Python code life cycle - CPython execution model
Hello! Spring has arrived, and this means that before the launch of the Python Developer course, less than a month remains. Our current publication will be devoted to this course.

Tasks:
')
- Learn about the internal device Python;
- Understand the principles of building an abstract syntax tree (AST);
- Write a more efficient code in time and memory.
Preliminary recommendations:
- Basic understanding of the interpreter (AST, tokens, etc.).
- Knowledge of Python.
- Basic knowledge of S.
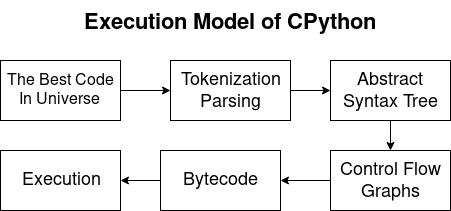
CPython execution model
Python compiled and interpreted language. Thus, the Python compiler generates bytecodes, and the interpreter executes them. In the course of the article we will consider the following questions:
Parsing and tokenization.
Grammar.
Grammar defines the semantics of the Python language. It is also useful in indicating the way in which the parser should interpret the language. The Python grammar uses a syntax similar to the Backus-Naur extended form. It has its own grammar for the translator from the source language. You can find the grammar file in the “cpython / Grammar / Grammar” directory.
The following is an example of grammar,
Simple expressions contain small expressions and brackets, and the command ends with a new line. Small expressions look like a list of expressions that import ...
Any other expressions :)
Tokenization (Lexical Analysis)
Tokenization is the process of obtaining textual data flow and splitting into tokens meaningful (for the interpreter) words with additional metadata (for example, where the token begins and ends, and what the string value of this token is).
Tokens
A token is a header file containing definitions of all tokens. A total of 59 types of tokens in Python (Include / token.h).
Below is an example of some of them,
You can see them if you break some kind of Python code into tokens.
CLI Tokenization
Here is the file tests.py
Then we token it with the python -m tokenize command and we get the following output:
Here the numbers (for example, 1.4-1.13) show where the token started and where it ended. The encoding token is always the very first token we receive. It gives information about the encoding of the source file, and if there are any problems with it, the interpreter causes an exception.
Tokenization with tokenize.tokenize
If you need to split a file from your code into tokens, you can use the tokenize module from stdlib .
The type of the token is its id in the token.h header file . String is the value of the token. Start and End show where the token begins and ends, respectively.
In other languages, blocks are indicated by brackets or begin / end operators, but Python uses indents and different levels. INDENT and DEDENT tokens and point to indents. These tokens are needed to build relational parsing trees and / or abstract syntax trees.
Parser generation
Parser generation is a process that generates a parser according to a given grammar. Parser generators are known as PGen. Cpython has two parser generators. One is the original (
“The original generator was the first code I wrote for Python”
-Guido
From the above quotation it becomes clear that pgen is the most important thing in a programming language. When you call pgen (in Parser / pgen ), it generates a header file and a C-file (the parser itself). If you look at the generated C code, it may seem meaningless, since its meaningful form is optional. It contains many static data and structures. Further we will try to explain its main components.
DFA (Definite State Machine)
The parser defines one DFA for each non-terminal. Each DFA is defined as an array of states.
For each DFA there is a starter kit that shows which tokens a special non-terminal can begin with.
condition
Each state is defined by an array of transitions / edges (arcs).
Transitions (arcs)
There are two numbers in each transition array. The first number is the name of the transition (arc label), it refers to the symbol number. The second number is the destination.
Names (labels)
This is a special table that relates the id of the character to the name of the transition.
The number 1 corresponds to all identifiers. Thus, each of them gets different transition names even if they all have the same symbol id.
A simple example:
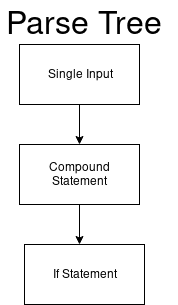
Suppose we have a code that displays “Hi” if 1 is true:
The parser considers this code as single_input.
Then our parse tree starts with a single input root node.

And the value of our DFA (single_input) is 0.
It will look like this:
};
Here
Having the initial set of

New DFA parsit compound statements.
