Our dependency problem
For decades, software reuse has been more often discussed than actually happened. Today, the situation is reversed: developers reuse other people's programs every day, in the form of program dependencies, while the problem itself remains virtually unexplored.
My own experience includes a decade of working with the Google internal repository , where dependencies are set as a priority concept, and also developing dependencies for the Go programming language .
Dependencies carry serious risks that are too often overlooked. The transition to the simple reuse of the smallest pieces of software happened so quickly that we have not yet developed best practices for effectively choosing and using dependencies. Even for deciding when they are relevant, and when not. The purpose of this article is to assess the risks and stimulate the search for solutions in this area.
In modern development, dependency is an additional code that is called from a program. Adding a dependency avoids repeating work already done: designing, writing, testing, debugging, and maintaining a specific unit of code. Let's call this code unit a package , although in some systems other terms are used instead of a package, such as a library or module.
')
Accepting external dependencies is an old practice: most programmers download and install the necessary library, be it PCRE or zlib from C, Boost or Qt from C ++, JodaTime or Junit from Java. These packages contain high-quality debugged code, which requires considerable experience to create. If a program needs the functionality of such a package, it is much easier to manually download, install, and update a package than to develop this functionality from scratch. But large upfront costs mean that manual reuse is expensive: it’s easier to write tiny packages yourself.
A dependency manager (sometimes called a package manager) automates the download and installation of dependency packages. Because dependency managers simplify the loading and installation of individual packages, reducing fixed costs makes small packages economical to publish and reuse.
For example, a Node.js dependency manager called NPM provides access to more than 750,000 packages. One of them,
Before the advent of dependency managers, it was impossible to present an eight-line library publication: too much overhead and too little benefit. But NPM reduced the overhead to almost zero, with the result that almost trivial functionality can be packaged and reused. At the end of January 2019, the
Now, dependency managers have appeared for almost every programming language. Maven Central (Java), Nuget (.NET), Packagist (PHP), PyPI (Python) and RubyGems (Ruby) - each contains more than 100,000 packages. The emergence of such widespread reuse of small packages is one of the biggest changes in software development over the past two decades. And if we are not more careful, this will lead to serious problems.
In the context of this discussion, a package is a code downloaded from the Internet. Adding dependencies entrusts the work of developing this code — designing, writing, testing, debugging, and support — to someone else on the Internet whom you usually don't know. Using this code, you expose your own program to the effects of all failures and dependencies. The execution of your software now literally depends on the code of a stranger from the Internet. If formulated in this way, it all sounds very insecure. Why would anyone even agree to this?
We agree, because it is easy, because everything seems to work, because everyone else does this, and most importantly, because it seems to be a natural continuation of a long-standing established practice. But there is an important difference that we ignore.
Decades ago, most developers also trusted others to write programs that they depended on, such as operating systems and compilers. This software was bought from well-known sources, often with some kind of support agreement. There is still room for mistakes or outright sabotage . But at least we knew who we were dealing with and, as a rule, could use commercial or legal measures.
The open source software phenomenon, which is distributed free of charge via the Internet, has largely supplanted the old software procurement practices. When reuse was still difficult, few projects introduced such dependencies. Although their licenses usually refused any “guarantees of commercial value and suitability for a specific purpose,” the projects built themselves a good reputation. Users have largely taken this reputation into account when making their decisions. Reputational support came instead of commercial and legal measures. Many common packages of that era still enjoy a good reputation: for example, BLAS (published 1979), Netlib (1987), libjpeg (1991), LAPACK (1992), HP STL (1994) and zlib (1995).
Package managers have reduced the code reuse model to the utmost simplicity: developers can now share the code up to individual functions in dozens of lines. This is a great technical achievement. There are countless packages available, and the project may include a large number of packages, but commercial, legal, or reputational mechanisms for relying on code are a thing of the past. We trust more code, although there are fewer reasons for trust.
The cost of making a bad addiction can be viewed as the sum of all possible bad outcomes on a series of the price of each bad outcome multiplied by its probability (risk).
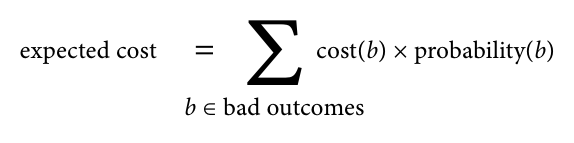
The price of a bad outcome depends on the context in which the dependency is used. At one end of the spectrum is a personal hobby project, where the price of most bad outcomes is close to zero: you just have fun, mistakes have no real impact, except for a little more time spent, and debugging them can even be fun. Thus, the probability of risk is almost irrelevant: it is multiplied by zero. At the other end of the spectrum is production software that should be supported for years. Here, the cost of dependency can be very high: servers can fall, confidential data can be disclosed, customers can suffer, companies can go bankrupt. In production, it is much more important to evaluate and minimize the risk of serious failure.
