How to make code review faster and more efficiently
How does code review usually occur? You send a pull request, get feedback, make corrections, send fixes to a second review, then get approval, and merge happens. It sounds simple, but in reality the review process can be very time consuming.
Imagine that you have a pull request with hundreds of rows of changes. The reviewer should spend a lot of time to fully read the code and understand the proposed changes. As a result, the whole process from creating a pull request to its approval may take several days - this is not very pleasant for the reviewer and the author of the changes. And the chances are great that in the end the reviewer will still miss something. Or the check may be too superficial, and in the worst case, the pull request may be rejected right away.
')
It turns out that the longer the pool-request, the less benefit it will be from checking it.
How to avoid such situations? How to make pool-request easier and more understandable for the reviewer and to optimize the whole process?
We are translating an article by our backend developer Sergey Zhuk about how the code review process works for the Skyeng mobile app team.
Change categories
Let's imagine that you have a task - to implement a new functionality in the project. The pull request you are working on may contain different categories of changes. Of course there will be some new code in it. But in the course of work, you may notice that some code needs to be previously refactored so that it contributes to the addition of new functionality. Or with this new functionality in the code appeared duplication, which you want to eliminate. Or you suddenly find a mistake and want to fix it. What should the final pull request look like?
First, let's look at what categories of changes can occur with the code.
- Functional changes.
- Structural refactoring - changes to classes, interfaces, methods, movement between classes.
- Simple refactoring - can be performed using an IDE (for example, retrieving variables / methods / constants, simplifying conditions).
- Renaming and moving classes - reorganize the namespace.
- Delete unused (dead) code.
- Corrections code style.
Review strategies
It is very important to understand that each of these categories is reviewed differently and when reviewing them, the reviewer should focus on different things. It can be said that each category of change involves its own review strategy.
- Functional change: solving business problems and system design.
- Structural refactoring: backward compatibility and design improvement.
- Primitive refactoring: improved readability. These changes can basically be made using the IDE (for example, retrieving variables / methods / constants, etc.).
- Rename / delete classes: Has the namespace structure improved?
- Remove unused code: backward compatibility.
- Corrections code style: most often merge pool request occurs immediately.
Different approaches are used to verify changes in different categories, so the amount of time and effort spent on their reviews also differ.
Functional changes. This is the longest process, because it involves changes in the domain logic. The reviewer looks to see if the problem is resolved and checks whether the proposed solution is the most appropriate or can be improved.
Structural refactoring. This process takes much less time than functional changes. But there may be suggestions and disagreements about how exactly the code should be organized.
