Code readability

The code creates interfaces. But the code itself is an interface.
Although the readability of the code is very important, the concept is poorly defined - and often in the form of a simple set of rules: use meaningful variable names, break large functions into smaller ones, use standard design patterns.
At the same time, everyone probably had to deal with a code that complies with these rules, but for some reason represents some kind of mess.
')
You can try to solve this problem by adding new rules: if the variable names become very long, you need to refactor the main logic; if in one class a lot of auxiliary methods have accumulated, it may be necessary to divide it into two; You cannot use design patterns in an inappropriate context.
Such instructions turn into a labyrinth of subjective decisions, and in order to navigate it, you will need a developer who can make the right choice — that is, he should already be able to write readable code.
Thus, a set of instructions is not an option. Therefore, we will have to form a broader view of the readability of the code.
What is readability for?
In practice, good readability usually means that the code is pleasant to read. However, such a definition does not go far: firstly, it is subjective, secondly, it binds us to reading plain text.
An unreadable code is perceived as a novel that pretends to be a code: a lot of comments revealing the essence of what is happening, sheets of text that need to be read sequentially, clever wording, the only meaning of which is to be “smart”, fear of re-use of words. The developer tries to make the code readable, but targets the wrong type of reader.
The readability of the text and the readability of the code are not the same.
Transferred to Alconost
The code creates interfaces. But the code itself is an interface.
If the code looks beautiful, does it mean that it is readable? Aesthetics - a pleasant side effect of readability, but as a criterion is not very useful. Perhaps, in extreme cases, the aesthetics of the code in the project will help to retain employees - but with the same success you can offer a good social package. In addition, everyone has their own idea of what “beautiful code” means. And over time, this definition of readability turns into a maelstrom of controversy about tabulation, spaces, brackets, camel notation, etc. It is unlikely that someone will lose consciousness after seeing the wrong indents, although this attracts attention during code checking.
If the code gives fewer errors, can we consider it more readable? The fewer mistakes, the better, but what is the mechanism here? How do you attribute the vague pleasant sensations that you experience when you see a readable code? In addition, no matter how frowning when reading the code, it will not add errors.
If the code is easy to edit, is it readable? But this is probably the right direction of thought. Requirements change, functions are added, errors occur - and at some point someone has to edit your code. And in order not to create new problems, the developer needs to understand what he is editing and how changes will change the behavior of the code. So, we have found a new heuristic rule: a readable code should be easily edited.
Which code is easier to edit?
Immediately I want to blurt out: "The code is easier to edit when the names of variables are given meaningfully," but in this way we will simply rename "readability" to "ease of editing." We need a deeper understanding, not the same set of rules in a different guise.
Let's start by forgetting for a moment that this is about code. Programming, which is several decades old, is only a point on the scale of human history. Having limited ourselves to this “point”, we will not be able to dig deeply.
Therefore, we will look at readability through the prism of interface design, which we encounter at almost every step - and not only with digital ones. The toy has the functionality that makes it ride or squeak. The door has an interface that allows you to open, close and lock it. The data in the book is collected in pages, which provides faster random access than scrolling. Studying design, you can learn much more about these interfaces - ask the design team if there is such an opportunity. In the general case, we all prefer good interfaces, even if we do not always know what makes them good.
The code creates interfaces. But the code itself, in combination with the IDE, is an interface. Interface designed for a very small group of users - our colleagues. Further we will call them “users” - to remain in the user interface design space.
With this in mind, consider the following examples of user paths:
- The user wants to add a new feature. To do this, you need to find the right place and add a function without generating new errors.
- The user wants to correct the error. He will need to find the source of the problem and edit the code so that the error disappears and no new errors appear.
- The user wants to make sure that in boundary cases the code behaves in a certain way. He will need to find a certain piece of code, then follow the logic and model what will happen.
And so on: most paths follow a similar pattern. In order not to complicate matters, let us consider specific examples - but do not forget that this is about finding common principles, and not drawing up a list of rules.