And we get the following:
Only the first transition can begin with
Next, we again change the DFA and the next DFA parses ifs.
As a result, we get a single transition with the designation 97. It coincides with the
When we switch to the next state, staying in the same DFA, the next arcs_41_1 also has only one transition. This is true for test non-terminal. It must begin with a number (for example, 1).
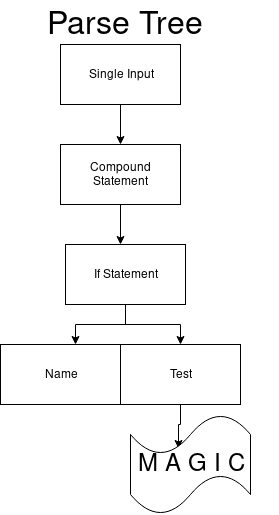
In arc_41_2 there is only one transition that gets the token colon (:).

So we get a set that can start with a print value. Finally, go to arcs_41_4. The first transition in the set is an elif expression, the second is an else, and the third is for the last state. And we get the final view of the parse tree.

Python interface for the parser.
Python allows you to edit the parsing tree for expressions using a module called parser.
You can generate a specific syntax tree (Concrete Syntax Tree, CST) using parser.suite.
The output value will be a nested list. Each list in the structure has 2 elements. The first one is the id of the character (0-256 - terminals, 256+ - non-terminals) and the second is the string of tokens for the terminal.
Abstract syntax tree
In fact, an abstract syntax tree (AST) is a structural representation of source code in the form of a tree, where each vertex denotes different types of language constructs (expression, variable, operator, etc.)
What is a tree?
A tree is a data structure that has a root vertex as the starting point. The root vertex is descended by branches (transitions) down to other vertices. Each vertex, except the root, has one unique parent vertex.
There is a definite difference between an abstract syntax tree and a syntax analysis tree.
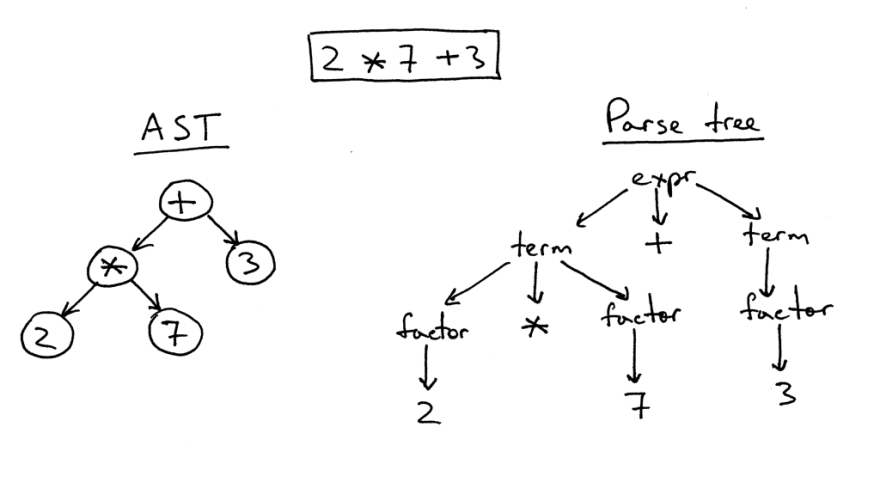
On the right is the tree parsing the expression 2 * 7 + 3. This is literally a one-to-one image of the source code in a tree. All expressions, terms and values are visible on it. However, such an image is too difficult for a simple piece of code, so we have the opportunity to simply remove all the syntax expressions that we had to define in the code for the calculations.
Such a simplified tree is called an abstract syntax tree (AST). On the left in the picture it is shown for the same code. All syntax expressions have been dropped for ease of understanding, but remember that certain information has been lost.
Example
Python offers an integrated AST module for working with AST. To generate code from AST trees, you can use third-party modules, such as Astor .
For example, consider the same code as before.
To get the AST, we use the ast.parse method.
Try using the
AST is in principle considered more visual and easy to understand than the parse tree.
Control Flow Graf (CFG)
Control flow graphs are directional graphs that model a program flow using basic blocks that contain an intermediate representation.
