Synthetic vs real test data: pros, cons, pitfalls

Let's start with sweet and give examples from the practice of testing.
Imagine an online store ready for launch. Nothing foreshadows trouble. Marketers have developed a promotion strategy, articles have been written in specialized Internet resources, advertising has been paid. Management expected up to 300 weekly purchases. The first week passes, the managers fix 53 payments. Shop Guide Furious ...
The project manager runs in search of reasons: poor usability? inappropriate traffic? something else? Began to understand, studied data analytics systems. It turned out that 247 people reached the order and only 53 paid.
')
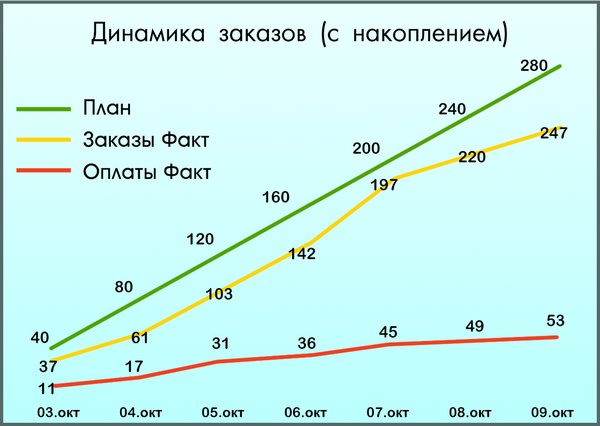
The analysis showed that the rest could not make a purchase because of the email address!
Testing order form given to a novice specialist. He tried his best, entered into the fields "Full Name", "Email", "Phone" all possible and impossible options that were given to him by online generators. A week later, all the bugs were found and fixed. The release took place. But among the options considered there was not a single email address containing less than 8 characters after @.

So happy owners of mail @ mail.ru, @ ya.ru (and similar) could not enter their mail and left the site without shopping. The owners did not receive about 600 thousand rubles, the entire advertising budget was merged into a void, and the online store received a lot of negative reviews.
Do you think this is an isolated case? Then here is another scary story for the customer.
In the wake of the general interest in non-cash payments, the company for issuing loans decided to introduce a new method of transferring funds - to the borrower's bank card. We implemented the appropriate form in the manager’s personal account, tested various errors in the fields for entering card data, fixed it, started working. A month later, the management received information that 24% of potential borrowers, who had already received approval, did not complete the loan until the end. Why? They provided a bank card, the number of which contained 18 digits, instead of the pledged and tested 16. Neither the system nor the managers could register such cards, and customers left with nothing.

The pilot project was implemented in 3 offices of the city. The average number of monthly loans in three offices was 340. Outcome: the organization lost at least 612 thousand rubles. revenue.
These are just a couple of examples where synthetic data can cause serious losses on a project. Many testers enter synthetic data in order to test various projects - from mobile applications to software. In this case, the testers themselves come up with test situations, trying to predict the behavior of the user.
However, most often they see the user is not multidimensional, as in a cinema with 3D glasses, but rather schematic, as if the child had painted a little man on the album sheet.
This leads to the fact that the tester does not cover all possible test situations and cannot work with a large amount of data. And, although the testing can be carried out well, there are no guarantees that the system will not fall when the real user (most often illogical and even unpredictable) starts interacting with the product.
Today we will talk about which data to give preference in the testing process: synthetic or real.
Understand the terms
Every time we take a test, we decide which test data we will use. Their sources can be:
- Copies of the production database version on the test stand.
- DB third-party client systems that can be used in the current.
- Generators test data.
- Manual creation of test data.
The first 2 sources provide us with real test data. They are created under existing processes by users or the system.

For example, when we join a web product development project for a manufacturing company, we can use a copy of an existing 1C database, which for several years collected and processed all data about operations and customers, for testing. With the help of the module for generating and displaying reports on completed orders, we get information from 1C in the right format and work with real test data.
We call the sources from points 3 and 4 “synthetic test data” (this term can be found in foreign testing, but it is rarely used in the Russian-language segment). We create such data ourselves for development and testing purposes.

