Zen Erlanga [and Elixir - approx. translator]
Introduction from the translator
This article is about Erlang , but everything said is equally applicable to Elixir , a functional language running on top of the same BEAM virtual machine. He appeared in 2012 and is now actively developing. Elixir has a more familiar syntax, plus extensive metaprogramming capabilities, while retaining the advantages of Erlang.
The article is from 2016, but we are talking about basic concepts that are not out of date.
References to concepts and comments from me (the translator) are located in square brackets [] and are provided with a pointer "comment of the translator".
If you find some parts of the translation insufficiently correct, especially in terms of terms, or you encounter any other errors - let me know, I will gladly correct it.
Special thanks to Jan Gravshin for help in proofreading and text editing.
This is a free transcript (or a long paraphrase?) Of my presentation at the ConnectDev'16 conference organized by Genetec.

I believe that the majority of people present here never programmed on Erlang. You may have heard about it, or you know the name. Therefore, my presentation will affect only the high-level concepts of Erlang, and in such a way as to be useful in your work or side projects, even if you never come across this language.

If you have ever been interested in Erlang, then heard about the motto "Let it crash" [ "Let it fall" - approx. translator ]. My first meeting with him made me think about what the hell was going on. It was assumed that Erlang is perfect for multi-thread execution and fault tolerance, but here I am offered to let everything fall: the exact opposite of the system behavior, which I actually want. The proposal is surprising, but, nevertheless, “Zen” Erlang is directly related to it.

In a sense, using "Let it Crash" for Erlang is as fun as "Blow it up" [ " Blow it up !" - approx. translator ] for rocket science. "Blow up", perhaps, the last thing you want in rocket science, and the Challenger disaster is a vivid reminder of this. On the other hand, if you look at the situation differently, then the rockets and their entire propulsion system deal with dangerous fuels that can and will explode (and this is a risky moment), but in a so controlled way that they can be used to organize spacecraft. traveling or sending payloads to orbit.
And the essence here is really in control; You can try to look at rocket science as a way to tame the explosions properly - or, at least, their power - to do whatever you want with them. In turn, you can take a look at “Let it crash” from the same angle: this is about fault tolerance. The idea is not in ubiquitous uncontrolled failures, it is to turn failures, exceptions and falls into tools that can be used.

Oncoming fell [ oncoming - approx. translator ] and controlled annealing is a real example of fighting fire with fire. In Saguenay-lac-Saint-Jean, the region where I come from, blueberry fields are regularly burned in a controlled manner to help stimulate and renew their growth. Often one can see unhealthy areas of the forest cleared by fire to prevent forest fires, so that this takes place under proper supervision and control. The main purpose is to remove combustible material so that a natural fire cannot spread further.
In all these situations, the destructive power of the fire that flies through crops or forests is used to rehabilitate crops or prevent much larger, unmanaged destruction of forests.
I believe that the meaning of "Let it crash" is precisely this. If we can take advantage of failures, crashes and exceptions, and make it a rather manageable way, then they will cease to be the frightening event that must be avoided, and instead will turn into a powerful building element for assembling large reliable systems.

Thus, the question becomes how to ensure that failures are more constructive than destructive. The main feature for this in Erlang is the process. Erlang processes are completely isolated and have an unshareable architecture (share nothing). No process can get into the memory of another or affect the work it does, distorting the data used. This is good because it means that the dying process with a 100% guarantee will keep its problems with itself, and provides your system with a very strong isolation of faults.
Erlang processes are also extremely lightweight, so thousands and thousands of them can work simultaneously without problems. The idea is to use as many processes as you need , rather than as many as you can afford . Imagine that there is an object-oriented programming language in which at any given time it is allowed to have a maximum of 32 objects running at the same time. You would quickly come to the conclusion that to create programs on it the restrictions are too strict and rather ridiculous. The presence of many small processes provides a higher variability of breakdowns. In a world where we want to put at the service the power of failures, this is good!
The mechanism of work processes in the Erlang may seem a bit strange. When you write a C program, you have one big main() function that does a lot of things. This is the entry point to the program. There is no such thing in Erlang. None of the processes is central. Each process starts a function, and this function plays the role of main() this particular process.
Now we have a swarm of bees, but it must be very difficult to send them to strengthen the hive, if they cannot communicate in any way. Where the bees are dancing [ dance of the bees - approx. translator ], Erlang processes are exchanging messages.