Regardless of the expected price, there are some approaches for assessing and reducing the risk of adding dependencies. It is likely that package managers should be optimized to reduce these risks, while they have so far focused on reducing the cost of loading and installation.
You would not have hired a developer about whom you have never heard and know nothing. First you will learn something about him: check the links, have an interview and so on. Before you depend on the package that you found on the Internet, it is also wise to know a little about this package.
A basic check can give an idea of the likelihood of problems when trying to use this code. If the check reveals minor problems, you can take steps to eliminate them. If the check reveals serious problems, it may be better not to use the package: you may find a more suitable one, or you may need to develop it yourself. Remember that open source packages are published by the authors in the hope that they will be useful, but with no guarantee of usability or support. If you fail in production, you will have to debug it. As the first GNU General Public License warned, “the entire risk associated with the quality and performance of a program lies with you. If the program turns out to be defective, you bear the cost of all the necessary maintenance, repair or correction. ”
Here are some considerations for checking the package and deciding whether to depend on it.
Is the package documentation clear? Does the API have a clear design? If the authors can well explain the API and design to the person, then this increases the likelihood that they also explained the implementation of the computer to the source code well. Writing code for a clear, well-thought-out API is simpler, faster, and probably less error prone. Did the authors document what they expected from the client code, for compatibility with future updates? (Examples include C ++ and Go compatibility documents).
Is the code well written? Read some snippets. Do authors seem to be cautious, conscientious, and consistent? Does it look like the code you want to debug? You may have to do this.
Develop your own systematic ways to verify code quality. Something simple, such as compiling in C or C ++ with important compiler warnings included (for example,
Keep in mind development methods you may not be familiar with. For example, the SQLite library comes as one file with 200,000 code and a header of 11,000 lines - as a result of merging multiple files. The very size of these files immediately raises a red flag, but a more thorough study will lead to the actual source code of development: the traditional file tree with more than a hundred C source files, tests and support scripts. It turns out that the single-file distribution is built automatically from the original source code: this is easier for end users, especially those who do not have dependency managers. (Compiled code also works faster because the compiler sees more optimization options).
Are there any tests in the code? Can you manage them? Do they pass? The tests establish that the basic functionality of the code is correct, and signal that the developer is seriously trying to keep it. For example, the SQLite development tree contains an incredibly detailed test suite with over 30,000 individual test cases. There is documentation for developers explaining the testing strategy. On the other hand, if there are few or no tests, or if the tests fail, this is a serious red flag: future changes in the package are likely to lead to regressions that could be easily detected. If you insist on tests in your code (right?), You must provide tests for code that you pass on to others.
Assuming that tests exist, run and pass, you can gather additional information by running tools to analyze code coverage, detect race conditions , check memory allocation and detect memory leaks.
Find the bug tracker of this package. Are there many open error messages? How long have they been open? How many bugs fixed? Are there any bugs fixed recently? If there are a lot of open questions about real bugs, especially not closed for a long time, this is a bad sign. On the other hand, if errors are rarely met and quickly corrected, that's great.
Look at the commit history. How long is the code actively maintained? Now he is actively supported? Packages that have been actively maintained for a long period of time are likely to continue to be supported. How many people work on the package? Many packages are personal projects that developers create for entertainment in their free time. Others - the result of thousands of hours of work of a group of paid developers. In general, packages of the second type usually fix errors faster, consistently implement new functions and, in general, they are better supported.
On the other hand, some code is really "perfect." For example, the
How many packages depend on this code? Package managers often give such statistics, or you can see on the Internet how often other developers mention this package. A greater number of users means at least that for many the code works quite well, and errors in it will be noticed more quickly. Extensive use is also a partial guarantee of continued service: if a widely used package loses the maintainer, then it is very likely that the interested user will assume its role.
For example, libraries like PCRE, Boost, or JUnit are incredibly widely used. This makes it more likely — although, of course, it does not guarantee — that errors that you may have encountered have already been corrected, because others have encountered them before you.
Will this package work with unsafe input? If so, how resistant is it to malicious data? Does it have bugs that are mentioned in the National Vulnerability Database (NVD) ?
For example, when in 2006 Jeff and Dean and I began working on Google Code Search (
Is the code licensed correctly? Does he even have a license? Is a license acceptable for your project or company? An amazing part of the projects on GitHub do not have a clear license. Your project or company may impose additional restrictions on license dependencies. For example, Google prohibits the use of code under licenses such as AGPL (too hard) and WTFPL (too vague).
Does this package have its own dependencies? The disadvantages of indirect dependencies are just as harmful as the disadvantages of direct dependencies. Package managers can list all the transitive dependencies of a given package, and each of them should ideally be checked as described in this section. A package with many dependencies will require a lot of work.
