Reverse engineering of a binary format on the example of Korg .SNG files

We live in amazing time. There is an abundance of technology around us: phones, computers, smart watches and other gadgets. Every day, manufacturers put on the market more and more new devices. Most of them are destined to have a short and bright (or not so) life: a powerful marketing company at the time of release, 1-2 years of full-fledged support by the manufacturer, and then a slow oblivion. Simple devices can work for years after the expiration of the official support. With smart devices everything is more complicated. Well if the gadget at least continues to work after disconnecting the server / services of the manufacturer. And lucky if the next update of the OS, drivers or other software will not beat compatibility.
Unfortunately, more and more events are developing in a pessimistic scenario. And 5-10 years after the purchase, we have technically sound devices in our hands, which nevertheless cannot be used due to the lack of software support. Of course, a broken gadget is unpleasant. But much more unpleasant, if there is user data in a format incompatible with anything. This data can be considered lost if the device ceases to function. In my case, the worst has not happened yet, but the alarm bells are already ringing.
So, there is a well-known firm Korg, which produces very high-quality musical equipment. In 2010, I bought a synthesizer from this company for music as a hobby. Korg microstation is a fairly advanced model. Among other things, he has onboard a sequencer for recording his own tracks and can write data to a memory card in proprietary SNG format. It is possible to export to the common midi format, but almost all the metadata is lost: information about the effects and filters applied, various settings of virtual instruments, etc. The main problem for me personally is the speed of transition to the recording of musical ideas. The muse is a capricious creation, and I often come across an interesting idea simply by improvising or playing some uncomplicated something. The faster I press the record button without wandering around the menu, the more likely I can repeat and write down an interesting piece, which in the future may become part of a full-fledged work. Of course, this approach is not ideal, but we are talking about a hobby. Anyway, for almost ten years, I have accumulated about a thousand musical sketches and sketches in SNG format.
')
The bell rang in the form of a series of synthesizer glitches that required a flashing of the device. And I thought about transferring all my accumulated data to Midi format, all the more so as it will make it much easier to store, organize and edit them. Search converter in Google did not give anything. There are many requests in various forums, the history of the issue has been going on for 20 years, if not more. All I found was someone's ancient Windows utility, naturally incompatible with my files.
And then I decided to try to see what is this SNG format? Maybe somewhere inside there are normal midi data that you can easily pull out and save?
Attempt to solve the problem "in the forehead"
So, from the instructions for the synthesizer, you can find out that the SNG format is a container in which so-called “songs” are stored. Each song contains 16 tracks of a sequencer with musical data, as well as sound and effect settings. When exporting to the Midi format via the synthesizer menu, each “song” is exported to a separate .MID file, and all settings for sounds and effects are lost. Since I play my ideas in the simplest form and without effects, the problem is precisely the large number of SNG files and the inconvenience of the manual conversion process. Let's see if this process cannot be accelerated or automated.
First, remember what midi data is. Simply put, this is a flow of musical events: pressing and releasing a key, pressing and releasing a sustain pedal, changing tempo, patch (virtual instrument) and other parameters. Each event contains a temporary delta since the previous event and data such as intensity and pitch of a note. The format of the midi file is very simple: there is practically nothing besides the headers and the data itself.
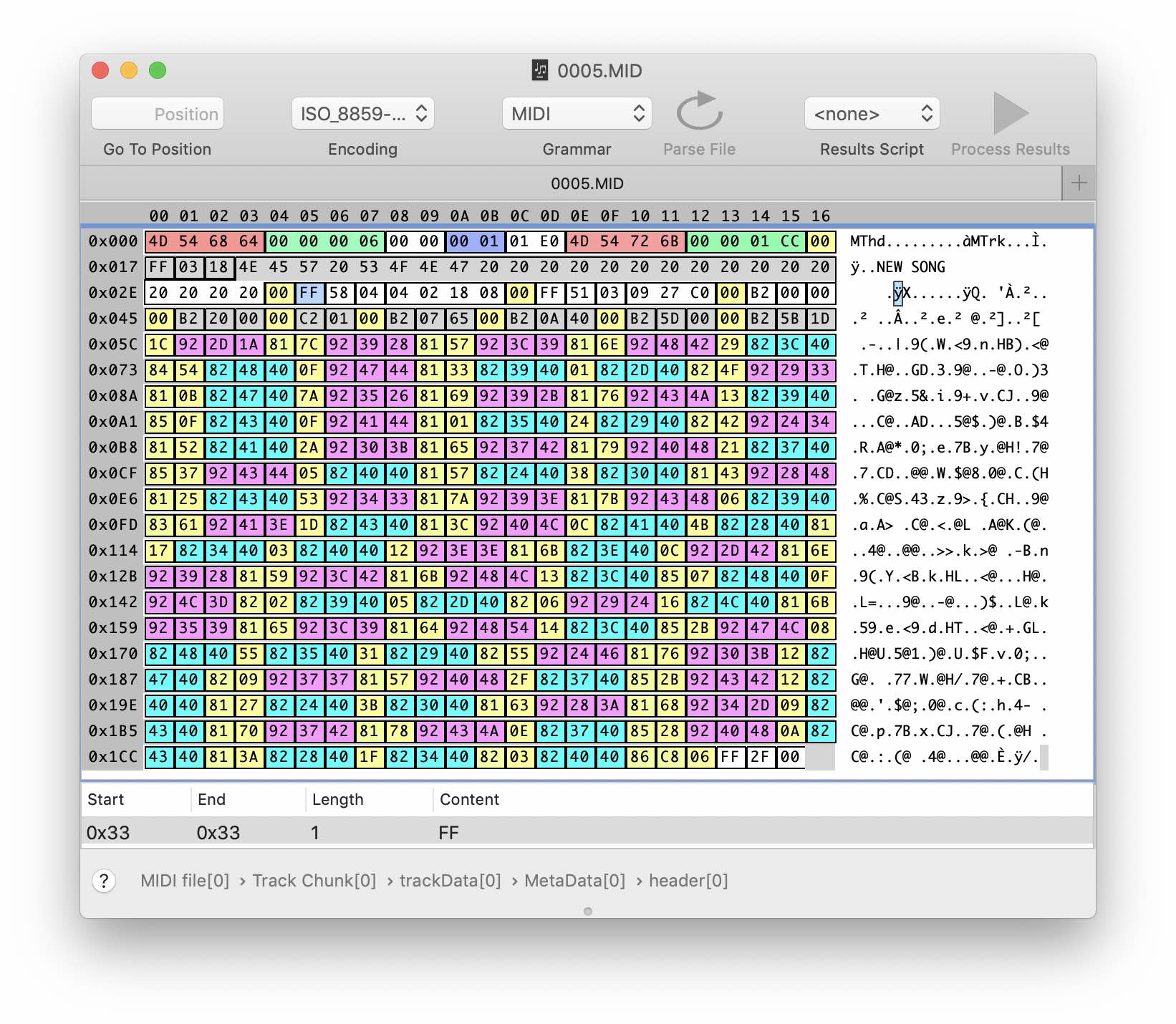
Pink is a Note On event. Pale yellow is the delta of time. Blue is a Note Off event.
Let's try to find our midi data in the SNG file. To do this, we write down a sequence of several notes on the synthesizer and export them in both formats. Since we don’t know where the music data is located in binary files, then we will try to repeat the process with different sequences of notes.