Messaging is the most intuitive form of communication in a competitive environment. She is one of the oldest people have dealt with, starting with the days when we wrote letters and sent them by courier on horseback, to more intricate mechanisms like Napoleon's semaphores [ optical semaphore - approx. translator ] shown in the illustration. In the latter case, you simply send a bunch of guys to the towers, give them a message, and they wave flags to transfer data over long distances in ways that were faster than tired horses. Gradually, this method was replaced by telegraph, which, in turn, changed the telephone and radio, and now we have all these modern technologies for sending messages really far and really fast.
An extremely important aspect of all this messaging, especially in the old days, is that everything was asynchronous and the messages were copied. No one stood on his porch for days waiting for the courier to return, and no one (I suspect) sat near the semaphore, waiting for an answer. You sent a message and went back to your business, and over time someone informed you that the answer came.
This is good - if the other side does not respond, you will not get stuck on your porch until death. Conversely, the recipient on the other hand will not be confronted with the fact that the newly arrived message suddenly magically disappeared or changed if you suddenly died. Data must be copied when sending messages. These two principles ensure that a failure during communication does not lead to a distorted or unrecoverable state [ condition - approx. translator ]. Erlang implements both.
Each process has its own inbox for all incoming messages. Anyone can write to the mailbox of the process, but only the owner of the box has the opportunity to look at it. By default, messages are processed in the order they are received, but some possibilities are of the type of pattern matching [ pattern matching - approx. translator ] allow you to change priorities and permanently or temporarily focus on any one type of message.

Some of you will notice strangeness in what I say. I keep repeating that isolation and independence are so wonderful that the components of the system are allowed to die and fall without affecting the rest. But I also mentioned communication between multiple processes or agents.
Each time at the beginning of a dialogue between two processes, an implicit relationship appears between them. An implicit state arises in the system that binds both to each other. If process A sends a message to process B, and B dies without responding, A can either wait for a response forever, or after some time, refuse to communicate. The second is an acceptable strategy, but very ambiguous: it’s completely unclear whether the remote side has died or is just so long busy, and messages without context can land in your mailbox.
Instead, Erlang gives us two mechanisms to solve this problem: monitors and binding [ links - approx. translator ].
Monitors are about being an observer. You decide to look after the process, and if it dies for some reason, a message will be sent to your inbox to notify you of the incident. To this you can respond and make decisions based on the detected information. The second process will never know that you have been doing all this. Therefore, the monitors are pretty good if you are an observer [ observer - watch the state of the processes - approx. translator ] or care about partner status.
Links [ links - approx. translator ] - bidirectional, and the creation of such a one brings together the fates of both related processes together. When a process dies, all related processes receive a command to complete. [ Exit signal - approx. translator ]. This command, in turn, kills others . translator ] processes.
All of this becomes really interesting, because you can use monitors to quickly detect failures, and you can use the binding as an architectural structure that allows you to combine several processes so that the failure spreads to them as a whole. Whenever my independent building blocks have dependencies on each other, I can start adding it to the program. This is useful because it prevents the system from accidentally falling into unstable partially altered states. Connections are guaranteed to developers: if something broke, it broke completely, leaving behind a clean sheet, and had no effect on the components that did not participate in the exercise.
For this illustration, I chose an image of climbers connected by a safety line. If climbers are connected only with each other, they will be in a miserable situation. Each time one climber slips away, the rest of the team will immediately die. Not a good way to do business.
Instead, Erlang allows you to specify that some processes are special, and mark them with the trap_exit parameter. Then they will be able to receive exit commands sent via links and convert them into messages. This will allow them to troubleshoot and possibly load a new process to do the work of the deceased. Unlike climbers, a special process of this type cannot prevent the partnership process from falling; this is the responsibility of the partner itself, implemented, for example, using try ... catch constructs. The process that catches the exits still does not have the ability to play in the memory of another and save it, but can avoid joint death.
This becomes a decisive opportunity for creating supervisors. We will get to them very soon.

