Top 20 errors when working with multithreading in C ++ and ways to avoid them
Hi, Habr! I bring to your attention a translation of the article “Top 20 C ++ multithreading mistakes” by Deb Haldar.
”")
Scene from the movie "The loop of time" (2012)
Multithreading is one of the most difficult areas in programming, especially in C ++. Over the years of development I have made many mistakes. Fortunately, most of them have been identified on code review and testing. Nonetheless, some somehow skipped over to the productive, and we had to rule the exploited systems, which is always expensive.
')
In this article I tried to categorize all the errors that I know with possible solutions. If you know any other pitfalls, or have suggestions for solving the described errors, please leave your comments below the article.
If you forget to join a stream ( join () ) or detach it ( detach () ) (make it not joinable) before the end of the program, this will lead to an abnormal termination. (Translated words will be joined in the context of join () and detached in the context of detach () , although this is not entirely correct. In fact, join () is the point at which one thread of execution waits until the end of the other, and no connection or union of threads occurs. [comment of the translator]).
In the example below, we forgot to join () the t1 stream in the main thread:
Why did the program crash ?! Because at the end of the main () function, the variable t1 went out of scope and the thread destructor was called. The destructor checks whether the stream t1 is joinable . A thread is joinable if it has not been detached. In this case, std :: terminate is called in its destructor. This is what the MSVC ++ compiler does, for example.
There are two ways to fix the problem depending on the task:
1. Call join () of stream t1 in the main thread:
2. Detach the stream t1 from the main stream, allow it to continue working as a “demonized” stream:
If at some point in the program you have a detachable flow, you cannot attach it back to the main flow. This is a very obvious mistake. The problem is that you can unpin the stream, and then write a few hundred lines of code and try to reattach it. After all, who remembers that he wrote 300 lines back, right?
The problem is that it will not cause a compilation error; instead, the program will crash at startup. For example:
The solution is to always check the joinable () flow before attempting to attach it to the calling thread.
In real-world applications, you may often need to allocate “long-playing” operations for processing network I / O or waiting for a user to press a button, etc., into a separate thread. A call to join () for such worker threads (for example, a UI draw thread) can cause the user interface to hang. There are more suitable ways of implementation.
For example, in a GUI application, a workflow can send a UI message to a thread when completed. The UI thread has its own event loop, such as: moving the mouse, pressing keys, etc. This loop can also receive messages from worker threads and respond to them without the need to call the join () blocking method.
For this very reason, almost all user interactions are asynchronous in the Microsoft WinRT platform, and synchronous alternatives are not available. These decisions were made to ensure that developers use an API that provides the best use experience for end users. You can refer to the " Modern C ++ and Windows Store Apps " manual for more information on this topic.
The arguments to the stream function are by default passed by value. If you need to make changes to the passed arguments, you must pass them by reference using the function std :: ref () .
Under the spoiler, examples from another C ++ 11 article Multithreading Tutorial via Q & A - Thread Management Basics (Deb Haldar) , illustrating the transfer of parameters [approx. translator].
In a multithreaded environment, usually more than one stream competes for resources and shared data. Often this leads to an undefined state for resources and data, except when access to them is protected by some mechanism that allows only one execution thread to perform operations on them at a time.
In the example below, std :: cout is a shared resource with which 6 threads work (t1-t5 + main).
If we execute this program, we get the output:
This is because five threads simultaneously access the output stream in a random order. To make the output more specific, you need to protect access to the shared resource with std :: mutex . Simply change the CallHome () function so that it captures the mutex before using std :: cout and releases it after.
In the previous paragraph, you saw how to protect the critical section with a mutex. However, calling the lock () and unlock () methods directly on the mutex is not the preferred option because you may forget to release the lock that is being held. What happens next? All other threads that are waiting for the resource to be released will be blocked indefinitely and the program may hang.
In our synthetic example, if you forgot to unblock the mutex in the call to the CallHome () function, the first message from the t1 stream will be output to the standard stream and the program will hang. This is due to the fact that the t1 thread has received a mutex lock, while the remaining threads are waiting for this lock to be released.
Below is the output of this code - the program is frozen, outputting a single message to the terminal, and does not end:
Such errors often occur, which is why it is undesirable to use the lock () / unlock () methods directly from the mutex. Instead, use the template class std :: lock_guard , which uses the RAII idiom to control the lock lifetime. When the lock_guard object is created, it tries to take over the mutex. When the program goes out of the lock_guard object, the destructor is called, which frees the mutex.
Rewrite the CallHome () function using the object's std :: lock_guard :
When one thread runs inside the critical section, all others trying to enter it are essentially blocked. We need to keep the minimum number of instructions in the critical section as possible. For illustration, here is an example of a bad code with a large critical section:
The ReadFifyThousandRecords () method does not modify the data. There is no reason to do it under lock. If this method is executed for 10 seconds, reading 50 thousand lines from the database, all other threads will be blocked for the entire period without any need. This can seriously affect the performance of the program.
The correct solution would be to keep only std :: cout in the critical section.
