AIOps in practice - what can Huawei FabricInsight
In response to the growing number of running applications and the number of network devices, network bandwidth increases and packet delivery requirements are tightened. On a scale of business-critical cloud data centers, the traditional approach to infrastructure maintenance no longer allows solving typical tasks. Therefore, the concept of AIOps (Algorithmic IT Operations) was born.
According to Gartner's forecast, by the next year around 50% of companies will use AIOps. The fact that such tools can today, we tell on the example of Huawei FabricInsight - network analyzer, which is part of a complete solution for the data center Huawei CloudFabric.
Digital transformation of enterprises provides new opportunities - the introduction of Big Data analysis, the development of machine learning algorithms is no longer just a tribute to fashion, but a conscious need, the closure of which brings real profits. However, new implementations entail a multiple increase in the complexity of the infrastructure, which simultaneously poses new challenges in terms of its maintenance.
')
The main problem of the maintenance of a large infrastructure today is the amount of data that must be collected and processed to obtain information about the state of the data center, as well as the speed with which a relevant response should be given to the causes of failures. On the one hand, the number of monitored parameters is constantly growing, on the other - time plays against organizations, because the goal of any company is to restore the availability of its services as soon as possible if something went wrong (especially considering the strict SLA requirements). The speed of the “rise” of the service after the collapse is largely determined by the speed with which the incident was investigated. And she, in turn, depends on the completeness of information about what is happening. But if at least 50 - 100 server racks are installed in the data center, standard monitoring mechanisms cannot cope with high bandwidth requirements and timely packet delivery.
Standard mechanisms - SNMP and xFlow - collect data only once every 5-15 minutes, sampling information. They were originally developed with an eye to the limitations of post-processing accumulated data without the task of identifying problems in real time. And even such limited data collection affects the operation of network devices.
Considering that the problem traffic is only 3.65%, the traditional approach based on the analysis reveals only 30% of network problems, 70% are not visible to monitoring systems.
To identify the root of the problem from the data collected by SNMP and xFlow, we need experienced administrators who know what to look for and where. Problems have to be identified by analyzing the huge logs and multiple error messages, and then manually make changes to the configuration. But with the development of SDN, with the virtualization of physical resources, manual configuration is a thing of the past. Today, even a whole staff of system administrators can no longer ensure continuous compliance of infrastructure parameters with business requirements.
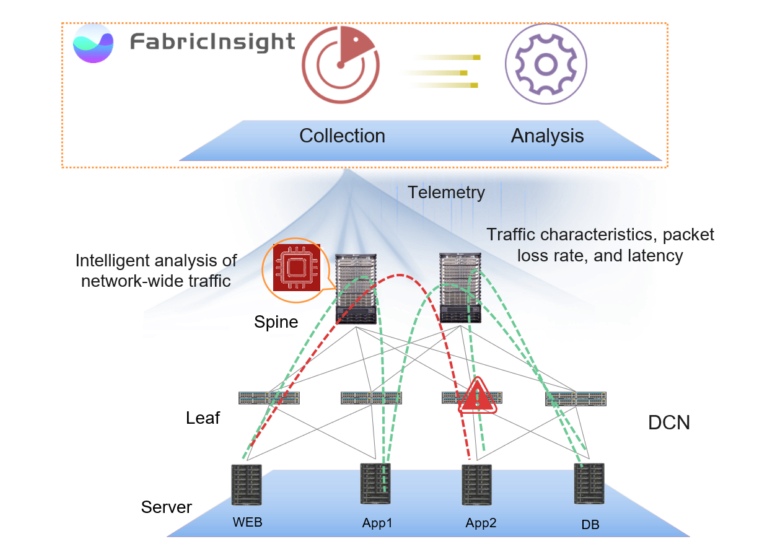
The network analysis platform, FabricInsight, offers a different approach, automating network maintenance processes and identifying points of failure. FabricInsight analyzes the behavior of applications, identifies the network paths they use, and tracks the status of devices on them.

This approach is based on two key components - the collection of all available data and their automatic analysis. Complemented by functional visualization and data openness policies, this approach allows you to solve many of the tasks that were previously deadlocked.
The key to a quick response to the situation is a complete picture of what is happening inside the data center at the network level. FabricInsight uses a push telemetry subscription mechanism to collect all second-level service data in a timely manner without sampling. For a complete network picture, data on the operation of devices, applications and network traffic (TCP TCP SYN, FIN and RST packets) is collected — ERSPAN is supported for mirroring packets without using the device’s CPU and Google’s GRPC for reporting the performance of the devices themselves.