Many developers have never looked at the full list of transitive dependencies of their code and do not know what they depend on. For example, in March 2016, the NPM user community discovered that many popular projects — including Babel, Ember, and React — are indirectly dependent on a tiny package called the
The verification process should include running your own package tests. If the package passed the test and you decide to make your project dependent on it, the next step should be to write new tests that focus on the functionality of your particular application. These tests often start as short stand-alone programs to make sure that you can understand the package API and that it does what you think (if you cannot understand or it doesn’t do it, stop immediately!). Then it is worth making an extra effort to turn these programs into automated tests that will run with new versions of the package. If you find a bug and you have a potential fix, you can easily restart these tests for a specific project and make sure that the fix did not break anything else.
Particular attention should be paid to the problem areas identified during the baseline review. For Code Search from past experience, we knew that PCRE sometimes takes a lot of time to execute certain regular expressions. Our initial plan was to make separate thread pools for “simple” and “complex” regular expressions. One of the first tests was the benchmark, which compared
Package dependency is a solution you may opt out of in the future. Perhaps the updates will lead the package in a new direction. Perhaps serious security issues will be found. Perhaps there will be a better option. For all these reasons, it is worth making an effort to simplify the project migration to a new dependency.
If the package is called from many places in the source code of the project, to switch to a new dependency, you need to make changes to all these different places. Worse, if the package is presented in the API of your own project, then the migration to a new dependency will require making changes to all the code that calls your API, and this may already be beyond your control. To avoid such costs, it makes sense to define your own interface along with a thin wrapper that implements this interface using dependencies. Note that the wrapper should include only what the project needs from the dependency, and not everything that the dependency offers. Ideally, this allows you to later replace another, equally suitable dependency, by changing only the wrapper.The migration of tests for each project to the use of a new interface checks the implementation of the interface and the wrapper, and also simplifies the testing of any potential replacements for dependencies.
For Code Search, we have developed an abstract class
It may also be advisable to isolate the dependency at run time to limit the possible damage caused by errors in it. For example, Google Chrome allows users to add dependencies to the browser - extension code. When Chrome was first launched in 2008, it introduced a critical function (now standard in all browsers) of isolating each extension in the sandbox , running in a separate operating system process. A potential exploit in a poorly written extension did not have automatic access to the entire memory of the browser itself.and could not make inappropriate system calls. For Code Search, until we completely dropped PCRE, the plan was to at least isolate the PCRE parser in a similar sandbox. Today another option would be a lightweight hypervisor-based sandbox, such as gVisor . Dependency isolation reduces the associated risks of executing this code.
Even with these examples and other ready-made options, isolating a suspicious code at runtime is still too complex and rarely performed. True isolation will require a language completely safe for memory, without an emergency exit to an untyped code. These are complex not only in completely unsafe languages, such as C and C ++, but also in languages that provide for restricting unsafe operations, such as Java when JNI is enabled, or Go, Rust, and Swift, when their unsafe functions are enabled. Even in a memory-safe language like JavaScript, the code often has access to far more than it needs. In November 2018, it turned out that the latest version of the npm package
If dependency seems too risky and you cannot isolate it, the best option would be to completely abandon it or at least exclude the most problematic parts.
For example, when we better understood the risks of PCRE, our plan for Google Code Search turned from “use PCRE library directly” to “use PCRE, but put the parser in the sandbox”, then “write a new regular expression parser, but keep the PCRE engine”, then in “write a new parser and connect it to another, more efficient open source engine”. Later, Jeff Dean and I also rewrote the engine, so there were no dependencies left, and we discovered the result: RE2 .
If you need only a small part of the dependency, the easiest way is to make a copy of what you need (of course, keeping the corresponding copyright and other legal notices). You take responsibility for error correction, maintenance, etc., But you are also completely isolated from larger risks. In the Go developer community, there is a saying to this effect: “A little bit of copying is better than a bit of dependency.”
For a long time, the common wisdom in software was: "If it works, do not touch anything." Updating carries the risk of introducing new bugs; without a corresponding reward - if you don’t need a new feature, why risk it? This approach ignores two aspects. First, the cost of a gradual upgrade. In software, the complexity of making changes to a code does not scale linearly: ten small changes are less work and easier than one corresponding large change. Secondly, the difficulty of detecting already fixed errors. Especially in the security context, where known errors are actively exploited, every day without updating it increases the risks that attackers can take advantage of bugs in the old code.
For example, consider the history of Equifax company from 2017, which was described in detail by managers in testimony before Congress. On March 7, a new vulnerability was discovered in Apache Struts and a patched version was released. On March 8, Equifax received a US-CERT notification of the need to update any use of Apache Struts. Equifax launched a scan of the source code and the network on March 9 and 15, respectively; no scan found vulnerable web servers open to the Internet. May 13, attackers found such servers that Equifax experts did not find. They used Apache Struts vulnerability to break into the Equifax network, and over the next two months they stole detailed personal and financial information about 148 million people. Finally, on July 29, Equifax noticed the hack and publicly announced it on September 4. By the end of September, the executive director of Equifax, as well as the CIO and CSO resigned, and an investigation began in Congress.