This is one of the most common causes of deadlock , a situation in which threads end up endlessly blocked due to waiting for access to resources blocked by other threads. Consider an example:
There may be a situation in which stream 1 will try to seize lock B and will be blocked, because stream 2 has already captured it. At the same time, the second thread tries to capture lock A, but cannot do this, because it was captured by the first thread. Thread 1 cannot release lock A until it locks lock B, etc. In other words, the program will freeze.
This code example will help you reproduce the deadlock :
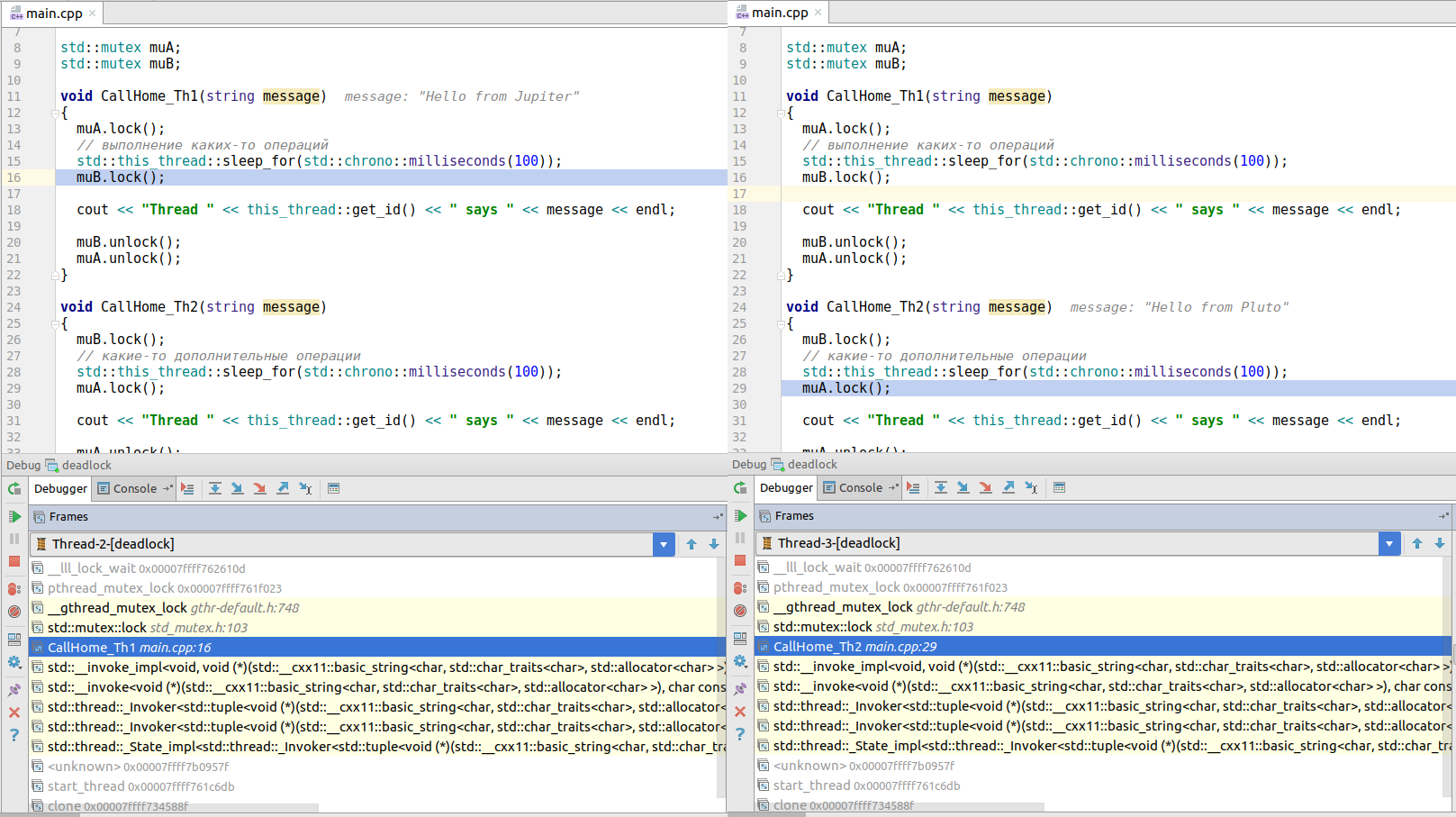
If you run this code, it will hang. If you go deeper into the debugger in the threads window, you will see that the first thread (called from CallHome_Th1 () ) is trying to get a mutex B lock, while thread 2 (called from CallHome_Th2 () ) is trying to block mutex A. None of the threads can not achieve success, which leads to a mutual blocking!
(the picture is clickable)
What can you do about it? The best solution would be to restructure the code in such a way that the lock is locked every time in the same order.
Depending on the situation, you can use other strategies:
1. Use the wrapper class std :: scoped_lock to jointly capture multiple locks:
2. Use the class std :: timed_mutex , in which you can specify a timeout after which the lock will be released if the resource is not available.
