We demystify convolutional neural networks
Translation Demystifying Convolutional Neural Networks .

Convolutional neural networks.
In the past decade, we have witnessed amazing and unprecedented progress in the field of computer vision. Today, computers are able to recognize objects in images and video frames with an accuracy of 98%, already ahead of a person with his 97%. It was the functions of the human brain that inspired developers to create and improve recognition techniques.
')
Once, neurologists conducted experiments on cats and found that the same parts of the image activate the same parts of the cat's brain. That is, when a cat looks at a circle, the alpha zone is activated in its brain, and when it looks at the square, the beta zone is activated. The researchers concluded that in the brain of animals there are areas of neurons that respond to specific image characteristics. In other words, animals perceive the environment through the multilayered neural architecture of the brain. And each scene, each image passes through a peculiar block of feature extraction, and only then it is transferred to deeper brain structures.
Inspired by this, mathematicians developed a system in which groups of neurons are emulated, triggering on different image properties and interacting with each other to form an overall picture.
The idea of a group of activated neurons that are supplied with specific input data was turned into a mathematical expression of a multidimensional matrix that plays the role of a determinant of some set of properties — it is called a filter or a kernel. Each such filter is looking for some feature in the image. For example, there may be a filter for defining boundaries. The properties found are then transferred to another set of filters that are able to determine higher-level image properties, for example, eyes, nose, etc.
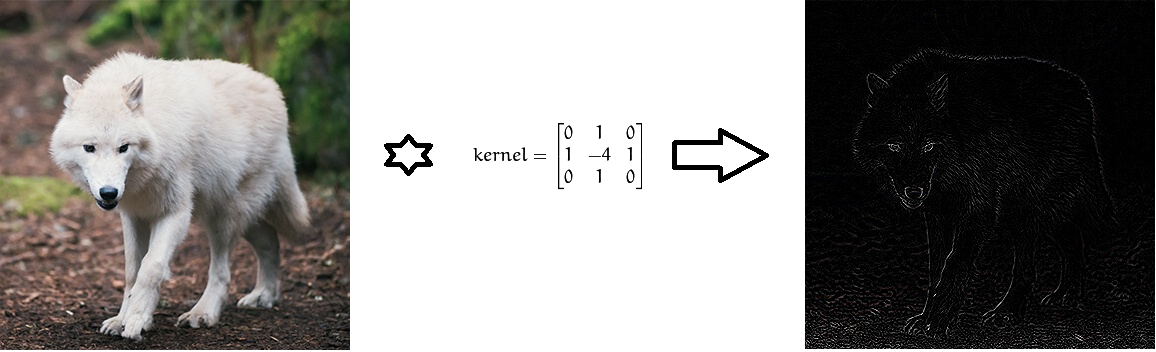
Convolve images using Laplace filters to define borders.
From the point of view of mathematics, between the input image, represented as a matrix of pixel intensity, and the filter, we perform a convolution operation, resulting in a so-called property map (feature map). This map will serve as input for the next layer of filters.
Convolution is the process by which the network tries to mark the input signal by comparing it with previously recognized information. If the input signal looks like previous images of cats, already known networks, then the reference signal "cat" will be minimized - mixed - with the input signal. The resulting signal is transmitted to the next layer. In this case, the input signal refers to the three-dimensional representation of a picture as the intensities of RGB pixels, and the reference signal “cat” is learned by the core for recognizing cats.
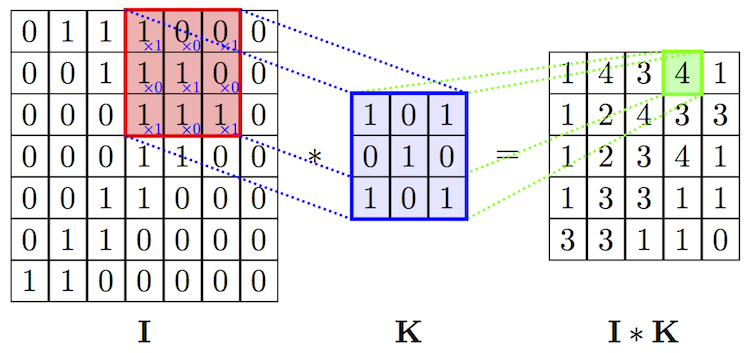
The operation of the image convolution and filter. Source of
The folding operation has an excellent property - translation invariance (translation invariant). This means that each convolutional filter reflects a certain set of properties, for example, eyes, ears, etc., and the convolutional neural network algorithm learns to determine which set of properties corresponds to the reference, say, a cat. The intensity of the output signal does not depend on the location of the properties, but on their presence. Consequently, the cat can be depicted in different poses, but the algorithm can still recognize it.
