Python vs. Scala for Apache Spark - the expected benchmark with an unexpected result

Apache Spark is by far the most popular platform for analyzing large data volumes. Considerable contribution to its popularity is made by the possibility of using it from under Python. At the same time, everyone agrees that within the framework of the standard API, the performance of Python and Scala / Java code is comparable, but there is no common point of view regarding user defined functions (User Defined Function, UDF). Let's try to figure out how much the overheads increase in this case, using the example of the problem of checking the solution of SNA Hackathon 2019 .
As part of the competition, participants solve the problem of sorting a news feed on a social network and upload solutions in the form of a set of sorted lists. To check the quality of the solution obtained, first, for each of the loaded lists, the ROC AUC is calculated, and then the average value is displayed. Pay attention that it is necessary to calculate not one common ROC AUC, but a personal one for each user - there is no ready construction for solving this problem, so you will have to write a specialized function. A good reason to compare the two approaches in practice.
As a platform for comparison, we will use a cloud container with four cores and Spark, running in local mode, and we will work with it through Apache Zeppelin . To compare the functionality, we will mirror the same code in PySpark and Scala Spark. [here] Start by loading data.
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count() val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count() When using the standard API, attention is drawn to the almost complete identity of the code, up to the val keyword. Work time is not significantly different. Now let's try to determine the UDF we need.
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType()) val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) }) When implementing a specific function, it is clear that Python is more concise, primarily because of the ability to use the built-in function scikit-learn . However, there are also unpleasant moments - it is necessary to clearly indicate the type of the return value, whereas in Scala it is determined automatically. Perform the operation:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show() toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show() The code looks almost identical, but the results are discouraging.

The implementation on PySpark worked one and a half minutes instead of two seconds on Scala, that is, Python was 45 times slower . During operation, the top shows 4 active Python processes running full, and this suggests that the problem here is not Global Interpreter Lock . But! Perhaps the problem is precisely in the internal implementation of scikit-learn - let's try to reproduce the code in Python literally, without referring to the standard libraries.
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show() 
The experiment shows interesting results. On the one hand, with this approach, the performance leveled off, but on the other, brevity was lost. The results obtained may indicate that when working in Python with the use of additional C ++ modules, there are significant overhead costs for switching between contexts. Of course, there are similar overheads when using JNI in Java / Scala, however, I did not have to deal with examples of degradation 45 times when using them.
For a more detailed analysis, we will conduct two additional experiments: using pure Python without Spark, in order to measure the contribution from the package call, and with an increased data size in Spark, in order to absorb the overhead and get a more accurate comparison.
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) 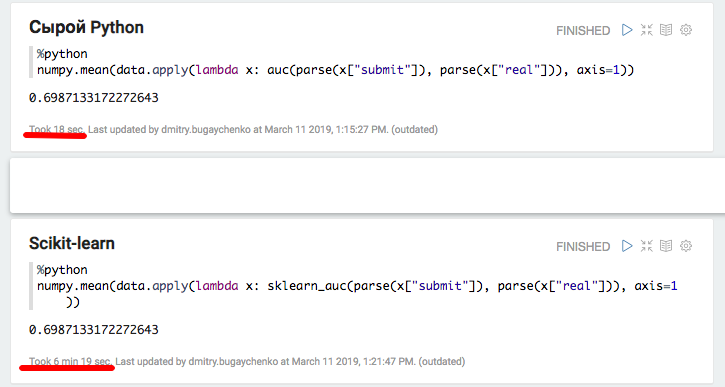
Experiment with local Python and Pandas confirmed the assumption of significant overhead when using additional packages - when using scikit-learn, the speed decreases by more than 20 times. However, 20 is not 45 - try to “inflate” the data and again compare the performance of Spark.
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count() 
The new comparison shows the speed advantage of the Scala implementation over Python 7-8 times - 7 seconds versus 55. Finally, we will try "the fastest thing in Python" - numpy to calculate the sum of the array:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType()) val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum) 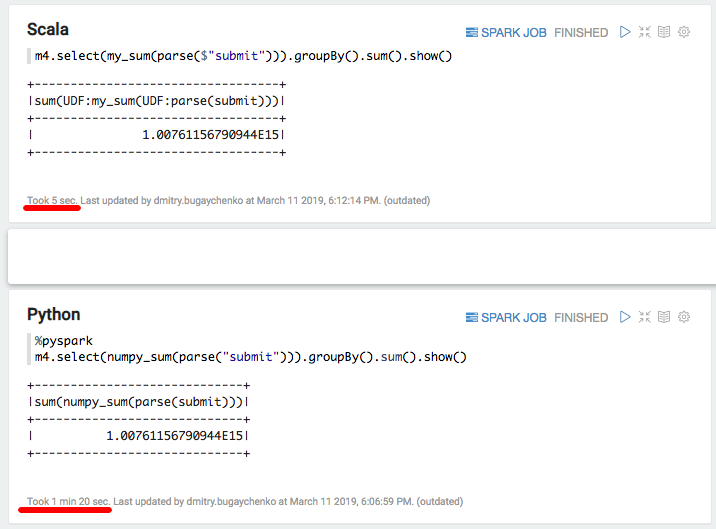
Again, a significant slowdown - 5 seconds Scala vs 80 second Python. Summing up, we can draw the following conclusions:
- As long as PySpark operates within the framework of the standard API, it can really be comparable in speed to Scala.
- When a specific logic appears in the form of User Defined Functions, the performance of PySpark is noticeably reduced. With enough information, when the processing time of a block of data exceeds a few seconds, the Python implementation runs 5-10 slower because of the need to move data between processes and waste resources on interpreting Python.
- If there is the use of additional functions implemented in C ++ modules, then there are additional costs for the call, and the difference between Python and Scala increases up to 10-50 times.
As a result, despite the beauty of Python, its use in conjunction with Spark does not always look justified. If there is not so much data to make Python overhead meaningful, then you should think, is Spark needed here? If there is a lot of data, but processing takes place within the framework of the standard Spark SQL API, is Python needed here?
If there is a lot of data and you often have to deal with tasks that go beyond the SQL API, in order to perform the same amount of work using PySpark, you will have to increase the cluster several times. For example, for Odnoklassniki, the cost of capital expenditures on a Spark cluster would increase by many hundreds of millions of rubles. And if you try to use the advanced features of the Python ecosystem libraries, then there is a risk of slowing down not just at times, but by an order of magnitude.
Some acceleration can be obtained using relatively new functionality of vectorized functions. In this case, not a single row is fed to the UDF input, but a package of several rows in the form of a Pandas Dataframe. However, the development of this functionality has not yet been completed , and even in this case, the difference will be significant .
An alternative would be to maintain an extensive team of data engineers capable of quickly closing the data scientist's needs with additional functions. Or, after all, immerse yourself in the world of Scala, since it’s not so difficult: many necessary tools already exist , tutorials appear that go beyond PySpark.
')
Source: https://habr.com/ru/post/443324/
All Articles