Here and then I use Synalyze It! Hex-editor! Its capabilities will be very useful in the future. In the meantime, just use the function of comparing binary files.
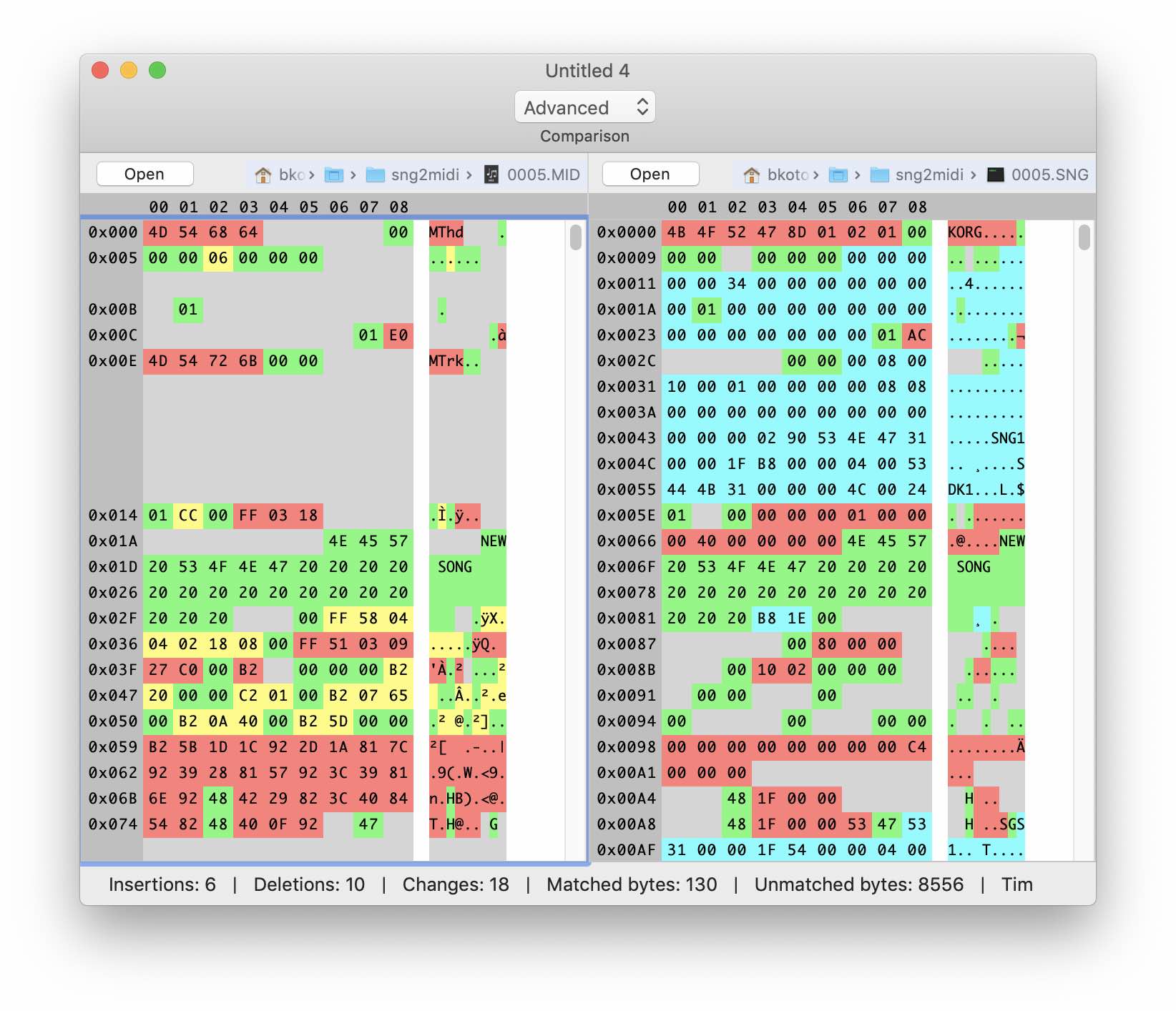
In fact, only the name of the song coincided. By comparing two SNG files with different sequences of notes, you can roughly guess where the music data is stored, but this will not help us so far - the data format is different. The file itself is dozens of times larger than the Midi file, and apparently contains a lot of additional information. You can see the KORG signature in the first four bytes and some other lines, including the name of the song and the names of the patches (voices) assigned to the tracks.
Parsing the data block structure
This could have been completed if, fortunately, there were no tools that would allow relatively easy to analyze and understand the structure of the data stored in binary form. This will help us all the same program Synalaze It!, Which allows you to create and use the "grammar" for the analysis of binary files.