When checking the remaining categories in 99% of cases, the merge occurs immediately.
- Simple refactoring. Is the code more readable? - merzhim.
- Rename / move classes. Has the class been moved to a better namespace? - merzhim.
- Deleting an unused (dead) code is merge.
- Corrections code style or formatting - merzhim. Your colleagues should not check this during the code review, this is the task of the linkers.
Why is it necessary to divide changes into categories?
We have already discussed that different categories of changes are revised differently. For example, we check the functional changes, starting from business requirements, and during structural refactoring we check backward compatibility. And if we mix several categories, it will be difficult for the reviewer to keep in mind at the same time several review strategies. And, most likely, the reviewer will spend more time than necessary on the pool-request, and because of this may miss something. Moreover, if the pool-request contains changes of various kinds, with any correction, the reviewer will have to revise all these categories again. For example, you mix structural refactoring and functional changes. Even if the refactoring is done well, but there is a problem with the implementation of the functional, then after corrections, the reviewer will have to view the entire pull request from the very beginning. That is, re-check and refactoring, and functional changes. So the verifier spends more time on the pull request. Instead of having to immediately separate the pull request with refactoring, the viewer should review the entire code again.
What exactly is not worth mixing
Rename / delete class and refactor it. Here we come across Git, which does not always understand such changes correctly. I mean large-scale changes when changing many lines. When you refactor a class and then move it somewhere, Git does not perceive it as a move. Instead, Git interprets these changes as deleting one class and creating another. This leads to a bunch of questions during the code review. And the author of the code is asked why he wrote this ugly code, although in fact this code was simply moved from one place to another with a few changes.
Any functional changes + any refactoring. We have already discussed this case above. This forces the reviewer to keep two review strategies in mind. Even if the refactoring is well done, we will not be able to mitigate these changes until the functional changes are approved.
Any mechanical changes + any changes made by humans. By "mechanical changes" I mean any formatting done with an IDE or code generation. For example, we use the new code style and get the changes for 3000 lines. And if we mix these changes with any functional or any other changes made by a person, we will make the reviewer mentally classify these changes and reason: this change made by a computer can be skipped, and this change made by a person must be check. So the reviewer spends a lot of extra time to check.
Example
Here is a pull request with a method function that neatly closes the client connection with Memcached:
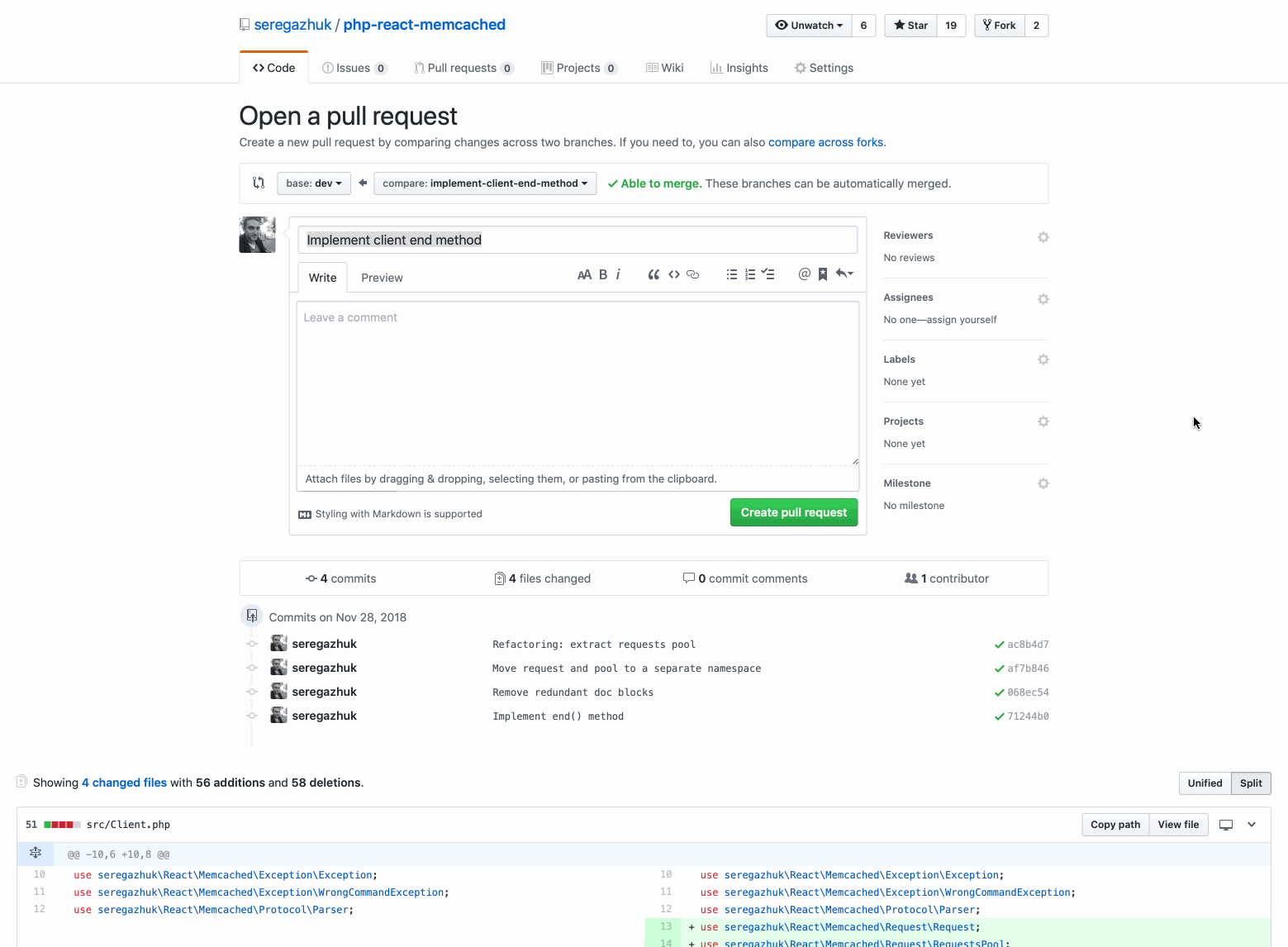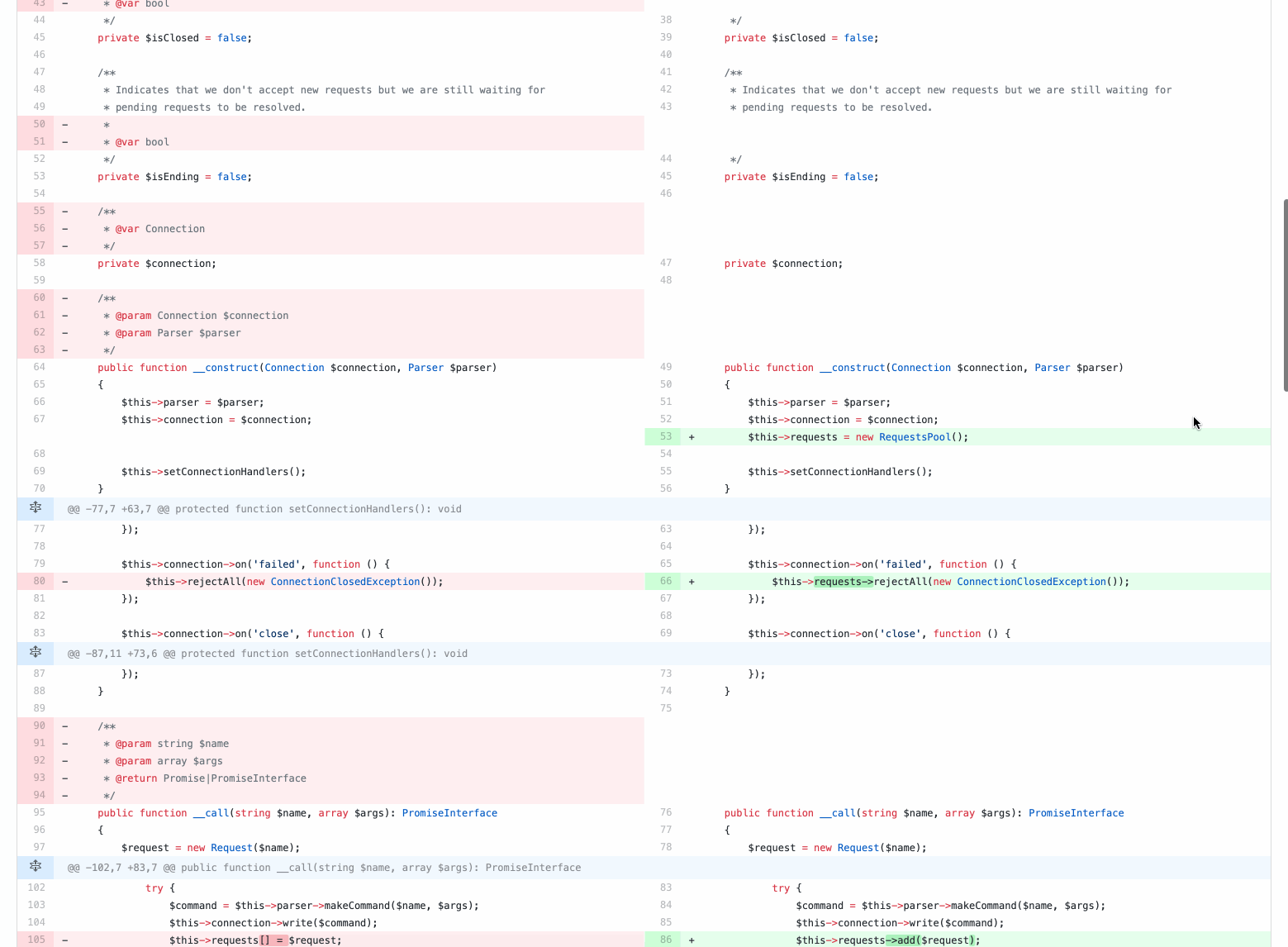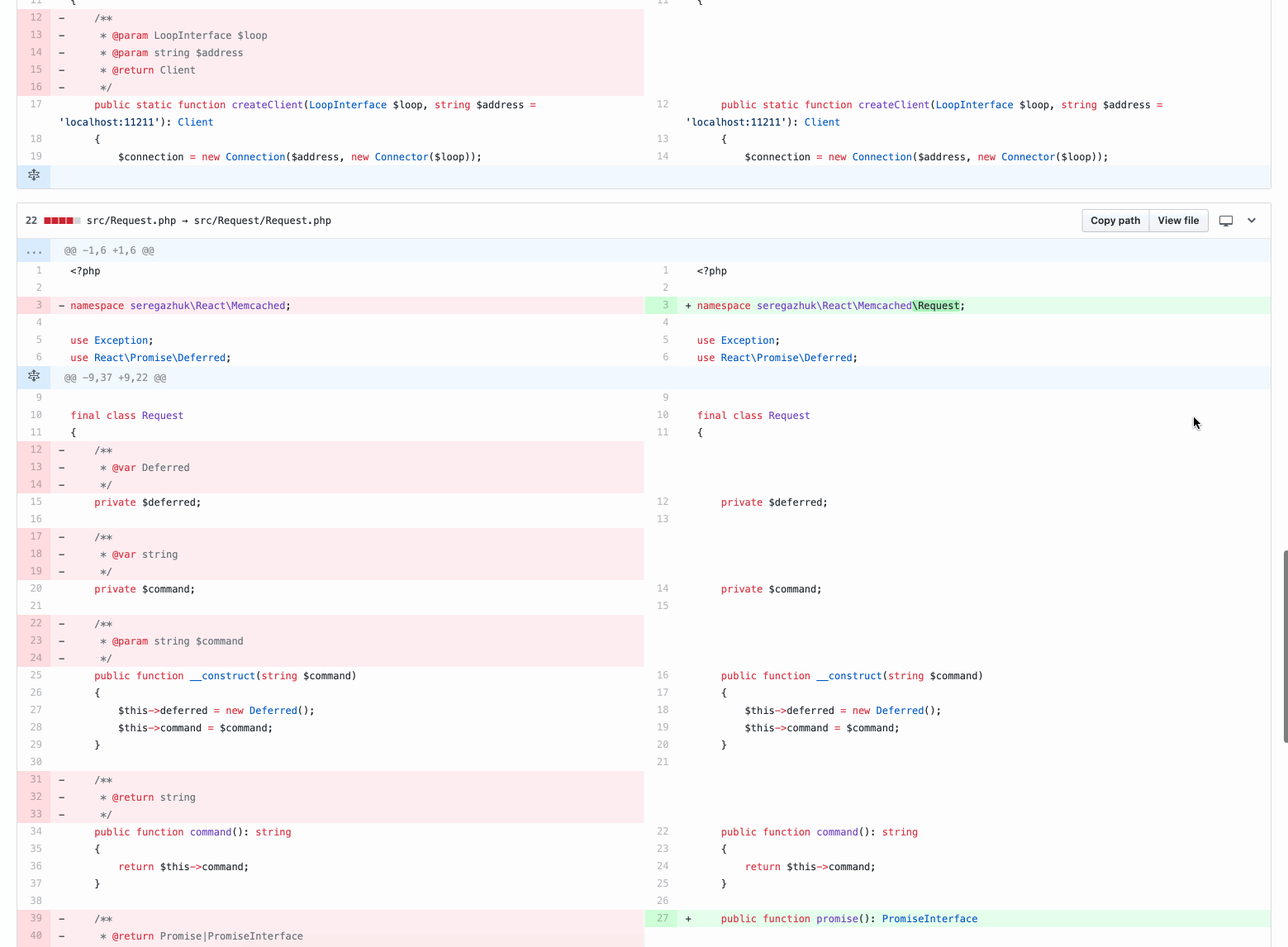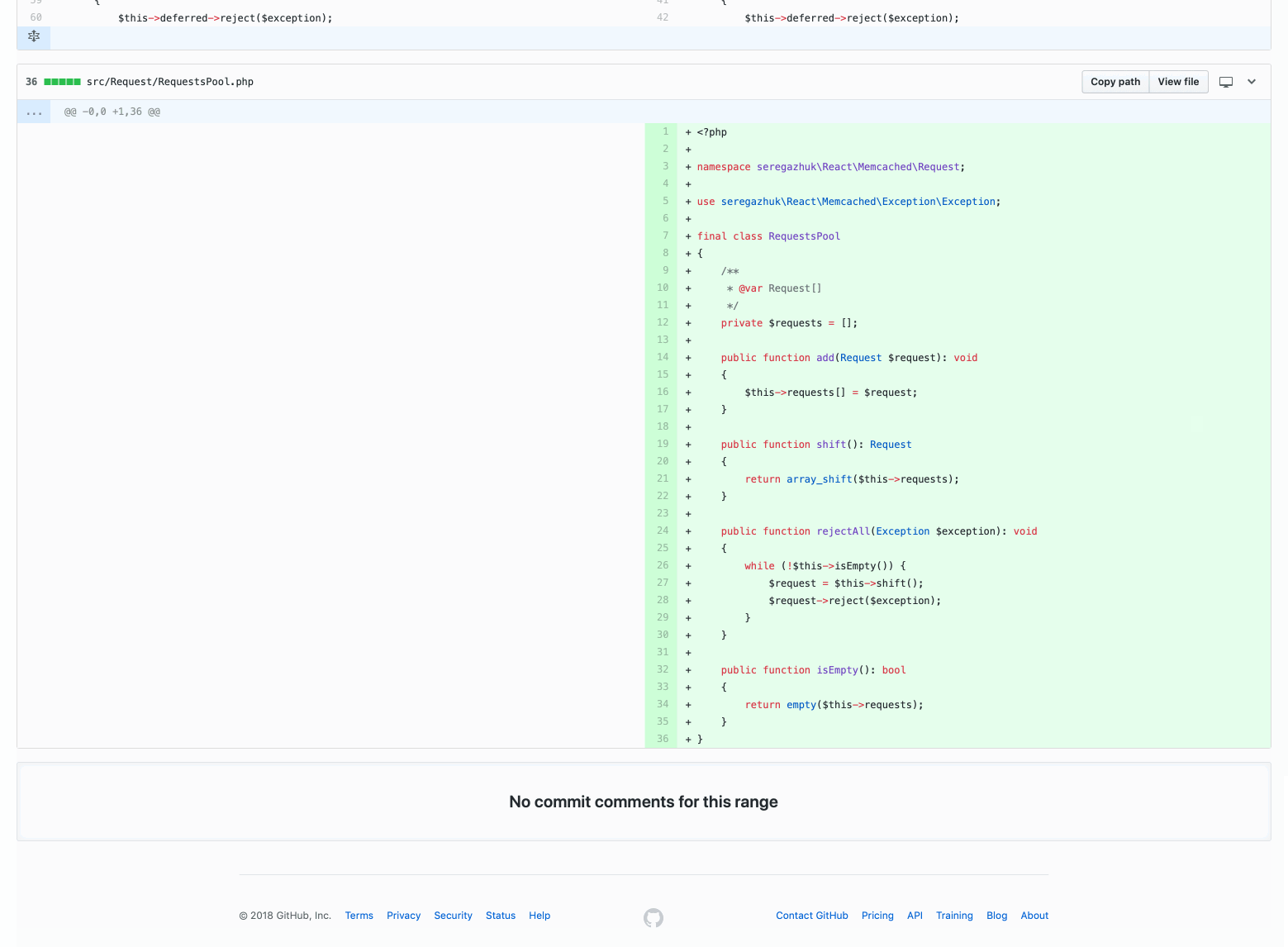
Even if the pull request is small and contains only a hundred lines of code, it is still difficult to check. As you can see by commits, it contains various categories of changes:
- functional (new code),
- refactoring (creating / moving classes),
- code style fixes (remove unnecessary dock blocks).