Before moving on to supervisors, take a look at the few remaining ingredients that will allow you to successfully prepare a system that uses drops for its own benefit. One of them is related to how the process scheduler works. The real case that I would like to refer to is the landing on the moon of Apollo 11 [ Apollo 11 - approx. translator ].
Apollo 11 is a mission that went to the moon in 1969. In the image we see a lunar module with Buzz Aldrin and Neil Armstrong on board, and the photo was taken, I believe, by Michael Collins, who remained in the command module.
On the way to landing on the moon, the module was controlled by Apollo PGNCS (Primary Guidance, Navigation and Control System) [ Apollo PGNCS - approx. translator ]. The control system performed several tasks with a carefully calculated number of cycles [ CPU - approx. translator ] each. NASA also found that the processor should be used for no more than 85% of its capacity, with a free 15% in reserve.
Since the astronauts wanted to have a reliable backup plan in case they had to interrupt the mission, they left the radar on the meeting with the command and service module turned on - it would come in handy. This decently loaded the remaining CPU power. As soon as Buzz Aldrin began to enter commands, messages began to appear about overloading and, in fact, about exceeding the available computing power. If the system had gone astray from this, it probably would not have been able to do its work, and everything would have ended with two dead astronauts.
The first overload occurred because the radar had a known hardware problem, causing its frequency to mismatch with the frequency of the control computer, which led to a "theft" of a much larger number of cycles than would otherwise be used. People at NASA were not idiots, and instead of using new technologies that were not tested in real work, they reused proven components for such an important mission that they knew about rare errors. But, more importantly, they invented scheduling by priorities.
This means that when this radar, or perhaps the commands entered, gave the processor too much work, their tasks were killed in order to give the CPU cycles vital things that have a higher priority and really need them. That was in 1969. Today there are still quite a few languages and frameworks that offer only cooperative dispatching and nothing else.
Erlang is not the language that should be used for vital systems, it takes into account only soft real -time constraints. translator ], not real-time constraints, and therefore using it for such scenarios would not be a very good idea. But Erlang provides proactive planning. [ It’s also preemptive multitasking, preemptive scheduling. translator ] and prioritize processes. This means that you, as a system developer or system architect, do not have to take care that in order to prevent freezes, everyone will carefully calculate the CPU load required for their components (including the libraries used). They simply can not get that power. And if you want an important task to be performed whenever necessary, you can also provide it.
This does not look like a serious or frequent requirement, and people still release really successful projects based solely on cooperative dispatching of parallel processes, but certainly extremely valuable because it protects you from other people's mistakes, as well as from your own. It also opens the door to mechanisms such as automatic load balancing, “punishing bad” or “encouraging good” processes, or assigning higher priorities to processes with more tasks. All this ultimately makes your systems sufficiently adaptable to loads and unforeseen events.

The last component that I would like to discuss as part of ensuring decent resiliency is the ability to work online. In any system that is developed with an eye on long-term activity, the ability to run on more than one computer is quickly becoming a requirement. You do not want to sit somewhere locked up behind the titanium doors with your gold machine, without being able to compensate for the failures that mainly affect your users.
So sooner or later you will need two computers so that one survives the second, and possibly the third, if there is a desire to deploy part of your system during breakdowns.
The plane in the illustration - F-82 "Twin Mustang" [ F-82 "Twin Mustang" - approx. translator ], an aircraft developed during World War II to escort bomber over distances that most other fighters simply could not cover. He had two cabins, so that the pilots could control the device in shifts; at the right moment there was an opportunity to divide the duties so that one pilot could lead the aircraft, and the second was to control the radar as an interceptor. Modern aircraft still have similar capabilities; they have countless backup systems, and often the crew members sleep during the flight so that there is always someone who is ready to take control of the aircraft if necessary.
As for programming languages or development environments, most of them are designed without the possibility of distributed work, although it is clear that when developing the server stack you will need to work with more than one server. However, if you are going to work with files, the standard library has tools for this. The most that most languages can give you is socket support or an HTTP client.
Erlang pays tribute to the reality of distributed systems and offers an implementation for their creation, which is documented and transparent. , , - [ pylyglot systems — . ].

" ". - , . "Let it crash" , , .
— .

[ supervision trees — . ] — , . — , — — , . , — "OTP", , "Erlang/OTP" [ OTP — Open Telecom Platform — . ].
— , , , , , "" . , : , , .
, , , , — .
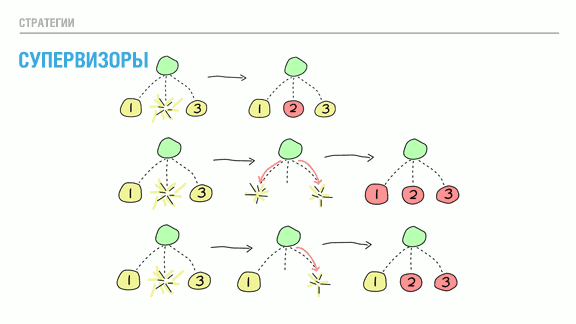
. " , ". , . .
. " " [ one for one — . *]. . , .
— " " [ one for all — . *]. , . , , . , . , . , , . , , !
, , , . , . : , .
, . — " " [ rest for one — . ]. , , . .
[ , — — . ] . 1 , 150 .

, , " , !"
. , , , . "" [ — . ] "" [ — . ], Jim Gray 1985 ( Jim Gray, !)
-, — , , . . , , . , , , , .
— , , , . , , . , , .
, , .

, — .
, . , , .
, — , , . , — ; . , , . , , , .
, , .
. , , [ Property-Based Testing Basics , Property-based testing — . ] ( ), — - , . , , , .