You can confidently assume that the user will not be able to immediately open the desired piece of code. This also applies to your own hobby projects: even if a function is written by you, it is very easy to forget where it is. Therefore, the code must be such that it is easy to find the right one.
To implement a convenient search, you need some search engine optimization - it’s here that we come to the rescue meaningful names of variables. If the user cannot find the function by moving through the call stack from a known point, he can start a search for keywords. However, you cannot include too many keywords in the names. When searching by code, the only entry point is searched for, from where you can continue working. Therefore, the user needs to help get to a specific place, and if you overdo it with keywords, there will be too many useless search results.
If the user has the opportunity to immediately verify that at a particular level of logic, everything is correct, he can forget the previous layers of abstraction and free the mind for the next.
You can also search using autocompletion: if you have a general idea of what function you need to call or which enumeration to use, you can start typing the suggested name and then choose the appropriate option from the autocompletion list. If the function is intended only for certain cases or you need to carefully read into its implementation due to the peculiarities of its use, you can indicate this by giving a more authentic name: by scrolling the auto-completion list, the user will rather avoid what looks difficult - if, of course, he is not sure , what is he doing.
Therefore, short normal names are more likely to be perceived as default options suitable for “random” users. There should be no surprises in functions with such names: you cannot insert setters into functions that look like simple getters - for the same reason that the “View” button in the interface should not change user data.

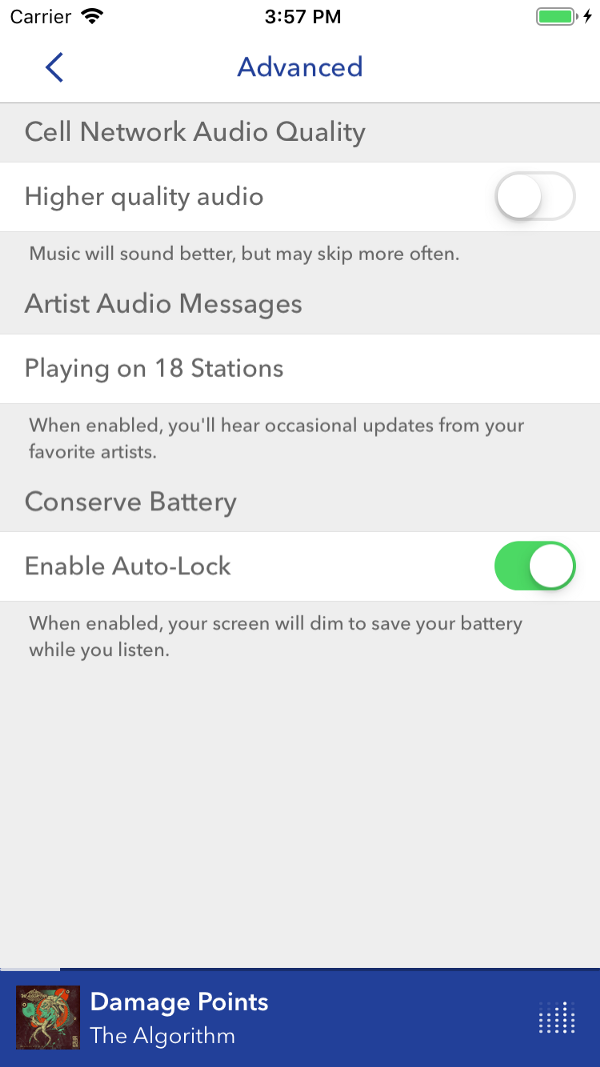
In the interface facing the client, familiar functions, such as a pause, are almost without text. As the functionality becomes more complex, the names are lengthened, which makes users slow down and think. Screenshot - Pandora
Users want to find the right information quickly. In most cases, compilation takes considerable time, and in the running application you will have to manually check many different borderline cases. Whenever possible, our users will prefer to read the code and understand how it behaves, rather than setting breakpoints and running the code.