A grammar is a hierarchical descriptive structure that allows you to represent binary data in a form understandable to humans. The program allows you to download grammars for some formats. For example, for the same midi:
For the SNG format, the finished grammar was not expected. Well, let's see what we can extract from the file on our own.
Let's start with the title. Typically, this part contains the file signature, version information, dimensions and offsets of the data blocks. By comparing several different SNG files, we find the unchanged parts and pay more attention to those that change.
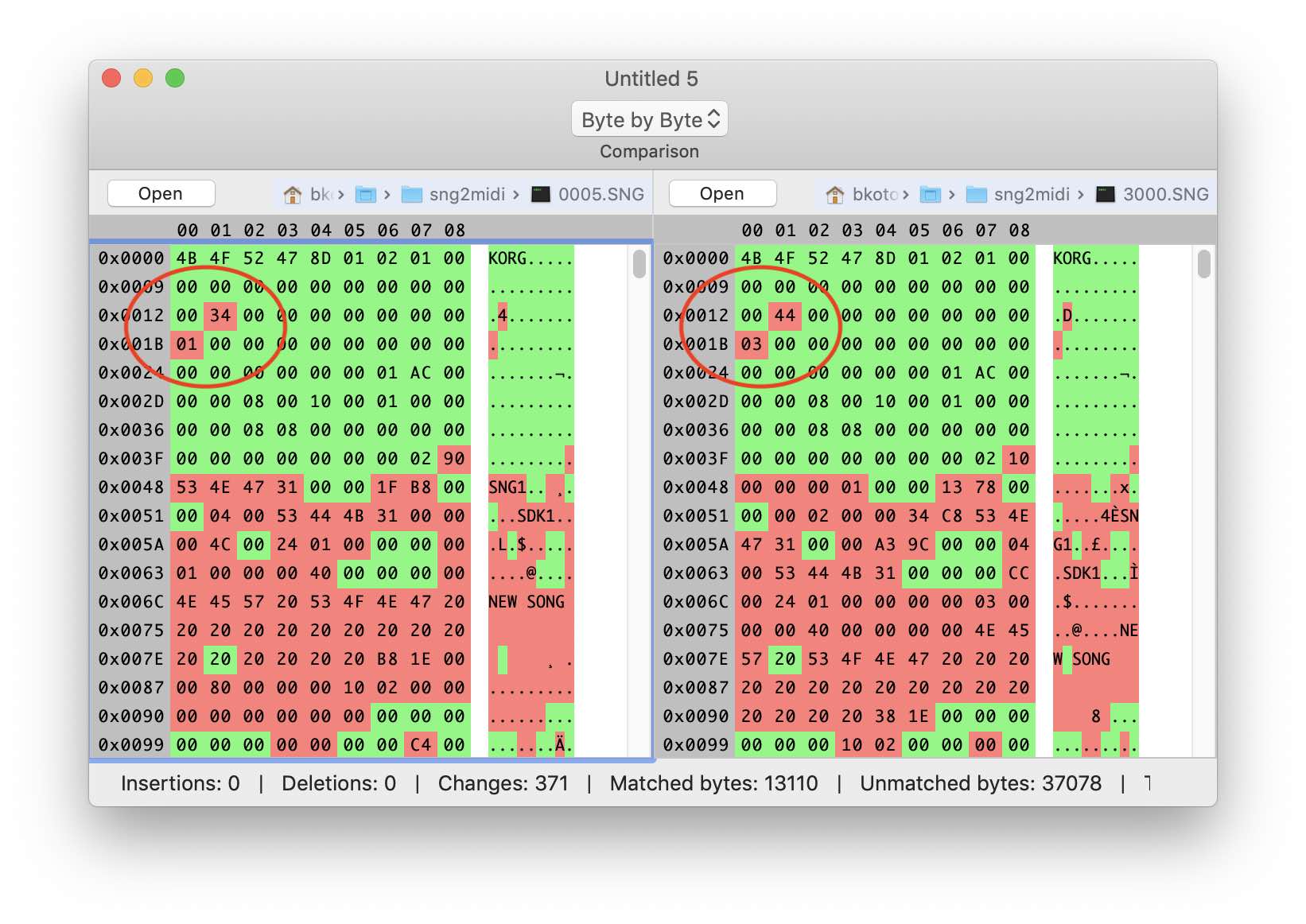
Create a header structure in the grammar editor. The first 4 bytes are obviously the signature of the file. Suppose the next 4 bytes are version related. The next few dozen bytes do not change and do not contain anything interesting - we create binaryData for them of the appropriate size. But then the interesting begins. You can notice some patterns in the behavior of bytes at offsets 0x13 and 0x1b. The second seems to correspond to the number of "songs" in our file. And the first one also grows with the increase in the amount of data in the header - it looks like it is the size, only the count is not