Attempting to lock the lock twice will result in unspecified behavior. In most debugging implementations, this will lead to crashing. For example, in the code below, LaunchRocket () will block the mutex and then call StartThruster () . What is curious is that in the above code you will not encounter this problem during normal program operation; a problem occurs only when an exception is thrown, which is accompanied by indefinite behavior or the program crash.
To eliminate this problem, you need to correct the code in such a way as to exclude the re-taking of previously obtained locks. You can use std :: recursive_mutex as a crutch solution, but this solution almost always indicates a bad program architecture.
When you need to change simple data types, such as a boolean value or an integer counter, using std: atomic will usually give you better performance than using mutexes.
For example, instead of using the following construct:
It is better to declare a variable as std :: atomic :
For a detailed comparison of mutex and atomic, see the article “Comparison: Lockless programming with atomics in C ++ 11 vs. mutex and RW-locks »
Creating and destroying threads is a costly operation in terms of CPU time. Imagine an attempt to create a stream while the system performs resource-intensive computational operations, for example, drawing graphics or calculating game physics. An approach often used for such tasks is to create a pool of pre-allocated threads that can handle routine tasks, such as writing to disk or sending data over the network during the entire life cycle of a process.
Another advantage of the thread pool, compared to spawning and destroying threads yourself, is that you do not need to worry about thread oversubscription (a situation in which the number of threads exceeds the number of available cores and much of the processor time is spent on context switching [approx. translator]). This may affect system performance.
In addition, the use of the pool saves us from the torments of managing the life cycle of threads, which ultimately results in a more compact code with fewer errors.
The two most popular libraries that implement thread pools are: Intel Thread Building Blocks (TBB) and Microsoft Parallel Patterns Library (PPL) .
Exceptions thrown in one stream cannot be processed in another stream. Let's imagine that we have a function that throws an exception. If we execute this function in a separate thread, branched from the main thread of execution, and expect that we will catch any exception thrown from the additional thread, this will not work. Consider an example:
When executing this program, a crash will occur, however, the catch block in main () will not execute and will not handle the exception thrown in stream t1.
The solution to this problem is to use the opportunity from C ++ 11: std :: exception_ptr is used to handle the exception thrown in the background thread. Here are the steps you need to take:
The exception is recalled by reference not in the thread in which it was created, so this feature is great for handling exceptions in different threads.
The code below achieves safe handling of the exception thrown in the background thread.
If you need the code to run asynchronously, i.e. without locking the main thread, the best choice would be to use std :: async () . This is equivalent to creating a stream and passing the necessary code to be executed into this stream via a pointer to a function or parameter in the form of a lambda function. However, in the latter case, you need to monitor the creation, attachment / detachment of this stream, as well as the handling of all exceptions that may occur in this stream. If you use std :: async () , you save yourself from these problems, and also sharply reduce your chances of getting into the deadlock .
Another significant advantage of using std :: async is the ability to get the result of an asynchronous operation back to the calling thread using the std :: future object. Imagine that we have a ConjureMagic () function that returns an int. We can start an asynchronous operation that will set the value in the future in the future object when the task is completed, and we can extract the result of the execution from this object in the execution flow from which the operation was called.
Getting the result back from the running thread to the caller is more cumbersome. Two ways are possible:
Kurt Guntheroth found that in terms of performance, the overhead of creating a thread is 14 times more than using async .
Bottom line: use std :: async () by default until you find strong arguments for using std :: thread directly.
The std :: async () function is not quite the correct name, because by default it may not be executed asynchronously!
There are two std :: async execution policies:
When we call std :: async () with default parameters, it starts up with a combination of these two parameters, which in fact leads to unpredictable behavior. There are a number of other difficulties associated with using std: async () with a default startup policy:
To avoid all these difficulties, always call std :: async with the launch policy std :: launch :: async .
Do not do this:
Instead, do this:
In more detail this moment is considered in Scott Meyers' book Effective and Modern C ++.
The code below handles the result obtained from the std :: future object of the asynchronous operation. However, the while loop will be blocked until an asynchronous operation is completed (in this case for 10 seconds). If you want to use this loop to display information on the screen, this can lead to unpleasant user interface rendering delays.
Note : Another problem with the above code is that it tries to access the std :: future object a second time, although the state of the object's std :: future was retrieved on the first iteration of the loop and cannot be re-received.
The correct solution would be to check the validity of the object's std :: future before calling the get () method. Thus, we do not block the completion of an asynchronous task and do not try to re-interrogate an already retrieved std :: future object.
This code snippet allows you to achieve this:
Imagine that we have the following code snippet, what do you think will be the result of a call to std :: future :: get () ? If you assume that the program will fall - you are absolutely right! The exception thrown in an asynchronous operation is thrown only when the get () method is invoked on the std :: future object . And if the get () method is not called, the exception will be ignored and thrown when the std :: future object goes out of scope. If your asynchronous operation can throw an exception, then you should always wrap the call to std :: future :: get () in the try / catch block. An example of how this might look like:
Although std :: async () is sufficient in most cases, there are situations in which you may need careful control over the execution of your code in the stream. For example, if you want to bind a specific thread to a specific processor core in a multiprocessor system (for example, Xbox).
