Web scraping for web developers: a brief summary
Knowing only one approach to web scraping solves the problem in the short term, but all methods have their strengths and weaknesses. Awareness of this saves time and helps to solve the problem more effectively.

Numerous resources tell about the only correct method of extracting data from a web page. But the reality is that for this you can use several solutions and tools.
')
The article will help get answers to these questions.
I assume that you already know what HTTP requests are, DOM (Document Object Model), HTML , CSS selectors, and Async JavaScript .
If not, I advise you to delve into the theory, and then return to the article.
HTML sources
Let's start with the simplest approach.
If you are planning to scrap web pages, this is the first place to start. It takes a little computer power and a minimum of time.
However, this only works if the source HTML code contains data that you are targeting. To check this out in Chrome, right-click the page and select View Page Code. You should now see the HTML source code.
Once you find the data, write a CSS selector that belongs to the wrapping element so that you later have a link.
For implementation, you can send an HTTP GET request to the URL of the page and get back the HTML source code.
In Node, you can use the CheerioJS tool to parse raw HTML and extract data using a selector. The code will look like this:
In many cases, you cannot access information from raw HTML code, because the DOM was driven by javascript, which runs in the background. A typical example of this is the SPA (one-page application), where the HTML document contains the minimum amount of information, and JavaScript fills it at run time.
In this situation, the solution is to create a DOM and execute the scripts located in the HTML source code, as the browser does. After that, data can be extracted from this object using selectors.
Headless browsers
A headless browser is the same as a regular browser, but without a user interface. It runs in the background, and you can control it programmatically instead of clicking and typing from the keyboard.
Puppeteer is one of the most popular headless browsers. It is an easy-to-use Node library that provides high-level APIs for managing Chrome offline. It can be configured to run without a title, which is very convenient when developing. The following code does the same thing as before, but it will work with dynamic pages:
Of course, you can do more interesting things with Puppeteer, so you should see the documentation . Here is a snippet of code that navigates through the URL, takes a screenshot and saves it:
The browser requires much more processing power than sending a simple GET request and analyzing the response. Therefore, the implementation is relatively slow. Not only that, but also adding a browser as a dependency makes the package massive.
On the other hand, this method is very flexible. You can use it to navigate through the pages, simulate clicks, mouse movements and use the keyboard, fill out forms, create screenshots or create PDF pages, execute commands in the console, select items to extract text content. Basically, everything that can be done manually in the browser.
Building a dom
You will think that it is unnecessary to model an entire browser just to create a DOM. In fact, this is the case, at least under certain circumstances.
Jsdom is a Node library that analyzes HTML passed in as the browser does. However, this is not a browser, but a tool for building DOM from a given HTML source code , as well as for executing JavaScript code in this HTML.
Thanks to this abstraction, Jsdom can run faster than a headless browser. If it's faster, why not use it instead of headless browsers all the time?
Quote from the documentation :
This solution is shown in the example. Every 100 ms, it is checked if an element has appeared or a timeout has occurred (after 2 seconds).
It also often generates error messages when Jsdom does not implement certain browser functions on the page, such as: “ Error: Not implemented: window.alert ...” or “Error: Not implemented: window.scrollTo ... ”. This problem can also be solved with the help of some workarounds ( virtual consoles ).
As a rule, this is a lower level API than Puppeteer, so you need to implement some things yourself.
This makes it a bit more difficult to use, as you can see from the example. Jsdom for the same job offers a quick fix.
Let's look at the same example, but using Jsdom :
Reverse engineering
Jsdom is a quick and easy solution, but you can make everything even easier.
Do we need to simulate DOM?
The webpage you want to scrap is made up of the same HTML and JavaScript, the same technologies that you already know. Thus, if you find a piece of code from which target data were obtained, you can repeat the same operation to get the same result .
If you simplify everything, the data you are looking for may be:
These data sources can be accessed via network requests . It doesn't matter if the web page uses HTTP, WebSockets, or some other communication protocol, because they are all replicable in theory.
Having found a resource containing data, you can send a similar network request to the same server as the original page. As a result, you will receive a response containing target data that can be easily retrieved using regular expressions, string methods, JSON.parse, etc.
In simple words, you can take the resource where the data is located, instead of processing and loading all the material. Thus, the problem shown in the previous examples can be solved with a single HTTP request instead of controlling the browser or a complex JavaScript object.
This solution seems simple in theory, but in most cases it can be time consuming and requires experience with web pages and servers.
Start by monitoring your network traffic. A great tool for this is the Network tab in Chrome DevTools . You will see all outgoing requests with responses (including static files, AJAX requests, etc.) to iterate and search for data.
If the answer is changed by some code before being displayed on the screen, the process will be slower. In this case, you should find this part of the code and understand what is happening.
As you can see, this method may require much more work than the methods described above. On the other hand, it provides the best performance.
