RBKmoney Payments under the hood - microservices, protocols and platform configuration
Hi Habr! RBKmoney gets in touch again and continues the series of articles on how to write payment processing with your own hands.

I wanted to immediately immerse myself in the details of the description of the implementation of the payment business process as a finite state machine, to show examples of such a machine with a set of events, implementation features ... But, it seems, we cannot do without a couple of review articles. Too large was the subject area. In this post, the nuances of work and interactions between microservices of our platform, interaction with external systems and how we manage the business configuration will be revealed.
Macroservice
Our system consists of a set of microservices, which, realizing each of its complete part of business logic, interact with each other and together form a macroservice. Actually, the macroservice deployed in the data center, connected to banks and other payment systems - this is our payment processing.
Microservice template
We use a unified approach to the development of any microservice in whatever language it is written. Each microservice is a Docker container, which contains:
- the application itself that implements business logic written in Erlang or Java;
- RPClib - a library that implements the communication between microservices;
- we use Apache Thrift, its main advantages are ready-made client-server libraries and the possibility of a strictly typed description of all public methods that each microservice gives;
- The second feature of the library is our implementation of Google Dapper , which allows us the ability to quickly trace requests by a simple search in Elasticsearch. The first microservice that receives a request from an external system generates a unique
trace_id, which is saved by each subsequent request chain. Also, we generate and saveparent_idandspan_id, which allows us to build a query tree, visually controlling the entire chain of microservices involved in processing the request; - the third feature is actively using the transport at the transport level of different information about the context of the request. For example, the deadline (set on the client the expected lifetime of the request), or on whose behalf we perform a call to a particular method;
- Consul template is a service discovery agent that maintains information about the location, availability and status of microservice. Microservices find each other by DNS names, TTL zones are zero, a dead or unchecked healthcheck service stops resolving and thus receives traffic;
- the logs that the application writes in the format understandable for Elasticsearch in the local container file and
filebeat, which is running on the host machine relative to the container, picks up these logs and sends them to the Elasticsearch cluster;- since we implement the platform using Event Sourcing models, the resulting chains of logs are also used for visualization in the form of different Grafana-dashboards, which allows us to reduce the time for the implementation of different metrics (we also use some metrics).

When developing microservices, we use restrictions that we have specially designed to solve the problem of both high availability of the platform and its resiliency:
- strict memory limits for each container, when going out of limits - OOM, most microservices live within 256-512M. This makes it more fragile to split the implementation of business logic, protects from drift towards the monolith, reduces the cost of the point of failure, provides an opportunity to work on cheap hardware (the platform is deployed and runs on low-cost single-dual-processor servers);
- as few stateful microservices as possible and as many stateless implementations as possible. This allows solving problems of fault tolerance, speed of recovery and in general, minimization of places with potentially incomprehensible behavior. This becomes especially important with an increase in the lifetime of the system when a large Legacy accumulates;
- approaches let it crash and "it will surely break." We know that any part of our system will fail, so we design so that it does not affect the overall correctness of the information accumulated in the platform. Helps minimize the number of undefined states in the system.
Certainly familiar to many who integrate with third parties the situation. We expected a response from a third party to the request for withdrawal of money according to the protocol, but a completely different answer came, not described in any specification that is unknown how to interpret.
In such a situation, we kill the state machine servicing this payment, any actions on it outside will receive error 500. And inside we find out the current status of the payment, bring the state of the machine in line with reality and revitalize the state machine.
Protocol Oriented Development

At the time of writing this article, 636 different checks for services that ensure the functioning of the platform have been registered in our Service Discovery. Even if we take into account that several checks go on one service, and also that most stateless services work at least in a triple instance, it still turns out to be about fifty applications that need to be able to somehow be connected with each other and not fail in RPC hell.
The situation is complicated by the fact that we have three development languages on the stack - Erlang, Java, JS and they all need to be able to communicate transparently with each other.
The first task that had to be solved was to design the correct data exchange architecture between microservices. We took Apache Thrift as a basis. All microservices exchange trifto binary files, using HTTP as the transport.
Trifet specifications are hosted as separate repositories in our github, so they are available to any developer who has access to them. Initially, they used one common repository for all protocols, but over time they came to the conclusion that this was inconvenient - joint parallel work on protocols turned into a constant headache. Different teams and even different developers were forced to agree on the names of variables, an attempt to divide into namespaces also did not help.