The above code fragment sets the thread binding to the 5th processor core in the system. This is possible thanks to the native_handle () method of the std :: thread object , and passing it to the Win32 API threading function . There are many other features provided through the Win32 streaming API that are not available in std :: thread or std :: async () . When working through
std :: async () these basic platform functions are not available, which makes this method unsuitable for more complex tasks.
Alternatively, create std :: packaged_task and move it to the desired execution thread after setting the properties of the flow.
From an architectural point of view, streams can be classified into two groups: “running” and “waiting”.
Running threads recycle 100% of the kernel time on which they are running. When more than one running thread is allocated per core, processor utilization efficiency drops. We do not get performance gains if we run more than one running thread on a single processor core — in fact, performance drops due to additional context switches.
Waiting threads recycle only a few clock ticks on which they run while waiting for system events or network I / O, etc. In this case, most of the available processor time of the kernel remains unused. One waiting thread can process data, while the others wait for events to trigger — which is why it is advantageous to distribute several waiting threads to one core. Planning multiple waiting threads per core can provide much better program performance.
So, how to understand how many threads the system supports? Use the std :: thread :: hardware_concurrency () method . This function usually returns the number of processor cores, but takes into account cores that behave like two or more logical cores due tohyper-trading .
You must use the resulting value of the target platform to plan the maximum number of concurrently running threads of your program. You can also assign one core for all pending threads, and use the remaining number of cores for the threads that are running. For example, in a quad-core system, use one core for ALL pending threads, and for the other three cores - three running threads. Depending on the performance of your thread scheduler, some of your executable threads may switch context (due to page access failures, etc.), leaving the kernel inactive for some time. If you observe this situation during profiling, you should create a slightly larger number of threads to execute than the number of cores and adjust this value for your system.
The volatile keyword before specifying the type of a variable does not make operations with this variable atomic or thread-safe. What you probably want is std :: atomic .
See the discussion on stackoverflow for details.
In complexity, there is something that every engineer likes. Creating programs that work without locks (lock free) sounds very tempting compared to conventional synchronization mechanisms such as mutex, condition variables, asynchrony, etc. However, every experienced C ++ developer I spoke with adhered to that the use of non-blocking programming as a source is a type of premature optimization that can go sideways at the most inopportune moment (think of a malfunction in the operating system when you do not have a full heap dump!)
In my career in C ++, there was only one situation that required unlocked code execution, because we worked in a system with limited resources, where each transaction in our component should take no more than 10 microseconds.
Before you think about using a non-blocking approach, please answer three questions:
Summarizing, for normal application development, please consider programming without blocking only when you have exhausted all other alternatives. Another way to look at this is that if you are still making some of the above 19 errors, you should probably stay away from non-blocking programming.
[From. translator: Many thanks to the user vovo4K for help in preparing this article.]
Scene from the movie "The loop of time" (2012)
Multithreading is one of the most difficult areas in programming, especially in C ++. Over the years of development I have made many mistakes. Fortunately, most of them have been identified on code review and testing. Nonetheless, some somehow skipped over to the productive, and we had to rule the exploited systems, which is always expensive.
')
In this article I tried to categorize all the errors that I know with possible solutions. If you know any other pitfalls, or have suggestions for solving the described errors, please leave your comments below the article.
Error 1: Do not use join () to wait for background threads before terminating the application.
If you forget to join a stream ( join () ) or detach it ( detach () ) (make it not joinable) before the end of the program, this will lead to an abnormal termination. (Translated words will be joined in the context of join () and detached in the context of detach () , although this is not entirely correct. In fact, join () is the point at which one thread of execution waits until the end of the other, and no connection or union of threads occurs. [comment of the translator]).
In the example below, we forgot to join () the t1 stream in the main thread:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
//t1.join(); // join-
return 0 ;
}Why did the program crash ?! Because at the end of the main () function, the variable t1 went out of scope and the thread destructor was called. The destructor checks whether the stream t1 is joinable . A thread is joinable if it has not been detached. In this case, std :: terminate is called in its destructor. This is what the MSVC ++ compiler does, for example.
~thread ( ) _NOEXCEPT
{ // clean up
if ( joinable ( ) )
XSTD terminate ( ) ;
}
There are two ways to fix the problem depending on the task:
1. Call join () of stream t1 in the main thread:
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. join ( ) ; // join t1,
return 0 ;
}
2. Detach the stream t1 from the main stream, allow it to continue working as a “demonized” stream:
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ; // t1
return 0 ;
}Mistake number 2: Try to attach a stream that was previously detached.
If at some point in the program you have a detachable flow, you cannot attach it back to the main flow. This is a very obvious mistake. The problem is that you can unpin the stream, and then write a few hundred lines of code and try to reattach it. After all, who remembers that he wrote 300 lines back, right?
The problem is that it will not cause a compilation error; instead, the program will crash at startup. For example:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
t1. join ( ) ; // CRASH !!!
return 0 ;
}
The solution is to always check the joinable () flow before attempting to attach it to the calling thread.