Usually CFG is the previous step before getting the output code values. The code is generated directly from the base blocks using reverse depth search in CFG, starting from the vertices.
Baytkod
Python bytecode is an intermediate set of instructions that run on a Python virtual machine. When you run the source code, Python creates a directory called __pycache__. It stores the compiled code in order to save time if the compilation is restarted.
Consider a simple Python function in func.py.
The type of object
It has an attribute
Code Objects
Code objects are immutable data structures that contain instructions or metadata necessary to execute code. Simply put, these are representations of Python code. You can also get code objects by compiling abstract syntax trees using the compile method.
Each code object has attributes that contain certain information (with the prefix co_). Here we mention only a few of them.
co_name
To begin with - the name. If there is a function, then it should have a name, respectively, this name will be the name of the function, a similar situation with the class. In the example with AST we use modules, and we can definitely tell the compiler how we want to name them. Let them be just a
co_varnames
This is a tuple containing all local variables, including arguments.
co_conts
A tuple containing all literals and constant values that we have addressed in the function body. It is worth noting the value of None. We did not include None in the function body, however Python pointed it out, because if the function starts to be executed and then ends without receiving any return values, it will return None.
Bytecode (co_code)
The following is the bytecode for our function.
This is not a string, it is a byte object, that is, a sequence of bytes.
The first character displayed is “t”. If we request its numerical value, we get the following.
116 is the same as bytecode [0].
For us, the value 116 means nothing. Fortunately, Python provides a standard library called dis (from disassembly). It is useful when working with the opname list. This is a list of all bytecode instructions, where each index is the name of the instruction.
Let's create another more complex function.
And we find out the first instruction in bytecode.
The LOAD_FAST instruction consists of two elements.
The Loadfast 0 instruction happens to search for variable names in a tuple and to push a zero-indexed item into a tuple in the execution stack.
Our code can be disassembled using dis.dis and convert baytkod to the usual form for a person. Here numbers (2,3,4) are line numbers. Each line of code in Python is expanded as a set of instructions.
lead time
CPython is a stack-oriented virtual machine, not a set of registers. This means that Python code is compiled for a virtual computer with a stack architecture.
When calling a function, Python uses two stacks together. The first is the execution stack, and the second is the stack of blocks. Most calls occur on the execution stack; the block stack keeps track of how many blocks are currently active, as well as other parameters related to blocks and scopes.
We are waiting for your comments on the material and invite you to an open webinar on the topic: “Release it: practical aspects of releasing reliable software”, which will be conducted by our teacher - the programmer of the advertising system in Mail.Ru - Stanislav Stupnikov .
Tasks:
')
- Learn about the internal device Python;
- Understand the principles of building an abstract syntax tree (AST);
- Write a more efficient code in time and memory.
Preliminary recommendations:
- Basic understanding of the interpreter (AST, tokens, etc.).
- Knowledge of Python.
- Basic knowledge of S.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0 CPython execution model
Python compiled and interpreted language. Thus, the Python compiler generates bytecodes, and the interpreter executes them. In the course of the article we will consider the following questions:
- Parsing and tokenization:
- Transformation in AST;
- Control Flow Graph (CFG);
- Baytkod;
- Running on a CPython virtual machine.
Parsing and tokenization.
Grammar.
Grammar defines the semantics of the Python language. It is also useful in indicating the way in which the parser should interpret the language. The Python grammar uses a syntax similar to the Backus-Naur extended form. It has its own grammar for the translator from the source language. You can find the grammar file in the “cpython / Grammar / Grammar” directory.
The following is an example of grammar,
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE Simple expressions contain small expressions and brackets, and the command ends with a new line. Small expressions look like a list of expressions that import ...
Any other expressions :)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue' Tokenization (Lexical Analysis)
Tokenization is the process of obtaining textual data flow and splitting into tokens meaningful (for the interpreter) words with additional metadata (for example, where the token begins and ends, and what the string value of this token is).
Tokens
A token is a header file containing definitions of all tokens. A total of 59 types of tokens in Python (Include / token.h).
Below is an example of some of them,
#define NAME 1 #define NUMBER 2 #define STRING 3 #define NEWLINE 4 #define INDENT 5 #define DEDENT 6 You can see them if you break some kind of Python code into tokens.
