Flexible data storage in MySQL (JSON)
Alexander Rubin works for Percona and more than once spoke at HighLoad ++ , familiar to participants as an expert in MySQL. It is logical to assume that today we will talk about something related to MySQL. This is true, but only in part, because we will also talk about the Internet of things . The story will be half-entertaining, especially the first part, in which we will look at the device that Alexander created to harvest the apricots. Such is the nature of this engineer - if you want fruit, you buy a fee.

Prehistory
It all started with a simple desire to plant a fruit tree on your site. It would seem very simple to do this - you come to the store and buy a sapling. But in America, the first question asked by vendors is how much wood will sunlight get. For Alexander, this turned out to be a giant mystery - it is completely unknown how much sunlight there is on the site.
')
To find out, a schoolboy could go out into the yard every day, watch how much sunlight there was, and write it in a notebook. But this is not the case - everything must be equipped with equipment and automated.
During the presentation, many examples were launched and reproduced on the air. Want a more complete picture than in the text, switch to watching videos.
So, in order not to record weather observations in a notebook, there are a large number of devices for Internet things - Raspberry Pi, the new Raspberry Pi, Arduino - thousands of different platforms. But I chose a device for this project called Particle Photon . It is very easy to use, it costs $ 19 on the official site.
In Particle Photon, it's good that it is:
I made such a device and put it in the grass on the site. It has a Particle Device Cloud and a console. This device connects via Wi-Fi hotspot and sends data: light, temperature and humidity. Priborchik lasted 24 hours on a small battery, which is quite good.
Next, I need to not only measure the light and so on and transfer them to the phone (which is really good - I can see in real time what kind of light I have), but also store the data . For this, naturally, as a veteran of MySQL, I chose MySQL.
How we write data to mysql
I chose a rather complicated scheme:
I am using the Particle JS API, which can be downloaded from the Particle website. I establish a connection with MySQL and write it down, that is, I just do INSERT INTO values. Such is the pipeline.
Thus, the device lies in the courtyard, connects via Wi-Fi to a home router and using the MQTT protocol transfers data to Particle. Next is the same scheme: a virtual machine runs a program on Node.js, which receives data from Particle and writes it to MySQL.
To begin with, I built graphs from raw data in R. The graphs show that the temperature and the illumination rise during the day, fall to the night, and the humidity rises - this is natural. But there is also noise on the graph, which is typical of Internet of things devices. For example, when a bug got into the device and closed it, the sensor can transmit completely irrelevant data. This will be important for further consideration.
Now let's talk about MySQL and JSON, what has changed in working with JSON from MySQL 5.7 in MySQL 8. Then I will show the demo for which I use MySQL 8 (at the time of the report this version was not yet ready for production, now a stable release has been released).
MySQL data storage
When we try to store the data received from the sensors, our first thought is to create a table in MySQL :
Here for each sensor and for each data type there is a column: light, temperature, humidity.
This is quite logical, but there is a problem - it is not flexible . Suppose we want to add another sensor and measure something else. For example, some people measure the remainder of a beer in a keg. What to do in this case?
How to pervert, to add something to the table? You need to make an alter table, but if you have done an alter table in MySQL, then you know what I'm talking about - this is absolutely not easy. Alter table in MySQL 8 and in MariaDB is much easier to implement, but historically this is a big problem. So if we need to add a column, for example, with the name of the beer, it will not be so easy.
Again, sensors appear, disappear, what do we do with the old data? For example, we stop receiving information about the light. Or are we creating a new column - how to store something that was not there before? The standard approach is null, but for analysis it will not be very convenient.
Another option is the key / value store.
Data storage in MySQL: key / value
It will be more flexible : in key / value there will be a name, for example, temperature and accordingly data.
In this case, another problem appears - no types . We do not know what we store in the 'data' field. We have to declare it as a text field. When I create my device for the Internet of things, I know what kind of sensor it is and, accordingly, the type, but if I need to store someone else’s data in the same table, I won’t know what data is being collected.
You can store many tables, but creating one whole new table for each sensor is not very good.
What can be done? - Use JSON.
MySQL data storage: JSON
The good news is that in MySQL 5.7 you can store JSON as a field.
