple image classification strategy.
Convolutional neural networks do an excellent job with the classification of distorted images, unlike people

In this article, I will show why advanced deep neural networks can perfectly recognize distorted images and how it helps to uncover the surprisingly simple strategy used by neural networks to classify natural photos. These discoveries, published in ICLR 2019, have many implications: first, they demonstrate that it is much easier to find an “ ImageNet ” solution than was thought. Secondly, they help us create more interpretable and understandable systems for classifying images. Third, they explain several phenomena observed in modern convolutional neural networks (SNA), for example, their tendency to search for textures (see our other work in ICLR 2019 and the corresponding blog entry ) and ignoring the spatial arrangement of parts of an object.
Good old models "bag of words"
In the good old days, before the emergence of deep learning, the recognition of natural images was quite simple: we define a set of key visual features (“words”), determine how often each visual feature is found in an image (“bag”), and classify an image based on these numbers Therefore, such models in computer vision are called “bag of words” (bag-of-words or BoW). For example, suppose that we have two visual features, the human eye and the pen, and we want to classify images into two classes, “people” and “birds”. The simplest BoW model would be this: for each eye found on the image, we increase the evidence in favor of the “person” by 1. Conversely, for each feather, we increase the evidence in favor of the “bird” by 1. Which class is gaining more evidence, so it will be.
A convenient feature of such a simple BoW model is the interpretability and clarity of the decision-making process: we can definitely check which features of the image speak in favor of a particular class, the spatial integration of features is very simple (compared to the nonlinear integration of features in deep neural networks) just understand how the model makes its decisions.
')
Traditional BoW models were extremely popular and worked well before the onslaught of deep learning, but quickly went out of fashion due to their relatively low efficiency. But are we sure that neural networks use a fundamentally different decision-making strategy from BoW?
Depth Interpretable Network with Features Bag (BagNet)
To test this assumption, let us combine the interpretability and clarity of BoW models with the effectiveness of neural networks. The strategy looks like this:
- Divide the image into small pieces qx q.
- We skip the pieces through the neural network to get evidence of class membership (logits) for each piece.
- We summarize the evidence for all the pieces to obtain a solution at the level of the entire image.
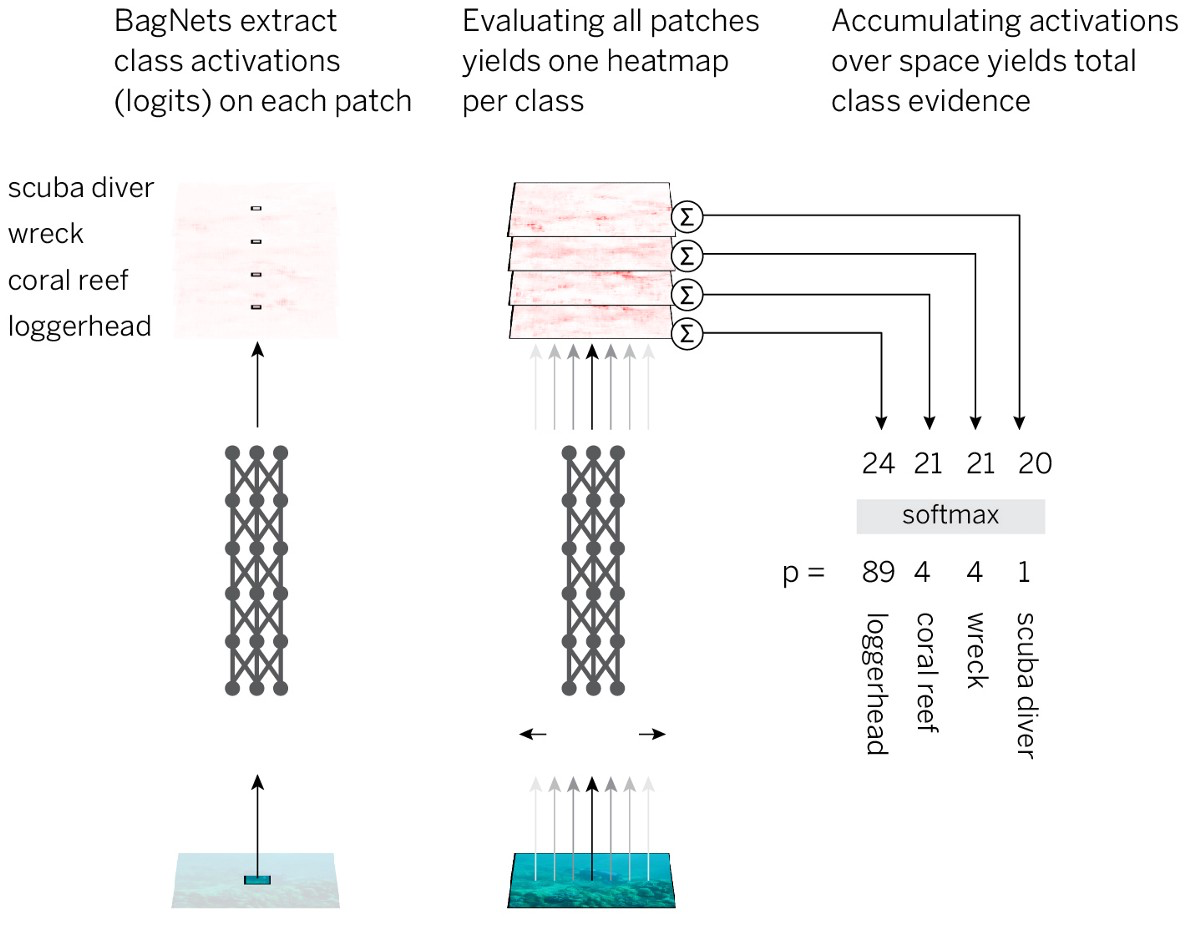
To implement such a strategy in the simplest way, we take the standard ResNet-50 architecture and replace almost all 3x3 convolutions with 1x1 convolutions. As a result, each hidden element in the last convolutional layer “sees” only a small part of the picture (that is, their field of perception is much smaller than the size of the image). So we avoid the imposed markup of the image and come as close as possible to the standard SNA, while applying a pre-planned strategy. We call the resulting BagNet-q architecture, where q denotes the size of the perceptual field of the uppermost layer (we tested the model with q = 9, 17, and 33). BagNet-q works about 2.5 longer than ResNet-50.