CLI Tokenization
Here is the file tests.py
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan") Then we token it with the python -m tokenize command and we get the following output:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER '' Here the numbers (for example, 1.4-1.13) show where the token started and where it ended. The encoding token is always the very first token we receive. It gives information about the encoding of the source file, and if there are any problems with it, the interpreter causes an exception.
Tokenization with tokenize.tokenize
If you need to split a file from your code into tokens, you can use the tokenize module from stdlib .
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ... The type of the token is its id in the token.h header file . String is the value of the token. Start and End show where the token begins and ends, respectively.
In other languages, blocks are indicated by brackets or begin / end operators, but Python uses indents and different levels. INDENT and DEDENT tokens and point to indents. These tokens are needed to build relational parsing trees and / or abstract syntax trees.
Parser generation
Parser generation is a process that generates a parser according to a given grammar. Parser generators are known as PGen. Cpython has two parser generators. One is the original (
Parser/pgen ) and one rewritten in python ( /Lib/lib2to3/pgen2 ).“The original generator was the first code I wrote for Python”
-Guido
From the above quotation it becomes clear that pgen is the most important thing in a programming language. When you call pgen (in Parser / pgen ), it generates a header file and a C-file (the parser itself). If you look at the generated C code, it may seem meaningless, since its meaningful form is optional. It contains many static data and structures. Further we will try to explain its main components.
DFA (Definite State Machine)
The parser defines one DFA for each non-terminal. Each DFA is defined as an array of states.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, }; For each DFA there is a starter kit that shows which tokens a special non-terminal can begin with.
condition
Each state is defined by an array of transitions / edges (arcs).
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, }; Transitions (arcs)
There are two numbers in each transition array. The first number is the name of the transition (arc label), it refers to the symbol number. The second number is the destination.
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, }; Names (labels)
This is a special table that relates the id of the character to the name of the transition.
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, }; The number 1 corresponds to all identifiers. Thus, each of them gets different transition names even if they all have the same symbol id.
A simple example:
Suppose we have a code that displays “Hi” if 1 is true:
if 1: print('Hi') The parser considers this code as single_input.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE Then our parse tree starts with a single input root node.
And the value of our DFA (single_input) is 0.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... } It will look like this:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1, arcs_0_2},};
Here
arc_0_0 consists of three elements. The first is NEWLINE , the second is simple_stmt , and the last is compound_stmt .Having the initial set of
simple_stmt it can be concluded that simple_stmt cannot begin with if . However, even if if is not a new line, then compound_stmt can still begin with if . So we go with the last arc ({4;2}) and add the compound_stmt node to the parse tree and switch to the new DFA before going to number 2. We get the updated parse tree:New DFA parsit compound statements.
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt And we get the following:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, }; Only the first transition can begin with
if . We get an updated parse tree.Next, we again change the DFA and the next DFA parses ifs.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite] As a result, we get a single transition with the designation 97. It coincides with the
if token. static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ... When we switch to the next state, staying in the same DFA, the next arcs_41_1 also has only one transition. This is true for test non-terminal. It must begin with a number (for example, 1).
In arc_41_2 there is only one transition that gets the token colon (:).
So we get a set that can start with a print value. Finally, go to arcs_41_4. The first transition in the set is an elif expression, the second is an else, and the third is for the last state. And we get the final view of the parse tree.
Python interface for the parser.
Python allows you to edit the parsing tree for expressions using a module called parser.
>>> import parser >>> code = "if 1: print('Hi')" You can generate a specific syntax tree (Concrete Syntax Tree, CST) using parser.suite.
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']] The output value will be a nested list. Each list in the structure has 2 elements. The first one is the id of the character (0-256 - terminals, 256+ - non-terminals) and the second is the string of tokens for the terminal.
Abstract syntax tree
In fact, an abstract syntax tree (AST) is a structural representation of source code in the form of a tree, where each vertex denotes different types of language constructs (expression, variable, operator, etc.)
What is a tree?
A tree is a data structure that has a root vertex as the starting point. The root vertex is descended by branches (transitions) down to other vertices. Each vertex, except the root, has one unique parent vertex.