Before MySQL 5.7 appeared, people also stored JSON, but as a text field. The JSON field in MySQL allows you to store JSON itself most efficiently. In addition, based on JSON, you can create virtual columns and indexes based on them.
The only small problem is that during storage the table will increase in size . But then we get much more flexibility.
A JSON field is better for storing JSON than a text field, because:
To store data in JSON, we can simply use SQL: make an INSERT, put 'data' there and get the data from the device.
Demo
For demonstration ( here its beginning on video) an example the virtual machine in which is SQL is used.

Below is a fragment of the program.
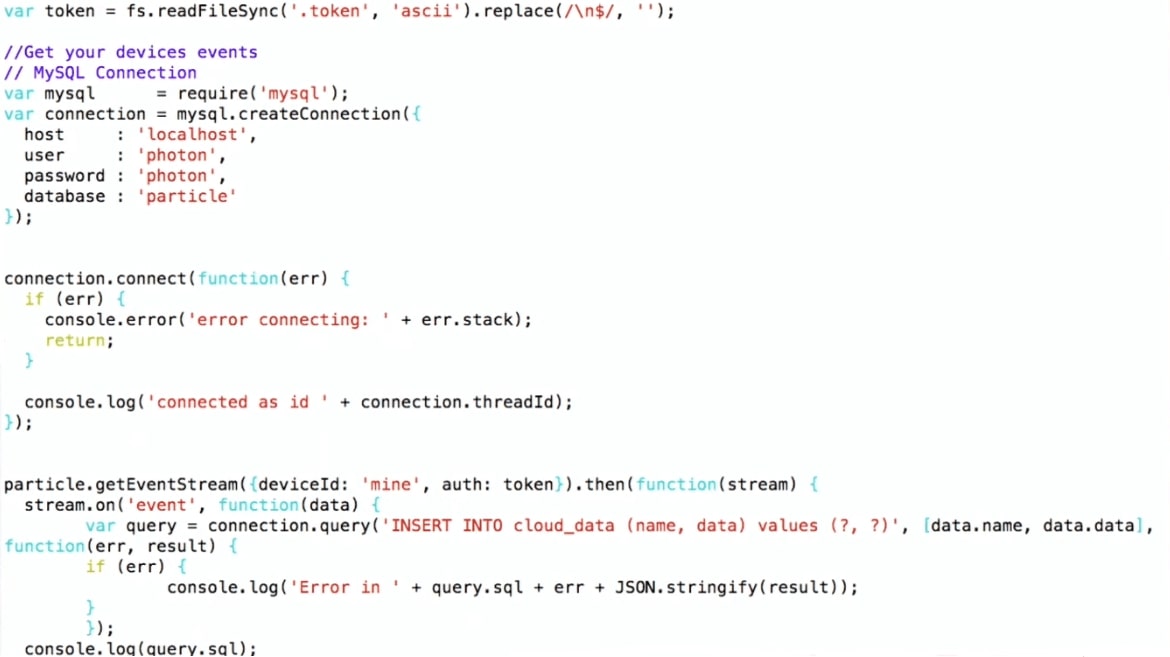
I do
As it turned out, with the help of this cloud you can get access not only to the data of my device, but in general to all the data that this Particle uses. It seems to be working so far. People who use Particle Photon all over the world are sending some kind of information: a garage door is open, or something like that, or something else. It is not known where these devices are located, but such data can be obtained. The only difference is that when I receive my data, I write something like:
When you run the code, we get a stream of some data from someone else's devices that do something.