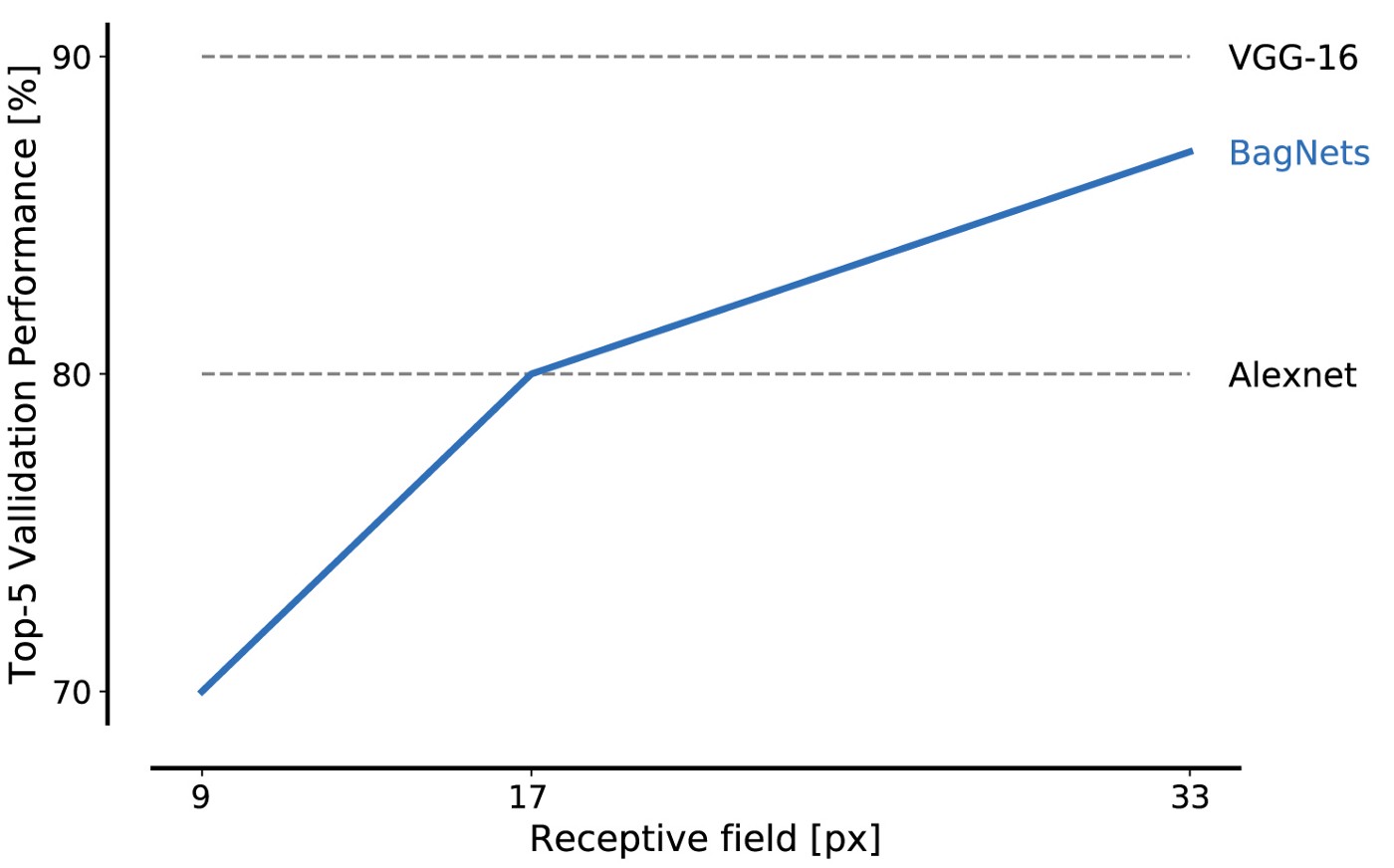
The efficiency of BagNet on the data from the ImageNet database is impressive even when using small pieces: 17 × 17 pixels are enough to reach the efficiency of AlexNet, and 33 × 33 pixels are enough to reach 87% accuracy by entering top-5. Efficiency can be increased by placing the 3x3 convolutions more carefully and adjusting the hyperparameters.