There is a definite difference between an abstract syntax tree and a syntax analysis tree.
On the right is the tree parsing the expression 2 * 7 + 3. This is literally a one-to-one image of the source code in a tree. All expressions, terms and values are visible on it. However, such an image is too difficult for a simple piece of code, so we have the opportunity to simply remove all the syntax expressions that we had to define in the code for the calculations.
Such a simplified tree is called an abstract syntax tree (AST). On the left in the picture it is shown for the same code. All syntax expressions have been dropped for ease of understanding, but remember that certain information has been lost.
Example
Python offers an integrated AST module for working with AST. To generate code from AST trees, you can use third-party modules, such as Astor .
For example, consider the same code as before.
>>> import ast >>> code = "if 1: print('Hi')" To get the AST, we use the ast.parse method.
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8> Try using the
ast.dump method to get a more readable abstract syntax tree. >>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])" AST is in principle considered more visual and easy to understand than the parse tree.
Control Flow Graf (CFG)
Control flow graphs are directional graphs that model a program flow using basic blocks that contain an intermediate representation.
Usually CFG is the previous step before getting the output code values. The code is generated directly from the base blocks using reverse depth search in CFG, starting from the vertices.
Baytkod
Python bytecode is an intermediate set of instructions that run on a Python virtual machine. When you run the source code, Python creates a directory called __pycache__. It stores the compiled code in order to save time if the compilation is restarted.
Consider a simple Python function in func.py.
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?") >>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan? The type of object
say_hello is a function. >>> type(say_hello) <class 'function'> It has an attribute
__code__ . >>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1> Code Objects
Code objects are immutable data structures that contain instructions or metadata necessary to execute code. Simply put, these are representations of Python code. You can also get code objects by compiling abstract syntax trees using the compile method.
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'> Each code object has attributes that contain certain information (with the prefix co_). Here we mention only a few of them.
co_name
To begin with - the name. If there is a function, then it should have a name, respectively, this name will be the name of the function, a similar situation with the class. In the example with AST we use modules, and we can definitely tell the compiler how we want to name them. Let them be just a
module . >>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello' co_varnames
This is a tuple containing all local variables, including arguments.
>>> say_hello.__code__.co_varnames ('name',) co_conts
A tuple containing all literals and constant values that we have addressed in the function body. It is worth noting the value of None. We did not include None in the function body, however Python pointed it out, because if the function starts to be executed and then ends without receiving any return values, it will return None.
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?') Bytecode (co_code)
The following is the bytecode for our function.
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00' This is not a string, it is a byte object, that is, a sequence of bytes.
>>> type(bytecode) <class 'bytes'> The first character displayed is “t”. If we request its numerical value, we get the following.
>>> ord('t') 116 116 is the same as bytecode [0].
>>> assert bytecode[0] == ord('t') For us, the value 116 means nothing. Fortunately, Python provides a standard library called dis (from disassembly). It is useful when working with the opname list. This is a list of all bytecode instructions, where each index is the name of the instruction.
>>> dis.opname[ord('t')] 'LOAD_GLOBAL' Let's create another more complex function.
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code And we find out the first instruction in bytecode.
>>> dis.opname[bytecode[0]] 'LOAD_FAST The LOAD_FAST instruction consists of two elements.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>' The Loadfast 0 instruction happens to search for variable names in a tuple and to push a zero-indexed item into a tuple in the execution stack.
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a' Our code can be disassembled using dis.dis and convert baytkod to the usual form for a person. Here numbers (2,3,4) are line numbers. Each line of code in Python is expanded as a set of instructions.
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE lead time
CPython is a stack-oriented virtual machine, not a set of registers. This means that Python code is compiled for a virtual computer with a stack architecture.
When calling a function, Python uses two stacks together. The first is the execution stack, and the second is the stack of blocks. Most calls occur on the execution stack; the block stack keeps track of how many blocks are currently active, as well as other parameters related to blocks and scopes.
We are waiting for your comments on the material and invite you to an open webinar on the topic: “Release it: practical aspects of releasing reliable software”, which will be conducted by our teacher - the programmer of the advertising system in Mail.Ru - Stanislav Stupnikov .
Source: https://habr.com/ru/post/442252/
All Articles