Comparison of methods for predicting the conversion of chains of advertising channels
The very essence of chains of advertising channels causes an overwhelming desire to find out what most likely will happen further in the chain. Will there be a conversion or not?
But this meritorious endeavor often sticks to the problem. If you try to keep the number of false-positive results within reasonable limits, the number of true-positive is not impressive. As a result, the results of the analysis often do not allow us to make adequate management decisions. Adequate forecasting requires more data than just short chains of custom channel touches . But this does not mean that the task is worth throwing.

In this article we will tell you a little about a series of experiments on the development of a conversion prediction algorithm. This article is a continuation of the previous two on a similar theme. Here is the first , Here is the second .
')
For LSTM, there is a huge amount of excellent materials on creating a system that predicts the values of time series and the letters in words . In our case, the task was even simpler at first glance.
 Fig.1. Processing coarse data to remove too short and split too long chains.
Fig.1. Processing coarse data to remove too short and split too long chains.
Our goal is to identify a combination of touches that maximizes the likelihood of conversion across the entire customer base for chains of a selected length. To do this, we select the words (chains) of the required length from the entire sample. If the chain is longer than the specified one, it is split into several chains of the desired length. For example - (1,2,3,4) -> (1,2,3), (2,3,4). The processing process is depicted in Figure 1.
Uniform chains in this study are useless. Their conversion depends only on the length of the chain and the number of the channel, the classifier for them is constructed by logistic multi-regression with two factors. The categorical factor is the channel number, and the numerical factor is the length of the chain. It turns out quite transparent, although it is useless, because sufficiently long chains are in any case suspicious of a conversion. Therefore, they can not be considered at all. Here, it should be noted that the sample size is significantly reduced, because usually around 80% of all chains are homogeneous.
Key observation 2
You can throw away all (fundamentally) inactive channels to limit the amount of data.
Key observation 3
For any chain, you can apply one-hot encoding. This eliminates a problem that may occur if you mark the channels as a numeric sequence. For example, the expression 3 - 1 = 2 does not make sense if the numbers are channel numbers (Fig.2.).
Among other things, we tried to encode the chain with some more strange ways, which were based on different assumptions about the nature of the chains. But since this did not help us, we will not talk about it. Fig.2. The second data conversion. Remove all homogeneous chains, apply one-hot encoding.
Fig.2. The second data conversion. Remove all homogeneous chains, apply one-hot encoding.
The parameters of all models were optimized using the Basin-hopping algorithm. The result of optimism did not cause. AUC ROC rose to 0.6, but in our case it was clearly not enough.
For example, you can remove all duplicates from a chain and sort the resulting list. You can do this with something like this simple python code:
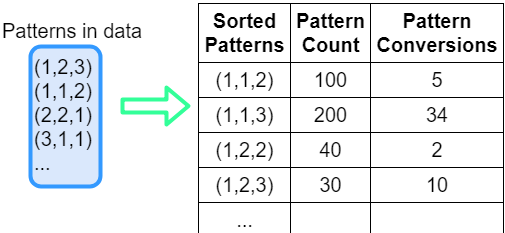 Fig.3. Sorting and counting chain patterns
Fig.3. Sorting and counting chain patterns
In the first pass, we can calculate the average conversion rate for each “template” chain in the data.
Now we sort the resulting list in descending order of conversion and get the classifier with the parameter "conversion cutoffs". Checking the test chain converted by the above method for the presence of one of the patterns from the list with a conversion greater than the specified one, we classify it as one that generates a conversion, or useless. Now we can test all incoming chains using this conversion level classifier and predict the result. Based on what happened, we built a single graph in this article that shows the advantage of this approach. ROC curve for this approach, which is called here - Pattern Check.
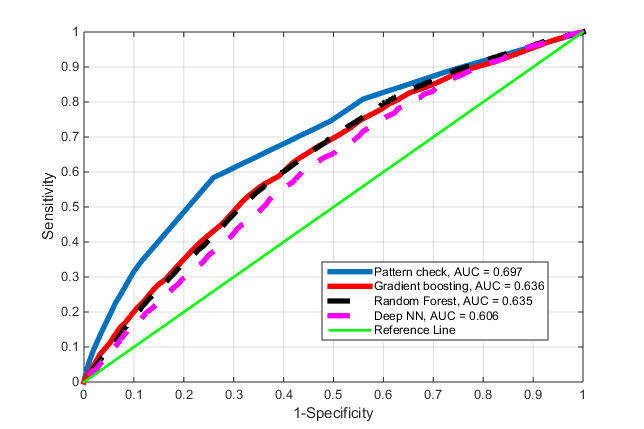 Fig.4. ROC curves for different classifiers.
Fig.4. ROC curves for different classifiers.
For our new method, AUC = 0.7. This is already something. Victory is not direct, but the coin is far from over. Comment. This method can be implemented without using one-hot, as described here for clarity, but if you want to build on success, it may already be required.
At the word “pattern”, people familiar with machine learning immediately have a thought - “convolutional neural networks!” Yes. This is true, but we will not write about it now. We have brought here a rather good, as it seems to us, chain conversion method, which, on the move, makes it possible to get a classifier (predictor) that works better than using the most advanced technologies. It can already be used to highlight a group of users with a high probability of conversion and not be afraid of thousands of false positives. For our data, when choosing a cut-off in the algorithm for a conversion of 0.25, we obtained for 5112 test sample conversions, 523 truly positive and 1123 false-positive, which, in principle, is tolerable, provided that there were 67 thousand people in the test.