At the same time, the new functionality itself is only 10 lines:
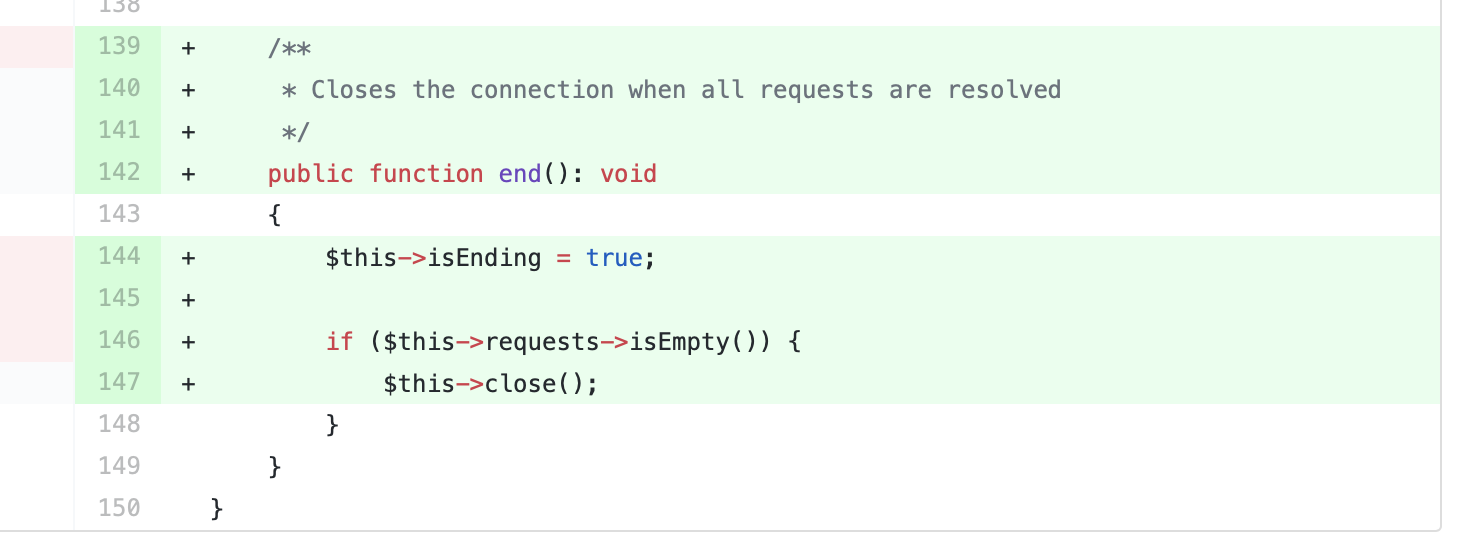
As a result, the reviewer must review the entire code and
- check that refactoring is OK;
- check if the new functionality is implemented correctly;