The Equifax experience leads to the fact that although package managers know the versions they use during the build, you need other mechanisms to track this information during the production process. For the Go language, we are experimenting with the automatic inclusion of a version manifest in each binary file so that the deployment processes can scan the binary files for dependencies that require updating. Go also makes this information available at runtime, so servers can access known error databases and report to the monitoring system themselves when they need to be updated.
A quick update is important, but updating means adding a new code to the project, which should mean updating the risk assessment of using dependencies based on the new version. At a minimum, you want to see the differences showing the changes made from the current version to the updated versions, or at least read the release notes to determine the most likely problem areas in the updated code. If a lot of code changes, so the differences are difficult to understand, this is also information that can be included in the risk assessment update.
In addition, you must re-run tests written specifically for the project to make sure that the updated package is at least as suitable for the project as the earlier version. It also makes sense to rerun your own package tests. If the package has its own dependencies, it is possible that the project configuration uses other versions of these dependencies (older or newer) than those used by the authors of the package. Running your own package tests allows you to quickly identify problems that are specific to configuration.
Again, updates should not be fully automatic. Before deploying updated versions, you must ensure that they are appropriate for your environment .
If the upgrade process involves the re-execution of already written integration and qualification tests, in most cases the delay in updating is more risky than a quick update.
The window for critical security updates is especially small. After hacking into Equifax, the security teams found evidence that the attackers (possibly different) successfully exploited the Apache Struts vulnerability on the affected servers on March 10, just three days after it was publicly disclosed. But they launched only one team there
Even after all this work is not finished. It is important to continue to monitor the dependencies and in some cases even abandon them.
First, make sure you continue to use specific versions of the packages. Most package managers now allow you to easily or automatically automatically record the cryptographic hash of the expected source code for this version of the package, and then check this hash when you re-download the package to another computer or in a test environment. This ensures that the same dependencies source code that you checked and tested will be used in the build. This kind of checks prevented the attacker
It is also important to monitor the emergence of new indirect dependencies: updates can easily implement new packages, on which the success of your project now depends. They also deserve your attention. In the case of
Creeping dependencies can also affect the size of a project. During the development of Google Sawzall- JIT-processing of logs - the authors at different times found that the interpreter's main binary contains not only JIT Sawzall, but also (unused) interpreters PostScript, Python and JavaScript. Each time, the culprit was unused dependencies declared by some Sawzall library, combined with the fact that Google’s build system automatically used a new dependency. This is why the Go compiler generates an error when importing an unused package.
The update is a natural time to revise the decision on the use of changing dependencies. It is also important to periodically review any dependency that does notis changing. Does it seem plausible that there are no security issues or other bugs to fix? Is the project abandoned? It may be time to plan a replacement for this dependency.
It is also important to double-check the security log of each dependency. For example, Apache Struts revealed serious remote code execution vulnerabilities in 2016, 2017 and 2018. Even if you have a lot of servers that run it and update it quickly, such a track record makes you think about whether to use it at all.
The era of software reuse has finally arrived, and I don’t want to downplay the benefits: it brought an extremely positive transformation to the developers. However, we accepted this transformation without fully considering the potential consequences. Former reasons to trust dependencies lose relevance at the same time when we have more dependencies than ever.
The critical analysis of specific dependencies that I described in this article represents a significant amount of work and remains the exception rather than the rule. But I doubt that there are developers who are really making efforts to do this for every possible new dependency. I have done only part of this work for a part of my own dependencies. Basically, the whole decision comes down to the following: “let's see what happens”. Too often, something more seems like too much effort.
But the Copay and Equifax attacks are clear warnings about real issues in how we use software dependencies today. We must not ignore the warnings. I propose three general recommendations.
There are a lot of good software. Let's work together and find out how to use it safely.
My own experience includes a decade of working with the Google internal repository , where dependencies are set as a priority concept, and also developing dependencies for the Go programming language .
Dependencies carry serious risks that are too often overlooked. The transition to the simple reuse of the smallest pieces of software happened so quickly that we have not yet developed best practices for effectively choosing and using dependencies. Even for deciding when they are relevant, and when not. The purpose of this article is to assess the risks and stimulate the search for solutions in this area.
What is addiction?
In modern development, dependency is an additional code that is called from a program. Adding a dependency avoids repeating work already done: designing, writing, testing, debugging, and maintaining a specific unit of code. Let's call this code unit a package , although in some systems other terms are used instead of a package, such as a library or module.
')
Accepting external dependencies is an old practice: most programmers download and install the necessary library, be it PCRE or zlib from C, Boost or Qt from C ++, JodaTime or Junit from Java. These packages contain high-quality debugged code, which requires considerable experience to create. If a program needs the functionality of such a package, it is much easier to manually download, install, and update a package than to develop this functionality from scratch. But large upfront costs mean that manual reuse is expensive: it’s easier to write tiny packages yourself.
A dependency manager (sometimes called a package manager) automates the download and installation of dependency packages. Because dependency managers simplify the loading and installation of individual packages, reducing fixed costs makes small packages economical to publish and reuse.