Tracing the principle of the biological brain, scientists were able to develop a mathematical apparatus for extracting properties. But, having estimated the total number of layers and properties that need to be analyzed to track complex geometric shapes, the scientists realized that computers did not have enough memory to store all the data. Moreover, the amount of computing resources required grows exponentially along with the increase in the number of properties. To solve this problem, a pooling technique was developed. Her idea is very simple: if a certain area contains pronounced properties, we can refuse to search for other properties in this area.

Example of maximum value pooling.
The operation of pooling allows not only to save memory and computing power, but also helps to clean the image from noise.
Okay, but why can a neural network be useful if it can only define sets of image properties? We need to somehow teach her to classify images into categories. And this will help us the traditional approach to the formation of neural networks. In particular, the property maps obtained on the previous layers can be assembled into a layer that is fully associated with all the labels that we have prepared for categorization. This last layer will assign probabilities of matching to each class. And based on these final probabilities, we will be able to attribute the image to some category.
Fully bonded layer. Source of
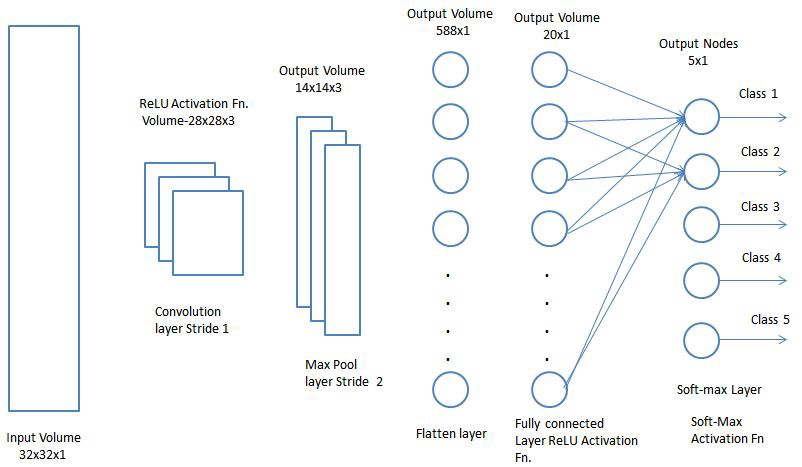
Now it remains only to combine all the concepts studied by the network into a single framework - the convolutional neural network (CNN). CNN consists of a series of convolutional layers that can be combined with pooling layers to generate a property map that is passed to fully connected layers to determine the likelihood of matching any classes. Returning the resulting errors, we will be able to train this neural network until accurate results are obtained.
Now that we understand the functional perspectives of CNN, let's take a closer look at aspects of using CNN.

Convolutional layer
The convolutional layer is the main building block of CNN. Each such layer includes a set of independent filters, each of which looks for its own set of properties in the incoming image.
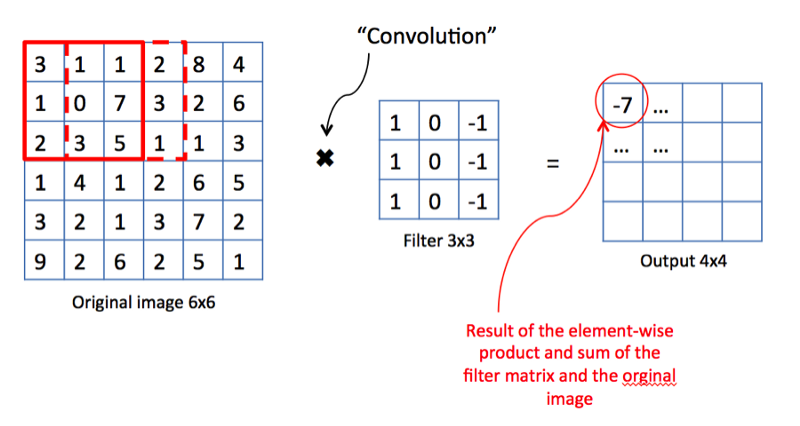
Convolution operation. Source of
From the point of view of mathematics, we take a filter of a fixed size, impose on the image and calculate the scalar product of the filter and a piece of the input image. The results of the work are placed in the final property map. Then we shift the filter to the right and repeat the operation, also adding the result of the calculation to the property map. After convolving the entire image using the filter, we get a property map, which is a set of obvious signs and served as input to the next layer.