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
if ( t1. joinable ( ) )
{
t1. join ( ) ;
}
return 0 ;
}
Error 3: Misunderstanding that std :: thread :: join () blocks the calling thread of execution
In real-world applications, you may often need to allocate “long-playing” operations for processing network I / O or waiting for a user to press a button, etc., into a separate thread. A call to join () for such worker threads (for example, a UI draw thread) can cause the user interface to hang. There are more suitable ways of implementation.
For example, in a GUI application, a workflow can send a UI message to a thread when completed. The UI thread has its own event loop, such as: moving the mouse, pressing keys, etc. This loop can also receive messages from worker threads and respond to them without the need to call the join () blocking method.
For this very reason, almost all user interactions are asynchronous in the Microsoft WinRT platform, and synchronous alternatives are not available. These decisions were made to ensure that developers use an API that provides the best use experience for end users. You can refer to the " Modern C ++ and Windows Store Apps " manual for more information on this topic.
Error # 4: Assume that the arguments of the stream function are passed by reference by default.
The arguments to the stream function are by default passed by value. If you need to make changes to the passed arguments, you must pass them by reference using the function std :: ref () .
Under the spoiler, examples from another C ++ 11 article Multithreading Tutorial via Q & A - Thread Management Basics (Deb Haldar) , illustrating the transfer of parameters [approx. translator].
more details:
When executing code:
It will be displayed in the terminal:
As you can see, the value of the targetCity variable received by the function called in the stream has not changed by reference.
Rewrite the code using std :: ref () to pass the argument:
It will be displayed:
Changes made in the new thread will affect the value of the targetCity variable declared and initialized in the main function.
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, targetCity ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
It will be displayed in the terminal:
Changing The Target City To Metropolis
Current Target City is Star CityAs you can see, the value of the targetCity variable received by the function called in the stream has not changed by reference.
Rewrite the code using std :: ref () to pass the argument:
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, std :: ref ( targetCity ) ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}It will be displayed:
Changing The Target City To Metropolis
Current Target City is MetropolisChanges made in the new thread will affect the value of the targetCity variable declared and initialized in the main function.
Error # 5: Do not protect shared data and resources using a critical section (for example, a mutex)
In a multithreaded environment, usually more than one stream competes for resources and shared data. Often this leads to an undefined state for resources and data, except when access to them is protected by some mechanism that allows only one execution thread to perform operations on them at a time.
In the example below, std :: cout is a shared resource with which 6 threads work (t1-t5 + main).
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex mu ;
void CallHome ( string message )
{
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
}
int main ( )
{
thread t1 ( CallHome, "Hello from Jupiter" ) ;
thread t2 ( CallHome, "Hello from Pluto" ) ;
thread t3 ( CallHome, "Hello from Moon" ) ;
CallHome ( "Hello from Main/Earth" ) ;
thread t4 ( CallHome, "Hello from Uranus" ) ;
thread t5 ( CallHome, "Hello from Neptune" ) ;
t1. join ( ) ;
t2. join ( ) ;
t3. join ( ) ;
t4. join ( ) ;
t5. join ( ) ;
return 0 ;
}
If we execute this program, we get the output:
Thread 0x1000fb5c0 says Hello from Main/Earth
Thread Thread Thread 0x700005bd20000x700005b4f000 says says Thread Thread Hello from Pluto0x700005c55000Hello from Jupiter says 0x700005d5b000Hello from Moon
0x700005cd8000 says says Hello from Uranus
Hello from Neptune
This is because five threads simultaneously access the output stream in a random order. To make the output more specific, you need to protect access to the shared resource with std :: mutex . Simply change the CallHome () function so that it captures the mutex before using std :: cout and releases it after.
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
mu. unlock ( ) ;
}Error # 6: Forget to release the lock after exiting the critical section
In the previous paragraph, you saw how to protect the critical section with a mutex. However, calling the lock () and unlock () methods directly on the mutex is not the preferred option because you may forget to release the lock that is being held. What happens next? All other threads that are waiting for the resource to be released will be blocked indefinitely and the program may hang.
In our synthetic example, if you forgot to unblock the mutex in the call to the CallHome () function, the first message from the t1 stream will be output to the standard stream and the program will hang. This is due to the fact that the t1 thread has received a mutex lock, while the remaining threads are waiting for this lock to be released.
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
//mu.unlock();
}Below is the output of this code - the program is frozen, outputting a single message to the terminal, and does not end:
Thread 0x700005986000 says Hello from Pluto
Such errors often occur, which is why it is undesirable to use the lock () / unlock () methods directly from the mutex. Instead, use the template class std :: lock_guard , which uses the RAII idiom to control the lock lifetime. When the lock_guard object is created, it tries to take over the mutex. When the program goes out of the lock_guard object, the destructor is called, which frees the mutex.
Rewrite the CallHome () function using the object's std :: lock_guard :
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; //
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guardMistake number 7: Make the size of the critical section larger than necessary.
