5 lifehacks optimize SQL queries in Greenplum

Any processes related to the database, sooner or later, will face performance problems with requests to this database.
The data warehouse of Rostelecom is built on Greenplum, most of the calculations (transform) are performed by sql queries that start (or generate and run) the ETL mechanism. DBMS has its own nuances that significantly affect performance. This article is an attempt to highlight the most critical, in terms of performance, aspects of working with Greenplum and share experience.
')
In a nutshell about Greenplum
Greenplum - MPP server database, the core of which is built on PostgreSql.
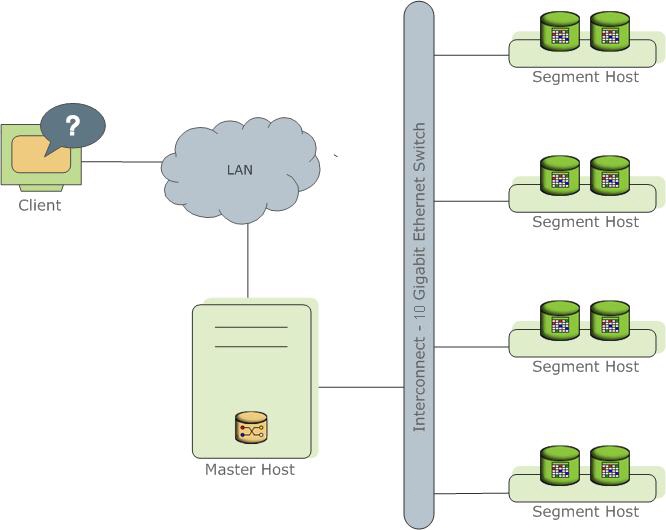
Represents several different instances of the PostgreSql process (instances). One of them is the entry point for the client and is called master instance (master), all the others are Segment instances (segment, Independent instances, each of which has its own piece of data). On each server (segment host) one to several services (segment) can be launched. This is done in order to better utilize server resources and first of all processors. The wizard stores metadata, is responsible for connecting clients with data, and also distributes work between segments.
You can read more in the official documentation .
Represents several different instances of the PostgreSql process (instances). One of them is the entry point for the client and is called master instance (master), all the others are Segment instances (segment, Independent instances, each of which has its own piece of data). On each server (segment host) one to several services (segment) can be launched. This is done in order to better utilize server resources and first of all processors. The wizard stores metadata, is responsible for connecting clients with data, and also distributes work between segments.
You can read more in the official documentation .
Further in the article there will be many references to the query plan. Information for Greenplum can be obtained here .
How to write good requests for Greenplum (or at least not quite sad)
Since we are dealing with a distributed database, it is important not only how the sql query is written, but also how the data is stored.
1. Distribution
Data is physically stored in different segments. Splitting data by segment can be randomly or by hash value from a field or a set of fields.
Syntax (when creating a table):
DISTRIBUTED BY (some_field) Or so:
DISTRIBUTED RANDOMLY The distribution field must have good selectivity and not have null values (or have a minimum of such values), since records with such fields will be distributed into one segment, which can lead to data distortions.
The field type is preferably integer. The field is used to join the tables. Hash join is one of the best ways to join tables (in terms of query execution), it works best with this data type.
For distribution, it is desirable to choose no more than two fields, and, of course, one is better than two. Additional fields in distribution keys, firstly, require additional time for hashing, and secondly, (in most cases) will require the transfer of data between segments when executing joins.
You can use a random distribution if you did not manage to pick up one or two suitable fields, as well as for small tablets. But we must bear in mind that such a distribution works best when mass data is inserted, and not one record at a time. GreenPlum distributes data according to a cyclic algorithm, and it launches a new cycle for each insert operation, starting with the first segment, which, with frequent small inserts, leads to data skew.
With a well-chosen distribution field, all calculations will be performed on the segment, without sending data to other segments. Also, for optimal joining of tables (join), the same values should be located on the same segment.
Distribution in pictures
Good distribution key:

Badly chosen distribution key:

Random distribution:

Badly chosen distribution key:
Random distribution:
The type of fields used in join must be the same in all tables.
Important: do not use as distribution fields those used in filtering queries in where, since in this case the load will not be evenly distributed when the query is executed.
2. Partitioning
Partitioning allows you to split large tables, for example, facts , into logically separated pieces. Greenplum physically divides your table into separate tables, each of which distributes into segments based on the settings in Section 1.
Tables should be divided into sections logically, choose for this purpose the field, often used in the where block. In fact tables this will be a period. Thus, with proper access to the table in the queries, you will only work with part of the entire large table.
In general, partitioning is a fairly well-known topic, and I wanted to emphasize that you should not choose the same field for partitioning and distribution. This will lead to the fact that the query will be executed entirely on one segment.
It's time to go, in fact, to requests. The request will be executed on segments according to a certain plan :
3. Optimizer
Greenplum has two optimizers, a built-in legacy optimizer and a third-party Orca optimizer: GPORCA - Orca - Pivotal Query Optimizer.
Enable GPORCA on request:
set optimizer = on; As a rule , the GPORCA optimizer is better than the built-in one. It works more adequately with subqueries and CTE (more here ).
Outstanding access to a large table in the CTE with maximum data filtering (do not forget about partition pruning) and a clearly specified list of fields - works very well.
It slightly modifies the query plan, for example, otherwise displays the scanned partitions:
Standard Optimizer:

Orca:

GPORCA also allows you to update partitioning / distribution fields. Although there are situations when the built-in optimizer works better. The third-party optimizer is very demanding on statistics, it is important not to forget to analyze .
No matter how good the optimizer may be, a poorly written query even Orca does not pull:
4. Manipulations with fields in the where block or join conditions
It is important to remember, the function applied to the filter field or join conditions is applied to each record.
In the case of a partitioning field (for example, date_trunc to the partitioning field — the date), even GPORCA cannot correctly work out in such a case, partition cutting will not work.
-- set optimizer = on; explain select * from edw_ods.t_000045_bills c where date_trunc('month',tech_dt) between to_date('20180101', 'YYYYMMDD') and to_date('20180101', 'YYYYMMDD') + interval '1 month - 1 second' ; 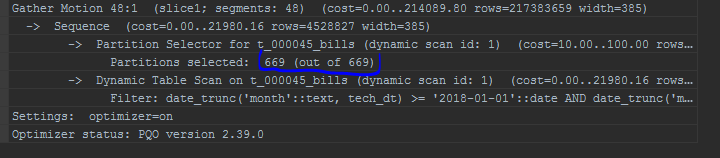
-- set optimizer = on; explain select * from edw_ods.t_000045_bills c where tech_dt between to_date('20180101', 'YYYYMMDD') and to_date('20180101', 'YYYYMMDD') + interval '1 month - 1 second' 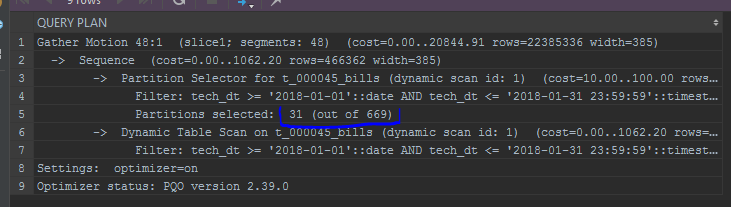
I also pay attention to the display of partitions. The built-in optimizer will display partitions with the list:

With care to apply functions to constants in the same filters on a partition. An example is the same date_trunc:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD')) 
GPORCA will cope with such tricks and work correctly, the standard optimizer can no longer cope. However, by making an explicit type conversion, you can make it work as well:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone 
And if everything is done wrong?
5. Motions
Another type of operation that can be observed in the query plan is motions. So marked the movement of data between segments:
- Gather motion - will be displayed in almost every plan, means combining the results of executing queries from all segments into one stream (as a rule, on the master).
Two tables, distributed by one key, which is used for the join, perform all operations on the segments, without moving data. Otherwise, Broadcast motion or Redistribution motion occurs: - Broadcast motion - each segment sends its copy of the data to other segments. In an ideal situation, broadcast happens only for small tables.
- Redistribution motion - to join large tables distributed across different keys, redistribution is performed to make connections locally. For large tables it can be quite a costly operation.
Broadcast and Redistribution are quite unprofitable operations. They are executed each time the query is run. It is recommended to avoid them. Having seen such items in the query plan, you should pay attention to the distribution keys. Also, the distinct and union operations cause motions.
This list is not exhaustive and is based primarily on the experience of the author. It did not work to find everything at once on the Internet in due time. Here I tried to identify the most critical factors affecting the performance of the request, and figure out why and why this happens.
The article was prepared by the data management team of Rostelecom.
Source: https://habr.com/ru/post/442758/
All Articles