( ). , , .
, . , , , , . - -.
. , , , , , , .
, . Jim Gray, , , 132 , , . 131 132 , , . , , , , ; , , , 100 000 , — 10 , - .
, , .

?
, . . , . , , . , "" Facebook ( ), , , Facebook .
, , , , . , , .
, . : , , , , .
, ( ), , . , .

, , . , , , .
, , .
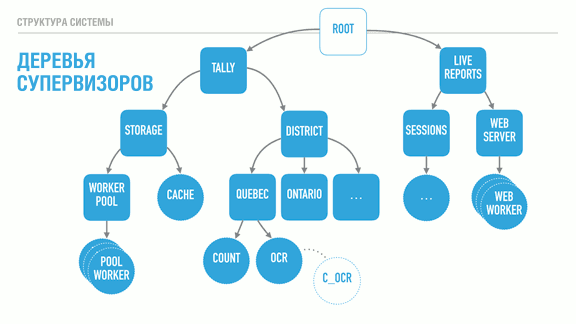
() . , : . Tally () , Live Reports ( ) .
, . District (; ) , (Storage). (Cache) ( ) (Worker pool).
[ supervision strategies — . ], , , , . , " ", , , . ( ) " ". , (OCR) , , . , , , , .
OCR , C , . , C, , , .
, , , . 10 , , , .
, , . , . — , .
, , , . OCR C , . OCR . . , , ( ). , , — , .
OCR , . , , — . — . , , , , - , .
, . , — - , - ( ) , . , — , . — let it crash!
. , if/else , switch ', try/catch . , , , . [ , — . ], .
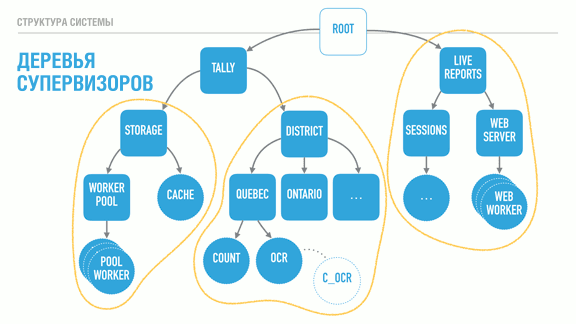
, , , , . : , .
, , , . (, SMS).
, , , , , .
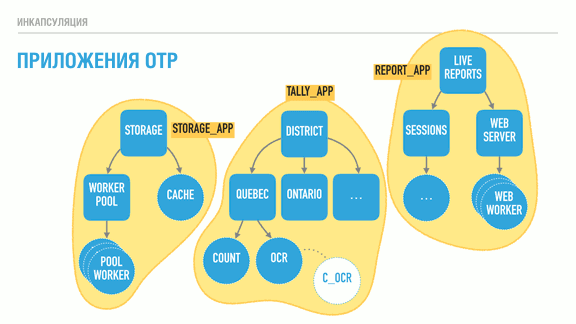
OTP. OTP- — , . , , . , , , . , , , .
, OTP- . OTP-, . [: OTP-, , ]
:
- , ;
- , , , ;
- , ;
- , , , , ;
- ( , );
- .
. , . , , . , — , , .

, ? , . , Heroku .
. (vegur) , , , . , , .
- , . , : 500 000 1 000 000 ! , . ? , , , 100 000 , ? - 1:17000 1:7000. , , , .
, . , , , . , . , , .

. .
, - : " , . , , , . , , . , ."
. .
, , , 60 . ( United 734), , , , - . , , , , ABS, .
( ), . , . , , .
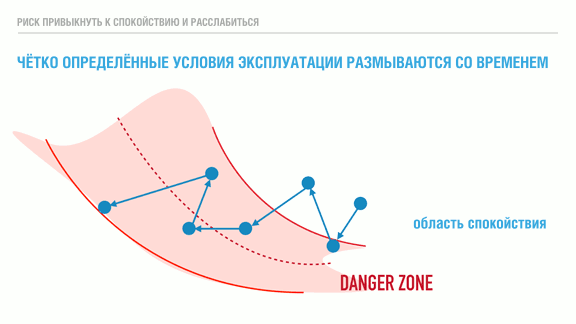
, . ( , ) Richard Cook. , YouTube, .
- . , , , .. — ( , , ..) , , - , .
, , , . , , - - .
, , , . , . , . - - , , , .

, . , , : , . . , , , .
, , , . .

, , . , , , .
. , , , - , , , , , . , .

, 'let it crash' — , , , , , — , , , . . fail-fast , , " ", .
, . , , . . , , . Let it crash.

: , , , — . , ( , !) .
')
Source: https://habr.com/ru/post/443290/
All Articles