To do without running the code, two conditions must be met:
- The user understands what the code is trying to do.
- The user is sure that the code does what it says.
Satisfying the first condition helps abstraction: users should be able to dive into the layers of abstraction to the desired level of detail. Imagine a hierarchical user interface: at the first levels, navigation is carried out through extensive sections, and then it is becoming more and more concrete — up to the level of logic that needs to be studied in more detail.
Sequential reading of a file or method is performed in linear time. But if the user can move up and down the call stacks, this is already a search through the tree, and if the hierarchy is well balanced, this action is performed in logarithmic time. Certainly, there is a place in interfaces, but it should be carefully considered whether there should be more than two or three method calls in some context.
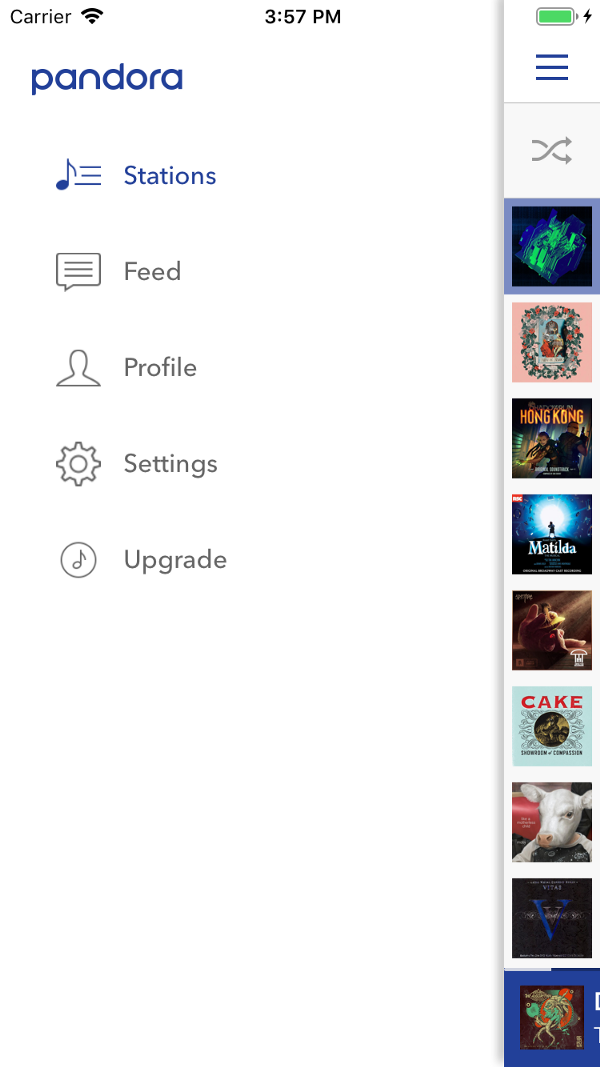

On short menus, hierarchical navigation is much faster. In the "long" menu on the right - only 11 lines. How often in the code of methods do we fit into this number? Screenshot - Pandora
The strategies for the second condition are different for different users. In low risk situations, sufficient evidence will be comments or method names. In more risky, complex areas, as well as when the code is overloaded with irrelevant comments, the latter will most likely be ignored. Sometimes even the names of methods and variables will be in doubt. In such cases, the user must read a lot more code and keep in mind a more extensive model of logic. It also helps to limit the context of small areas that are easy to keep attention. If the user has the opportunity to immediately verify that at a particular level of logic, everything is correct, he can forget the previous layers of abstraction and free the mind for the next.