The collected data through the FabricInsight LEAF is transferred to the FabricInsight Collector, which tracks the time parameters of the packet through the network. Data on network traffic Collector provides time stamps, encodes and sends via HTTP to the FabricInsight Analizer. This approach allows you to gather as much information as possible about the network, capturing even short-term bursts of traffic that cannot be detected by “classic” solutions.
At the same time, FabricInsight does not look inside of IP packets (does not capture their content), using only headers in their work. Thus, it can be used in business-critical areas, for example, where work with personal data is underway.
The second integral element of the system is FabricInsight Analyzer. Receiving the collected data, it identifies the traffic paths and runs algorithms that analyze the situation almost in real time. In general, FabricInsight Analyzer relates network traffic to applications, allowing you to quickly identify and correct problems. At the expense of machine learning, the algorithms are “trained” to identify the normal and anomalous behavior of the infrastructure.
The results of network analysis FabricInsight reflects in its interface in the form of network status maps, application interactions, analytics on individual applications, etc., updated in real time. The interface is implemented in such a way as to visually connect the level of applications and specific physical devices responsible for the network operability, which speeds up the search for faults and methods for solving them.
If any anomalies are detected in the automatic mode, the original information is saved according to which problems were detected (the storage duration is adjusted), if necessary, FabricInsight warns the user. In addition, the procedures for correcting the situation “in one click with the mouse” via a graphical interface are initialized. At the same time, various error correction patterns are analyzed to find the most relevant approach.
To identify anomalies of data center behavior, a correlation analysis of applications, devices, and traffic paths is used; thus, various types of anomalies are recorded, both temporary and long-lasting.

By the way, most of the temporary anomalies listed above cannot be fixed using the classical approach. This also applies to some long-term anomalies. A fairly common example is the “crooked” software update. Suppose there was some kind of application in the data center that generates certain traffic. After its update, the volume of this traffic has changed dramatically, for example, the application's throughput has decreased, and delays have increased. This anomaly will be fixed by FabricInsight.
Another example is the gradual degradation of the optical communication module (performance drop), preceding the failure. Degradation determines the instability of transmission, which for long periods of time may indicate the need for an immediate replacement of equipment. But to identify this with a standard approach is extremely difficult.

In response to this problem, the FabricInsight interface displays the statuses of all optical modules in the system along with an estimate of the probability of their failure.

Although FabricInsight appeared on the Russian market in January of this year, it has already been deployed in ICBC, China UnionPay, China Merchants Bank, PICC and other large data centers based on Huawei infrastructure.
So far, the solution supports only our switches (on Broadcom chipsets), but in the future we plan to go beyond the ecosystem of one manufacturer. Also, in the work on FabricInsight, we initially focused on open standards, so that it could normally make friends with third-party tools. For example, Druid can be used to export data from FabricInsight, through which you can send information to third-party visualization tools. Also, FabricInsight is already integrated with the open-source visualization tool Grafana.
In general, AIOps tools like our FabricInsight are the logical way to develop infrastructure monitoring and maintenance tools. It seems to us that this is the only way to continue to observe SLA for services.
According to Gartner's forecast, by the next year around 50% of companies will use AIOps. The fact that such tools can today, we tell on the example of Huawei FabricInsight - network analyzer, which is part of a complete solution for the data center Huawei CloudFabric.
Digital transformation of enterprises provides new opportunities - the introduction of Big Data analysis, the development of machine learning algorithms is no longer just a tribute to fashion, but a conscious need, the closure of which brings real profits. However, new implementations entail a multiple increase in the complexity of the infrastructure, which simultaneously poses new challenges in terms of its maintenance.
')
The main problem of the maintenance of a large infrastructure today is the amount of data that must be collected and processed to obtain information about the state of the data center, as well as the speed with which a relevant response should be given to the causes of failures. On the one hand, the number of monitored parameters is constantly growing, on the other - time plays against organizations, because the goal of any company is to restore the availability of its services as soon as possible if something went wrong (especially considering the strict SLA requirements). The speed of the “rise” of the service after the collapse is largely determined by the speed with which the incident was investigated. And she, in turn, depends on the completeness of information about what is happening. But if at least 50 - 100 server racks are installed in the data center, standard monitoring mechanisms cannot cope with high bandwidth requirements and timely packet delivery.
Why can't SNMP cope?
Standard mechanisms - SNMP and xFlow - collect data only once every 5-15 minutes, sampling information. They were originally developed with an eye to the limitations of post-processing accumulated data without the task of identifying problems in real time. And even such limited data collection affects the operation of network devices.