from the beginning of the file, but from the next byte 0x14. At this stage, we can only guess about the type of numeric data. Suppose that the size is of type UInt32, i.e. takes 4 bytes. Add them to our structure. Now we can set the size of the header structure (size + 20).
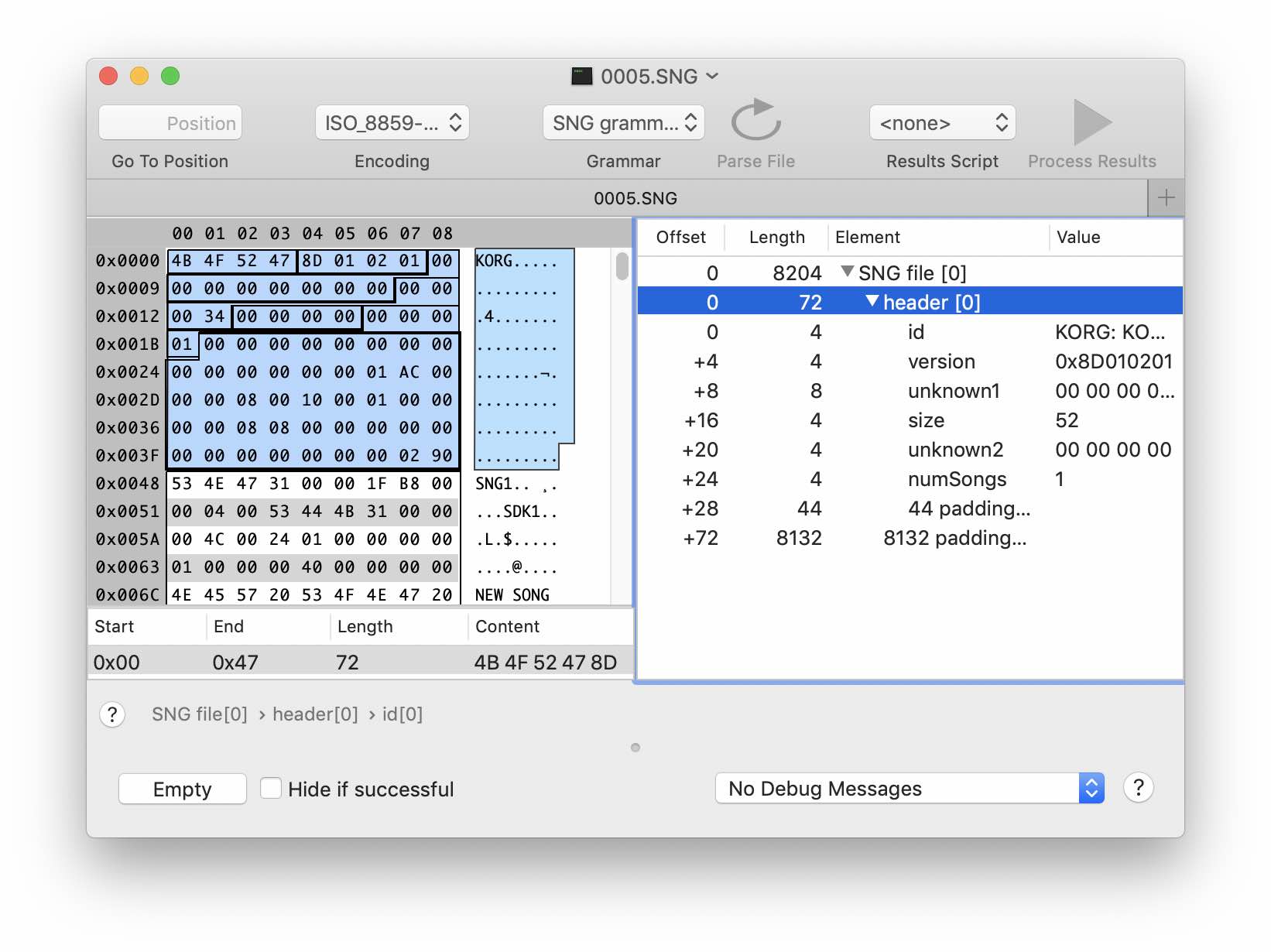
Grammar with added file header structure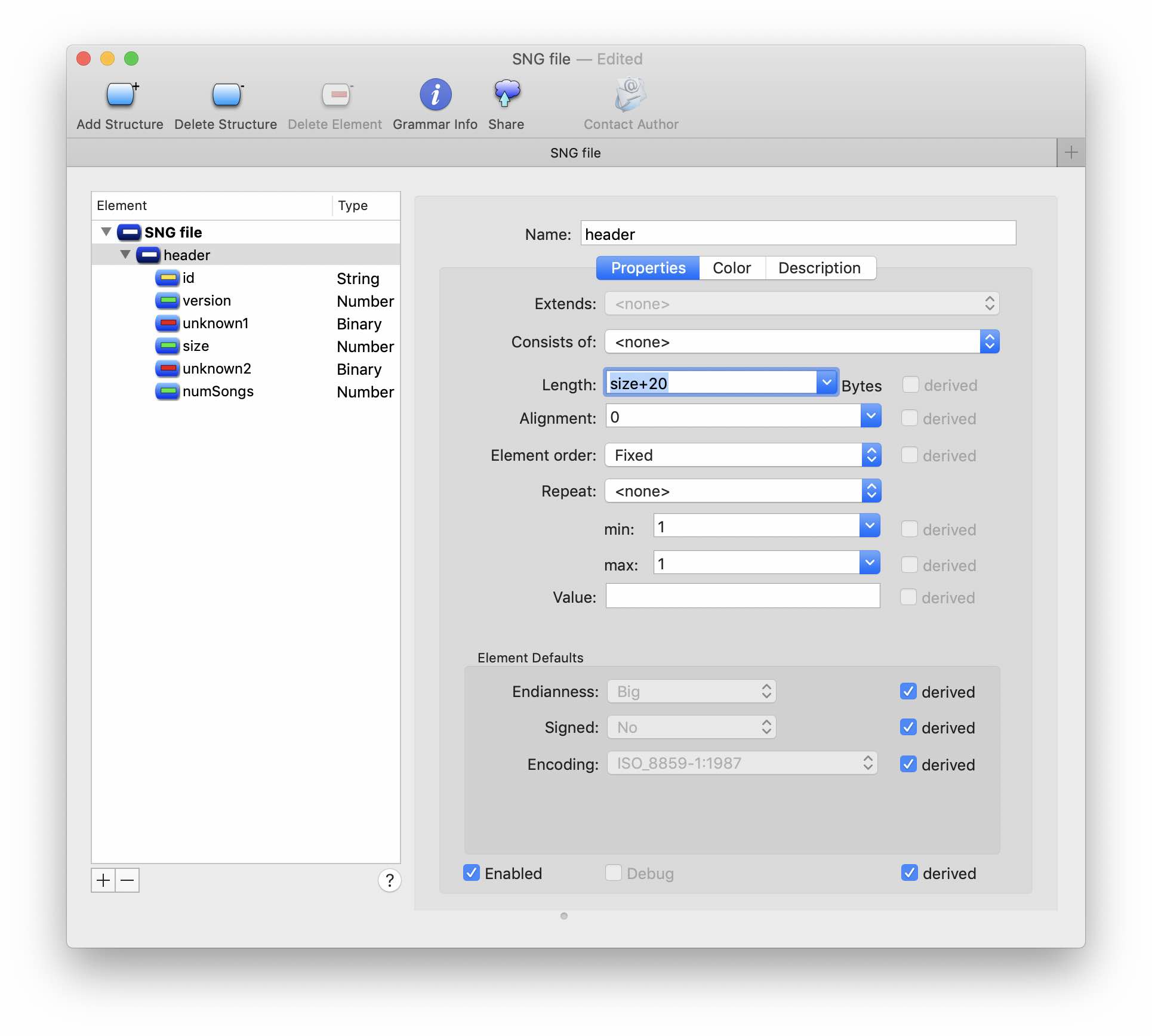
Let's see what comes next. If you look closely, you can see that three-letter abbreviations are scattered throughout the file: SNG1, SDK1, SGS1, and so on. These symbols are found in all SNG files, so we can assume that these are signatures of some blocks. In addition, our title is very well ended just before one of these signatures. Let's compare how the 4 bytes following it behave in files of different sizes. It can be seen that the values grow with the amount of data.
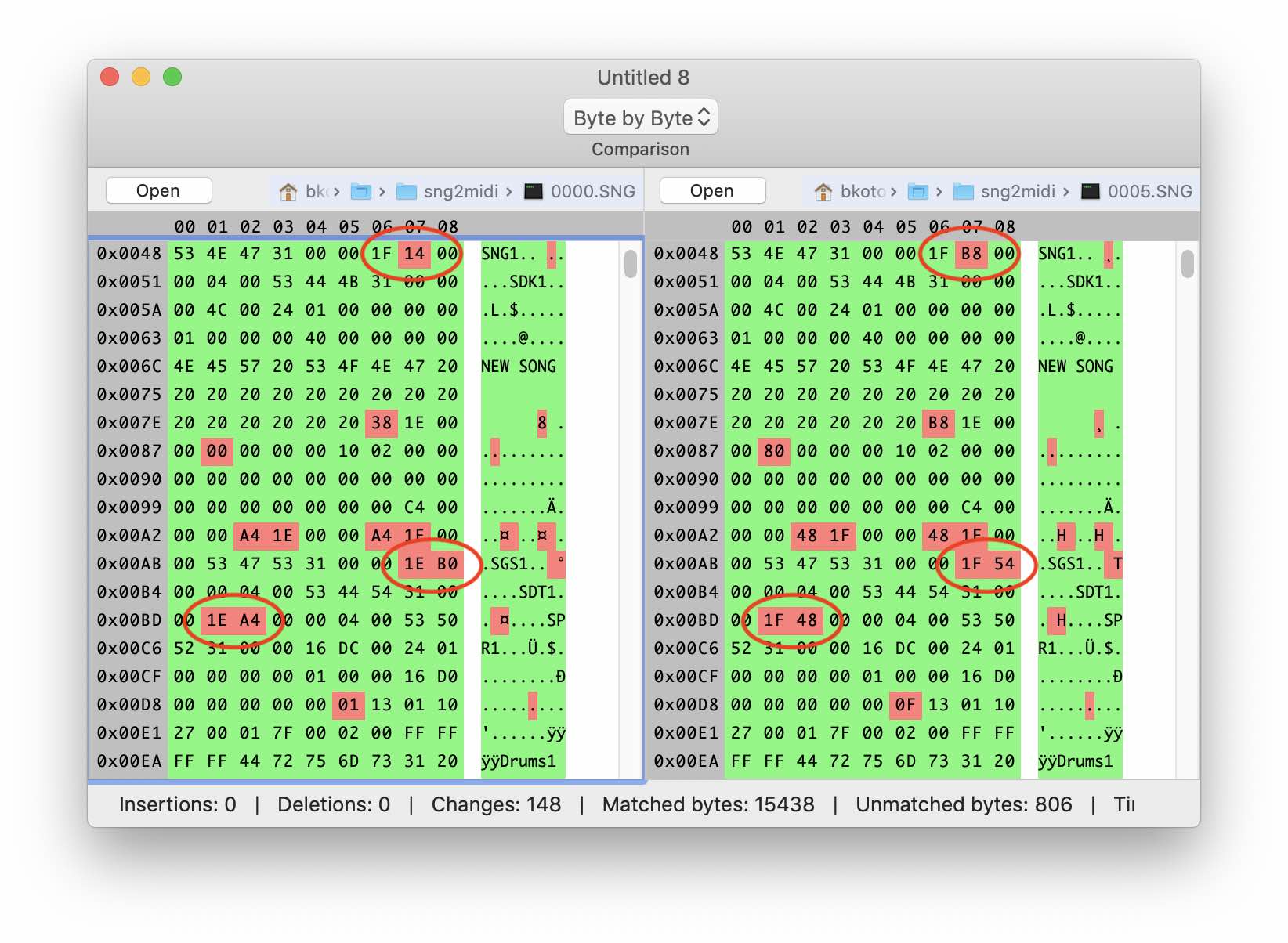
Some more experiments, analysis and calculations, and the following picture begins to emerge:
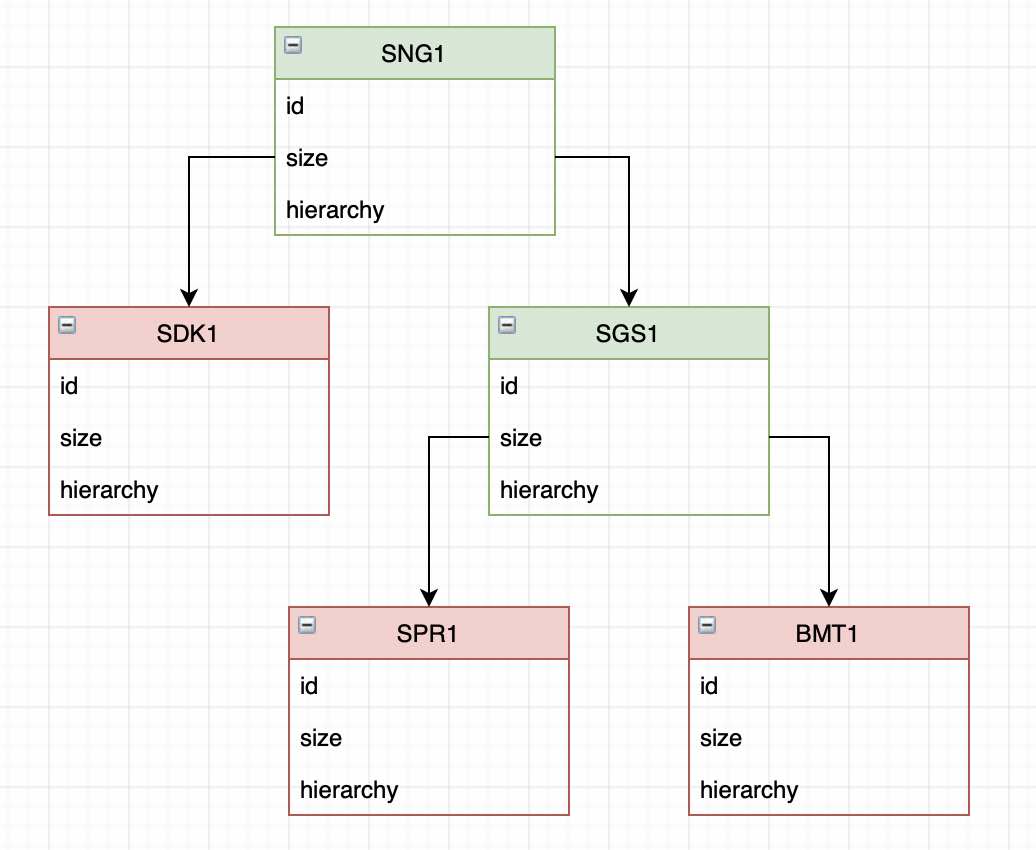
Alternative chart view