Stride is the amount of displacement of the filter. In the above illustration, we shift the filter by a factor of 1. But sometimes you need to increase the size of the offset. For example, if neighboring pixels are strongly correlated with each other (especially on the lower layers), then it makes sense to reduce the size of the output data using the appropriate stride. But if the stride is made too large, then a lot of information will be lost, so be careful.
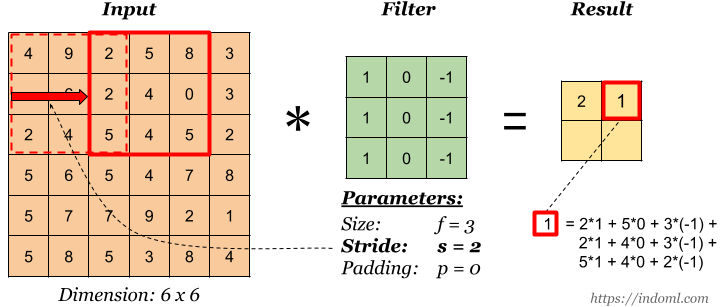
Stride is 2. Source .
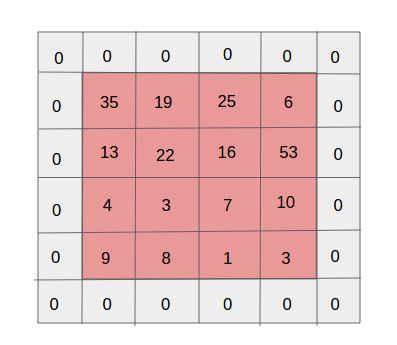
Padding single layer. Source of
One of the side effects of striding is the gradual reduction of the property map as more and more new packages are executed. This may be undesirable because “reducing” means losing information. To make it clearer, pay attention to the number of applications of the filter to the cell in the middle part and in the corner. It turns out that for no reason the information in the middle part is more important than at the edges. And to extract useful information from earlier layers, you can surround the matrix with layers of zeros.
Why do we need convolutional networks if we already have good deep learning neural networks? It is noteworthy that if we use deep learning networks for classifying images, the number of parameters on each layer will be a thousand times larger than that of the convolutional neural network.

The sharing of parameters in the convolutional neural network.
Convolutional neural networks.
In the past decade, we have witnessed amazing and unprecedented progress in the field of computer vision. Today, computers are able to recognize objects in images and video frames with an accuracy of 98%, already ahead of a person with his 97%. It was the functions of the human brain that inspired developers to create and improve recognition techniques.
')
Once, neurologists conducted experiments on cats and found that the same parts of the image activate the same parts of the cat's brain. That is, when a cat looks at a circle, the alpha zone is activated in its brain, and when it looks at the square, the beta zone is activated. The researchers concluded that in the brain of animals there are areas of neurons that respond to specific image characteristics. In other words, animals perceive the environment through the multilayered neural architecture of the brain. And each scene, each image passes through a peculiar block of feature extraction, and only then it is transferred to deeper brain structures.
Inspired by this, mathematicians developed a system in which groups of neurons are emulated, triggering on different image properties and interacting with each other to form an overall picture.
Retrieving Properties
The idea of a group of activated neurons that are supplied with specific input data was turned into a mathematical expression of a multidimensional matrix that plays the role of a determinant of some set of properties — it is called a filter or a kernel. Each such filter is looking for some feature in the image. For example, there may be a filter for defining boundaries. The properties found are then transferred to another set of filters that are able to determine higher-level image properties, for example, eyes, nose, etc.