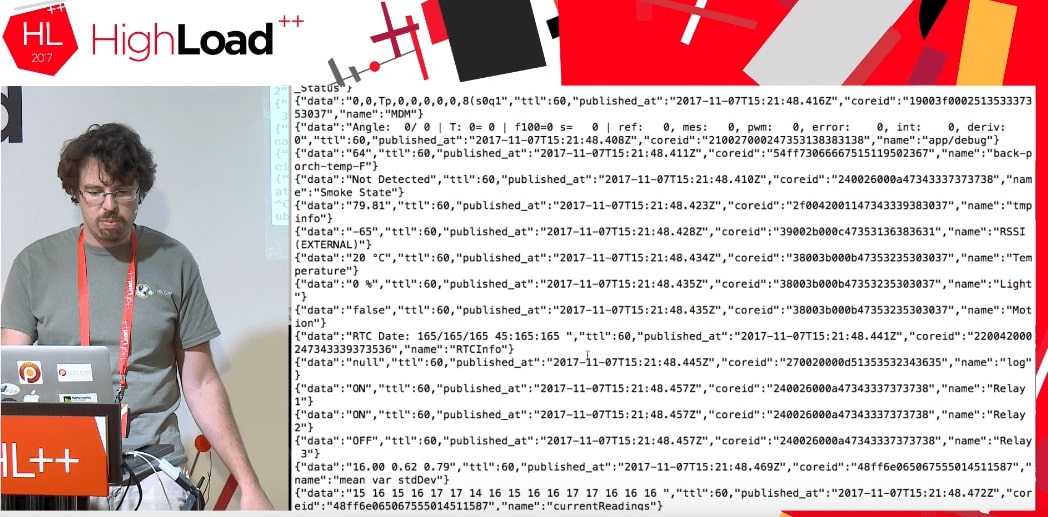
We do not know at all what this data is: TTL, published_at, coreid, door status (relay open), relay on.
This is a great example. Suppose I try to put this in MySQL into a normal data structure. I have to know what is behind the door, why it is open and what parameters it can even take. If I have JSON, then I write it directly to MySQL as a JSON field.
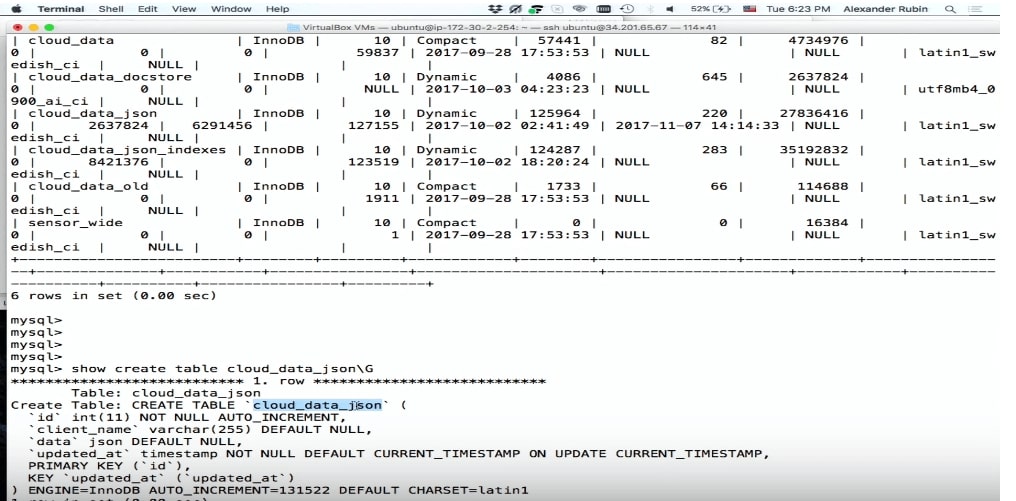
Please, everything is recorded.
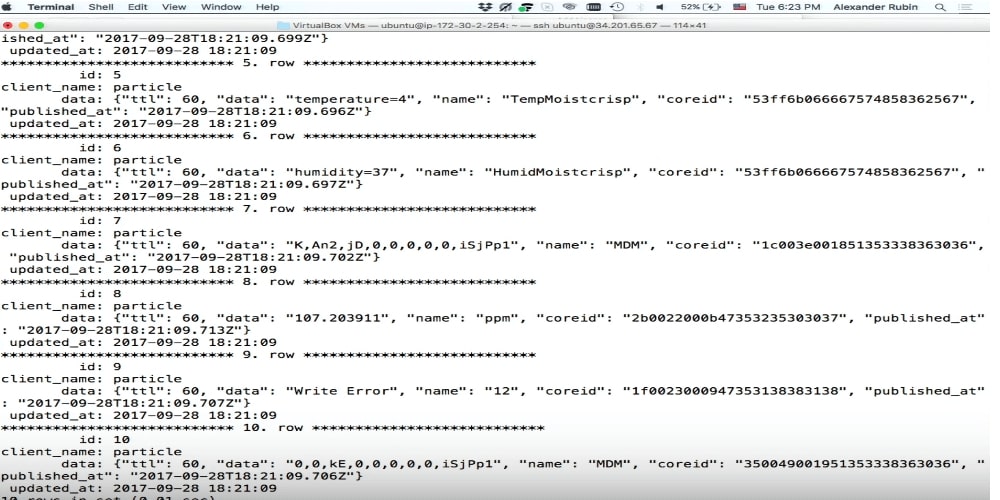
Document store
The Document store is an attempt in MySQL to make storage for JSON. I love SQL, I know it well, I can do any SQL query, etc. But many people do not like SQL for various reasons, and the Document store can be a solution for them, because with its help you can abstract from SQL, connect to MySQL and write JSON directly there.