The diagram shows the required runtime and package size compared to Jsdom and Puppeteer:
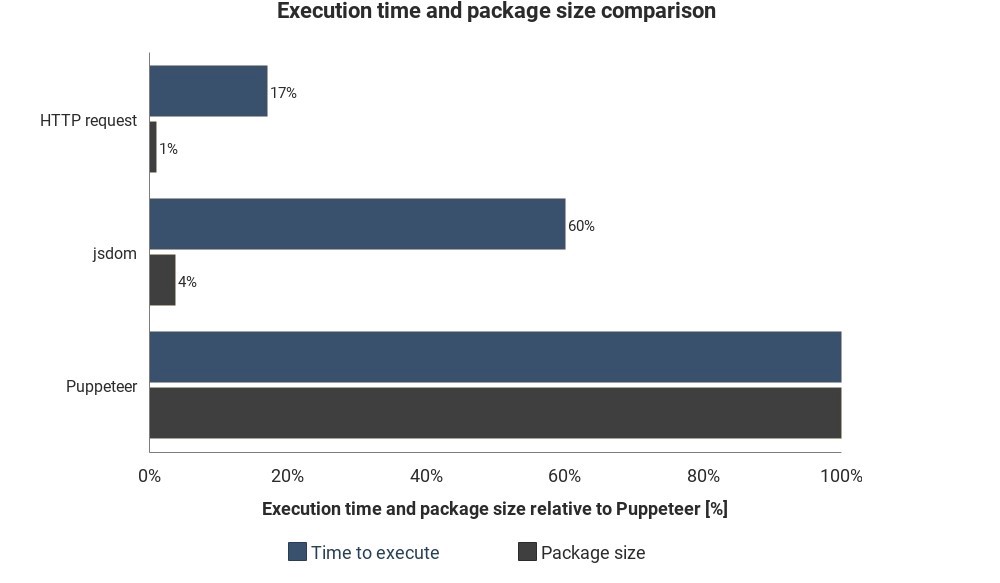
The results are not based on accurate measurements and can vary, but show well the approximate difference between these methods.
Suppose you have implemented one of these solutions. One way to run the script is to turn on the computer, open the terminal and start it manually.
But it will become annoying and inefficient, so it’s better if you could just upload the script to the server, and it would execute the code regularly, depending on the settings.
This can be done by running the actual server and setting the rules for when to run the script. In other cases, the cloud function is a simpler way.
Cloud functions are repositories designed to execute loaded code when an event occurs. This means that you do not need to manage the servers, this is done automatically by your cloud provider.
A trigger can be a schedule, a network request and many other events. You can save the collected data in a database, write it to the Google sheet or send it by email . It all depends on your imagination.
Popular cloud providers are Amazon Web Services (AWS), Google Cloud Platform (GCP) and Microsoft Azure :
You can use these services for free, but not for long.
If you use Puppeteer, Google’s cloud functions are the easiest solution. The package size in the Headless Chrome format (~ 130 MB) exceeds the maximum allowed archive size in AWS Lambda (50 MB). There are several methods to get it to work with Lambda, but the default GCP features support Chrome without a header , you just need to enable Puppeteer as a dependency in package.json .
If you want to learn more about cloud functions in general, check out the architecture information without servers. Many good manuals have already been written on this topic, and most providers have easy-to-understand documentation.
Numerous resources tell about the only correct method of extracting data from a web page. But the reality is that for this you can use several solutions and tools.
')
- What are the options for software extraction from a web page?
- Pros and cons of each approach?
- How to use cloud resources to increase the degree of automation?
The article will help get answers to these questions.
I assume that you already know what HTTP requests are, DOM (Document Object Model), HTML , CSS selectors, and Async JavaScript .
If not, I advise you to delve into the theory, and then return to the article.
Static content
HTML sources
Let's start with the simplest approach.
If you are planning to scrap web pages, this is the first place to start. It takes a little computer power and a minimum of time.
However, this only works if the source HTML code contains data that you are targeting. To check this out in Chrome, right-click the page and select View Page Code. You should now see the HTML source code.
Once you find the data, write a CSS selector that belongs to the wrapping element so that you later have a link.
For implementation, you can send an HTTP GET request to the URL of the page and get back the HTML source code.
In Node, you can use the CheerioJS tool to parse raw HTML and extract data using a selector. The code will look like this:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); }); Dynamic content
In many cases, you cannot access information from raw HTML code, because the DOM was driven by javascript, which runs in the background. A typical example of this is the SPA (one-page application), where the HTML document contains the minimum amount of information, and JavaScript fills it at run time.
In this situation, the solution is to create a DOM and execute the scripts located in the HTML source code, as the browser does. After that, data can be extracted from this object using selectors.
Headless browsers
A headless browser is the same as a regular browser, but without a user interface. It runs in the background, and you can control it programmatically instead of clicking and typing from the keyboard.