In this mode of operation, individual tokens begin to have a greater meaning. For example, boolean flag
element.visible = true/false it is easy to understand in isolation from the rest of the code, but for this you need to combine two different lexemes in your mind. If you use
element.visibility = .visible/.hidden then the value of the flag can be understood on the fly: in this case, it is not necessary to read the variable name to find out that it is relevant to visibility. ¹ We saw similar approaches in designing customer-oriented interfaces. Over the past decades, the “OK” and “Cancel” actions confirm buttons have become more descriptive interface elements: “Save” and “Cancel”, “Send” and “Continue editing”, etc., in order to understand what will be done, it is enough for the user to look at the proposed options without reading the entire context completely.
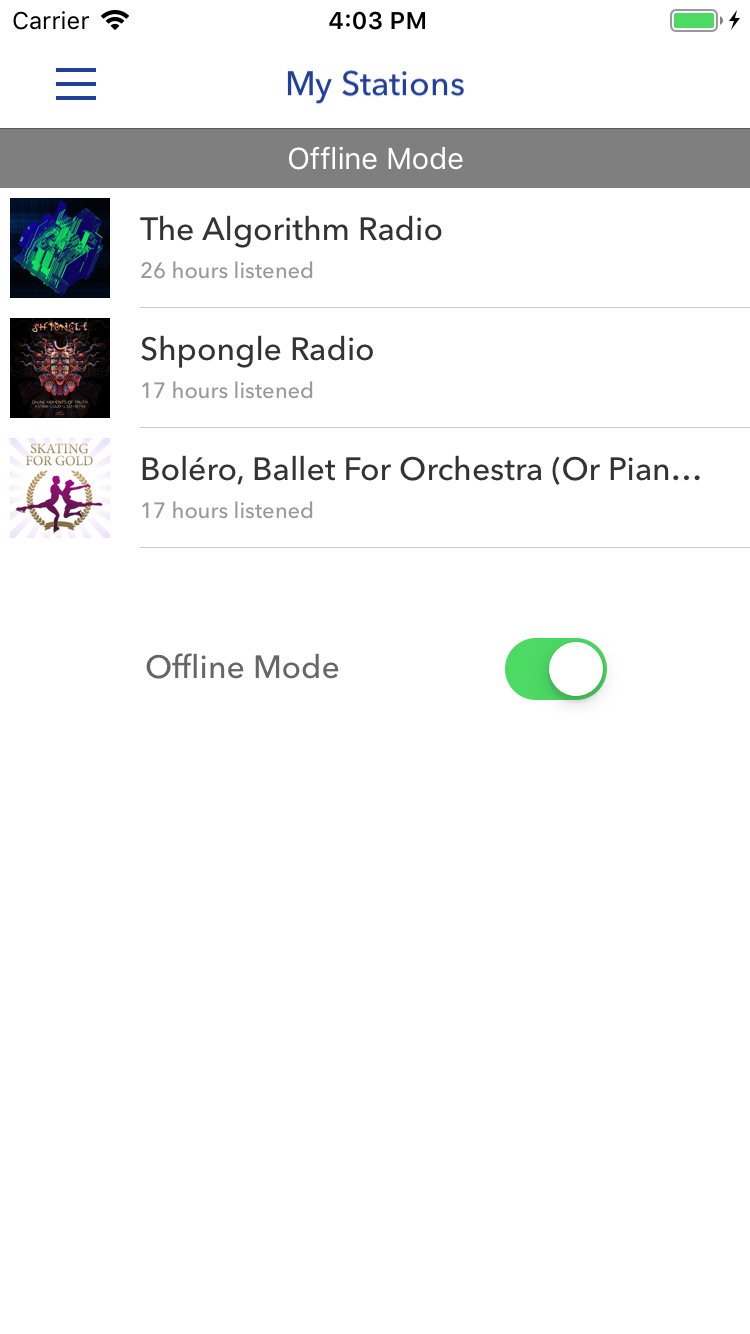
The string “Offline Mode” in the example above indicates that the application is offline. The switch in the example below has the same meaning, but to understand it, you need to look at the context. Screenshot - Pandora
The unit tests also help confirm the expected behavior of the code: they act as comments — which, however, can be trusted to a greater degree, since they are better kept up to date. True, for them, too, need to perform an assembly. But in the case of a well-established CI pipeline, tests are run regularly, so if you make changes to the existing code, you can skip this step.