There is another possibility that appeared in MySQL 5.7: to use another protocol, another port, another driver is also needed. For Node.js (in fact, for any programming languages - PHP, Java, etc.), we connect to MySQL using a different protocol and can transfer data in JSON format. Again, I don’t know if I have JSON in it - information about doors or something else, I just dump the data in MySQL, and then we'll figure it out later.
If you want to experiment with this, you can configure MySQL 5.7 to understand and listen on the appropriate port of the Document store or X DevAPI. I used connector-nodejs.
This is an example of what I write down there: beer, etc. I absolutely do not know what is there. Now just write, and analyze later.

The next item on our program is how to see what is there?
MySQL data storage: JSON + indexes
JSON and MySQL 5.7 have a great feature that can pull fields from JSON. This is such a syntactic sugar on the JSON_EXTRACT function. I think it is very convenient.
Data in our case is the name of the column in which JSON is stored, and name is our field. Name, data, published_at is all we can pull out this way.
In this example, I want to see what I have recorded in the MySQL table, and the last 10 entries. I make such a request and try to fulfill it. Unfortunately, this will work for a very long time .
Logically, MySQL will not use any indexes in this case. We pull data from JSON and try to apply some sort of filters and sorting. In this case, we get Using filesort.
Using filesort is very bad, this is external sorting.
The good news is that you can take 2 steps to speed it up.
Step 1. Creating a virtual column
I do EXTRACT, that is, I pull data from JSON and on its basis create a virtual column. Virtual column in MySQL 5.7 and in MySQL 8 is not stored - it is just an opportunity to create a separate column.
You ask how so, you said that ALTER TABLE is such a long operation. But everything is not so bad. Creating a virtual column is fast . There is lok, but in fact, MySQL has a lock on all DDL operations. ALTER TABLE is a fairly fast operation, and it does not rebuild the entire table.
We have created a virtual column here. I had to convert the date, because in JSON it is stored in the iso format, and here MySQL uses a completely different format. To create a column, I called her, gave her a type and said that I would write there.
To optimize the original query, you need to pull out the published_at and name. Published_at is already there, name is easier - just make a virtual column.
Step 2. Create an index
In the code below, I create an index on published_at and execute the query:
You can see that MySQL actually uses an index. This is order by optimization. In this example, data and name are not indexed. MySQL uses order by data, and since we have an index on published_at, it uses it.
Moreover, I could use the same syntax sugar
There is actually a little problem with this. Suppose I want to sort the data not only by published_at, but also by name.
If your device processes tens of thousands of events per second, published_at will not give a good sort, since there will be duplicates. Therefore, we add another sort by data_name. This is a typical request not only for the Internet of things: give me the last 10 events, but sort them by date, and then, for example, by the person's last name in ascending order. For this, there are two fields in the example above and two sort keys are specified: descending and ascending.
First of all, in this case, MySQL will not use indexes. In this particular case, MySQL decides that a full table scan will be more profitable than using an index, and again the very slow filesort operation is used.
New in MySQL 8.0
descending / ascending
In MySQL 5.7, such a query cannot be optimized, if only at the expense of other things. MySQL 8 has a real ability to specify sorting for each field.
The most interesting thing is that the descending / ascending key after the index name has long been in SQL. Even in the very first version of MySQL 3.23, it was possible to specify published_at descending or published_at ascending. MySQL took it, but did nothing , that is, it always sorted in one direction.