- to determine whether this change was made automatically by an IDE or person.
Therefore, such a pool-request is difficult to revise. To remedy the situation, you can break these commits into separate branches and create a pool of requests for each of them.
1. Refactoring: class extraction
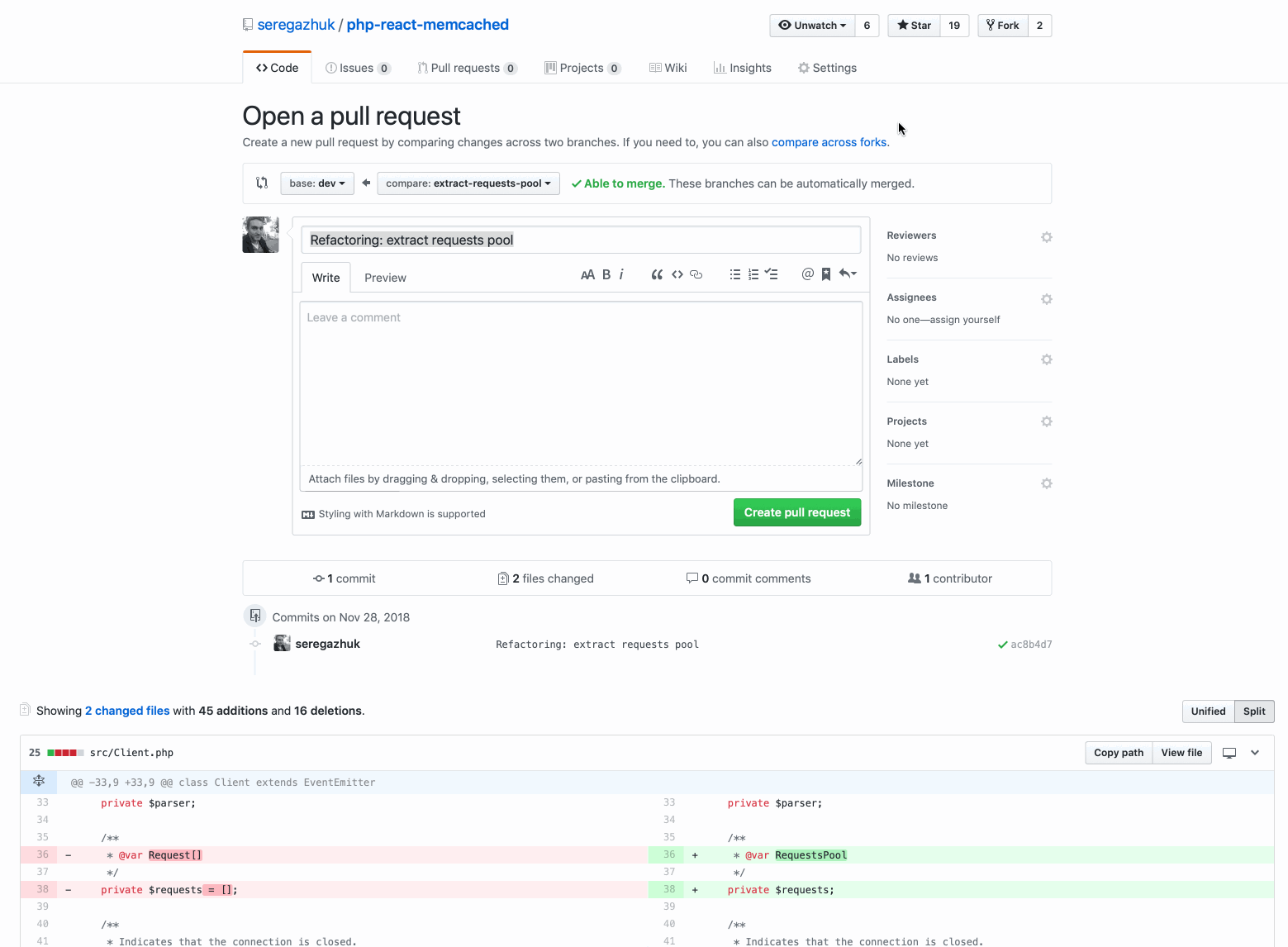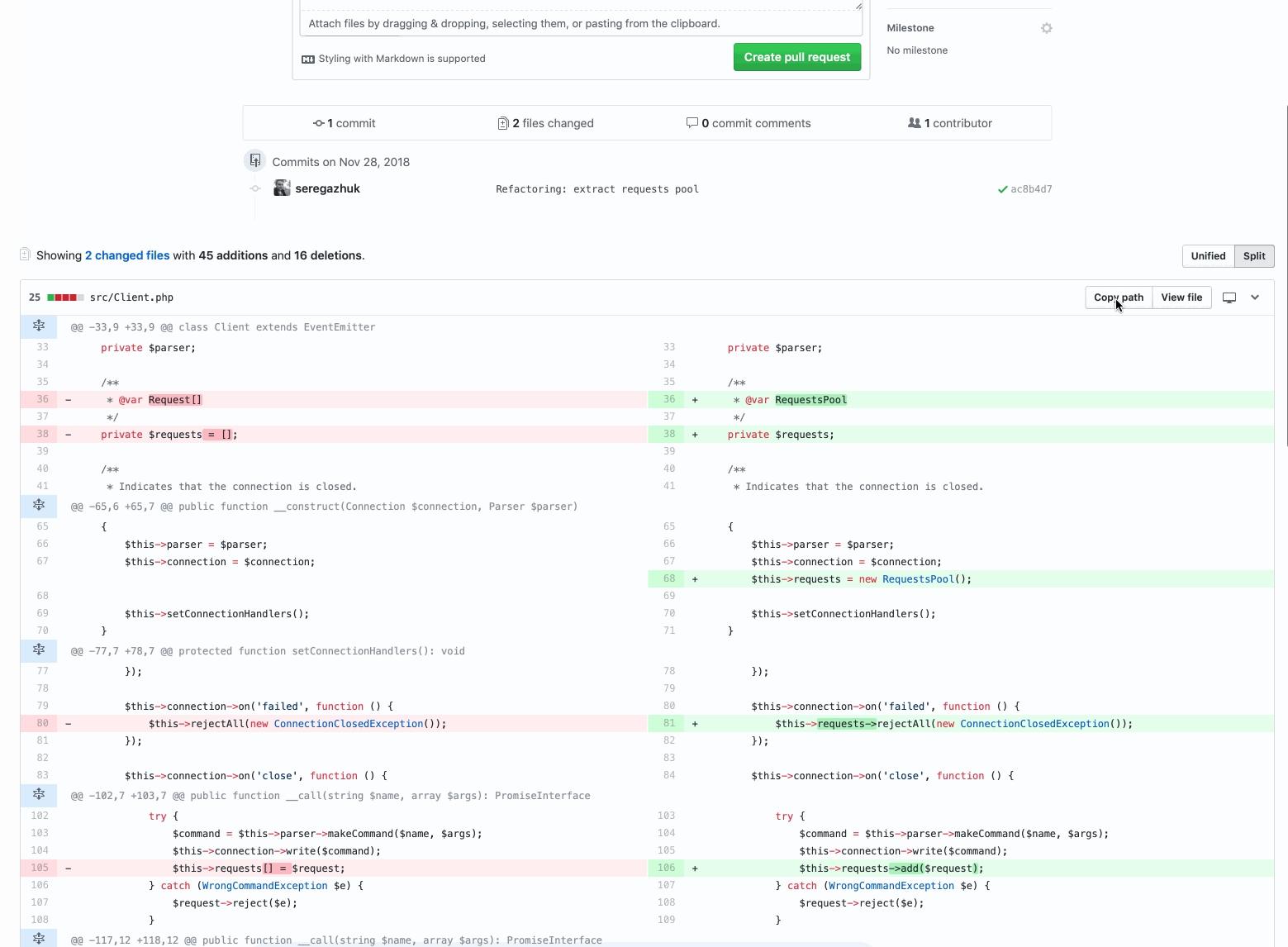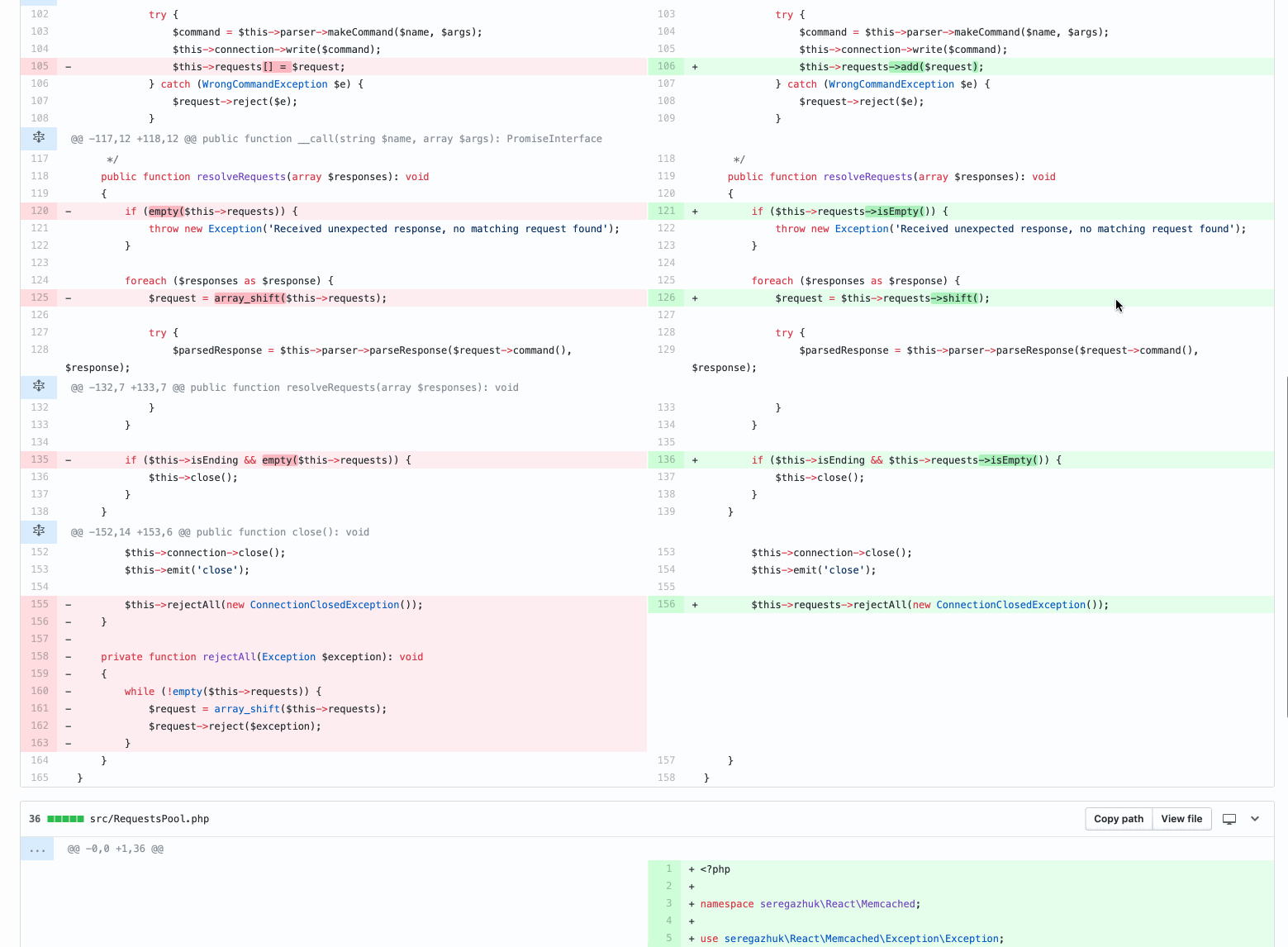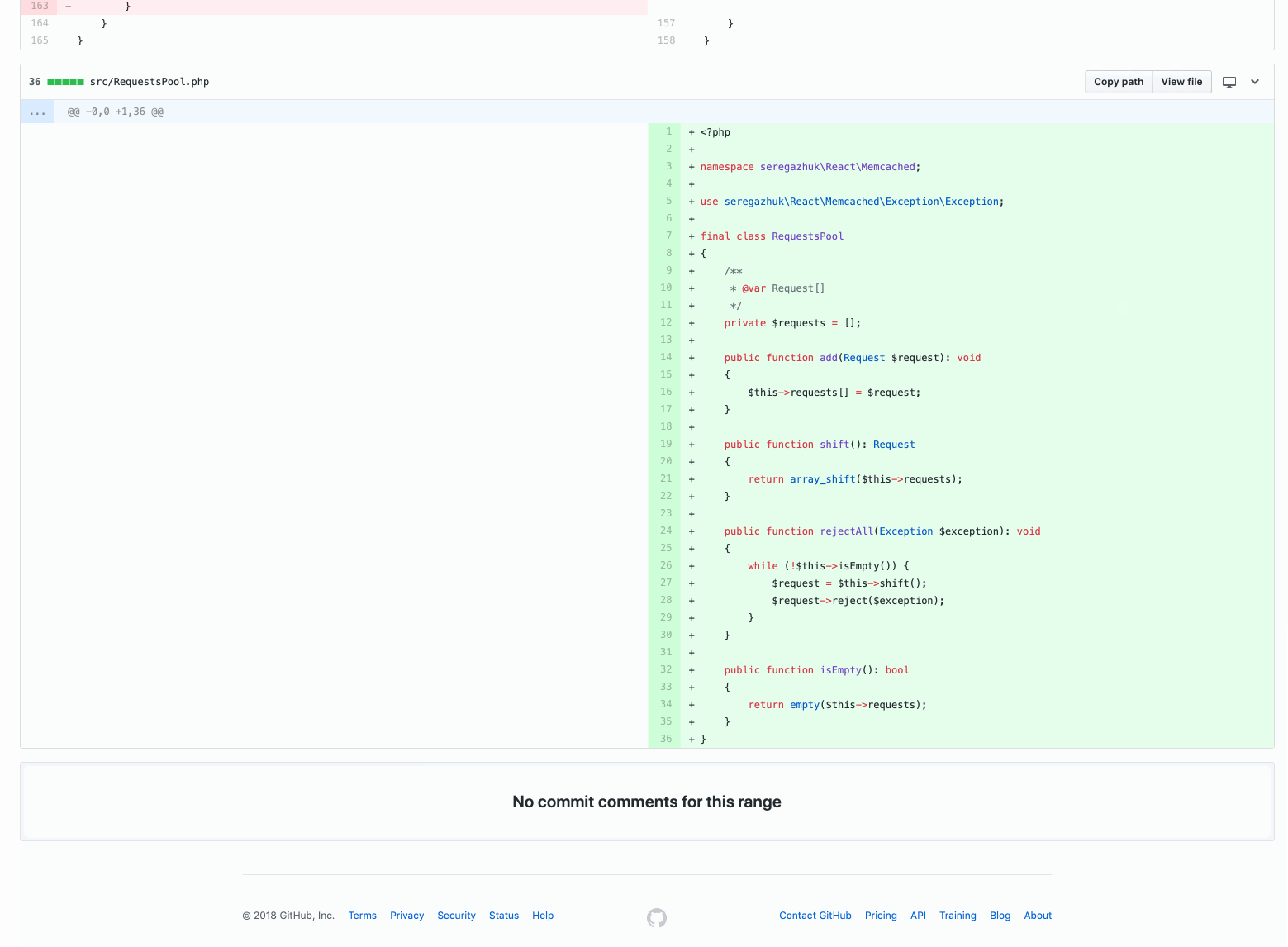
There are only two files. The reviewer should check only the new design. If everything is in order - merzhim.