Thus, our file consists of a fairly simple hierarchy of blocks. There are parent blocks that can contain several child blocks. There are blocks-leaves (in the terminology of binary trees) that do not contain other blocks.
Then the magic begins. With just a few grammar structures, we can fully automatically parse the block structure of the file.
So, create a DataChunk template structure with the following fields (the size is indicated in square brackets):
id: string [4]
size: int [4]
hierarchy: int [4]
data: structure
Now create a parentChunk structure that inherits DataChunk. In the hierarchy property, we indicate Fixed Value 0x400 - this is a sign of the parent unit. Be sure to check the Must match checkbox
Similarly, create childChunk. Hierarchy in this case will have two values: 0x240100 and 0x100
Add links to the parentChunk and childChunk structures in the data parentChunk structure - this is how we create the recursion.
Finally, add a link to the parentChunk structure to the main node.
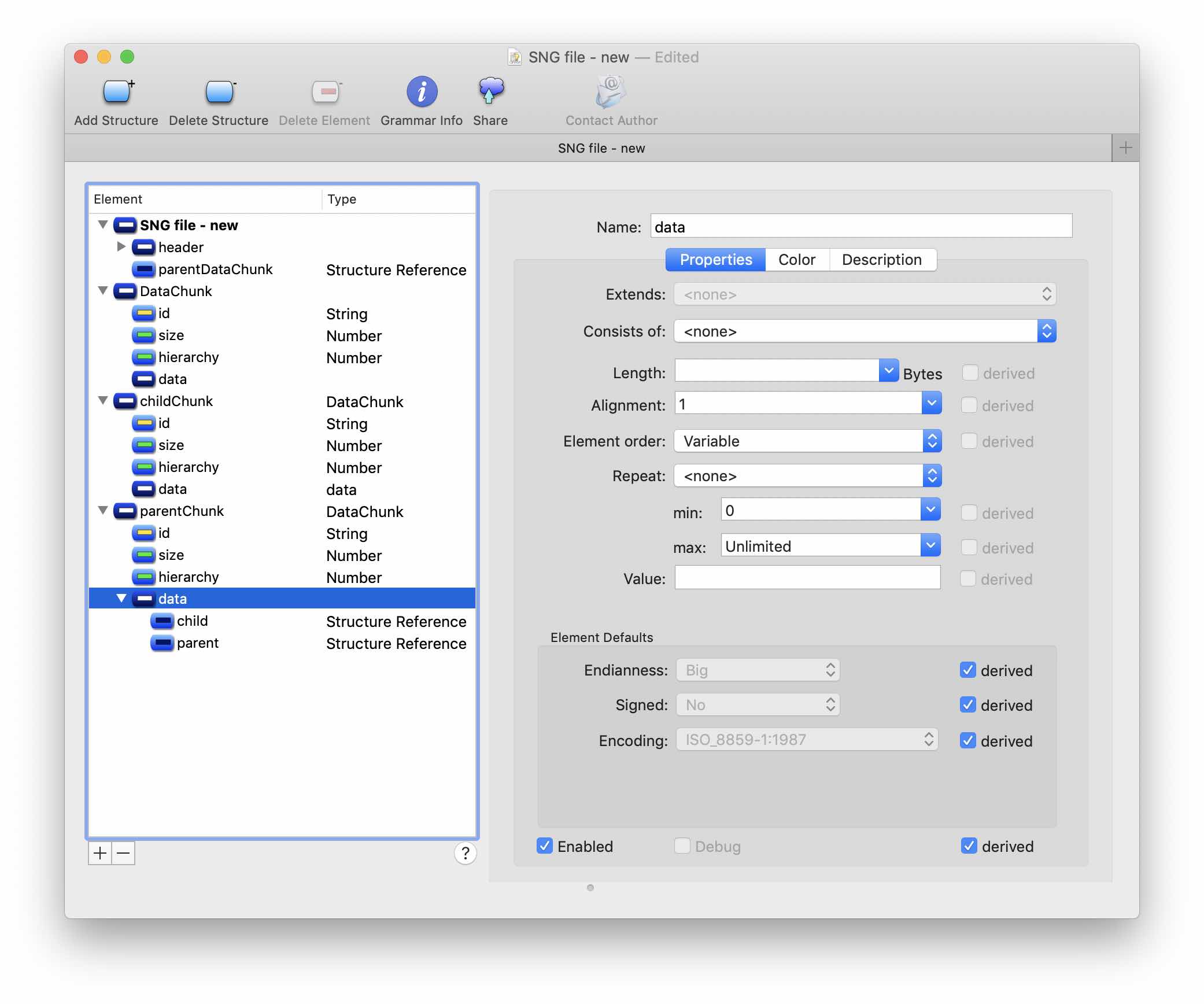
The order of the elements in the data parentChunk structure must be Variable, you also need to set the minimum and maximum number of child elements of this structure: 0 and Unlimited, respectively.