When one thread runs inside the critical section, all others trying to enter it are essentially blocked. We need to keep the minimum number of instructions in the critical section as possible. For illustration, here is an example of a bad code with a large critical section:
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
ReadFifyThousandRecords ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard muThe ReadFifyThousandRecords () method does not modify the data. There is no reason to do it under lock. If this method is executed for 10 seconds, reading 50 thousand lines from the database, all other threads will be blocked for the entire period without any need. This can seriously affect the performance of the program.
The correct solution would be to keep only std :: cout in the critical section.
void CallHome ( string message )
{
ReadFifyThousandRecords ( ) ; // ..
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard muMistake number 8: Taking several locks in a different order.
This is one of the most common causes of deadlock , a situation in which threads end up endlessly blocked due to waiting for access to resources blocked by other threads. Consider an example:
| stream 1 | stream 2 |
|---|---|
| lock A | lock B |
| // ... some operations | // ... some operations |
| lock B | lock A |
| // ... some other operations | // ... some other operations |
| unlock B | unlock A |
| unlock A | unlock B |
There may be a situation in which stream 1 will try to seize lock B and will be blocked, because stream 2 has already captured it. At the same time, the second thread tries to capture lock A, but cannot do this, because it was captured by the first thread. Thread 1 cannot release lock A until it locks lock B, etc. In other words, the program will freeze.
This code example will help you reproduce the deadlock :
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex muA ;
std :: mutex muB ;
void CallHome_Th1 ( string message )
{
muA. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muB. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muB. unlock ( ) ;
muA. unlock ( ) ;
}
void CallHome_Th2 ( string message )
{
muB. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muA. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muA. unlock ( ) ;
muB. unlock ( ) ;
}
int main ( )
{
thread t1 ( CallHome_Th1, "Hello from Jupiter" ) ;
thread t2 ( CallHome_Th2, "Hello from Pluto" ) ;
t1. join ( ) ;
t2. join ( ) ;
return 0 ;
}If you run this code, it will hang. If you go deeper into the debugger in the threads window, you will see that the first thread (called from CallHome_Th1 () ) is trying to get a mutex B lock, while thread 2 (called from CallHome_Th2 () ) is trying to block mutex A. None of the threads can not achieve success, which leads to a mutual blocking!
(the picture is clickable)
What can you do about it? The best solution would be to restructure the code in such a way that the lock is locked every time in the same order.
Depending on the situation, you can use other strategies:
1. Use the wrapper class std :: scoped_lock to jointly capture multiple locks:
std :: scoped_lock lock { muA, muB } ;2. Use the class std :: timed_mutex , in which you can specify a timeout after which the lock will be released if the resource is not available.
std :: timed_mutex m ;
void DoSome ( ) {
std :: chrono :: milliseconds timeout ( 100 ) ;
while ( true ) {
if ( m. try_lock_for ( timeout ) ) {
std :: cout << std :: this_thread :: get_id ( ) << ": acquire mutex successfully" << std :: endl ;
m. unlock ( ) ;
} else {
std :: cout << std :: this_thread :: get_id ( ) << ": can't acquire mutex, do something else" << std :: endl ;
}
}
}Mistake 9: Trying to seize the std :: mutex lock twice.
Attempting to lock the lock twice will result in unspecified behavior. In most debugging implementations, this will lead to crashing. For example, in the code below, LaunchRocket () will block the mutex and then call StartThruster () . What is curious is that in the above code you will not encounter this problem during normal program operation; a problem occurs only when an exception is thrown, which is accompanied by indefinite behavior or the program crash.
#include "stdafx.h"
#include <iostream>
#include <thread>
#include <mutex>
std :: mutex mu ;
static int counter = 0 ;
void StartThruster ( )
{
try
{
// -
}
catch ( ... )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
std :: cout << "Launching rocket" << std :: endl ;
}
}
void LaunchRocket ( )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
counter ++ ;
StartThruster ( ) ;
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
return 0 ;
}
To eliminate this problem, you need to correct the code in such a way as to exclude the re-taking of previously obtained locks. You can use std :: recursive_mutex as a crutch solution, but this solution almost always indicates a bad program architecture.
Mistake # 10: Use mutexes when std :: atomic types are enough
When you need to change simple data types, such as a boolean value or an integer counter, using std: atomic will usually give you better performance than using mutexes.
For example, instead of using the following construct:
int counter ;
...
mu. lock ( ) ;
counter ++ ;
mu. unlock ( ) ;
It is better to declare a variable as std :: atomic :
std :: atomic < int > counter ;
...
counter ++ ;For a detailed comparison of mutex and atomic, see the article “Comparison: Lockless programming with atomics in C ++ 11 vs. mutex and RW-locks »
Mistake # 11: Create and destroy a large number of threads directly, instead of using a pool of free threads.
Creating and destroying threads is a costly operation in terms of CPU time. Imagine an attempt to create a stream while the system performs resource-intensive computational operations, for example, drawing graphics or calculating game physics. An approach often used for such tasks is to create a pool of pre-allocated threads that can handle routine tasks, such as writing to disk or sending data over the network during the entire life cycle of a process.
Another advantage of the thread pool, compared to spawning and destroying threads yourself, is that you do not need to worry about thread oversubscription (a situation in which the number of threads exceeds the number of available cores and much of the processor time is spent on context switching [approx. translator]). This may affect system performance.