Convolve images using Laplace filters to define borders.
From the point of view of mathematics, between the input image, represented as a matrix of pixel intensity, and the filter, we perform a convolution operation, resulting in a so-called property map (feature map). This map will serve as input for the next layer of filters.
Why the bundle?
Convolution is the process by which the network tries to mark the input signal by comparing it with previously recognized information. If the input signal looks like previous images of cats, already known networks, then the reference signal "cat" will be minimized - mixed - with the input signal. The resulting signal is transmitted to the next layer. In this case, the input signal refers to the three-dimensional representation of a picture as the intensities of RGB pixels, and the reference signal “cat” is learned by the core for recognizing cats.
The operation of the image convolution and filter. Source of
The folding operation has an excellent property - translation invariance (translation invariant). This means that each convolutional filter reflects a certain set of properties, for example, eyes, ears, etc., and the convolutional neural network algorithm learns to determine which set of properties corresponds to the reference, say, a cat. The intensity of the output signal does not depend on the location of the properties, but on their presence. Consequently, the cat can be depicted in different poses, but the algorithm can still recognize it.
Pooling
Tracing the principle of the biological brain, scientists were able to develop a mathematical apparatus for extracting properties. But, having estimated the total number of layers and properties that need to be analyzed to track complex geometric shapes, the scientists realized that computers did not have enough memory to store all the data. Moreover, the amount of computing resources required grows exponentially along with the increase in the number of properties. To solve this problem, a pooling technique was developed. Her idea is very simple: if a certain area contains pronounced properties, we can refuse to search for other properties in this area.
Example of maximum value pooling.
The operation of pooling allows not only to save memory and computing power, but also helps to clean the image from noise.
Fully connected layer
Okay, but why can a neural network be useful if it can only define sets of image properties? We need to somehow teach her to classify images into categories. And this will help us the traditional approach to the formation of neural networks. In particular, the property maps obtained on the previous layers can be assembled into a layer that is fully associated with all the labels that we have prepared for categorization. This last layer will assign probabilities of matching to each class. And based on these final probabilities, we will be able to attribute the image to some category.
Fully bonded layer. Source of
Final architecture
Now it remains only to combine all the concepts studied by the network into a single framework - the convolutional neural network (CNN). CNN consists of a series of convolutional layers that can be combined with pooling layers to generate a property map that is passed to fully connected layers to determine the likelihood of matching any classes. Returning the resulting errors, we will be able to train this neural network until accurate results are obtained.
Now that we understand the functional perspectives of CNN, let's take a closer look at aspects of using CNN.
Convolutional neural networks
Convolutional layer
The convolutional layer is the main building block of CNN. Each such layer includes a set of independent filters, each of which looks for its own set of properties in the incoming image.
Convolution operation. Source of
From the point of view of mathematics, we take a filter of a fixed size, impose on the image and calculate the scalar product of the filter and a piece of the input image. The results of the work are placed in the final property map. Then we shift the filter to the right and repeat the operation, also adding the result of the calculation to the property map. After convolving the entire image using the filter, we get a property map, which is a set of obvious signs and served as input to the next layer.
Strides
Stride is the amount of displacement of the filter. In the above illustration, we shift the filter by a factor of 1. But sometimes you need to increase the size of the offset. For example, if neighboring pixels are strongly correlated with each other (especially on the lower layers), then it makes sense to reduce the size of the output data using the appropriate stride. But if the stride is made too large, then a lot of information will be lost, so be careful.
Stride is 2. Source .
Padding
Padding single layer. Source of
One of the side effects of striding is the gradual reduction of the property map as more and more new packages are executed. This may be undesirable because “reducing” means losing information. To make it clearer, pay attention to the number of applications of the filter to the cell in the middle part and in the corner. It turns out that for no reason the information in the middle part is more important than at the edges. And to extract useful information from earlier layers, you can surround the matrix with layers of zeros.
Sharing Parameters
Why do we need convolutional networks if we already have good deep learning neural networks? It is noteworthy that if we use deep learning networks for classifying images, the number of parameters on each layer will be a thousand times larger than that of the convolutional neural network.
The sharing of parameters in the convolutional neural network.
Source: https://habr.com/ru/post/443236/
All Articles