In MySQL 8, this is corrected and now there is such a feature. You can create a field with descending sorting and default sorting.
Let's go back a second and look at the example from step 2 again.
Why does this work, but not? This works because in MySQL indexes are B-tree, and B-tree indexes can be read from the beginning and from the end. In this case, MySQL reads the index from the end and everything is fine. But if we do descending and ascending, then it is impossible to read. You can read in one order, but you cannot combine two sortings - you need to re-sort.
Since we are optimizing a very specific case, we can create an index for it and specify a specific sorting: here published_at is descending, data_name is ascending. MySQL uses this index, and everything will be fine and fast.
This is a feature of MySQL 8, which is now, at the time of publication, already available and ready for use in production.
Output Results
There are two interesting things I want to show:
1. Pretty print, that is, a beautiful display of data on the screen. In normal SELECT, JSON will not be formatted.
2. You can tell MySQL to output the result as a JSON array or JSON object, specify the fields, and then the output will be formatted as JSON.
Full text search inside JSON documents
If we use a flexible storage system and do not know what is inside our JSON, then it would be logical to use full-text search.
Unfortunately, full-text search has its limitations . The first thing I tried was just to create a full-text key. I tried to do this thing:
Unfortunately, this does not work. Even in MySQL 8, creating a full-text index just across the JSON field is unfortunately impossible. I would certainly like to have such a function - the ability to search at least by JSON keys would be very useful.
But if this is not yet possible, let's create a virtual column. In our case, there is a data field, and it would be interesting for us to see what is inside.
Unfortunately, this also does not work - you cannot create a full-text index on a virtual column .
If so, let's create a stored column. MySQL 5.7 allows you to declare a column as a stored field.
In the previous examples, we created virtual columns that are not stored, but indexes are created and stored. In this case, I had to tell MySQL that this is a STORED column, that is, it will be created and the data in it will be copied. After that, MySQL created a full-text index, for this it was necessary to recreate the table. But this restriction is actually InnoDB and InnoDB fulltext search: you have to recreate the table to add a special full-text search identifier.
Interestingly, MySQL 8 has a new UTF8 MB4 encoding for emoticons . Of course, not quite for them, but because UTF8MB3 has some problems with Russian, Chinese, Japanese and other languages.
Accordingly, MySQL 8 should store JSON data in UTF8MB4. But either due to the fact that Node.js connects to the Device Cloud, and something is wrong there, or it is a beta version, this did not happen. Therefore, I had to convert the data before writing it to the stored column.
After that, I was able to create a full-text search on two fields: on the JSON name and on the JSON data.
Not only iot
JSON is not only the Internet of things. It can be used for other interesting pieces:
Some things can be much more conveniently implemented using a flexible data storage scheme. At Oracle OpenWorld, a great example was cited: reservations in the cinema. Implementing this in the relational model is very difficult - you get a lot of dependent tables, joins, etc. On the other hand, we can store the entire room as a JSON structure, respectively, write it in MySQL to other tables and use it in the usual way: create indexes based on JSON, etc. Complex structures are conveniently stored in JSON format.

This is a tree that has been planted successfully. Unfortunately, after a few years deer ate it, but that's another story.
Prehistory
It all started with a simple desire to plant a fruit tree on your site. It would seem very simple to do this - you come to the store and buy a sapling. But in America, the first question asked by vendors is how much wood will sunlight get. For Alexander, this turned out to be a giant mystery - it is completely unknown how much sunlight there is on the site.
')
To find out, a schoolboy could go out into the yard every day, watch how much sunlight there was, and write it in a notebook. But this is not the case - everything must be equipped with equipment and automated.
During the presentation, many examples were launched and reproduced on the air. Want a more complete picture than in the text, switch to watching videos.
So, in order not to record weather observations in a notebook, there are a large number of devices for Internet things - Raspberry Pi, the new Raspberry Pi, Arduino - thousands of different platforms. But I chose a device for this project called Particle Photon . It is very easy to use, it costs $ 19 on the official site.
In Particle Photon, it's good that it is:
- 100% cloud solution;
- Any sensors are suitable, for example, for Arduino. They all cost less than a dollar.