Apply the changes, and voila - our file is beautifully parsed into the main blocks.
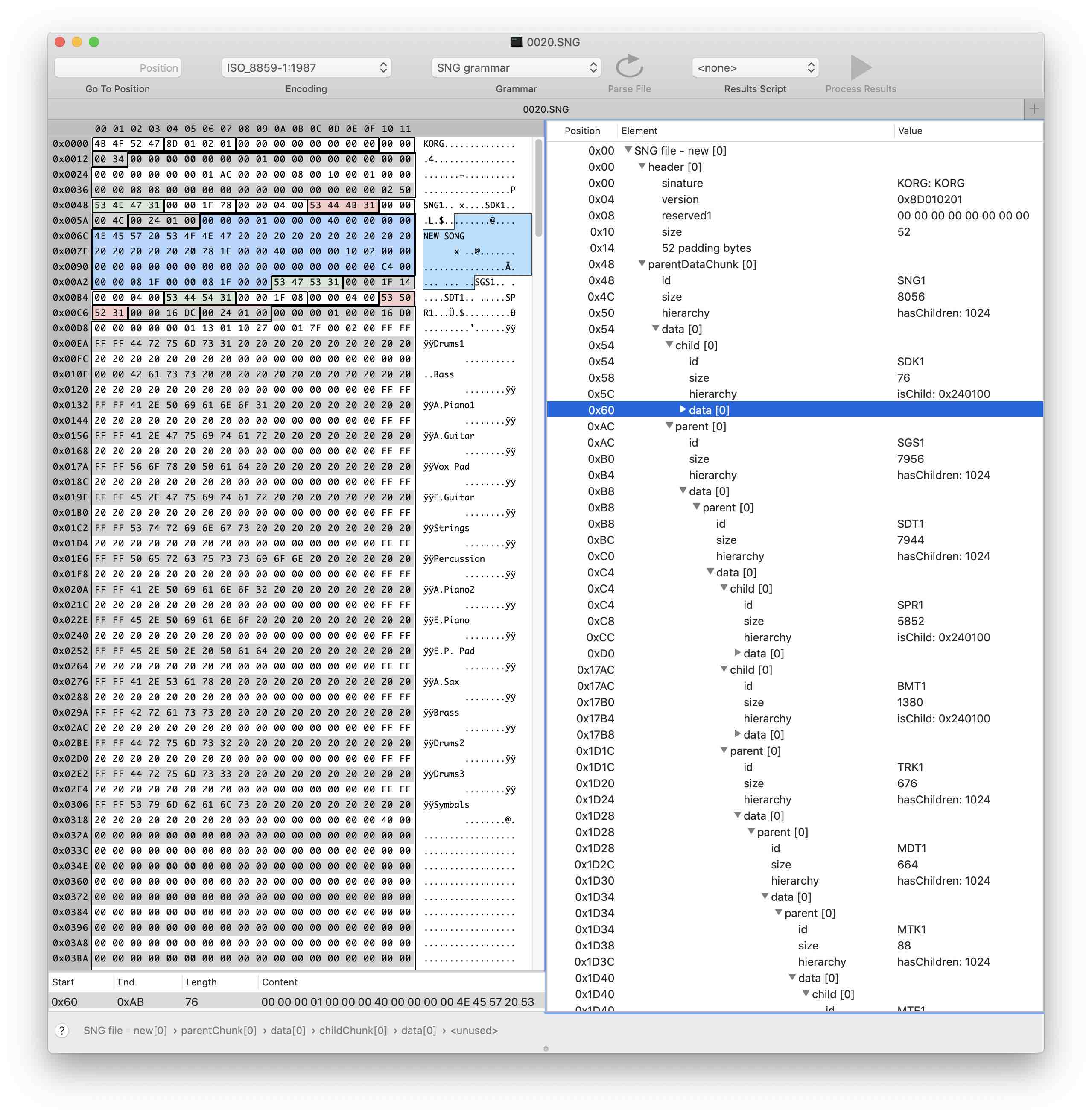
About the data itself, we still do not know, but now we can much easier to navigate the file and focus on finding the information we need.
Parsing the block containing the "table of contents" file
For training, let's try to disassemble some simple block, for example, SDK1. Apparently, it contains something like a table of contents - a list of songs and, probably, some offsets / sizes.
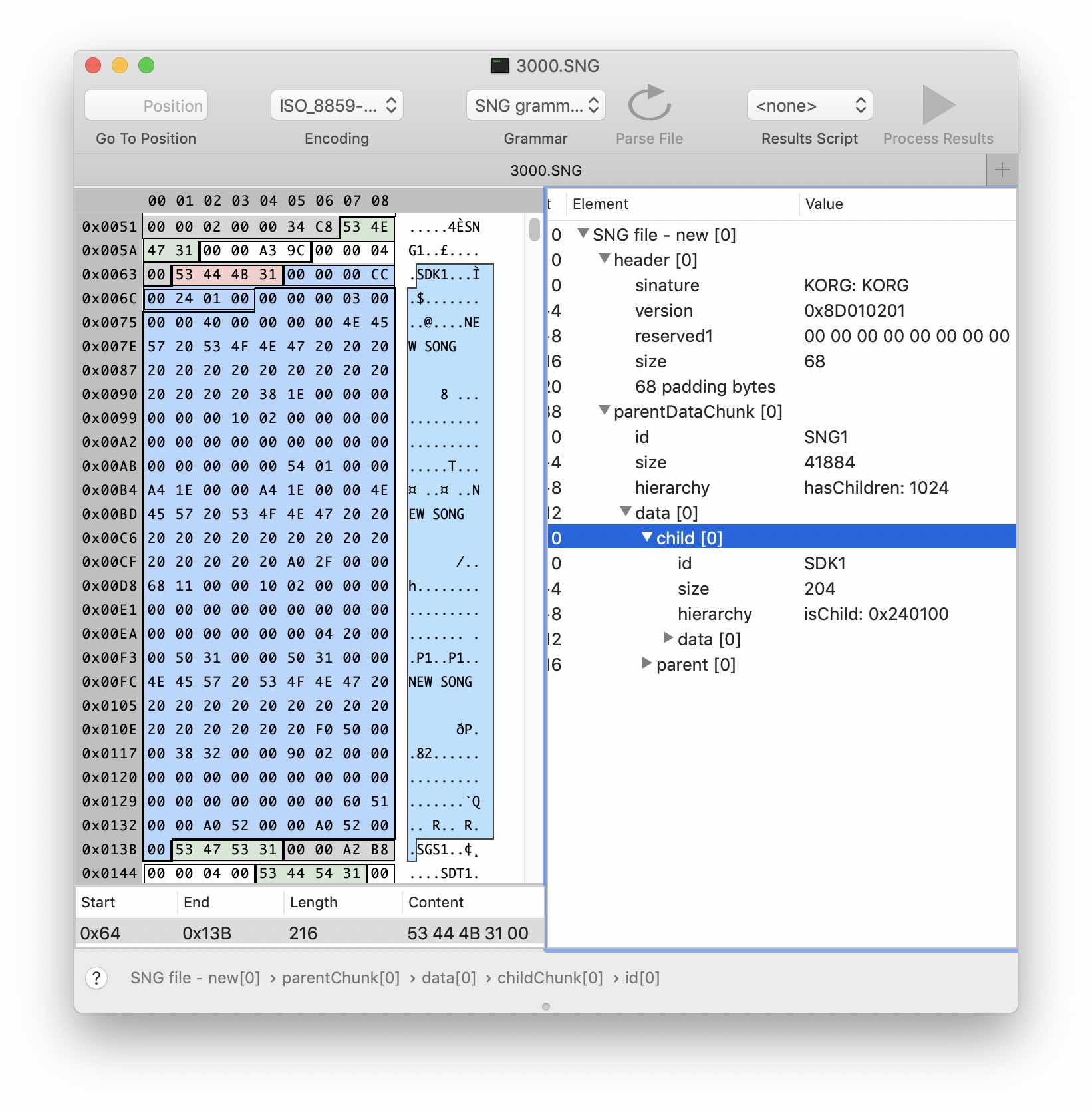
Create a sdk1Chunk structure inheriting from childChunk. Edit the ID field by specifying the signature of our block in the Fixed Values field. Do not forget about the checkbox Must match. In the block data one can observe a rather obvious repeating pattern: the name of the “song” and so far unknown data. Note that the size of the repeating fragments is 64 bytes. Also, by comparing versions of