Considering that the problem traffic is only 3.65%, the traditional approach based on the analysis reveals only 30% of network problems, 70% are not visible to monitoring systems.
To identify the root of the problem from the data collected by SNMP and xFlow, we need experienced administrators who know what to look for and where. Problems have to be identified by analyzing the huge logs and multiple error messages, and then manually make changes to the configuration. But with the development of SDN, with the virtualization of physical resources, manual configuration is a thing of the past. Today, even a whole staff of system administrators can no longer ensure continuous compliance of infrastructure parameters with business requirements.
FabricInsight works differently
The network analysis platform, FabricInsight, offers a different approach, automating network maintenance processes and identifying points of failure. FabricInsight analyzes the behavior of applications, identifies the network paths they use, and tracks the status of devices on them.
This approach is based on two key components - the collection of all available data and their automatic analysis. Complemented by functional visualization and data openness policies, this approach allows you to solve many of the tasks that were previously deadlocked.
Collect all available data
The key to a quick response to the situation is a complete picture of what is happening inside the data center at the network level. FabricInsight uses a push telemetry subscription mechanism to collect all second-level service data in a timely manner without sampling. For a complete network picture, data on the operation of devices, applications and network traffic (TCP TCP SYN, FIN and RST packets) is collected — ERSPAN is supported for mirroring packets without using the device’s CPU and Google’s GRPC for reporting the performance of the devices themselves.
The collected data through the FabricInsight LEAF is transferred to the FabricInsight Collector, which tracks the time parameters of the packet through the network. Data on network traffic Collector provides time stamps, encodes and sends via HTTP to the FabricInsight Analizer. This approach allows you to gather as much information as possible about the network, capturing even short-term bursts of traffic that cannot be detected by “classic” solutions.
At the same time, FabricInsight does not look inside of IP packets (does not capture their content), using only headers in their work. Thus, it can be used in business-critical areas, for example, where work with personal data is underway.
Real time analysis
The second integral element of the system is FabricInsight Analyzer. Receiving the collected data, it identifies the traffic paths and runs algorithms that analyze the situation almost in real time. In general, FabricInsight Analyzer relates network traffic to applications, allowing you to quickly identify and correct problems. At the expense of machine learning, the algorithms are “trained” to identify the normal and anomalous behavior of the infrastructure.
The results of network analysis FabricInsight reflects in its interface in the form of network status maps, application interactions, analytics on individual applications, etc., updated in real time. The interface is implemented in such a way as to visually connect the level of applications and specific physical devices responsible for the network operability, which speeds up the search for faults and methods for solving them.
If any anomalies are detected in the automatic mode, the original information is saved according to which problems were detected (the storage duration is adjusted), if necessary, FabricInsight warns the user. In addition, the procedures for correcting the situation “in one click with the mouse” via a graphical interface are initialized. At the same time, various error correction patterns are analyzed to find the most relevant approach.
Cases
To identify anomalies of data center behavior, a correlation analysis of applications, devices, and traffic paths is used; thus, various types of anomalies are recorded, both temporary and long-lasting.
By the way, most of the temporary anomalies listed above cannot be fixed using the classical approach. This also applies to some long-term anomalies. A fairly common example is the “crooked” software update. Suppose there was some kind of application in the data center that generates certain traffic. After its update, the volume of this traffic has changed dramatically, for example, the application's throughput has decreased, and delays have increased. This anomaly will be fixed by FabricInsight.
Another example is the gradual degradation of the optical communication module (performance drop), preceding the failure. Degradation determines the instability of transmission, which for long periods of time may indicate the need for an immediate replacement of equipment. But to identify this with a standard approach is extremely difficult.
In response to this problem, the FabricInsight interface displays the statuses of all optical modules in the system along with an estimate of the probability of their failure.
Integration
Although FabricInsight appeared on the Russian market in January of this year, it has already been deployed in ICBC, China UnionPay, China Merchants Bank, PICC and other large data centers based on Huawei infrastructure.
So far, the solution supports only our switches (on Broadcom chipsets), but in the future we plan to go beyond the ecosystem of one manufacturer. Also, in the work on FabricInsight, we initially focused on open standards, so that it could normally make friends with third-party tools. For example, Druid can be used to export data from FabricInsight, through which you can send information to third-party visualization tools. Also, FabricInsight is already integrated with the open-source visualization tool Grafana.
In general, AIOps tools like our FabricInsight are the logical way to develop infrastructure monitoring and maintenance tools. It seems to us that this is the only way to continue to observe SLA for services.
Source: https://habr.com/ru/post/443482/
All Articles