I made such a device and put it in the grass on the site. It has a Particle Device Cloud and a console. This device connects via Wi-Fi hotspot and sends data: light, temperature and humidity. Priborchik lasted 24 hours on a small battery, which is quite good.
Next, I need to not only measure the light and so on and transfer them to the phone (which is really good - I can see in real time what kind of light I have), but also store the data . For this, naturally, as a veteran of MySQL, I chose MySQL.
How we write data to mysql
I chose a rather complicated scheme:
- get data from the Particle console;
- I use Node.js to write them in MySQL.
I am using the Particle JS API, which can be downloaded from the Particle website. I establish a connection with MySQL and write it down, that is, I just do INSERT INTO values. Such is the pipeline.
Thus, the device lies in the courtyard, connects via Wi-Fi to a home router and using the MQTT protocol transfers data to Particle. Next is the same scheme: a virtual machine runs a program on Node.js, which receives data from Particle and writes it to MySQL.
To begin with, I built graphs from raw data in R. The graphs show that the temperature and the illumination rise during the day, fall to the night, and the humidity rises - this is natural. But there is also noise on the graph, which is typical of Internet of things devices. For example, when a bug got into the device and closed it, the sensor can transmit completely irrelevant data. This will be important for further consideration.
Now let's talk about MySQL and JSON, what has changed in working with JSON from MySQL 5.7 in MySQL 8. Then I will show the demo for which I use MySQL 8 (at the time of the report this version was not yet ready for production, now a stable release has been released).
MySQL data storage
When we try to store the data received from the sensors, our first thought is to create a table in MySQL :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB Here for each sensor and for each data type there is a column: light, temperature, humidity.
This is quite logical, but there is a problem - it is not flexible . Suppose we want to add another sensor and measure something else. For example, some people measure the remainder of a beer in a keg. What to do in this case?
alter table sensor_wide add water level double ...; How to pervert, to add something to the table? You need to make an alter table, but if you have done an alter table in MySQL, then you know what I'm talking about - this is absolutely not easy. Alter table in MySQL 8 and in MariaDB is much easier to implement, but historically this is a big problem. So if we need to add a column, for example, with the name of the beer, it will not be so easy.
Again, sensors appear, disappear, what do we do with the old data? For example, we stop receiving information about the light. Or are we creating a new column - how to store something that was not there before? The standard approach is null, but for analysis it will not be very convenient.
Another option is the key / value store.
Data storage in MySQL: key / value
It will be more flexible : in key / value there will be a name, for example, temperature and accordingly data.
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB In this case, another problem appears - no types . We do not know what we store in the 'data' field. We have to declare it as a text field. When I create my device for the Internet of things, I know what kind of sensor it is and, accordingly, the type, but if I need to store someone else’s data in the same table, I won’t know what data is being collected.
You can store many tables, but creating one whole new table for each sensor is not very good.
What can be done? - Use JSON.
MySQL data storage: JSON
The good news is that in MySQL 5.7 you can store JSON as a field.
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB; Before MySQL 5.7 appeared, people also stored JSON, but as a text field. The JSON field in MySQL allows you to store JSON itself most efficiently. In addition, based on JSON, you can create virtual columns and indexes based on them.
The only small problem is that during storage the table will increase in size . But then we get much more flexibility.
A JSON field is better for storing JSON than a text field, because:
- Provides automatic document validation . That is, if we try to write something not valid there, an error will occur.
- This is an optimized storage format . JSON is stored in a binary format, which allows you to move from one JSON document to another - something called skip.
To store data in JSON, we can simply use SQL: make an INSERT, put 'data' there and get the data from the device.
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo) Demo
For demonstration ( here its beginning on video) an example the virtual machine in which is SQL is used.
Below is a fragment of the program.
I do
INSERT INTO cloud_data (name, data) , I get the data already in JSON format, and I can directly write it to MySQL, as it is, without thinking about what is inside there.As it turned out, with the help of this cloud you can get access not only to the data of my device, but in general to all the data that this Particle uses. It seems to be working so far. People who use Particle Photon all over the world are sending some kind of information: a garage door is open, or something like that, or something else. It is not known where these devices are located, but such data can be obtained. The only difference is that when I receive my data, I write something like:
deviceId: 'mine' .When you run the code, we get a stream of some data from someone else's devices that do something.