In general, we can say that we have protocol-driven development. Before starting any implementation, we develop the future protocol of microservice in the form of a trift specification, go through 7 laps of the review, attracting future clients of this microservice, and get the opportunity to simultaneously start developing several microservices in parallel, because we know all its future methods and we can write their handlers optionally using moki.
A separate step in the protocol development process is security-review, where guys look at the nuances of the specification being developed from their pentester point of view.
We also found it expedient to single out a separate role of the protocol owner in the team. The task is complex, a person has to keep in mind the specifics of the work of all microservices, but it pays for itself in a large order and with a single point of escalation.
Without the final approval of the pull request by these employees, the protocol cannot be merged into a master branch. In githaba there is a very convenient functionality for this - codeowners , we use it with pleasure.
Thus, we solved the problem of communication between microservices, possible problems of misunderstanding, what microservice appeared in the platform, and what it is for. This set of protocols is probably the only part of the platform where we certainly choose quality against the cost and speed of development, because the implementation of one microservice can be rewritten relatively painlessly, and the protocol on which several dozen is tied is already expensive and painful.
Along the way, careful logging helps in solving the problem of documentation. Reasonably selected method and parameter names, few comments, and a self-documented specification saves a lot of time!
For example, the specification of the method of one of our microservices looks like this, which allows you to get a list of events that occurred in the platform:
/** */ typedef i64 EventID /* Event sink service definitions */ service EventSink { /** * , * , , `range`. * `0` `range.limit` . * * `range.after` , * , , * `EventNotFound`. */ Events GetEvents (1: EventRange range) throws (1: EventNotFound ex1, 2: base.InvalidRequest ex2) /** * * . */ base.EventID GetLastEventID () throws (1: NoLastEvent ex1) } /* Events */ typedef list<Event> Events /** * , -, . */ struct Event { /** * . * , * (total order). */ 1: required base.EventID id /** * . */ 2: required base.Timestamp created_at /** * -, . */ 3: required EventSource source /** * , ( ) * -, . */ 4: required EventPayload payload /** * . * . */ 5: optional base.SequenceID sequence } // Exceptions exception EventNotFound {} exception NoLastEvent {} /** * , - */ exception InvalidRequest { /** */ 1: required list<string> errors } Thrift console client
Sometimes we are faced with the task of calling certain methods of the required microservice directly, for example, with hands from the terminal. This is useful for debugging, getting some kind of data set in raw form or in the case when the task is so rare that the development of a separate user interface is inappropriate.
Therefore, we have developed a tool for ourselves that combines curl functions, but allows you to make triple requests in the form of JSON structures. We woorl it accordingly - woorl . The utility is universal; it is enough to pass the location of any trift specification to the command line parameter, it will do the rest. Very handy utility, you can start a payment directly from the terminal, for example.
This is how the appeal directly to the platform microservice, which is responsible for managing requests (for example, to create a store), looks like. I requested data from my test account:

Observant readers probably noticed one feature in the screenshot. We don't like it either. It is necessary to fasten the authorization triftovyh calls between microservices, it is necessary in a good way TLS there gash. But while resources, as always, are not enough. They were limited to total perimeter fencing in which processing microservices live.
Communication protocols with external systems
To publish outside the trift specifications and to force our merchants to communicate using a binary protocol, we found it too cruel to them. It was necessary to choose a human readable protocol that would allow us to conveniently integrate with us, conduct debugging and be able to easily document. We chose the Open API standard, also known as Swagger .
Returning to the problem of documenting protocols, Swagger allows you to quickly and cheaply solve this problem. There are many implementations of the beautiful design of the Swagger-specification in the form of developer documentation. We looked through all that we could find and finally chose ReDoc , the JS library, which accepts swagger.json as input, and at the output generates just such three-column documentation: https://developer.rbk.money/api/ .
The approaches to the development of both protocols, internal Thrift and external Swagger are absolutely identical with us. This adds time to development, but pays off over the long term.
We also needed to solve one more important task - we not only accept requests for writing off money, but also send them further - to banks and payment systems.
Making them implement our trift would be an even more impossible task than to give it to public APIs.
Therefore, we have come up with and implemented the concept of protocol adapters. This is just another microservice, which one side implements our internal trift specification, which is the same for the entire platform, and the second is the specific protocol specific for a particular bank or PS.
The problems that arise when writing such adapters, when you have to interact with third parties, is a topic that is very rich in different stories. In our practice, we have met different, answers like: "Of course, you can implement this function as described in the protocol that we gave you, but I do not give any guarantees. After 2 weeks, our person will leave the hospital room for all this answers, and you ask him for confirmation. " Also, such situations are not rare: "here's your login and password from our server, go there and set everything up yourself."