For example, a Node.js dependency manager called NPM provides access to more than 750,000 packages. One of them,
escape-string-regexp , contains a single function that escapes regular expression operators on the input data. All implementation: var matchOperatorsRe = /[|\\{}()[\]^$+*?.]/g; module.exports = function (str) { if (typeof str !== 'string') { throw new TypeError('Expected a string'); } return str.replace(matchOperatorsRe, '\\$&'); }; Before the advent of dependency managers, it was impossible to present an eight-line library publication: too much overhead and too little benefit. But NPM reduced the overhead to almost zero, with the result that almost trivial functionality can be packaged and reused. At the end of January 2019, the
escape-string-regexp dependency is embedded in almost a thousand other NPM packages, not to mention all the packages that developers write for their own use and do not publish in the public domain.Now, dependency managers have appeared for almost every programming language. Maven Central (Java), Nuget (.NET), Packagist (PHP), PyPI (Python) and RubyGems (Ruby) - each contains more than 100,000 packages. The emergence of such widespread reuse of small packages is one of the biggest changes in software development over the past two decades. And if we are not more careful, this will lead to serious problems.
What can go wrong?
In the context of this discussion, a package is a code downloaded from the Internet. Adding dependencies entrusts the work of developing this code — designing, writing, testing, debugging, and support — to someone else on the Internet whom you usually don't know. Using this code, you expose your own program to the effects of all failures and dependencies. The execution of your software now literally depends on the code of a stranger from the Internet. If formulated in this way, it all sounds very insecure. Why would anyone even agree to this?
We agree, because it is easy, because everything seems to work, because everyone else does this, and most importantly, because it seems to be a natural continuation of a long-standing established practice. But there is an important difference that we ignore.
Decades ago, most developers also trusted others to write programs that they depended on, such as operating systems and compilers. This software was bought from well-known sources, often with some kind of support agreement. There is still room for mistakes or outright sabotage . But at least we knew who we were dealing with and, as a rule, could use commercial or legal measures.
The open source software phenomenon, which is distributed free of charge via the Internet, has largely supplanted the old software procurement practices. When reuse was still difficult, few projects introduced such dependencies. Although their licenses usually refused any “guarantees of commercial value and suitability for a specific purpose,” the projects built themselves a good reputation. Users have largely taken this reputation into account when making their decisions. Reputational support came instead of commercial and legal measures. Many common packages of that era still enjoy a good reputation: for example, BLAS (published 1979), Netlib (1987), libjpeg (1991), LAPACK (1992), HP STL (1994) and zlib (1995).
Package managers have reduced the code reuse model to the utmost simplicity: developers can now share the code up to individual functions in dozens of lines. This is a great technical achievement. There are countless packages available, and the project may include a large number of packages, but commercial, legal, or reputational mechanisms for relying on code are a thing of the past. We trust more code, although there are fewer reasons for trust.
The cost of making a bad addiction can be viewed as the sum of all possible bad outcomes on a series of the price of each bad outcome multiplied by its probability (risk).
The price of a bad outcome depends on the context in which the dependency is used. At one end of the spectrum is a personal hobby project, where the price of most bad outcomes is close to zero: you just have fun, mistakes have no real impact, except for a little more time spent, and debugging them can even be fun. Thus, the probability of risk is almost irrelevant: it is multiplied by zero. At the other end of the spectrum is production software that should be supported for years. Here, the cost of dependency can be very high: servers can fall, confidential data can be disclosed, customers can suffer, companies can go bankrupt. In production, it is much more important to evaluate and minimize the risk of serious failure.
Regardless of the expected price, there are some approaches for assessing and reducing the risk of adding dependencies. It is likely that package managers should be optimized to reduce these risks, while they have so far focused on reducing the cost of loading and installation.
Dependency Check
You would not have hired a developer about whom you have never heard and know nothing. First you will learn something about him: check the links, have an interview and so on. Before you depend on the package that you found on the Internet, it is also wise to know a little about this package.
A basic check can give an idea of the likelihood of problems when trying to use this code. If the check reveals minor problems, you can take steps to eliminate them. If the check reveals serious problems, it may be better not to use the package: you may find a more suitable one, or you may need to develop it yourself. Remember that open source packages are published by the authors in the hope that they will be useful, but with no guarantee of usability or support. If you fail in production, you will have to debug it. As the first GNU General Public License warned, “the entire risk associated with the quality and performance of a program lies with you. If the program turns out to be defective, you bear the cost of all the necessary maintenance, repair or correction. ”
Here are some considerations for checking the package and deciding whether to depend on it.
Design
Is the package documentation clear? Does the API have a clear design? If the authors can well explain the API and design to the person, then this increases the likelihood that they also explained the implementation of the computer to the source code well. Writing code for a clear, well-thought-out API is simpler, faster, and probably less error prone. Did the authors document what they expected from the client code, for compatibility with future updates? (Examples include C ++ and Go compatibility documents).
Quality code
Is the code well written? Read some snippets. Do authors seem to be cautious, conscientious, and consistent? Does it look like the code you want to debug? You may have to do this.