Puppeteer is one of the most popular headless browsers. It is an easy-to-use Node library that provides high-level APIs for managing Chrome offline. It can be configured to run without a title, which is very convenient when developing. The following code does the same thing as before, but it will work with dynamic pages:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result)); Of course, you can do more interesting things with Puppeteer, so you should see the documentation . Here is a snippet of code that navigates through the URL, takes a screenshot and saves it:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path); The browser requires much more processing power than sending a simple GET request and analyzing the response. Therefore, the implementation is relatively slow. Not only that, but also adding a browser as a dependency makes the package massive.
On the other hand, this method is very flexible. You can use it to navigate through the pages, simulate clicks, mouse movements and use the keyboard, fill out forms, create screenshots or create PDF pages, execute commands in the console, select items to extract text content. Basically, everything that can be done manually in the browser.
Building a dom
You will think that it is unnecessary to model an entire browser just to create a DOM. In fact, this is the case, at least under certain circumstances.
Jsdom is a Node library that analyzes HTML passed in as the browser does. However, this is not a browser, but a tool for building DOM from a given HTML source code , as well as for executing JavaScript code in this HTML.
Thanks to this abstraction, Jsdom can run faster than a headless browser. If it's faster, why not use it instead of headless browsers all the time?
Quote from the documentation :
People often have problems with asynchronous script loading when using jsdom. Many pages load scripts asynchronously, but it is impossible to determine when this happened, and, therefore, when to run the code and check the resulting DOM structure. This is a fundamental limitation.
This solution is shown in the example. Every 100 ms, it is checked if an element has appeared or a timeout has occurred (after 2 seconds).
It also often generates error messages when Jsdom does not implement certain browser functions on the page, such as: “ Error: Not implemented: window.alert ...” or “Error: Not implemented: window.scrollTo ... ”. This problem can also be solved with the help of some workarounds ( virtual consoles ).
As a rule, this is a lower level API than Puppeteer, so you need to implement some things yourself.
This makes it a bit more difficult to use, as you can see from the example. Jsdom for the same job offers a quick fix.
Let's look at the same example, but using Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result)); Reverse engineering
Jsdom is a quick and easy solution, but you can make everything even easier.
Do we need to simulate DOM?
The webpage you want to scrap is made up of the same HTML and JavaScript, the same technologies that you already know. Thus, if you find a piece of code from which target data were obtained, you can repeat the same operation to get the same result .
If you simplify everything, the data you are looking for may be:
- part of the source HTML code (as seen from the first part of the article),
- part of a static file that is referenced in an HTML document (for example, a line in a javascript file),
- responding to a network request (for example, some JavaScript code sent an AJAX request to a server that responded with a JSON string).
These data sources can be accessed via network requests . It doesn't matter if the web page uses HTTP, WebSockets, or some other communication protocol, because they are all replicable in theory.
Having found a resource containing data, you can send a similar network request to the same server as the original page. As a result, you will receive a response containing target data that can be easily retrieved using regular expressions, string methods, JSON.parse, etc.
In simple words, you can take the resource where the data is located, instead of processing and loading all the material. Thus, the problem shown in the previous examples can be solved with a single HTTP request instead of controlling the browser or a complex JavaScript object.
This solution seems simple in theory, but in most cases it can be time consuming and requires experience with web pages and servers.
Start by monitoring your network traffic. A great tool for this is the Network tab in Chrome DevTools . You will see all outgoing requests with responses (including static files, AJAX requests, etc.) to iterate and search for data.
If the answer is changed by some code before being displayed on the screen, the process will be slower. In this case, you should find this part of the code and understand what is happening.
As you can see, this method may require much more work than the methods described above. On the other hand, it provides the best performance.
The diagram shows the required runtime and package size compared to Jsdom and Puppeteer:
The results are not based on accurate measurements and can vary, but show well the approximate difference between these methods.
Cloud Integration
Suppose you have implemented one of these solutions. One way to run the script is to turn on the computer, open the terminal and start it manually.
But it will become annoying and inefficient, so it’s better if you could just upload the script to the server, and it would execute the code regularly, depending on the settings.
This can be done by running the actual server and setting the rules for when to run the script. In other cases, the cloud function is a simpler way.
Cloud functions are repositories designed to execute loaded code when an event occurs. This means that you do not need to manage the servers, this is done automatically by your cloud provider.
A trigger can be a schedule, a network request and many other events. You can save the collected data in a database, write it to the Google sheet or send it by email . It all depends on your imagination.
Popular cloud providers are Amazon Web Services (AWS), Google Cloud Platform (GCP) and Microsoft Azure :
You can use these services for free, but not for long.
If you use Puppeteer, Google’s cloud functions are the easiest solution. The package size in the Headless Chrome format (~ 130 MB) exceeds the maximum allowed archive size in AWS Lambda (50 MB). There are several methods to get it to work with Lambda, but the default GCP features support Chrome without a header , you just need to enable Puppeteer as a dependency in package.json .
If you want to learn more about cloud functions in general, check out the architecture information without servers. Many good manuals have already been written on this topic, and most providers have easy-to-understand documentation.
Source: https://habr.com/ru/post/442258/
All Articles