For example, we received an order from a new electronic trading platform for procurement by state and municipal organizations of 44 FZ. There are very strict rules for the protection of information, so the team does not have access to real data. The only way to test: create a whole set of test data from scratch. Even physical digital signatures that are intended solely for testing.
In our practice, one type of data is rarely used, usually we work with their combination depending on the task.
To check the limitations and exceptions in the same system for a manufacturing company, we additionally used synthetic data. With their help, we checked how the report behaves if there are no products in one of the orders. On the electronic trading platform we combined synthetic data with real reference books OKPD2 and OKVED2.
Synthetic data features

In some situations, without synthetic data simply can not do! Let's see for which tasks from the tester's arsenal they can be used:
1. Simplification and standardization
Often, real data are homogeneous data arrays: imagine that thousands of individuals with one set of attributes, legal entities that differ in type, standard operations, and many other types of entities are registered in the system. Then why spend hours testing the same input data, if you can combine them into groups and assign a “representative” for each group?
At one of last year’s projects, the customer decided to strengthen the team of testers before the next release, for which a team of our specialists was involved. The product contained a modified registration form with multiple fields. We laid on the test form 30 minutes and spent about the same time. In parallel, it was revealed that this form had previously been tested by another tester, having spent 7 hours on this. Why? He simply decided to drive out the test according to real data of 12 employees from the staff list and did not take into account that the test for one employee covers all the attributes that are the same for each registered profile.
Profit: 6 hours and 30 minutes and it is only on one test.
2. Combinatorics and test coverage
Despite the often large amount of real data, they may not contain a number of possible cases. In order to guarantee the performance of the system with various combinations of input data, we have to generate them ourselves.
Let's return to the previous example. The registration form in the new release was not just refined. The customer's team, based on the norms of corporate culture, decided to make the patronymic area mandatory. As a result, all foreign specialists in the state abruptly had one father - Ivan (someone said to write Ivanovich, until they fixed it). The case is funny, but if you do not take into account any Wishlist or the parameters of your clients in the tests, then do not be offended if these people will not then consider you in their costs / feedback.
3. Automation
In automated testing, synthetic data is indispensable. Even seemingly insignificant changes in data can affect the performance of a whole set of test runs.
Here is an illustrative example from the banking sector. To check whether the application correctly puts down the numbers of bank accounts in the documents it generates, we spent 120 man / hours on writing autotests. There was no access to the database, because the account number was specified in the AutoTest itself. The tests performed well and we were ready to draw in the report 180% + ROI from automation. But a week later the database was updated with a change in the account number. All autotests, as well as our efforts to automate safely hit. After completion of autotests, the total ROI dropped to 106%. With the same success, we could immediately start testing with our hands.
4. Improved manageability
Using synthetic data, we know (at worst, we assume) what kind of response to expect from the system. If changes are made to the functionality, we understand how the response to the same data will change. Or we can correct the data to get the desired result.
In one of the projects, our team started testing using real data from the database of customer’s contractors. The database was actively developed, but at that time it was composed extremely carelessly. We lost time trying to understand where the error is, in the functional or in the database. The solution was simple, to create a synthetic database, which has become shorter, but more adequate and more informative. Testing of this functionality was completed for 12 people / hours.
So what are the disadvantages?
It may seem that synthetic data is omnipotent. So it is, until you encounter the human factor. Synthetic data is deliberately created by people and this is their main drawback. We physically can not think of all possible scenarios and combinations of input factors (and no one has canceled force majeure). And here the advantage remains for real data.
The benefits of working with real data