Develop your own systematic ways to verify code quality. Something simple, such as compiling in C or C ++ with important compiler warnings included (for example,
-Wall ), can give an idea how seriously the developers have worked to avoid various undefined behaviors. Recent languages, such as Go, Rust and Swift, use the unsafe keyword to denote code that violates the type system; look at how much unsafe code is there. More advanced semantic tools like Infer or SpotBugs are also helpful. Linters are less useful: you should ignore standard tips on topics such as the style of brackets and focus on semantic issues.Keep in mind development methods you may not be familiar with. For example, the SQLite library comes as one file with 200,000 code and a header of 11,000 lines - as a result of merging multiple files. The very size of these files immediately raises a red flag, but a more thorough study will lead to the actual source code of development: the traditional file tree with more than a hundred C source files, tests and support scripts. It turns out that the single-file distribution is built automatically from the original source code: this is easier for end users, especially those who do not have dependency managers. (Compiled code also works faster because the compiler sees more optimization options).
Testing
Are there any tests in the code? Can you manage them? Do they pass? The tests establish that the basic functionality of the code is correct, and signal that the developer is seriously trying to keep it. For example, the SQLite development tree contains an incredibly detailed test suite with over 30,000 individual test cases. There is documentation for developers explaining the testing strategy. On the other hand, if there are few or no tests, or if the tests fail, this is a serious red flag: future changes in the package are likely to lead to regressions that could be easily detected. If you insist on tests in your code (right?), You must provide tests for code that you pass on to others.
Assuming that tests exist, run and pass, you can gather additional information by running tools to analyze code coverage, detect race conditions , check memory allocation and detect memory leaks.
Debugging
Find the bug tracker of this package. Are there many open error messages? How long have they been open? How many bugs fixed? Are there any bugs fixed recently? If there are a lot of open questions about real bugs, especially not closed for a long time, this is a bad sign. On the other hand, if errors are rarely met and quickly corrected, that's great.
Support
Look at the commit history. How long is the code actively maintained? Now he is actively supported? Packages that have been actively maintained for a long period of time are likely to continue to be supported. How many people work on the package? Many packages are personal projects that developers create for entertainment in their free time. Others - the result of thousands of hours of work of a group of paid developers. In general, packages of the second type usually fix errors faster, consistently implement new functions and, in general, they are better supported.
On the other hand, some code is really "perfect." For example, the
escape-string-regexp from NPM may never again need to be changed.Using
How many packages depend on this code? Package managers often give such statistics, or you can see on the Internet how often other developers mention this package. A greater number of users means at least that for many the code works quite well, and errors in it will be noticed more quickly. Extensive use is also a partial guarantee of continued service: if a widely used package loses the maintainer, then it is very likely that the interested user will assume its role.
For example, libraries like PCRE, Boost, or JUnit are incredibly widely used. This makes it more likely — although, of course, it does not guarantee — that errors that you may have encountered have already been corrected, because others have encountered them before you.
Security
Will this package work with unsafe input? If so, how resistant is it to malicious data? Does it have bugs that are mentioned in the National Vulnerability Database (NVD) ?
For example, when in 2006 Jeff and Dean and I began working on Google Code Search (
grep on public code bases), the popular regular expression library PCRE seemed the obvious choice. However, in a conversation with the Google security team, we learned that PCRE has a long history of problems, such as buffer overflows, especially in the parser. We saw this for ourselves by searching for PCRE in NVD. This discovery did not immediately make us give up on PCRE, but it made us think more carefully about testing and isolation.Licensing
Is the code licensed correctly? Does he even have a license? Is a license acceptable for your project or company? An amazing part of the projects on GitHub do not have a clear license. Your project or company may impose additional restrictions on license dependencies. For example, Google prohibits the use of code under licenses such as AGPL (too hard) and WTFPL (too vague).
Dependencies
Does this package have its own dependencies? The disadvantages of indirect dependencies are just as harmful as the disadvantages of direct dependencies. Package managers can list all the transitive dependencies of a given package, and each of them should ideally be checked as described in this section. A package with many dependencies will require a lot of work.
Many developers have never looked at the full list of transitive dependencies of their code and do not know what they depend on. For example, in March 2016, the NPM user community discovered that many popular projects — including Babel, Ember, and React — are indirectly dependent on a tiny package called the
left-pad of 8-line function. They discovered this when the author of the left-pad removed the package from NPM, inadvertently breaking most of the Node.js user assemblies. And the left-pad hardly exceptional in this regard. For example, 30% of the 750,000 packets in NPM depend — at least indirectly — on escape-string-regexp . By adapting Leslie Lamport's observation about distributed systems, the package manager easily creates a situation where a package crash, the existence of which you didn’t even know, can make your own code unusable.Dependency Testing
The verification process should include running your own package tests. If the package passed the test and you decide to make your project dependent on it, the next step should be to write new tests that focus on the functionality of your particular application. These tests often start as short stand-alone programs to make sure that you can understand the package API and that it does what you think (if you cannot understand or it doesn’t do it, stop immediately!). Then it is worth making an extra effort to turn these programs into automated tests that will run with new versions of the package. If you find a bug and you have a potential fix, you can easily restart these tests for a specific project and make sure that the fix did not break anything else.
