NoVerify: Linter for PHP from Team VKontakte is now publicly available

Let me tell you how we managed to write a linter, which turned out fast enough to check for changes during each git push and do it in 5-10 seconds with a code base of 5 million lines in PHP. We called it NoVerify.
NoVerify supports basic things like the transition to defining and finding uses and can work in Language Server mode. First of all, our tool is focused on the search for potential errors, but is able to check and style. Today its source code appeared in open-source on GitHub. Look for the link at the end of the article.
Why do we need a linter
In the middle of 2018, we decided that it was time to implement a linter for PHP code. There were two goals: to reduce the number of errors that users see, and to more strictly enforce the code style. At the same time, we focused on preventing typical errors: the presence of undeclared and unused variables in the code, unreachable code and others. I also wanted the static analyzer to work as fast as possible on our code base (5-6 million lines of PHP code at the time of this writing).
')
As you probably know, the source code for most of the site is written in PHP and compiled using KPHP , so it would be logical to add these checks to the compiler. But in fact, not all code makes sense to run through KPHP - for example, the compiler is weakly compatible with third-party libraries, so regular PHP is still used for some parts of the site. They are also important and should be checked by the linter, so, unfortunately, there is no possibility to embed it in KPHP.
Why NoVerify
Given the size of the PHP code (remember, this is 5-6 million lines), it is not possible to “fix” it right away so that it passes our own checks in the linter. Nevertheless, I want the changing code to gradually become cleaner and more strictly follow the coding standards, and also contain fewer errors. Therefore, we decided that the linter should be able to check for changes that the developer is going to push, and not swear at the rest.
To do this, the linter needs to index the entire project, fully analyze the files before and after the changes, and calculate the difference between the generated warnings. New warnings are shown to the developer, and we need to fix them before you can push.
But there are situations when this behavior is undesirable, and then developers can push without local hooks — using the
git push --no-verify . The option --no-verify and gave the name to the linter :)What were the alternatives
The code base in VK uses little OOP and mainly consists of functions and classes with static methods. If classes in PHP support autoload, then functions are not. Therefore, we cannot use static analyzers without significant modifications, which base their work on the fact that autoload will load all the missing code. Such linters include, for example, psalm from the company Vimeo .
We reviewed the following static analysis tools:
- PHPStan is single-threaded, requires autoload, code base analysis has reached 30% in half an hour;
- Phan - even in quick mode with 20 processes, analysis stopped at 5% after 20 minutes;
- Psalm - requires autoload, the analysis took 10 minutes (I would still like to be much faster);
- PHPCS - checks style, but not logic;
- phpcf - only checks formatting.
As you can guess from the title of the article, none of these tools satisfy our requirements, so we wrote our own.
How to create a prototype
At first we decided to build a small prototype to see if it was worth trying to make a full-fledged linter at all. Since one of the most important requirements for a linter is its speed, instead of PHP, we chose Go. “Fast” is to give feedback to the developer as quickly as possible, preferably in no more than 10-20 seconds. Otherwise, the cycle “correct the code, run the linter again” begins to significantly slow down the development and spoil the mood of people :)
Since Go is chosen for the prototype, you need a PHP parser. There are several of them, but the php-parser project seemed to be the most mature. This parser is not perfect and is still being finalized, but for our purposes it is quite suitable.
For the prototype, it was decided to try to implement one of the most simple, at first glance, inspections: access to an undefined variable.
The basic idea for implementing such an inspection looks simple: for each branch (for example, for if) we create a separate nested scope and combine the types of variables at the output from it. Example:
<?php if (rand()) { $a = 42; // : { $a: int } } else { $b = "test"; $a = "another_test"; // : { $b: string, $a: string } } // : { $b: string?, $a: int|string } echo $a, $b; // , // $b Looks easy, right? In the case of ordinary conditional statements, everything works well. But we have to handle, for example, switch without break;
<?php switch (rand()) { case 1: $a = 1; // { $a: int } case 2: $b = 2; // { $a: int, $b: int } default: $c = 3; // { $a: int, $b: int, $c: int } } // { $a: int?, $b: int?, $c: int } It is not immediately clear from the code that $ c will always be actually defined. Specifically, this example is fictional, but it illustrates well what are the difficult moments for the linter (and for the person in this case too).
Consider a more complex example:
<?php exec("hostname", $out, $retval); echo $out, $retval; // { $out: ???, $retval: ??? } Without knowing the signature of the exec function, one cannot say whether $ out and $ retval are defined. Signatures of built-in functions can be obtained from the repository github.com/JetBrains/phpstorm-stubs . But the same problems will be when calling custom functions, and their signature can be found only by indexing the entire project. The exec function takes the second and third arguments by reference, so the variables $ out and $ retval can be defined. Here, accessing these variables is not necessarily an error, and the linter should not swear at such a code.