What advantages do we see in working with real data? 4 proofs from our experience:
1. Work with large amounts of information
The real work of the system gives us millions of operations. No team of specialists will be able to repeat the simultaneous operation of thousands of users or automatic data generation.
Proof: we created a synthetic mini-DB, which, as it seemed to us, met all the criteria of the customer’s existing base. With a synthetic base, everything worked perfectly, but it was enough to run tests with a real base, how it all fell down. Bottom line: if you cannot take into account all the nuances of a real data sample, do not waste time generating synthetic data.
2. Using a variety of data formats
Text, sound, video, images, executable files, archives - it is impossible to predict what the user will decide to load into the form field. Tips on accepted formats can be ignored, and the ban on downloading may not be implemented by the development team. As a result, the desired scenarios are tested. For example, that in the sound download field, indeed, you can download an mp3 file and that downloading an executable file does not harm the system. The actual data helps us to track exceptions.
Proof: we tested the field of loading photos into the user profile. We tried the most common graphic formats from the database, plus several video and text files. Synthetic selection loaded perfectly. In actual operation, it turned out that any attempt to download a sound file causes an error. The entire registration form crashed without the ability to replace the file. Not even saved the page update.
3. Unpredictable user behavior
Although many QA specialists have succeeded in creating and analyzing exceptional situations, let's be honest - we will never be able to accurately predict how a person will behave and the surrounding factors. And you can start with turning off the Internet at the time of the operation, and finish with operations with the program code and internal files.
Proof: in our company, employees are certified every year, where, among other things, they assess their skills in a special application form. Estimates are coordinated with the manager, and on the basis of them the grade (level) of the specialist is calculated. Before the release, the module was fully tested, everything worked like a clock. But once, at the moment of saving the results to the system, a ddos-attack was made, as a result of which only part of the data was saved, and subsequent attempts to save only duplicated errors. Without a real situation, we would not have traced such a serious mistake.
4. System updates
It is very important to understand how the system will behave when upgrading, what risks are possible, what may "not take off." In programs like 1C, where there is a huge amount of reference books and links, the issue of updates is particularly acute. And here the best option would be to have a fresh copy of the production version, test the update on it, and only then be released.
Proof: the case is quite common. The project in the field of factoring services. The severity of data loss and corruption is overwhelming, and any suspicion of the relevance of the data reproduced by the system can stop the work of the entire office. And here our special crookedly rolls out the next update immediately on the prod, without capturing the last 10 versions of the builds.
Rolled out at 18-00 fixed in the morning, hours at 11. Due to the failed revision and misunderstanding with the versions, the work of the company's divisions was completely frozen for 2 hours. Managers could not process current contracts and register new ones.
Since then, we have been working with three stands:
- Develop. Here are laid out improvements, anarchy and chaos is created, called exceptions testing. QA-engineers work mainly with synthetic data, real ones are infrequently downloaded.
- Pre-release. When all the improvements are implemented and tested, they are collected in this thread. This is also pre-rolled version with the sale. Thus, we are testing the update and operation of new functions in conditionally combat conditions.
- Production. This is already a working, combat version of the system with which end users work.
So with what data and when to work?

We share 3 insights of our work with real and synthetic data:
1. Remember that the choice of data type depends on the purpose and stage of testing. So, developing a new system, we can operate only with synthetic data. To cover various combinations of input conditions, we also, most often, turn to them. But the reproduction of some tricky exceptions associated with the behavior of the user will require real logs. The same applies to working with generally accepted directories and registries.
2. Do not forget to optimize your work with test data. Where possible, use generators, form general registries of basic entities, save and use system backups in time, deploying them at the right moment. Then the preparation for the next project will not be a source of longing and despondency for you, but one of the stages of work.
3. Do not go to the side of solid synthetics, but do not dwell on real data. Use a combined approach to test data to avoid missing errors, save time and show maximum results in your work.
Despite the fact that synthetics are predicting a great future, and scientists have seen in the synthetic data a new hope of artificial intelligence, synthetics in testing are no panacea. This is just another approach to the generation of test data, which can help solve your problems, and may lead to the emergence of new ones. Knowing the strengths and weaknesses of real / synthetic data, as well as the ability to apply them at the right time, this is what protects you from loss, downtime or a lawsuit. I hope today we have helped you become a bit more secure. Or not?
Let's discuss. Tell us in the comments about your cases of working with synthetic and real test data. Let's see who among us more: realists or synthetics? ;)
Victoria Sokovikova.
Test Analyst at Quality Laboratory
Source: https://habr.com/ru/post/443478/
All Articles