In theory, security follows from a sufficient understanding: as soon as our user understands the behavior of the code, he can safely make edits. In practice, we have to take into account that developers are ordinary people: our brain uses the same tricks and is also lazy. Therefore, the less power you need to spend on understanding the code, the safer our actions.
The readable code should pass most checks on errors to the computer. One way to accomplish this is assert debugging checks, however, they also require assembly and running. Worse, if the user has forgotten the borderline cases, “assert” will not help. Unit tests with frequently forgotten borderline cases can do better, but as soon as the user makes a change, they will have to wait for the tests to run.
Summarizing: the readable code should be easy to use. And - as a side effect - it can look beautiful.
To speed up the development cycle, we use the error checking function built into the compiler. Usually for such cases full assembly is not required, and errors are displayed in real time. How to take advantage of this opportunity? Generally speaking, you need to find situations where compiler checks become very strict. For example, most compilers do not look at how exhaustively the “if” statement is described, but carefully check the “switch” for missing conditions. If a user tries to add or change a condition, it will be safer if all previous similar operators were exhaustive. And at the moment of changing the “case” condition, the compiler will mark all other conditions that need to be checked.
Another common readability issue is the use of primitives in conditional expressions. This problem is especially acute when the application analyzes JSON, because you really want to put “if” statements around a string or integer equality. This not only increases the likelihood of typos, but also complicates users with the task of determining possible values. When checking border cases, there is a big difference between when any string is possible and when there are only two or three separate options. Even if the primitives are fixed in constants, it is necessary to hurry once, trying to finish the project on time, and an arbitrary value will appear. But if you use specially created objects or enums, the compiler blocks invalid arguments and gives a specific list of valid ones.
Similarly, if some combinations of Boolean flags are not allowed, you should replace them with one enumeration. Take, for example, a composition that may be in the following states: buffered, loaded completely, and played. If you present the loading and playback states as two boolean flags
(loaded, playing) the compiler will allow input of invalid values
(loaded: false, playing: true) And if you use an enumeration
(.buffering/.loaded/.playing) this invalid state will be impossible to specify. In a client-centric default interface, there should be a ban on invalid combinations of settings. But when we write code inside the application, we often forget to ensure the same protection for ourselves.
Invalid combinations are disabled in advance; users do not need to think about which configurations are incompatible. Screenshot - Apple
Following the considered user paths, we came to the same rules as in the beginning. But now we have a principle according to which they can be formulated independently and modified according to the situation. For this we ask ourselves:
- Will it be easy for the user to search for the desired piece of code? Wouldn't the search results be cluttered with functions unrelated to the query?
- Will the user, having found the necessary code, quickly verify the correctness of his behavior?
- Does the development environment provide safe code editing and reuse?
Summarizing: the readable code should be easy to use. And - as a side effect - it can look beautiful.
Note
- It may seem that boolean variables are more convenient to reuse, but this possibility of reuse implies interchangeability. Take, for example, the tappable and cached flags , which represent concepts located in completely different planes: the ability to click on an item and the caching state. But if both flags are Boolean, they can be randomly interchanged, having received a non-trivial expression on one line of code, which will mean that caching is associated with the possibility of clicking on an element. When using enumerations, we will be forced to create explicit, verifiable transformation logic of the “units of measure” we use to form such relationships.
About the translator
The article is translated in Alconost.
Alconost is engaged in the localization of games , applications and websites in 70 languages. Language translators, linguistic testing, cloud platform with API, continuous localization, 24/7 project managers, any formats of string resources.
We also make advertising and training videos - for websites selling, image, advertising, training, teasers, expliners, trailers for Google Play and the App Store.
→ Read more
Source: https://habr.com/ru/post/443678/
All Articles