Particular attention should be paid to the problem areas identified during the baseline review. For Code Search from past experience, we knew that PCRE sometimes takes a lot of time to execute certain regular expressions. Our initial plan was to make separate thread pools for “simple” and “complex” regular expressions. One of the first tests was the benchmark, which compared
pcregrep with several other grep implementations. When we found that for one basic test case, pcregrep was 70 times slower than the fastest grep , we began to rethink our plan for using PCRE. Despite the fact that we ultimately completely abandoned PCRE, this test remains in our code base today.Abstraction of dependency
Package dependency is a solution you may opt out of in the future. Perhaps the updates will lead the package in a new direction. Perhaps serious security issues will be found. Perhaps there will be a better option. For all these reasons, it is worth making an effort to simplify the project migration to a new dependency.
If the package is called from many places in the source code of the project, to switch to a new dependency, you need to make changes to all these different places. Worse, if the package is presented in the API of your own project, then the migration to a new dependency will require making changes to all the code that calls your API, and this may already be beyond your control. To avoid such costs, it makes sense to define your own interface along with a thin wrapper that implements this interface using dependencies. Note that the wrapper should include only what the project needs from the dependency, and not everything that the dependency offers. Ideally, this allows you to later replace another, equally suitable dependency, by changing only the wrapper.The migration of tests for each project to the use of a new interface checks the implementation of the interface and the wrapper, and also simplifies the testing of any potential replacements for dependencies.
For Code Search, we have developed an abstract class
Regexpthat defines the Code Search interface required from any regular expression mechanism. Then they wrote a thin wrapper around PCRE that implements this interface. Such a method facilitated the testing of alternative libraries and prevented the accidental introduction of knowledge of the internal components of PCRE into the rest of the source tree. This, in turn, ensures that if necessary it will be easy to switch to another dependency.Dependency Isolation
It may also be advisable to isolate the dependency at run time to limit the possible damage caused by errors in it. For example, Google Chrome allows users to add dependencies to the browser - extension code. When Chrome was first launched in 2008, it introduced a critical function (now standard in all browsers) of isolating each extension in the sandbox , running in a separate operating system process. A potential exploit in a poorly written extension did not have automatic access to the entire memory of the browser itself.and could not make inappropriate system calls. For Code Search, until we completely dropped PCRE, the plan was to at least isolate the PCRE parser in a similar sandbox. Today another option would be a lightweight hypervisor-based sandbox, such as gVisor . Dependency isolation reduces the associated risks of executing this code.
Even with these examples and other ready-made options, isolating a suspicious code at runtime is still too complex and rarely performed. True isolation will require a language completely safe for memory, without an emergency exit to an untyped code. These are complex not only in completely unsafe languages, such as C and C ++, but also in languages that provide for restricting unsafe operations, such as Java when JNI is enabled, or Go, Rust, and Swift, when their unsafe functions are enabled. Even in a memory-safe language like JavaScript, the code often has access to far more than it needs. In November 2018, it turned out that the latest version of the npm package
event-stream(a functional streaming API for JavaScript events) contains confusing malicious codeadded two and a half months ago. The code collected Bitcoin wallets from users of the Copay mobile application, got access to system resources completely unrelated to the processing of event flows. One of the many possible ways to protect against these kinds of problems would be better isolating dependencies.Denial of dependence
If dependency seems too risky and you cannot isolate it, the best option would be to completely abandon it or at least exclude the most problematic parts.
For example, when we better understood the risks of PCRE, our plan for Google Code Search turned from “use PCRE library directly” to “use PCRE, but put the parser in the sandbox”, then “write a new regular expression parser, but keep the PCRE engine”, then in “write a new parser and connect it to another, more efficient open source engine”. Later, Jeff Dean and I also rewrote the engine, so there were no dependencies left, and we discovered the result: RE2 .
If you need only a small part of the dependency, the easiest way is to make a copy of what you need (of course, keeping the corresponding copyright and other legal notices). You take responsibility for error correction, maintenance, etc., But you are also completely isolated from larger risks. In the Go developer community, there is a saying to this effect: “A little bit of copying is better than a bit of dependency.”
Dependency update
For a long time, the common wisdom in software was: "If it works, do not touch anything." Updating carries the risk of introducing new bugs; without a corresponding reward - if you don’t need a new feature, why risk it? This approach ignores two aspects. First, the cost of a gradual upgrade. In software, the complexity of making changes to a code does not scale linearly: ten small changes are less work and easier than one corresponding large change. Secondly, the difficulty of detecting already fixed errors. Especially in the security context, where known errors are actively exploited, every day without updating it increases the risks that attackers can take advantage of bugs in the old code.