It seems to me that the case when we integrated with a payment partner, who, in turn, integrated with our platform and successfully made payments through us (it often happens, the business specifics of the payment industry), seems to me especially interesting. The partner replied to our request for a test environment that he doesn’t have a test environment as such, but he can direct the traffic for integration with RBC, that is, with our platform, where we can be tested. This is how we, through our partner, integrated with ourselves once.
Thus, we simply solved the problem of implementing mass parallel connection of various payment systems and other third parties. In the absolute majority of cases, you do not need to touch the platform code, it is enough just to write adapters and add payment instruments to the enums.
As a result, we have such a scheme of work - RBKmoney API microservices look outward (we call them Common API, or capi *, you saw them in the consul above), which validate the input data according to the public Swagger-specification, authorize clients, broadcast These methods are in our internal trift calls and send requests further along the chain to the next microservice. In addition, these services implement another requirement for the platform, whose TZ was formulated as: "the system must always be able to get a cat."
When we need to make a call to some external system, internal microservices pull the trift methods of the corresponding protocol adapter, they translate them into the language of a specific bank or payment system and send them outside.
Protocol backward compatibility difficulties
The platform is constantly evolving, new functions are being added, old ones are changing. In such conditions, it is necessary either to invest in supporting backward compatibility, or to constantly update dependent microservices. And if the situation when the required field turns into an optional everything is simple, you can do nothing at all, then in the opposite case you have to spend additional resources.
With a set of internal protocols, everything goes easier. The payment industry rarely changes so much that there are some fundamentally new methods of interaction. Let us take, for example, the task that is frequent for us - connecting a new provider with a new means of payment. For example, local purse processing, which allows to process payments on the territory of Kazakhstan in tenge. This is a new wallet for our platform, but it doesn’t differ in principle from the same Qiwi-wallet - it always has some unique identifier and methods that allow you to debit / cancel funds from it.
Accordingly, our trift specification for all purse providers looks like this:
typedef string DigitalWalletID struct DigitalWallet { 1: required DigitalWalletProvider provider 2: required DigitalWalletID id } enum DigitalWalletProvider { qiwi rbkmoney } and adding a new payment instrument in the form of a new wallet simply complements the enum:
enum DigitalWalletProvider { qiwi rbkmoney newwallet } Now it remains to bump all microservices using this specification, synchronizing with the repository master with the specification and rolling them out via CI / CD.
With external protocols more difficult. Each update of the Swagger-specification, especially without backward compatibility, is practically unrealistic to apply within a reasonable time - it is unlikely that our partners keep free developer resources specifically for updating our platform.
And sometimes it is simply impossible, we periodically encounter situations like: “the programmer wrote us a store and left, took the source code with us, how it works, we don’t know, it works and we don’t touch it”.
Therefore, we are investing in supporting backward compatibility on external protocols. In our architecture, this is slightly easier to do - since we use separate protocol adapters for each specific version of the Common API, we simply leave the old capi microservices to work, changing only the part that looks trift inside the platform, if necessary. This is how capi-v1 , capi-v2 , capi-v3 microservices appear and stay with us forever, and so on.
What will happen when a capi-v33 let's see, you'll have to deprecate some old versions, probably.
At this point, I usually begin to understand very well companies like Microsoft and all their pain in supporting backward compatibility solutions that have been around for decades.
Configure the system
And, ending the topic, we will describe how we manage the business-specific settings of the platform.
Simply making a payment is not as easy as it sounds. For each payment, the business customer wants to attach a huge amount of conditions - from commission to, in principle, the possibility of a successful outcome depending on the time of day. We set ourselves the task of digitizing the entire set of conditions that a business customer can come up with now and in the future and apply this set to each newly launched payment.
As a result, we stopped at developing our own DSL, which we used to attach tools for convenient management, which allow us to describe the business model in the right way: selection of protocol adapters, description of the posting plan, according to which money will be scattered over accounts inside the system, setting limits, fees, categories and other things specific to the payment system.
For example, when we want to take a commission of 1% for acquiring with the maestro and MS cards and scatter it over the accounts within the system, we configure the domain like this:
{ "cash_flow": { "decisions": [ { "if_": { "any_of": [ { "condition": { "payment_tool": { "bank_card": { "definition": { "payment_system_is": "maestro" } } } } }, { "condition": { "payment_tool": { "bank_card": { "definition": { "payment_system_is": "mastercard" } } } } } ] }, "then_": { "value": [ { "source": { "system": "settlement" }, "destination": { "provider": "settlement" }, "volume": { "share": { "parts": { "p": 1, "q": 100 }, "of": "operation_amount" } }, "details": "1% processing fee" } ] } } ] } } , , . , JSON. , , , . , , . , CVS/SVN-.