In addition, the use of the pool saves us from the torments of managing the life cycle of threads, which ultimately results in a more compact code with fewer errors.
The two most popular libraries that implement thread pools are: Intel Thread Building Blocks (TBB) and Microsoft Parallel Patterns Library (PPL) .
Mistake # 12: Do not handle exceptions that occur in background threads.
Exceptions thrown in one stream cannot be processed in another stream. Let's imagine that we have a function that throws an exception. If we execute this function in a separate thread, branched from the main thread of execution, and expect that we will catch any exception thrown from the additional thread, this will not work. Consider an example:
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr teptr = nullptr ;
void LaunchRocket ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
int main ( )
{
try
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
return 0 ;
}
When executing this program, a crash will occur, however, the catch block in main () will not execute and will not handle the exception thrown in stream t1.
The solution to this problem is to use the opportunity from C ++ 11: std :: exception_ptr is used to handle the exception thrown in the background thread. Here are the steps you need to take:
- Create a global instance of the class std :: exception_ptr , initialized with nullptr
- Inside a function that runs in a separate thread, handle all exceptions and set the value of std :: current_exception () to the global variable std :: exception_ptr declared in the previous step
- Inside the main thread, check the value of a global variable.
- If the value is set, use the function std :: rethrow_exception (exception_ptr p) to call the previously caught exception again, passing it by reference as a parameter
The exception is recalled by reference not in the thread in which it was created, so this feature is great for handling exceptions in different threads.
The code below achieves safe handling of the exception thrown in the background thread.
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr globalExceptionPtr = nullptr ;
void LaunchRocket ( )
{
try
{
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
catch ( ... )
{
//
globalExceptionPtr = std :: current_exception ( ) ;
}
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
if ( globalExceptionPtr )
{
try
{
std :: rethrow_exception ( globalExceptionPtr ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
}
return 0 ;
}
Error 13: Use threads to simulate asynchronous operation, instead of using std :: async
If you need the code to run asynchronously, i.e. without locking the main thread, the best choice would be to use std :: async () . This is equivalent to creating a stream and passing the necessary code to be executed into this stream via a pointer to a function or parameter in the form of a lambda function. However, in the latter case, you need to monitor the creation, attachment / detachment of this stream, as well as the handling of all exceptions that may occur in this stream. If you use std :: async () , you save yourself from these problems, and also sharply reduce your chances of getting into the deadlock .
Another significant advantage of using std :: async is the ability to get the result of an asynchronous operation back to the calling thread using the std :: future object. Imagine that we have a ConjureMagic () function that returns an int. We can start an asynchronous operation that will set the value in the future in the future object when the task is completed, and we can extract the result of the execution from this object in the execution flow from which the operation was called.
// future
std :: future asyncResult2 = std :: async ( & ConjureMagic ) ;
//... - future
// future
int v = asyncResult2. get ( ) ;Getting the result back from the running thread to the caller is more cumbersome. Two ways are possible:
- Passing a reference to the output variable to the stream in which it will save the result.
- Store the result in a field variable of the workflow object that can be read as soon as the thread completes execution.
Kurt Guntheroth found that in terms of performance, the overhead of creating a thread is 14 times more than using async .
Bottom line: use std :: async () by default until you find strong arguments for using std :: thread directly.
Error 14: Do not use std :: launch :: async if asynchrony is required
The std :: async () function is not quite the correct name, because by default it may not be executed asynchronously!
There are two std :: async execution policies:
- std :: launch :: async : the transferred function starts to run immediately in a separate thread
- std :: launch :: deferred : the passed function does not start right away, its launch is postponed until calls to get () or wait () are made on the std :: future object that will be returned from the call to std :: async . In the place where these methods are called, the function will be executed synchronously.
When we call std :: async () with default parameters, it starts up with a combination of these two parameters, which in fact leads to unpredictable behavior. There are a number of other difficulties associated with using std: async () with a default startup policy:
- inability to predict the correctness of access to local variables of the stream
- an asynchronous task may not start at all due to the fact that calls to get () and wait () methods may not be called during program execution
- when used in loops in which the exit condition waits for the std :: future object to be ready, these loops may never end, because std :: future, returned by a call to std :: async, can start in a pending state.
To avoid all these difficulties, always call std :: async with the launch policy std :: launch :: async .
Do not do this:
// myFunction std::async
auto myFuture = std :: async ( myFunction ) ;Instead, do this:
// myFunction
auto myFuture = std :: async ( std :: launch :: async , myFunction ) ;In more detail this moment is considered in Scott Meyers' book Effective and Modern C ++.
Error 15: Call the get () method of the std :: future object in a block of code whose execution time is critical
The code below handles the result obtained from the std :: future object of the asynchronous operation. However, the while loop will be blocked until an asynchronous operation is completed (in this case for 10 seconds). If you want to use this loop to display information on the screen, this can lead to unpleasant user interface rendering delays.