2. The next step is also refactoring, we simply move two classes to a new namespace.
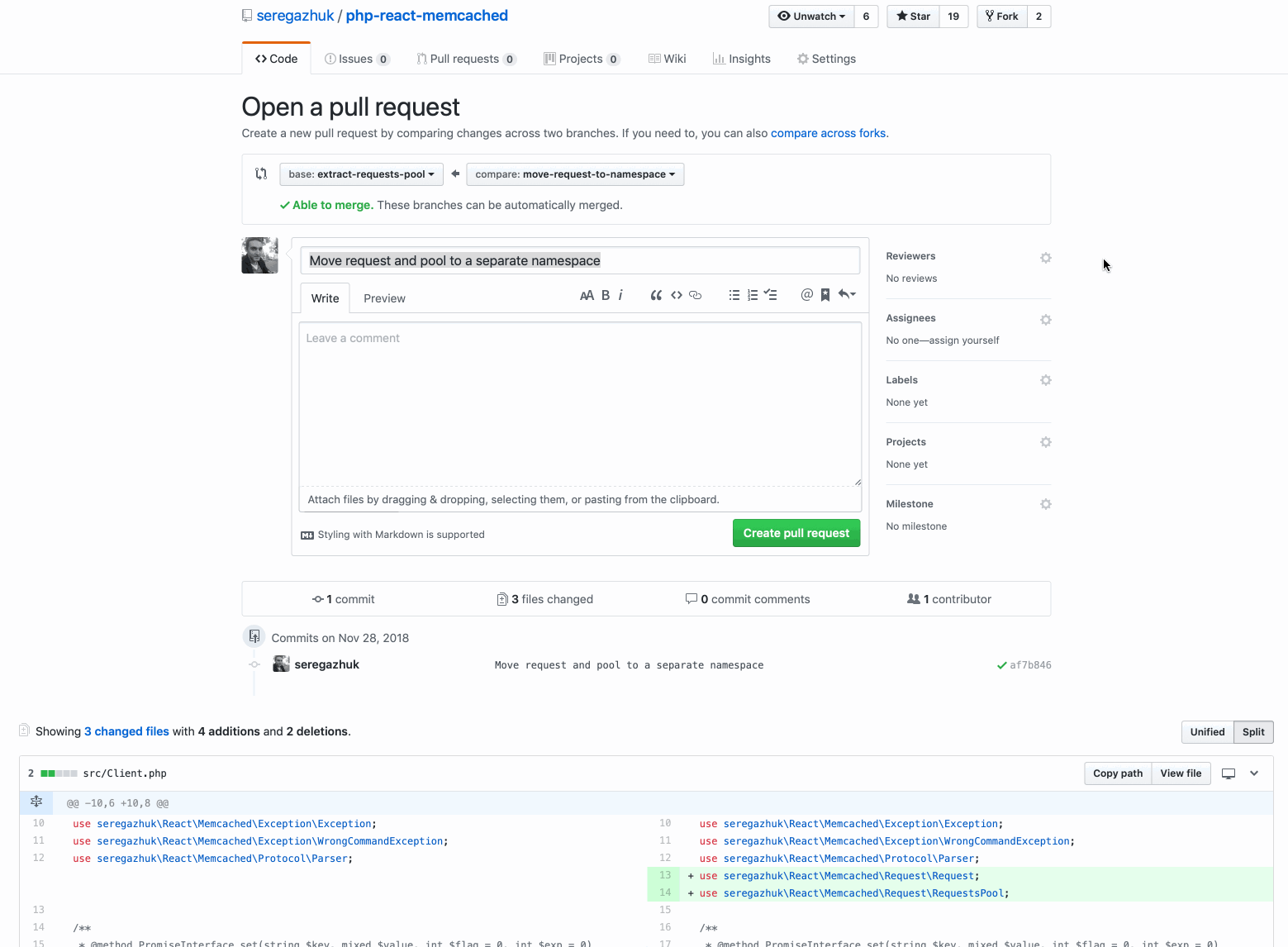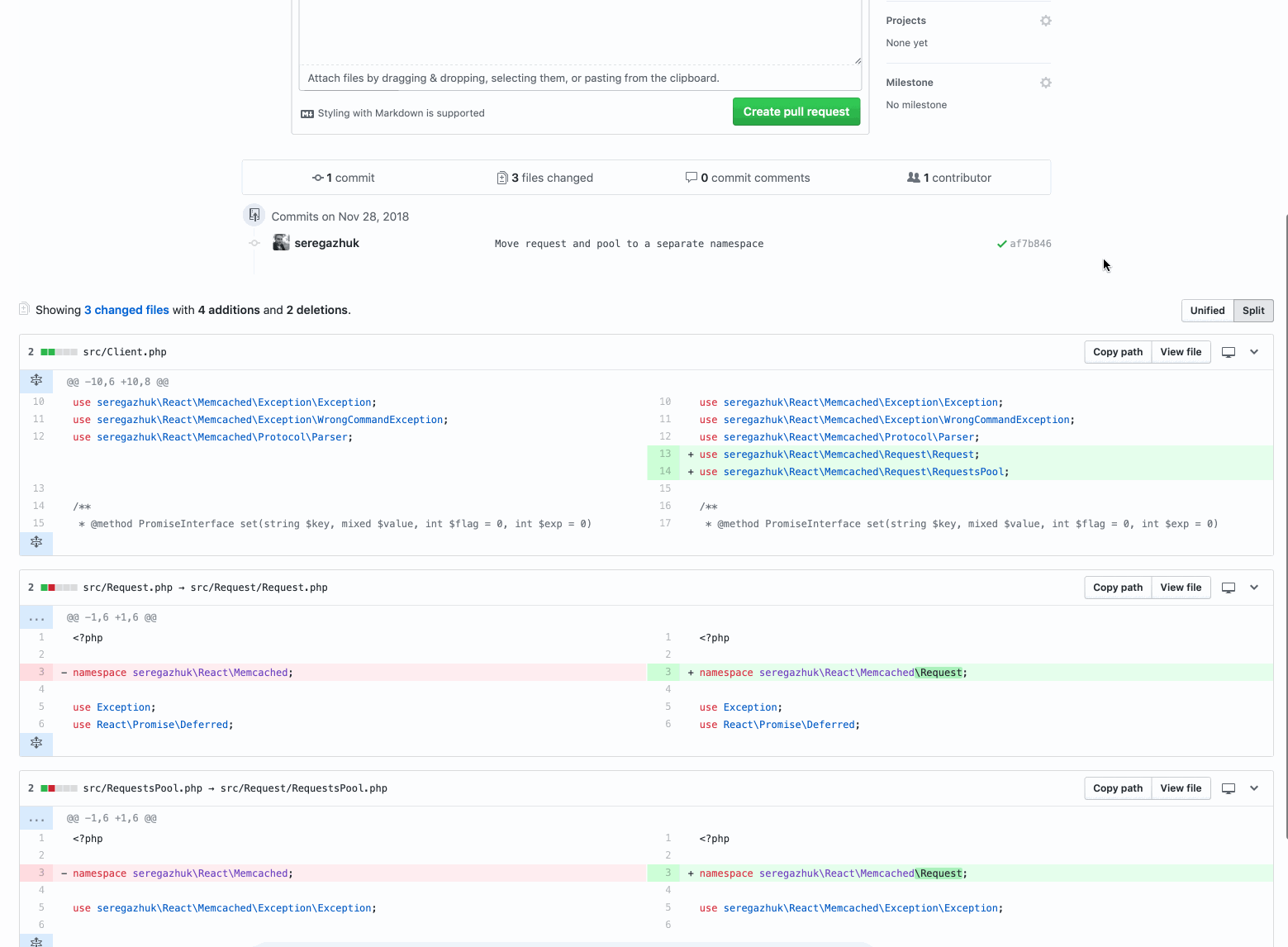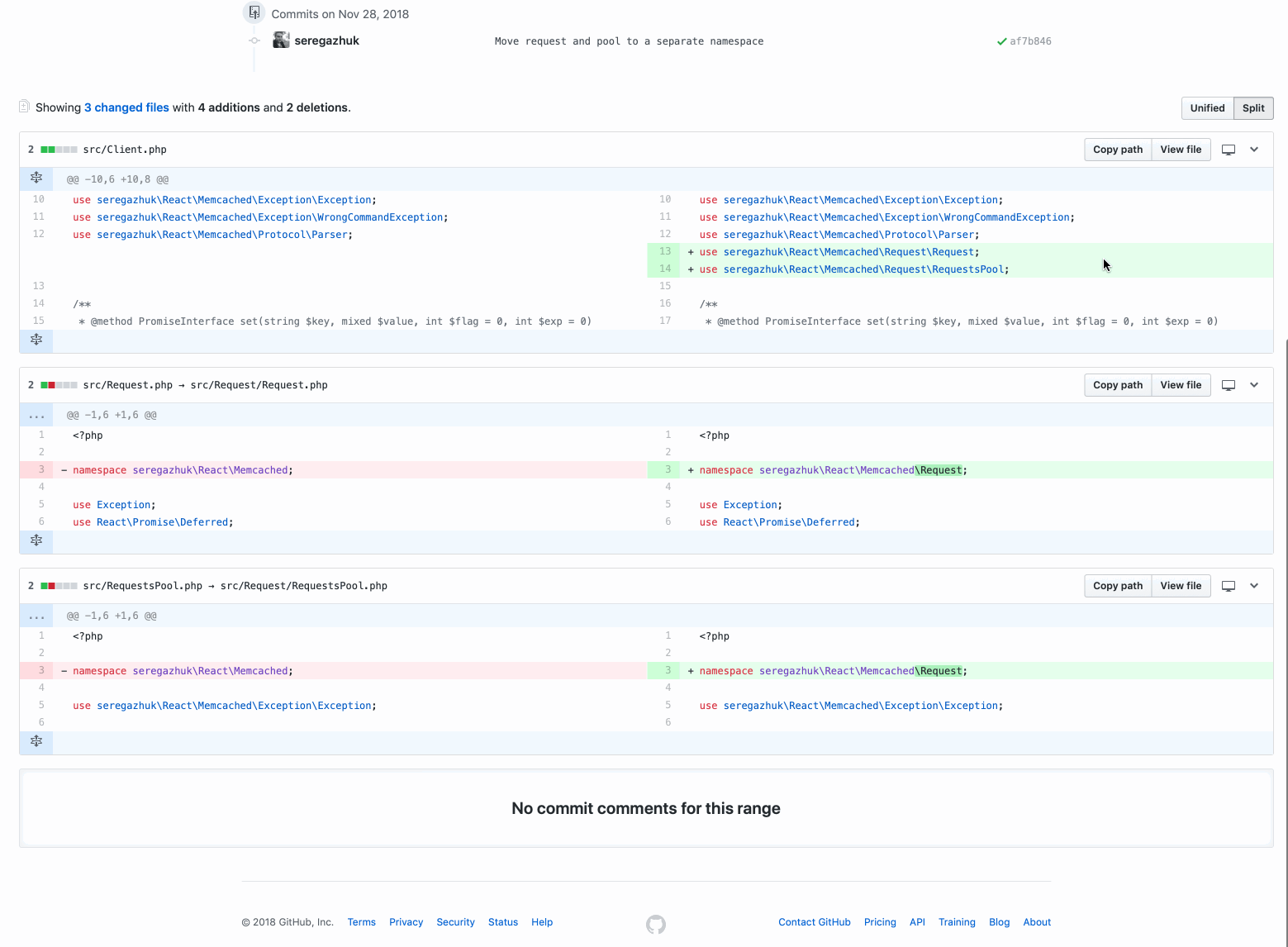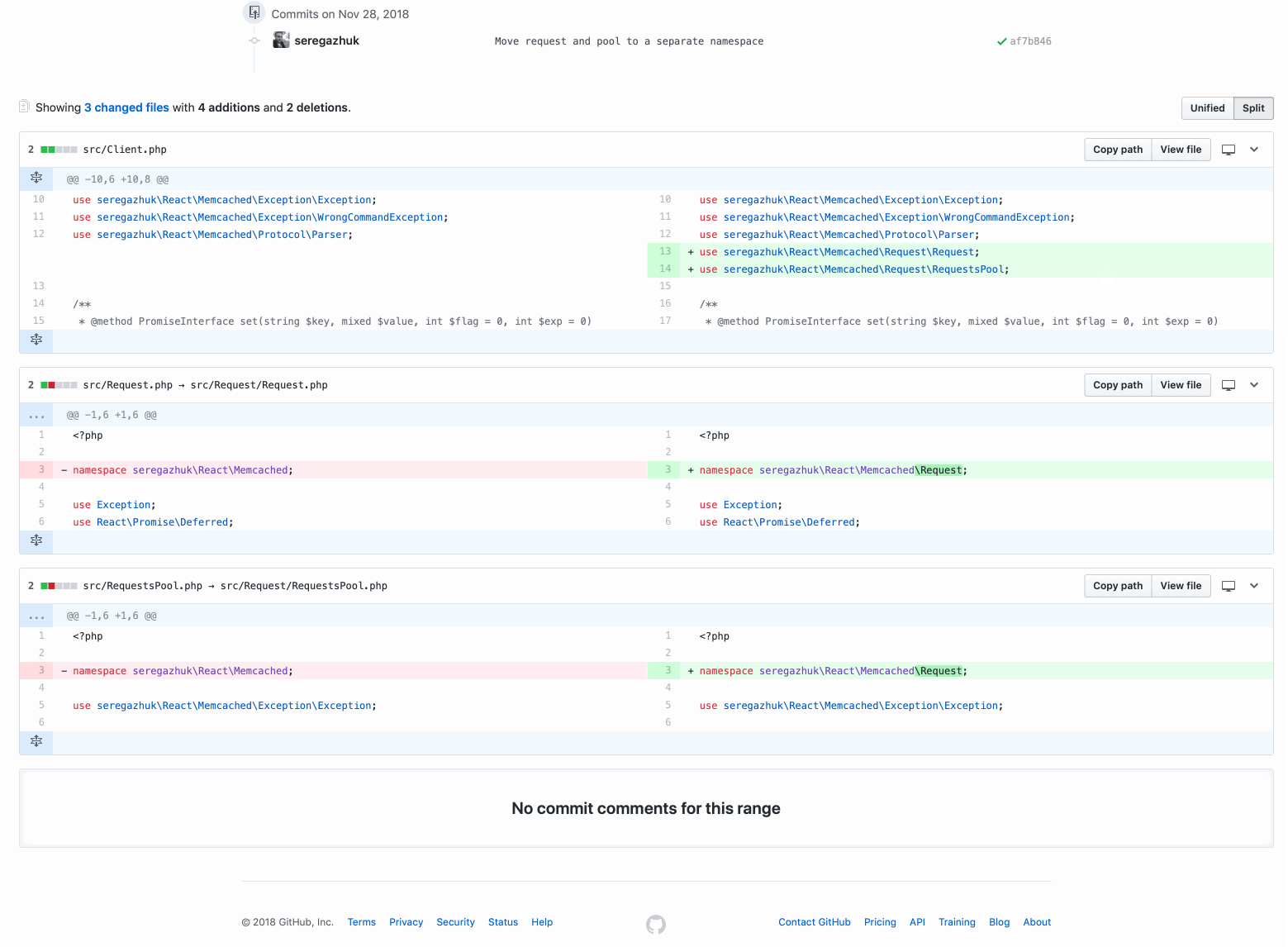
Such a pull request is quite simple to check, it can be smomer immediately.