" ". , , , 1%, , , . , , . , .
cvs-like , . , — stateless, , . . .
- . , , . , , .
. , 10 , , .
, , , -, woorl-. - JSON- . - JS, , UX:
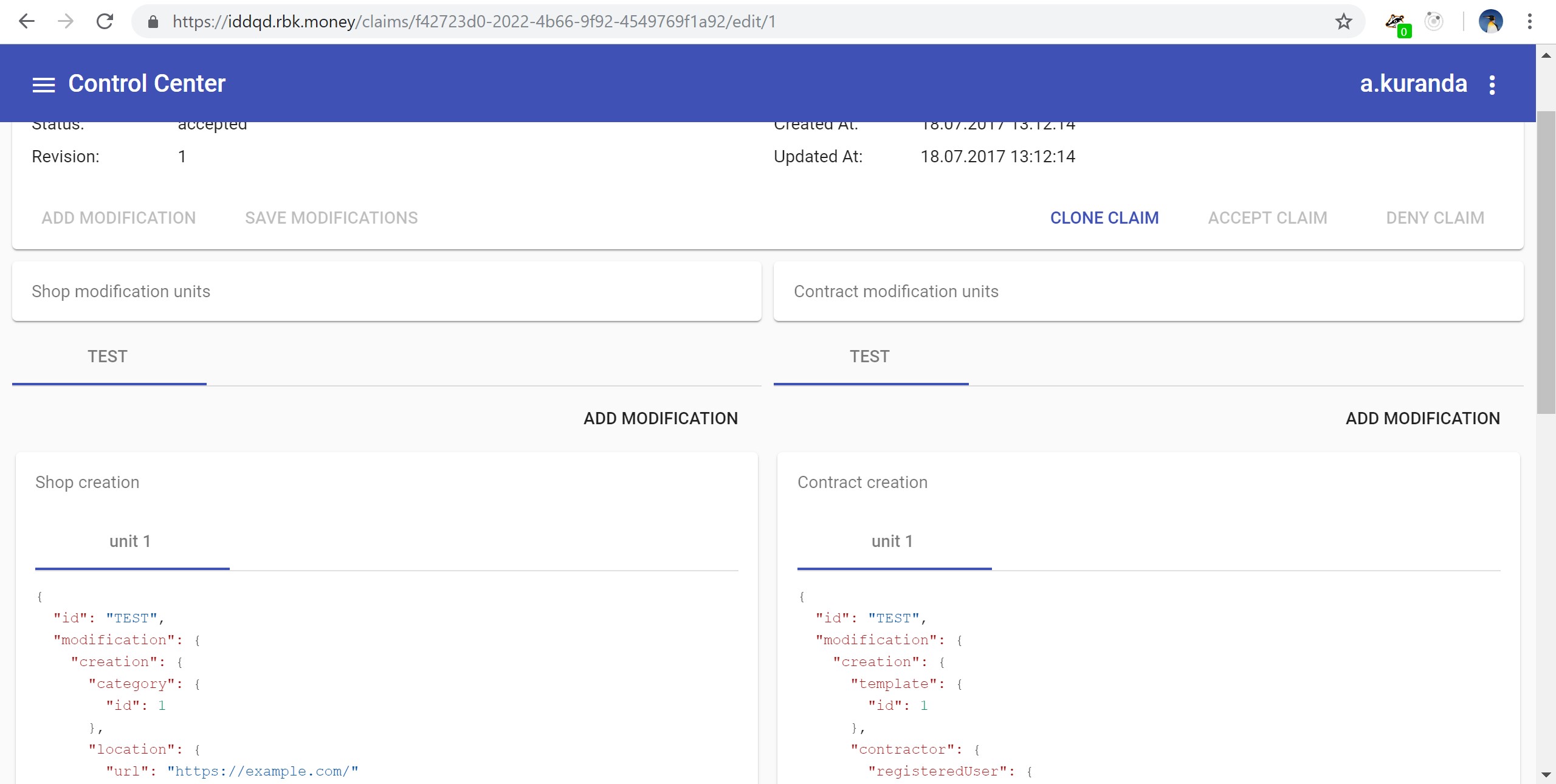
, , , .
, , .
, , SaltStack.
, !
')
Source: https://habr.com/ru/post/443518/
All Articles