files with different numbers of “songs,” you can determine that their number is stored in the first four bytes. By simple calculations and making several assumptions, we obtain the following version of the structure in the grammar:
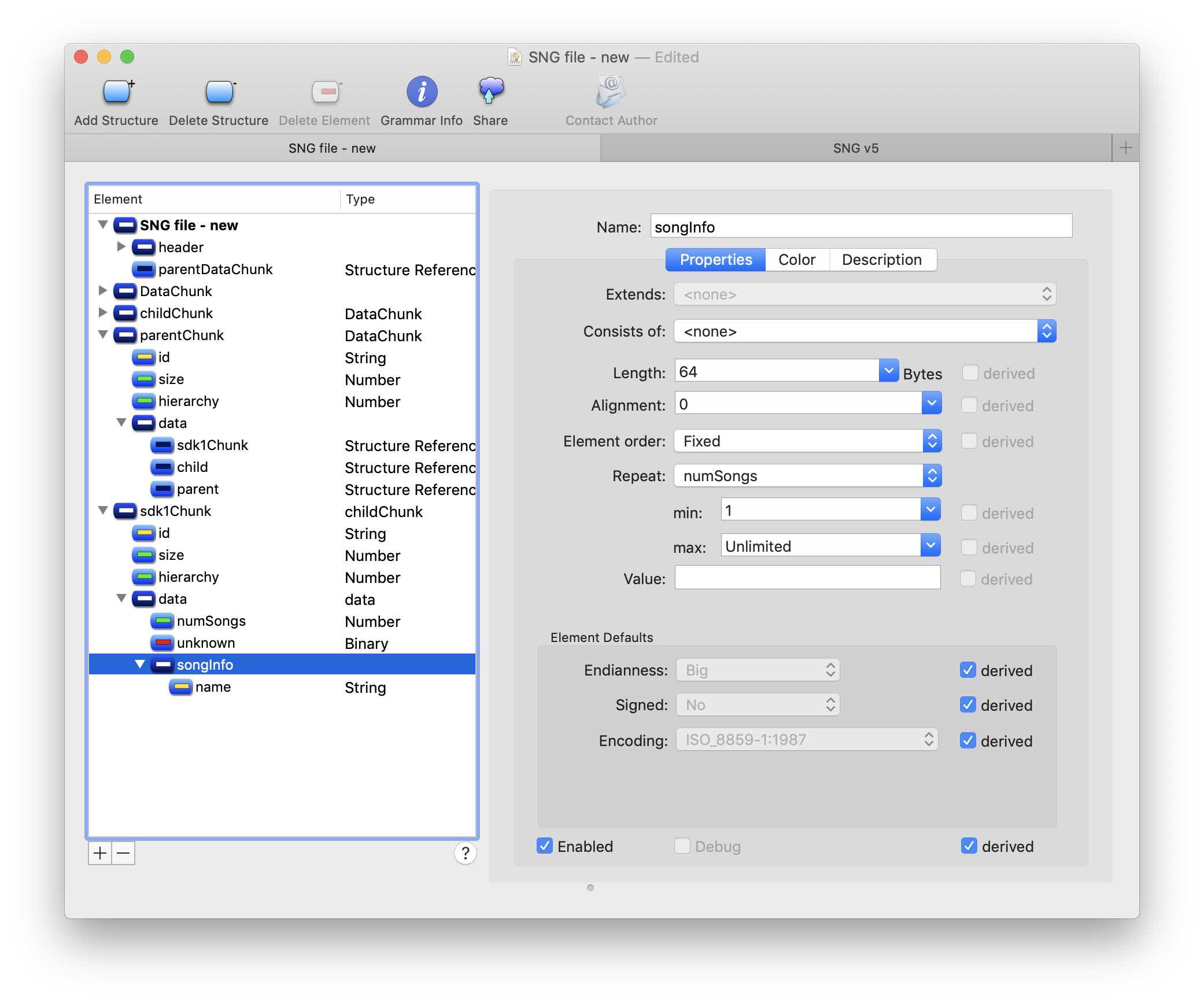
Here I created a 64-byte childInfo structure and indicated the possibility of repeating numSongs times. Here is the result of the grammar:
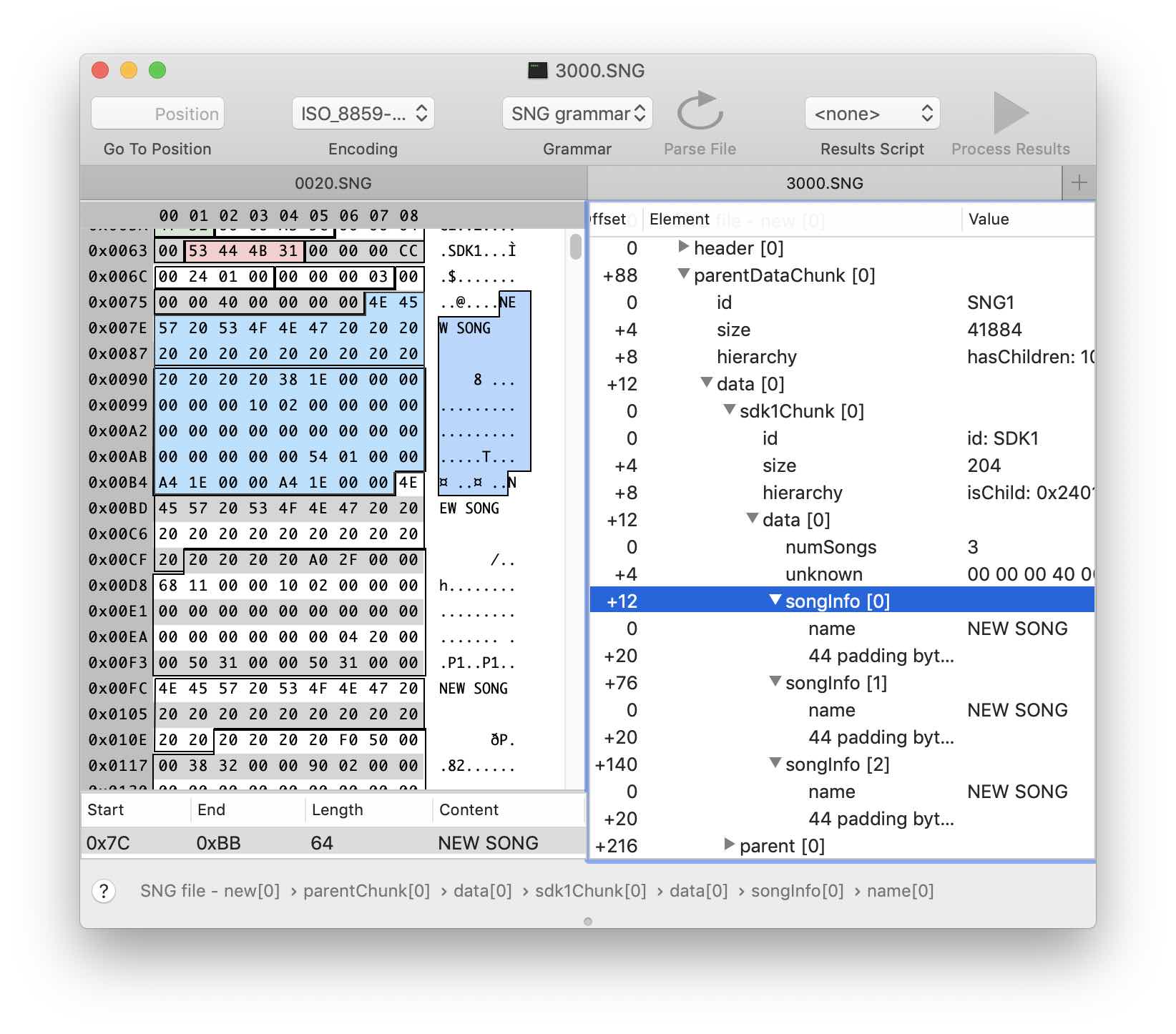
Further analysis of the file remains a trick. I changed the general settings of the “song” and the parameters of individual tracks on the synthesizer. Comparing versions of files with various changes, you can improve and refine the grammar. After a sufficiently large number of such iterations, there are almost no unrecognized pieces of data in the file. I got a little carried away with the process and sorted out almost all sections of the file, although this was not required for the original task.