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
int val = myFuture. get ( ) ; // 10
// - Val
}
return 0 ;
}
Note : Another problem with the above code is that it tries to access the std :: future object a second time, although the state of the object's std :: future was retrieved on the first iteration of the loop and cannot be re-received.
The correct solution would be to check the validity of the object's std :: future before calling the get () method. Thus, we do not block the completion of an asynchronous task and do not try to re-interrogate an already retrieved std :: future object.
This code snippet allows you to achieve this:
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
if ( myFuture. valid ( ) )
{
int val = myFuture. get ( ) ; // 10
// - Val
}
}
return 0 ;
}
№16: , , , std::future::get()
Imagine that we have the following code snippet, what do you think will be the result of a call to std :: future :: get () ? If you assume that the program will fall - you are absolutely right! The exception thrown in an asynchronous operation is thrown only when the get () method is invoked on the std :: future object . And if the get () method is not called, the exception will be ignored and thrown when the std :: future object goes out of scope. If your asynchronous operation can throw an exception, then you should always wrap the call to std :: future :: get () in the try / catch block. An example of how this might look like:
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
int result = myFuture. get ( ) ;
}
return 0 ;
}
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
try
{
int result = myFuture. get ( ) ;
}
catch ( const std :: runtime_error & e )
{
std :: cout << "Async task threw exception: " << e. what ( ) << std :: endl ;
}
}
return 0 ;
}
№17: std::async,
Although std :: async () is sufficient in most cases, there are situations in which you may need careful control over the execution of your code in the stream. For example, if you want to bind a specific thread to a specific processor core in a multiprocessor system (for example, Xbox).
The above code fragment sets the thread binding to the 5th processor core in the system. This is possible thanks to the native_handle () method of the std :: thread object , and passing it to the Win32 API threading function . There are many other features provided through the Win32 streaming API that are not available in std :: thread or std :: async () . When working through
#include "stdafx.h"
#include <windows.h>
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
DWORD result = :: SetThreadIdealProcessor ( t1. native_handle ( ) , 5 ) ;
t1. join ( ) ;
return 0 ;
}
std :: async () these basic platform functions are not available, which makes this method unsuitable for more complex tasks.
Alternatively, create std :: packaged_task and move it to the desired execution thread after setting the properties of the flow.
Mistake # 18: Create much more “running” threads than available cores.
From an architectural point of view, streams can be classified into two groups: “running” and “waiting”.
Running threads recycle 100% of the kernel time on which they are running. When more than one running thread is allocated per core, processor utilization efficiency drops. We do not get performance gains if we run more than one running thread on a single processor core — in fact, performance drops due to additional context switches.
Waiting threads recycle only a few clock ticks on which they run while waiting for system events or network I / O, etc. In this case, most of the available processor time of the kernel remains unused. One waiting thread can process data, while the others wait for events to trigger — which is why it is advantageous to distribute several waiting threads to one core. Planning multiple waiting threads per core can provide much better program performance.
So, how to understand how many threads the system supports? Use the std :: thread :: hardware_concurrency () method . This function usually returns the number of processor cores, but takes into account cores that behave like two or more logical cores due tohyper-trading .
You must use the resulting value of the target platform to plan the maximum number of concurrently running threads of your program. You can also assign one core for all pending threads, and use the remaining number of cores for the threads that are running. For example, in a quad-core system, use one core for ALL pending threads, and for the other three cores - three running threads. Depending on the performance of your thread scheduler, some of your executable threads may switch context (due to page access failures, etc.), leaving the kernel inactive for some time. If you observe this situation during profiling, you should create a slightly larger number of threads to execute than the number of cores and adjust this value for your system.
Error 19: Using the volatile keyword for synchronization
The volatile keyword before specifying the type of a variable does not make operations with this variable atomic or thread-safe. What you probably want is std :: atomic .
See the discussion on stackoverflow for details.
Mistake number 20: Using Lock Free architecture, except when absolutely necessary
In complexity, there is something that every engineer likes. Creating programs that work without locks (lock free) sounds very tempting compared to conventional synchronization mechanisms such as mutex, condition variables, asynchrony, etc. However, every experienced C ++ developer I spoke with adhered to that the use of non-blocking programming as a source is a type of premature optimization that can go sideways at the most inopportune moment (think of a malfunction in the operating system when you do not have a full heap dump!)
In my career in C ++, there was only one situation that required unlocked code execution, because we worked in a system with limited resources, where each transaction in our component should take no more than 10 microseconds.
Before you think about using a non-blocking approach, please answer three questions:
- Have you tried to design the architecture of your system so that it does not need a synchronization mechanism? As a rule, the best synchronization is the lack of synchronization.
- If you need synchronization, have you profiled your code to understand performance characteristics? If so, have you tried to optimize bottlenecks?
- Can you scale horizontally instead of vertically?
Summarizing, for normal application development, please consider programming without blocking only when you have exhausted all other alternatives. Another way to look at this is that if you are still making some of the above 19 errors, you should probably stay away from non-blocking programming.
[From. translator: Many thanks to the user vovo4K for help in preparing this article.]
Source: https://habr.com/ru/post/443406/
All Articles