PS To keep up with the news of the Maxilect company and be the first to learn about all publications, subscribe to our pages on the VK , FB or Telegram channel .
But this meritorious endeavor often sticks to the problem. If you try to keep the number of false-positive results within reasonable limits, the number of true-positive is not impressive. As a result, the results of the analysis often do not allow us to make adequate management decisions. Adequate forecasting requires more data than just short chains of custom channel touches . But this does not mean that the task is worth throwing.
In this article we will tell you a little about a series of experiments on the development of a conversion prediction algorithm. This article is a continuation of the previous two on a similar theme. Here is the first , Here is the second .
')
Formulation of the problem
Anyone who has dealt with machine learning in the context of prediction is familiar with LSTM ( RNN neural networks). But our “forecasting” comes down to an even simpler task. To predict a conversion is to classify one or another chain as belonging to the class of "converted in the future."For LSTM, there is a huge amount of excellent materials on creating a system that predicts the values of time series and the letters in words . In our case, the task was even simpler at first glance.
- Analyzing the interaction of channels, we can make up what looks like the alphabet, where the letters are separate channels. For example - “(channel) 1”, “(channel) 2”, ...
- From letters, a huge number of "words" are obtained in the form of chains, which are all possible combinations of interactions between the user and the channels. For example, chain = "1", "2", "1", "3"; chain = "2", "4", "4", "1"; ...
Our goal is to identify a combination of touches that maximizes the likelihood of conversion across the entire customer base for chains of a selected length. To do this, we select the words (chains) of the required length from the entire sample. If the chain is longer than the specified one, it is split into several chains of the desired length. For example - (1,2,3,4) -> (1,2,3), (2,3,4). The processing process is depicted in Figure 1.
The first attempt to find a simple solution.
In this attempt, we trained the LSTM network with “almost raw” chains of the same length and obtained the RUC AUC value somewhere around 0.5, which tells us that the accuracy of the classifier tends to the effectiveness of coin toss. Oops. Did not work. But to try to make a stupid was worth? Suddenly would be a ride. But no. I had to think a little.Analysis of what is happening
Key observation 1Uniform chains in this study are useless. Their conversion depends only on the length of the chain and the number of the channel, the classifier for them is constructed by logistic multi-regression with two factors. The categorical factor is the channel number, and the numerical factor is the length of the chain. It turns out quite transparent, although it is useless, because sufficiently long chains are in any case suspicious of a conversion. Therefore, they can not be considered at all. Here, it should be noted that the sample size is significantly reduced, because usually around 80% of all chains are homogeneous.
Key observation 2
You can throw away all (fundamentally) inactive channels to limit the amount of data.
Key observation 3
For any chain, you can apply one-hot encoding. This eliminates a problem that may occur if you mark the channels as a numeric sequence. For example, the expression 3 - 1 = 2 does not make sense if the numbers are channel numbers (Fig.2.).
Among other things, we tried to encode the chain with some more strange ways, which were based on different assumptions about the nature of the chains. But since this did not help us, we will not talk about it.
The second attempt is a simple solution
For different variants of chain coding, the following classification tools have been tried:- Lstm
- Multiple LSTM
- Multilayer perceptron (2,3,4, layer)
- Random forest
- Gradient Boosting Classifier (GBC)
- SVM
- Deep Convolutional Network (with 2 layers, purely just in case)
The parameters of all models were optimized using the Basin-hopping algorithm. The result of optimism did not cause. AUC ROC rose to 0.6, but in our case it was clearly not enough.
Third attempt: a simple solution.
Everything that happens naturally led to the idea that the most important is the diversity of the composition of the channels of chains and the actual composition of the channels under the condition of chains of the same length. This is not so banal thought, because it is usually considered that order is still important. But previous experiments with LSTM have shown that even if this is the case, it will not help us much. Therefore, it is necessary to focus on the composition of the chain.For example, you can remove all duplicates from a chain and sort the resulting list. You can do this with something like this simple python code:
sorted_chain = tuple(sorted(list(set(chain)))) In the first pass, we can calculate the average conversion rate for each “template” chain in the data.
Now we sort the resulting list in descending order of conversion and get the classifier with the parameter "conversion cutoffs". Checking the test chain converted by the above method for the presence of one of the patterns from the list with a conversion greater than the specified one, we classify it as one that generates a conversion, or useless. Now we can test all incoming chains using this conversion level classifier and predict the result. Based on what happened, we built a single graph in this article that shows the advantage of this approach. ROC curve for this approach, which is called here - Pattern Check.
For our new method, AUC = 0.7. This is already something. Victory is not direct, but the coin is far from over. Comment. This method can be implemented without using one-hot, as described here for clarity, but if you want to build on success, it may already be required.
findings
At the word “pattern”, people familiar with machine learning immediately have a thought - “convolutional neural networks!” Yes. This is true, but we will not write about it now. We have brought here a rather good, as it seems to us, chain conversion method, which, on the move, makes it possible to get a classifier (predictor) that works better than using the most advanced technologies. It can already be used to highlight a group of users with a high probability of conversion and not be afraid of thousands of false positives. For our data, when choosing a cut-off in the algorithm for a conversion of 0.25, we obtained for 5112 test sample conversions, 523 truly positive and 1123 false-positive, which, in principle, is tolerable, provided that there were 67 thousand people in the test.
PS To keep up with the news of the Maxilect company and be the first to learn about all publications, subscribe to our pages on the VK , FB or Telegram channel .
Source: https://habr.com/ru/post/443562/
All Articles