A small part of the grammar SNG file after 8 hours of parsing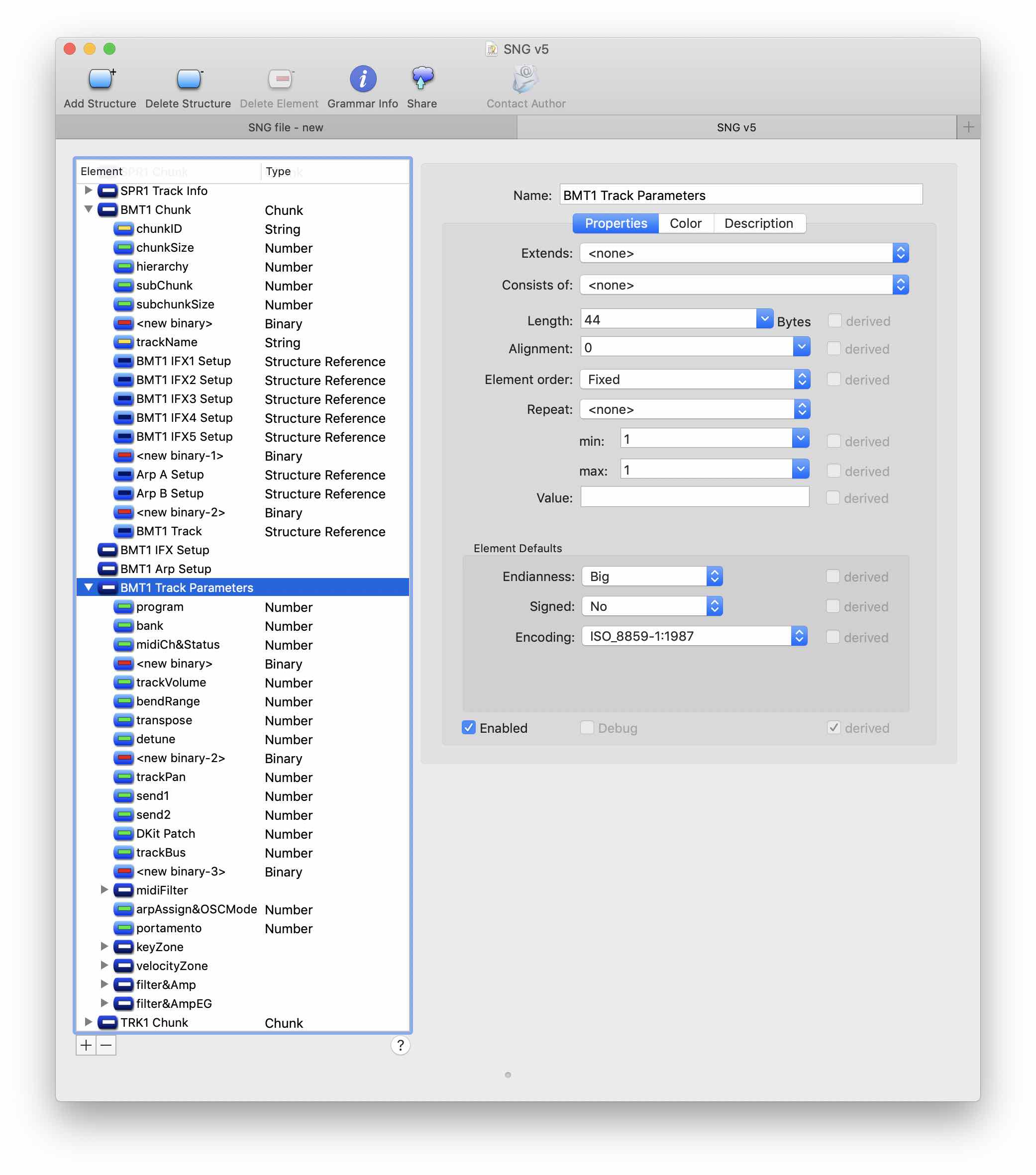
I will miss the details of this process - in the future we will focus on the analysis of the musical data itself.
But about this - in the next part. In the same place, we will face an interesting task of data conversion (quite suitable for interviews), try to solve it with a small script and hear a rather unusual result of a test conversion.
Preliminary results
The need for reverse engineering of binary files may arise unexpectedly. For example, to analyze the firmware of devices, convert from rare data formats, analyze digital threats, or even banal modifications to save games. Modern tools allow you to solve these problems quickly and efficiently. About 10 years ago, I was researching laptop firmware and this process could take several weeks. Then it was required to manually write scripts to analyze data blocks and mark out the structure. With a new partially automated approach, I created an almost complete grammar of a file in just a couple of days.
You can start analyzing a binary file by searching for strings — they can give the first hooks and speed up the analysis process. Often binaries consist of data blocks that are organized in a hierarchical or linear structure. If you deal with this structure, then further analysis will be much easier. The file header can give hints on the offsets / sizes of data blocks. At the first stages, it makes sense to focus on the description of obvious structures and blocks. The analysis task is greatly simplified by the ability to create new versions of files with different settings, parameters, data. There are a number of difficulties associated with unknown data types and byte order in their binary representation (Endianness). We will address these questions in the next section.
Recommended literature
Andreas Pehnack. How to Approach Binary File Format Analysis
Source: https://habr.com/ru/post/442580/
All Articles