This is our first main result: ImageNet can be solved using only a set of small features of images. Distant spatial relationships of parts of a composition, such as the shape of objects or the interaction between parts of an object, can be completely ignored; they are completely unnecessary to solve the problem.
BagNet's remarkable feature is the transparency of their decision making system. For example, you can find out what features of the images will be the most characteristic for a given class. For example, tench, a large fish, is usually recognized by the image of fingers on a green background. Why? Because most of the photos in this category are fisherman, holding a tench as his trophy. And when BagNet incorrectly recognizes the image as a line, it usually happens because somewhere in the photo there are fingers on a green background.

The most characteristic parts of the images. The top row in each cell corresponds to the correct recognition, and the bottom one - to distracting fragments that led to incorrect recognition.
We also get an accurate “heat map” that shows which parts of the image contributed to the decision.

Heat maps are not approximations, they accurately show the contribution of each part of the image.
BagNet's demonstrate that it is possible to obtain high accuracy of working with ImageNet only on the basis of weak statistical correlations between local features of images and the category of objects. If this is enough, then why would standard neural networks like ResNet-50 explore something fundamentally different? Why would ResNet-50 study complex large-scale relationships of the type of object's shape, if the abundance of local image features is enough to solve the problem?
To test the hypothesis that modern SNS adhere to a strategy similar to the work of the simplest BoW networks, we tested different networks — ResNet, DenseNet, and VGG on the following “signs” of BagNet:
- The solutions are independent of the spatial shuffling of the image features (this can only be verified on VGG models).
- Modifications of different parts of the image should not depend on each other (in the sense of their influence on class membership).
- Errors made by standard SNS and BagNet should be similar.
- Standard SNA and BagNet should be sensitive to similar features.
In all four experiments, we found a surprisingly similar behavior of the SNS and BagNet. For example, in the last experiment, we show that BagNet is most sensitive (if they, for example, overlap) to the same image locations as the SNS. In fact, heat maps (spatial sensitivity maps) of BagNet better predict the sensitivity of DenseNet-169 than heat maps obtained by such attribution methods like DeepLift (counting heat maps for DenseNet-169 directly). Of course, the SNA does not exactly repeat the behavior of BagNet, but some deviations demonstrate. In particular, the deeper the networks become, the larger the dimensions of the features become and the further the dependencies extend. Therefore, deep neural networks are indeed an improvement compared to BagNet models, but I do not think that the basis of their classification is somehow changing.
We go beyond the classification of BoW
Observing the decision making of the SNA in the style of BoW strategies can explain some of the strange features of the SNA. First, it explains why the SNS is so strongly tied to textures . Secondly, why the SNS is not sensitive to the mixing of parts of the image. This may even explain the existence of competitive stickers and competitive perturbations: confusing signals can be placed anywhere in the image, and the SNS will still certainly catch this signal, regardless of whether it fits the rest of the image.
In fact, our work shows that when recognizing images, the SNA use a lot of weak statistical laws and do not go on to integrate parts of the image at the object level, as people do. The same is likely true for other tasks and sensory modalities.
We need to carefully plan our architectures, tasks, and training methods to overcome the tendency to use weak statistical correlations. One approach is to translate the distortion of SNA learning from small local features to more global ones. The other is to remove or replace those features that the neural network should not rely on, which we did in another publication for ICLR 2019, using style transfer preprocessing to eliminate the texture of the natural object.
One of the biggest problems, however, remains the classification of images: if there are enough local features, there is no incentive to study the real "physics" of the natural world. We need to restructure the task so as to encourage the models to study the physical nature of objects. To do this, you will most likely have to go beyond purely observational learning to the correlation of input and output data so that models can extract cause-and-effect relationships.
Together, our results suggest that the SNS can follow an extremely simple classification strategy. The fact that such a discovery can be made in 2019 emphasizes how little we still understand the internal features of the work of the deep neural networks. Lack of understanding does not allow us to develop fundamentally improved models and architectures that reduce the gap between human and machine perception. Deepening understanding will allow us to discover ways to narrow this gap. This can be extremely useful: trying to move the SNA towards the physical properties of objects, we suddenly achieved resistance to the noise of the human level. I look forward to the emergence of a large number of other interesting results on our way to the development of the SNA, truly comprehending the physical and causal nature of our world.
Source: https://habr.com/ru/post/443734/
All Articles