We do not know at all what this data is: TTL, published_at, coreid, door status (relay open), relay on.
This is a great example. Suppose I try to put this in MySQL into a normal data structure. I have to know what is behind the door, why it is open and what parameters it can even take. If I have JSON, then I write it directly to MySQL as a JSON field.
Please, everything is recorded.
Document store
The Document store is an attempt in MySQL to make storage for JSON. I love SQL, I know it well, I can do any SQL query, etc. But many people do not like SQL for various reasons, and the Document store can be a solution for them, because with its help you can abstract from SQL, connect to MySQL and write JSON directly there.
There is another possibility that appeared in MySQL 5.7: to use another protocol, another port, another driver is also needed. For Node.js (in fact, for any programming languages - PHP, Java, etc.), we connect to MySQL using a different protocol and can transfer data in JSON format. Again, I don’t know if I have JSON in it - information about doors or something else, I just dump the data in MySQL, and then we'll figure it out later.
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https://dev.mysql.com/doc/dev/connector-nodejs/ If you want to experiment with this, you can configure MySQL 5.7 to understand and listen on the appropriate port of the Document store or X DevAPI. I used connector-nodejs.
This is an example of what I write down there: beer, etc. I absolutely do not know what is there. Now just write, and analyze later.
The next item on our program is how to see what is there?
MySQL data storage: JSON + indexes
JSON and MySQL 5.7 have a great feature that can pull fields from JSON. This is such a syntactic sugar on the JSON_EXTRACT function. I think it is very convenient.
Data in our case is the name of the column in which JSON is stored, and name is our field. Name, data, published_at is all we can pull out this way.
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10; In this example, I want to see what I have recorded in the MySQL table, and the last 10 entries. I make such a request and try to fulfill it. Unfortunately, this will work for a very long time .
Logically, MySQL will not use any indexes in this case. We pull data from JSON and try to apply some sort of filters and sorting. In this case, we get Using filesort.
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort Using filesort is very bad, this is external sorting.
The good news is that you can take 2 steps to speed it up.
Step 1. Creating a virtual column
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 I do EXTRACT, that is, I pull data from JSON and on its basis create a virtual column. Virtual column in MySQL 5.7 and in MySQL 8 is not stored - it is just an opportunity to create a separate column.
You ask how so, you said that ALTER TABLE is such a long operation. But everything is not so bad. Creating a virtual column is fast . There is lok, but in fact, MySQL has a lock on all DDL operations. ALTER TABLE is a fairly fast operation, and it does not rebuild the entire table.
We have created a virtual column here. I had to convert the date, because in JSON it is stored in the iso format, and here MySQL uses a completely different format. To create a column, I called her, gave her a type and said that I would write there.
To optimize the original query, you need to pull out the published_at and name. Published_at is already there, name is easier - just make a virtual column.
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 Step 2. Create an index
In the code below, I create an index on published_at and execute the query:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan You can see that MySQL actually uses an index. This is order by optimization. In this example, data and name are not indexed. MySQL uses order by data, and since we have an index on published_at, it uses it.
Moreover, I could use the same syntax sugar
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") in order by instead of published_at. MySQL would still understand that there is an index on this column and would start using it.There is actually a little problem with this. Suppose I want to sort the data not only by published_at, but also by name.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort If your device processes tens of thousands of events per second, published_at will not give a good sort, since there will be duplicates. Therefore, we add another sort by data_name. This is a typical request not only for the Internet of things: give me the last 10 events, but sort them by date, and then, for example, by the person's last name in ascending order. For this, there are two fields in the example above and two sort keys are specified: descending and ascending.
First of all, in this case, MySQL will not use indexes. In this particular case, MySQL decides that a full table scan will be more profitable than using an index, and again the very slow filesort operation is used.
New in MySQL 8.0
descending / ascending
In MySQL 5.7, such a query cannot be optimized, if only at the expense of other things. MySQL 8 has a real ability to specify sorting for each field.