For example, consider the history of Equifax company from 2017, which was described in detail by managers in testimony before Congress. On March 7, a new vulnerability was discovered in Apache Struts and a patched version was released. On March 8, Equifax received a US-CERT notification of the need to update any use of Apache Struts. Equifax launched a scan of the source code and the network on March 9 and 15, respectively; no scan found vulnerable web servers open to the Internet. May 13, attackers found such servers that Equifax experts did not find. They used Apache Struts vulnerability to break into the Equifax network, and over the next two months they stole detailed personal and financial information about 148 million people. Finally, on July 29, Equifax noticed the hack and publicly announced it on September 4. By the end of September, the executive director of Equifax, as well as the CIO and CSO resigned, and an investigation began in Congress.
The Equifax experience leads to the fact that although package managers know the versions they use during the build, you need other mechanisms to track this information during the production process. For the Go language, we are experimenting with the automatic inclusion of a version manifest in each binary file so that the deployment processes can scan the binary files for dependencies that require updating. Go also makes this information available at runtime, so servers can access known error databases and report to the monitoring system themselves when they need to be updated.
A quick update is important, but updating means adding a new code to the project, which should mean updating the risk assessment of using dependencies based on the new version. At a minimum, you want to see the differences showing the changes made from the current version to the updated versions, or at least read the release notes to determine the most likely problem areas in the updated code. If a lot of code changes, so the differences are difficult to understand, this is also information that can be included in the risk assessment update.
In addition, you must re-run tests written specifically for the project to make sure that the updated package is at least as suitable for the project as the earlier version. It also makes sense to rerun your own package tests. If the package has its own dependencies, it is possible that the project configuration uses other versions of these dependencies (older or newer) than those used by the authors of the package. Running your own package tests allows you to quickly identify problems that are specific to configuration.
Again, updates should not be fully automatic. Before deploying updated versions, you must ensure that they are appropriate for your environment .
If the upgrade process involves the re-execution of already written integration and qualification tests, in most cases the delay in updating is more risky than a quick update.
The window for critical security updates is especially small. After hacking into Equifax, the security teams found evidence that the attackers (possibly different) successfully exploited the Apache Struts vulnerability on the affected servers on March 10, just three days after it was publicly disclosed. But they launched only one team there
whoami.Watch your dependencies
Even after all this work is not finished. It is important to continue to monitor the dependencies and in some cases even abandon them.
First, make sure you continue to use specific versions of the packages. Most package managers now allow you to easily or automatically automatically record the cryptographic hash of the expected source code for this version of the package, and then check this hash when you re-download the package to another computer or in a test environment. This ensures that the same dependencies source code that you checked and tested will be used in the build. This kind of checks prevented the attacker
event-stream, automatically inject the malicious code into the already released version 3.3.5. Instead, the attacker had to create a new version 3.3.6 and wait for people to update (without carefully reviewing the changes).It is also important to monitor the emergence of new indirect dependencies: updates can easily implement new packages, on which the success of your project now depends. They also deserve your attention. In the case of
event-streammalicious code was hidden in another package flatMap-stream, which in the new version event-streamwas added as a new dependency.Creeping dependencies can also affect the size of a project. During the development of Google Sawzall- JIT-processing of logs - the authors at different times found that the interpreter's main binary contains not only JIT Sawzall, but also (unused) interpreters PostScript, Python and JavaScript. Each time, the culprit was unused dependencies declared by some Sawzall library, combined with the fact that Google’s build system automatically used a new dependency. This is why the Go compiler generates an error when importing an unused package.
The update is a natural time to revise the decision on the use of changing dependencies. It is also important to periodically review any dependency that does notis changing. Does it seem plausible that there are no security issues or other bugs to fix? Is the project abandoned? It may be time to plan a replacement for this dependency.
It is also important to double-check the security log of each dependency. For example, Apache Struts revealed serious remote code execution vulnerabilities in 2016, 2017 and 2018. Even if you have a lot of servers that run it and update it quickly, such a track record makes you think about whether to use it at all.
Conclusion
The era of software reuse has finally arrived, and I don’t want to downplay the benefits: it brought an extremely positive transformation to the developers. However, we accepted this transformation without fully considering the potential consequences. Former reasons to trust dependencies lose relevance at the same time when we have more dependencies than ever.
The critical analysis of specific dependencies that I described in this article represents a significant amount of work and remains the exception rather than the rule. But I doubt that there are developers who are really making efforts to do this for every possible new dependency. I have done only part of this work for a part of my own dependencies. Basically, the whole decision comes down to the following: “let's see what happens”. Too often, something more seems like too much effort.
But the Copay and Equifax attacks are clear warnings about real issues in how we use software dependencies today. We must not ignore the warnings. I propose three general recommendations.
- . , , , . , .
- . , , . , , . , , , .
- . . . , . , , . , , API. .
There are a lot of good software. Let's work together and find out how to use it safely.
Source: https://habr.com/ru/post/443620/
All Articles