3. Removing unnecessary blocks of documents
There is nothing interesting. Merzhim.
4. The functionality itself
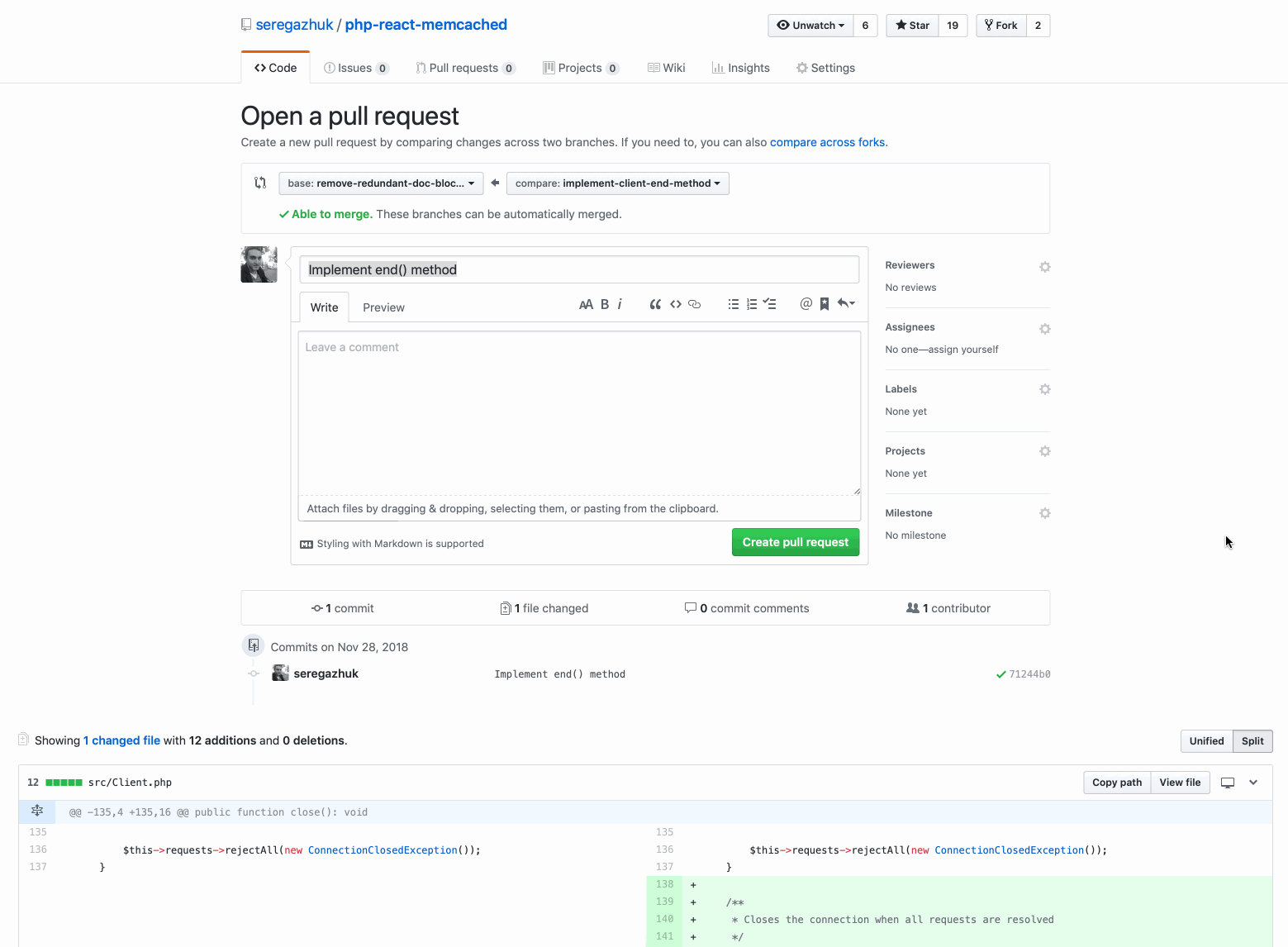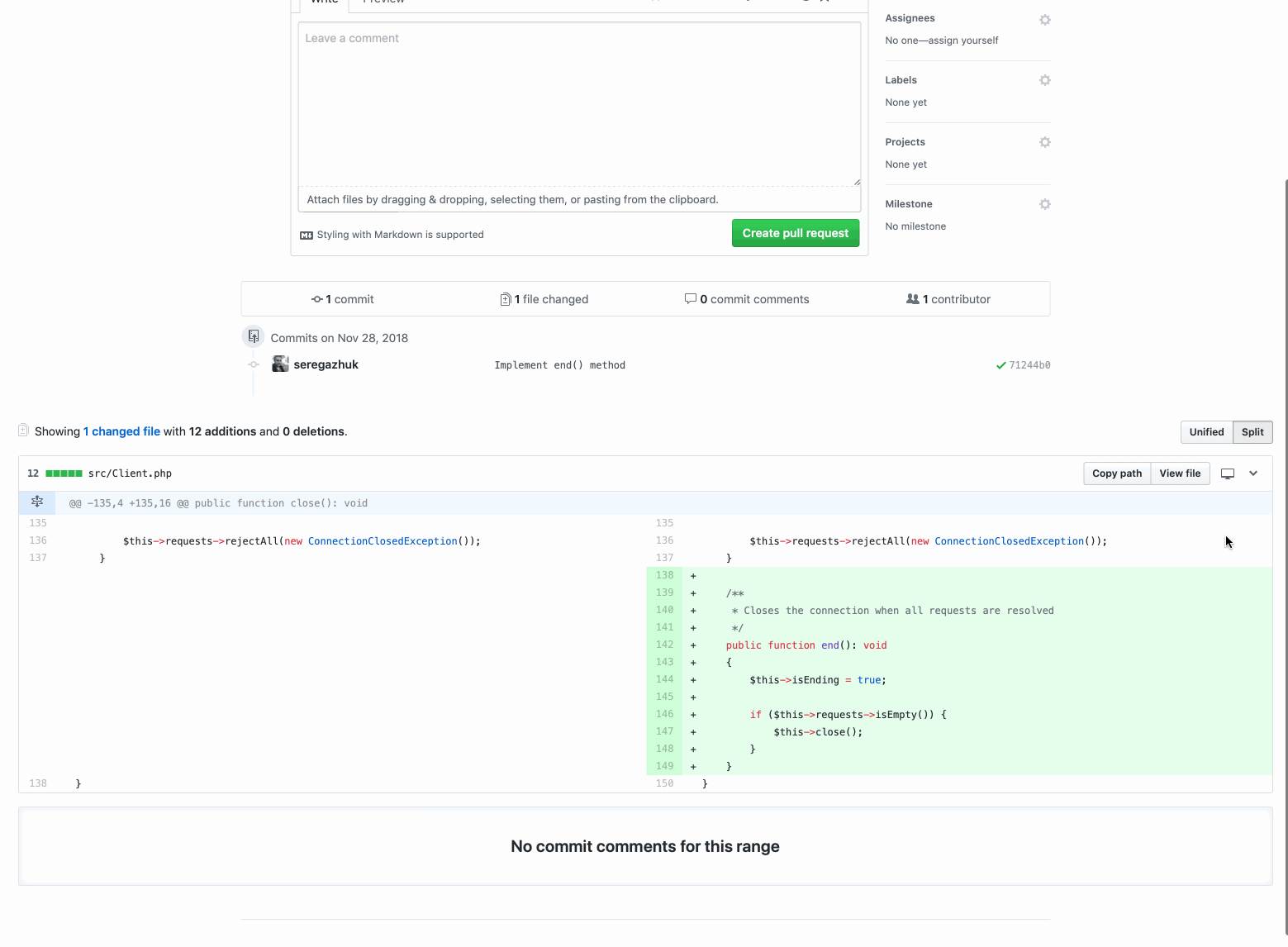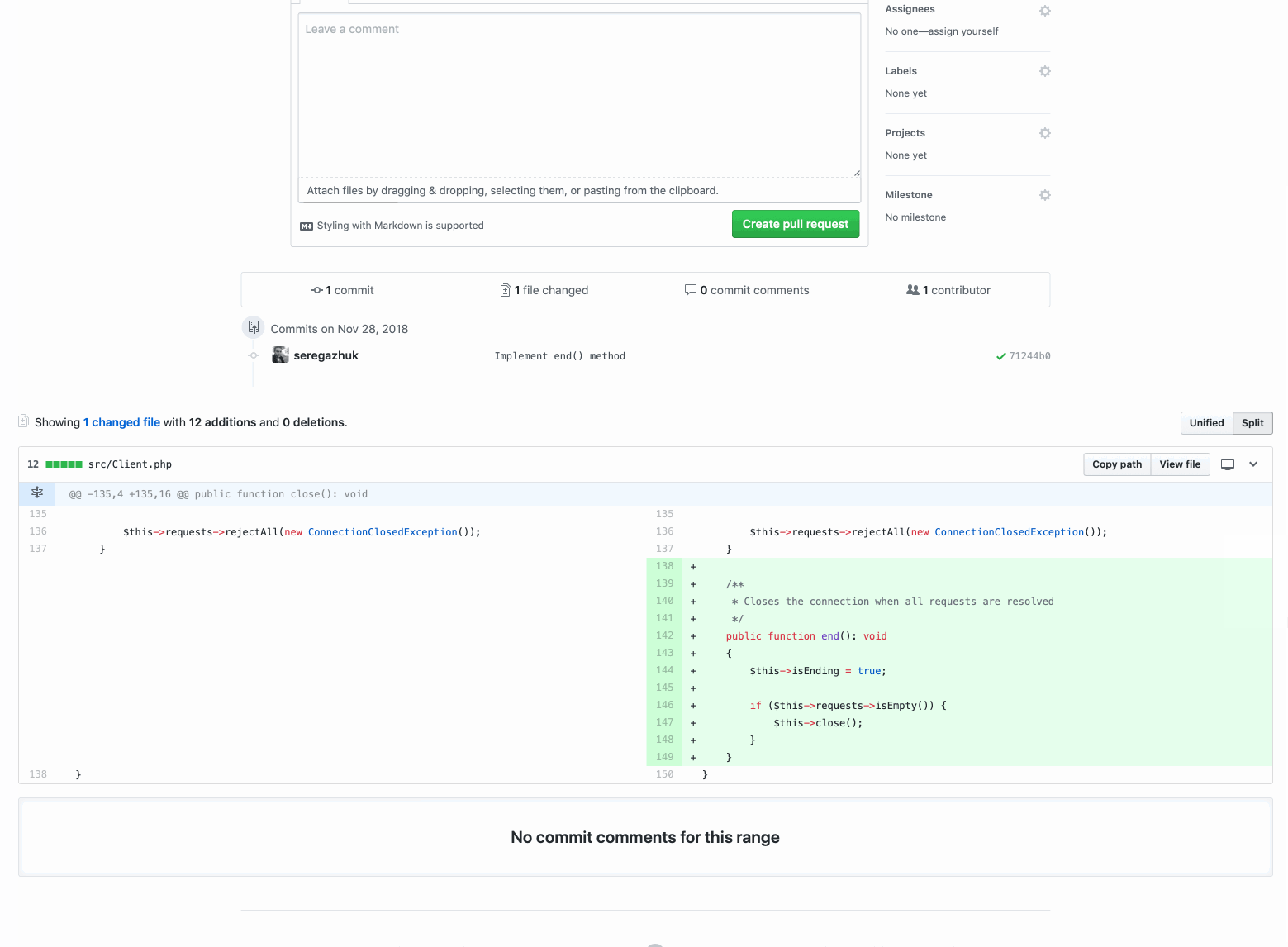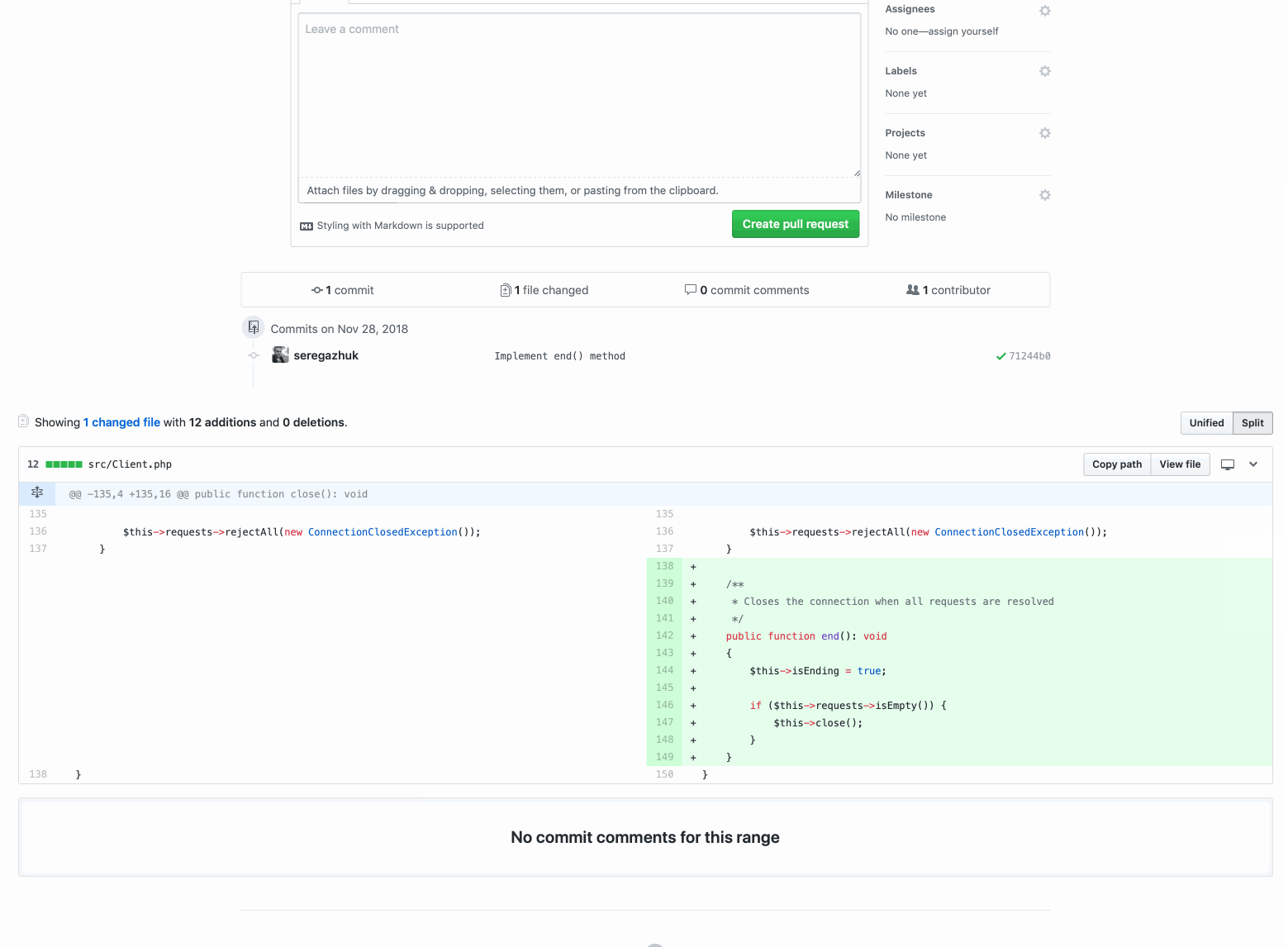
And now the pool request with functional changes contains only the necessary code. So your reviewer can only focus on this task. The pull request is small and easy to check.
Conclusion
Rule of thumb:
Do not create huge pull requests with mixed categories of changes.The larger the pool request, the harder it is for the reviewer to understand the changes you are proposing. Most likely, a huge pull request with hundreds of lines of code will be rejected. Instead, break it into small logical pieces. If your refactoring is in order, but the functional changes contain errors, then you can safely refactor, so you and your reviewer can focus on the functionality without looking at all the code from the beginning.
And always follow these steps before sending a pull request:
- optimize your code for reading. The code is much more readable than written;
- describe the proposed changes to provide the necessary context for understanding them;
- Always check your code before creating a pull request. And do it as if it were someone else's code. Sometimes it helps to find something that you missed. This will reduce the likelihood of rejecting your pull request and the number of corrections.
My colleague Oleg Antonevich told me about the idea of breaking changes into categories.
Editorial note: Sergey writes a lot of interesting things about programming and PHP, and sometimes we translate something: a streaming video server , rendering HTML files . Feel free to ask him questions in the comments to this article - he will answer!
Well, we also remind you that we always have a lot of interesting vacancies for developers!
Source: https://habr.com/ru/post/443402/
All Articles