Similar problems with implicit passing by reference arise with methods, but at the same time the need to infer types of variables is added:
<?php if (rand()) { $a = some_func(); } else { $a = other_func(); } $a->some_method($b); echo $b; We need to know which types return some_func () and other_func () functions, so that we can later find a method called some_method in these classes. Only then can we say whether the variable $ b will be defined or not. The situation is complicated by the fact that often simple functions and methods do not have phpdoc annotations, so you need to be able to calculate the types of functions and methods based on their implementation.
When developing a prototype, we had to implement about half of all the functionality in order for the simplest inspection to work as it should.
Work as a language server
To make it easier to debug the linter logic and make it easier to see the warnings that it issues, we decided to add a mode as a language server for PHP . In the integration mode with Visual Studio Code, it looks like this:
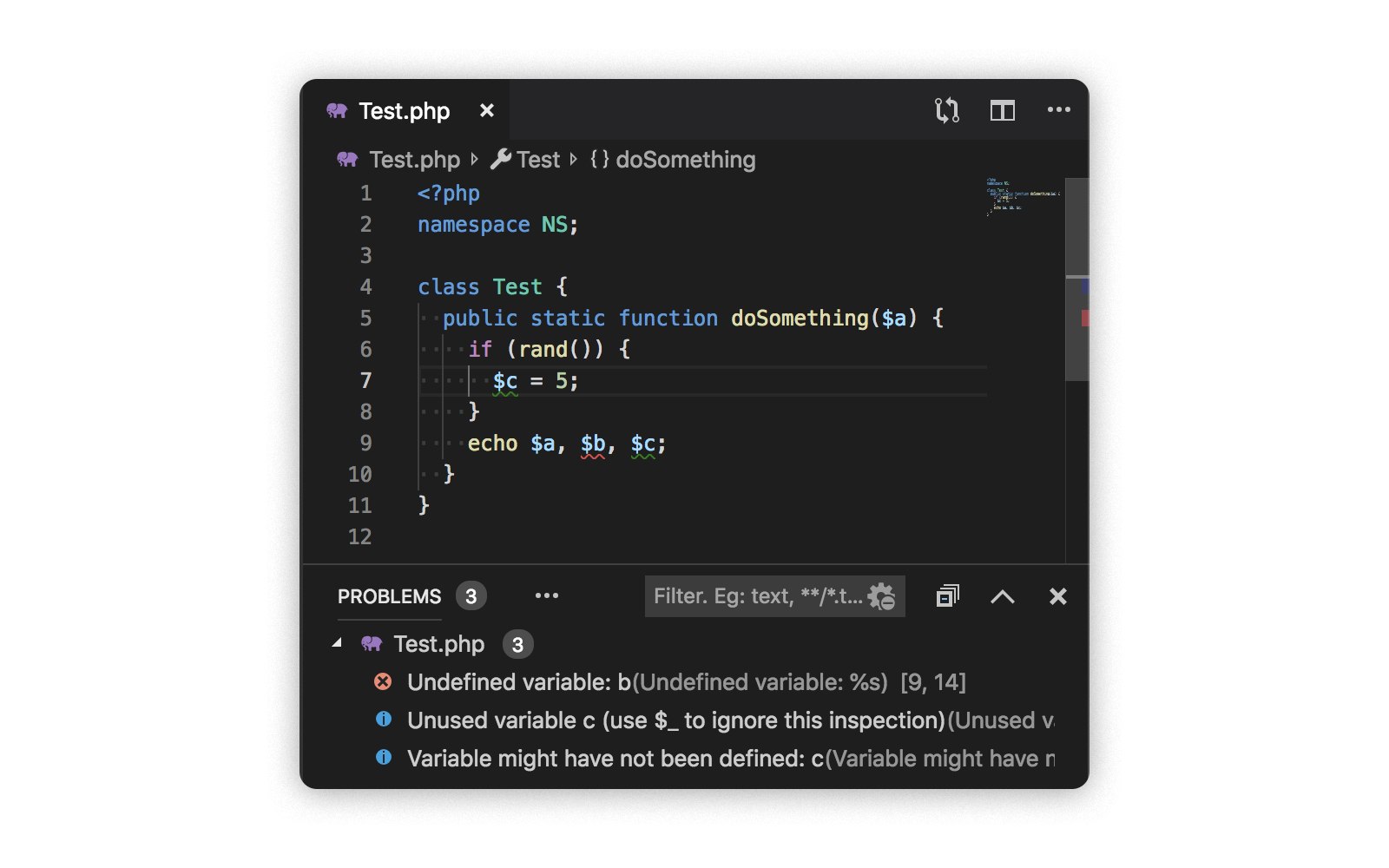
In this mode, it is convenient to test hypotheses and test complex cases (after that, you need to write tests, of course). It is also good to test performance: even on large files, php-parser on Go shows good performance.