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0 The most interesting thing is that the descending / ascending key after the index name has long been in SQL. Even in the very first version of MySQL 3.23, it was possible to specify published_at descending or published_at ascending. MySQL took it, but did nothing , that is, it always sorted in one direction.
In MySQL 8, this is corrected and now there is such a feature. You can create a field with descending sorting and default sorting.
Let's go back a second and look at the example from step 2 again.
Why does this work, but not? This works because in MySQL indexes are B-tree, and B-tree indexes can be read from the beginning and from the end. In this case, MySQL reads the index from the end and everything is fine. But if we do descending and ascending, then it is impossible to read. You can read in one order, but you cannot combine two sortings - you need to re-sort.
Since we are optimizing a very specific case, we can create an index for it and specify a specific sorting: here published_at is descending, data_name is ascending. MySQL uses this index, and everything will be fine and fast.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL This is a feature of MySQL 8, which is now, at the time of publication, already available and ready for use in production.
Output Results
There are two interesting things I want to show:
1. Pretty print, that is, a beautiful display of data on the screen. In normal SELECT, JSON will not be formatted.
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" } 2. You can tell MySQL to output the result as a JSON array or JSON object, specify the fields, and then the output will be formatted as JSON.
Full text search inside JSON documents
If we use a flexible storage system and do not know what is inside our JSON, then it would be logical to use full-text search.
Unfortunately, full-text search has its limitations . The first thing I tried was just to create a full-text key. I tried to do this thing:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path. Unfortunately, this does not work. Even in MySQL 8, creating a full-text index just across the JSON field is unfortunately impossible. I would certainly like to have such a function - the ability to search at least by JSON keys would be very useful.
But if this is not yet possible, let's create a virtual column. In our case, there is a data field, and it would be interesting for us to see what is inside.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns. Unfortunately, this also does not work - you cannot create a full-text index on a virtual column .
If so, let's create a stored column. MySQL 5.7 allows you to declare a column as a stored field.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +------------+--------+---------------------------------------------------+ | Level | Code | Message | +------------+--------+---------------------------------------------------+ | Warning | 124 | InnoDB rebuilding table to add column FTS_DOC_ID | +------------+--------+---------------------------------------------------+ In the previous examples, we created virtual columns that are not stored, but indexes are created and stored. In this case, I had to tell MySQL that this is a STORED column, that is, it will be created and the data in it will be copied. After that, MySQL created a full-text index, for this it was necessary to recreate the table. But this restriction is actually InnoDB and InnoDB fulltext search: you have to recreate the table to add a special full-text search identifier.
Interestingly, MySQL 8 has a new UTF8 MB4 encoding for emoticons . Of course, not quite for them, but because UTF8MB3 has some problems with Russian, Chinese, Japanese and other languages.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0 Accordingly, MySQL 8 should store JSON data in UTF8MB4. But either due to the fact that Node.js connects to the Device Cloud, and something is wrong there, or it is a beta version, this did not happen. Therefore, I had to convert the data before writing it to the stored column.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0 After that, I was able to create a full-text search on two fields: on the JSON name and on the JSON data.
Not only iot
JSON is not only the Internet of things. It can be used for other interesting pieces:
- Custom fields (CMS);
- Complex structures, etc .;
Some things can be much more conveniently implemented using a flexible data storage scheme. At Oracle OpenWorld, a great example was cited: reservations in the cinema. Implementing this in the relational model is very difficult - you get a lot of dependent tables, joins, etc. On the other hand, we can store the entire room as a JSON structure, respectively, write it in MySQL to other tables and use it in the usual way: create indexes based on JSON, etc. Complex structures are conveniently stored in JSON format.
This is a tree that has been planted successfully. Unfortunately, after a few years deer ate it, but that's another story.
This report is an excellent example of how from one topic at a large conference, a whole section grows, and then a separate event. In the case of the Internet of Things, we got InoThings ++ - a conference for professionals of the Internet of Things market, which will be held for the second time on April 4.
The central event of the conference seems to be the round table “Do we need national standards on the Internet of Things?”, Which will organically complement the comprehensive application reports . Come, if your highly loaded systems are moving right to IIoT.
Source: https://habr.com/ru/post/443422/
All Articles