Language server support is far from ideal, since its main purpose is to debug linter rules. However, in this mode there are several additional features:
- Hints for the names of variables, constants, functions, properties and methods.
- Highlighting derived types of variables.
- Transition to definition.
- Search for uses.
Lazy type inference
In language server mode, the following is required: you change the code in one file, and then, when you switch to another, you should work with the already updated information about which types are returned in functions or methods. Imagine that the files are edited in the following sequence:
<?php // A.php, 1 class A { /** @var int */ public $prop; } // B.php, class B { public static function something() { $obj = new A; return $obj->prop; } } // C.php, $c = B::something(); // $c int // A.php, 2 class A { /** @var string <--- string */ public $prop; } // C.php, $c = B::something(); // $c string, B.php, C.php Given that we do not force developers to always write PHPDoc (especially in such simple cases), we need a way to store information about what type the function B :: something () returns. So that when the A.php file changes, the type information in the C.php file is immediately up to date.
One possible solution is to store "lazy types." For example, the return type of the method B :: something () actually represents the type of the expression (new A) -> prop. In this form, the linter and stores information about the type, and thanks to this, you can cache all the meta-information on each file and update it only when this file changes. This should be done carefully, so that there is no chance that specific types of information are leaked. You also need to change the cache version when the type inference logic changes. However, such a cache speeds up the indexing phase (which I will discuss later) by a factor of 5–10 compared to re-parsing all files.
Two phases of work: indexing and analysis
As we remember, even for the simplest code analysis, information on at least all functions and methods in a project is required. This means that you can not analyze only one file separately from the project. And also - that it is impossible to do this in one pass: for example, PHP allows accessing functions that are further declared in a file.
Due to these limitations, the linter operation consists of two phases: primary indexing and subsequent analysis of only the necessary files. Now more about these two phases.
Indexing phase
In this phase, all files are parsed and local code analysis of methods and functions is done, as well as code at the top level (for example, to determine the types of global variables). Information about declared global variables, constants, functions, classes and their methods is collected and written to the cache. For each file in the project, the cache is a separate file on the disk.
A global dictionary of all the meta-information about the project is compiled from individual pieces, which later does not change anymore *.
* In addition to the mode of operation as a language server, when an indexing and analysis of a modified file is carried out for every edit.
Analysis phase
In this phase, we can use the meta-information (about functions, classes ...) and already directly analyze the code. Here is a list of what NoVerify can check by default:
- unreachable code;
- referring to objects as an array;
- insufficient number of arguments when calling a function;
- calling an undefined method / function;
- access to a missing class property / constant;
- lack of class;
- invalid phpdoc;
- reference to an undefined variable;
- reference to a variable that is not always defined;
- no “break;” after case in switch / case constructs;
- syntax error;
- unused variable.
The list is quite short, but you can add checks that are specific to your project.
During the operation of the linter, it turned out that the most useful inspection is just the last (unused variable). This often happens when you refactor a code (or write a new one) and put it wrong in the name of the variable: this code is valid from the point of view of PHP, but erroneously logically.
Work speed
How long does the change we want to push are checked? It all depends on the number of files. With NoVerify, the process can take up to a minute (as it was when I changed 1,400 files in the repository), but if there were a few changes, then usually all checks take 4–5 seconds to complete. During this time there is a full indexing of the project, the parsing of new files, as well as their analysis. We were quite able to create a linter for PHP, which works quickly even with our large codebase.
What is the result?
Since the solution is written in Go, you need to use the repository github.com/JetBrains/phpstorm-stubs to have the definitions of all the built-in PHP functions and classes. Instead, we got high speed (indexing 1 million lines per second, analyzing 100 thousand lines per second) and were able to add linker checks as one of the first steps in hooks for git push.
A convenient base was developed for creating new inspections and a code understanding level close to PHPStorm was achieved. Due to the fact that out of the box, the mode of operation with diff calculation is supported, it is possible to gradually improve the code, preventing new potentially problematic structures in the new code.
Diff counting is not perfect: for example, if one large file was separated into several small ones, then git, and therefore NoVerify, will not be able to determine that the code has been moved, and the linter will require fixing any problems found. In this regard, the counting of diffs makes it difficult to conduct a major refactoring, so in such cases it is often turned off.
Writing a linter on Go has another advantage: not only the AST parser is faster and consumes less memory than PHP, but the subsequent analysis is also very smart compared to anything that could be done in PHP. This means that our linter can perform more complex and in-depth analysis of the code, while maintaining high performance (for example, the “lazy types” feature requires a fairly large number of calculations to be performed in the process).
Open source
NoVerify is available in open source on github
Enjoy using your project!
UPD: I have prepared a demo that works through WebAssembly . The only limitation of this demo is the lack of definitions of functions from phpstorm-stubs, so the linter will swear on the built-in functions.
Yury Nasretdinov, developer of the VKontakte infrastructure department
Source: https://habr.com/ru/post/442284/
All Articles