Project "Prometheus": search for fires using AI

Translation Project Prometheus - An AI-powered fire finding solution
My colleagues and I are working on the Prometheus project (Prometheus) - this is a solution for early fire detection that combines AI, computer vision, automatic drones, and weather forecasting services. This complex is designed to detect fires in the wild before they develop into a real disaster. We want to talk about the project in more detail, how it works and what theoretical device underlies it. The material will be submitted as independently as possible from specific technologies, so if you are interested in specific implementation features (CNTK, Faster R-CNN, Docker containers, Python, .NET framework, etc.), then go to our GitHub repository . And here we only mention the technologies used.
')
A little introduction:
Motivation
In 2017, it was estimated that forest fires cost the US economy about $ 200 billion. This is slightly less damage from hurricanes. But the difference is that if you extinguish fires until they have grown, then the losses can be greatly reduced. However, the task of fire detection is a routine task, difficult and requiring the participation of people: for the most part they sit on observation towers with binoculars, trying to notice a fire in time, or fly around the territory by helicopters or by means of controlled drones. The Prometheus project is designed to automate all this routine with the help of automatic drones, which will detect fires at an early stage, otherwise wind, dryness, or relief features will help the fire spread to acres of land in minutes. Moreover, most of these fires occur in remote areas where there are few people and no one to track the occurrence of outbreaks.
If you send drones to patrol these remote areas, they will help detect fire in time and minimize damage.
Project
"Prometheus" can be divided into three parts:
- The fire detection module uses deep learning algorithms to identify small foci using the drone's RGB camera (implemented as a cloud REST service).
- Flight planning module allows the user to select and plan patrol zones (implemented as a Windows application and integrated with weather mapping services).
- The warning system allows the user to quickly notify the command of a fire found (using Azure Functions and Twilio).
Fire detection
We use automated drones to search for fire in remote areas. Installed on-board RGB cameras are used to capture the entire area, and the photos are then fed to machine learning models that look for fires and notify the user. Thanks to everybody, you're free. Wait a minute though ...
Lesson one: size matters
Defining fires with the help of computer vision in the proportions we needed proved to be a difficult task, and therefore we used a different approach. You probably thought that using RGB cameras was not practical because infrared cameras are preferable in this case. But after talking with firefighters, we found out that everything is not so simple: fires will look like places with high air temperature on infrared cameras, and some surface areas will look like heat sources only because of the features of light reflection. In addition, these cameras are significantly more expensive. Firefighters use them for the most part at night to see if they were able to completely extinguish the fire.
In general, if you want to use the machine learning to attribute the image to a specific category - fire / not fire - then you will certainly use the classification methodologies. Easy peasy. But it may be that the characteristics that are required for classification will be too small compared with the full image. For example, a typical small source of ignition looks like this:

In such cases, including ours, the best performance in identifying objects can be achieved if you do not pay attention to their specific location or count the number in the image. But more often the device of the object definition system turns out to be much more complicated. There are different ways to solve this problem, and we used the regional convolutional neural network (R-CNN) or, more precisely, the Faster R-CNN implementation.
Also often use YoLo and Detectron (recently transferred to open-source).
The process consists of the following steps:
- Localization: you need to generate areas (samples) of areas inside the image that may contain the desired objects. These areas are called Regions of Interest (ROI). They are large sets of frames that cover the entire image. We generate ROI using the methodology described in “Segmentation as Selective Search for Object Recognition” by Koen EA van de Sande and others. The technique is implemented in the dlib Python library.
- Classification of objects: then visual properties are extracted from each frame, they are evaluated and the system assumes whether there are any objects there and what they are (more on this below).
- Non-maximum suppression: it happens that the frames representing the same object partially or completely overlap each other. To avoid such duplications, the intersecting frames are combined into one. This task may require a lot of computing power, however, some optimizations are implemented in the Intel Math Library.
Lesson two: your data may need help.
Machine learning needs data. But in deep learning (that is, in multidimensional input space) you will need a lot of data to extract the visual properties of interest. As you understand, it is difficult to find a large dataset of objects that interest us (fires). To solve this problem, we used the method of “transfer learning” with previously trained models for the classification of general-purpose images, as they can generalize well. Simply put, you take a model that has been previously trained to define something, and “tune it” with your dataset. That is, this model will retrieve properties, and you will already try to use their representations learned for task A (usually the high-level task) in solving problem B (usually low-level). The success of solving Problem B shows how much the model for Task A was able to learn about Task B. In our case, Task A was the task of classifying ImageNet objects, and Task B was identifying fires.
This technique can be applied by removing the last layer from a previously trained neural network and replacing it with its classifier. Then we freeze the weights of all the other layers and in the usual way we train the neural network.
The resulting neural network is not available on GitHub because of its size - about 250 MB. If you need it, write to us .
For ImageNet there are many already trained models (AlexNet, VGG, Inception, RestNet, etc.). In each of them, the authors used different trade-offs in terms of speed, accuracy, and structure. We chose AlexNet, because it requires less computational resources, and the results in our problem differ little from other networks.
Lesson Three: Videos (especially their individual shots) - your best friends.
But despite the transfer of training, we still need quite a lot of data to solve the problem of classification. And here we took advantage of the video. From each video you can extract a bunch of frames and quickly get a great great dataset. The video has another useful feature: if an object or camera moves, then you get images of an object with different lighting, from different angles and in different positions, so it turns out very high quality.
We didn’t upload our set of pictures to the repository either because of the size, knocking.
We collected videos from drones from various sources and manually tagged them. There are several tools for assigning tags to images in different formats, depending on the deep learning framework used. I recommend LabelImg for Linux / Windows and RectLabel for Mac. We used CNTK, so we stopped at the Microsoft VoTT tool, which can export to CNTK and TensorFlow formats.
Lesson number four: buy a video card (or rent a cloud card)
Learning a big model like ours requires a lot of computational power, and the GPU will be of great help. It took us about 15 minutes to learn with the help of the NVIDIA GeForce GTX 1050. But even despite the use of a video card, setting up the model parameters is a big difficulty. Microsoft has a good tool, the Azure Experimentation Service, which allows you to run several exercises in parallel in the cloud with different parameters and analyze the resulting accuracy. Also look at AWS SageMaker.
In our repository is the Sweep_parameters.py script , which automatically clears the parametric space and starts training tasks.
Done!
So, we have trained our R-CNN and got stuck with the transfer of training, deep training, video cards, etc. How can we now share our work with others? First, we launched a REST service to interact with the model. The API allows you to send images for evaluation and returns areas of images, the presence of fire for which the model identified with a certain confidence. You can also tell the API whether the image is actually fire or not. Other endpoints are used to get feedback and make improvements.
The REST API service is packaged in a Docker container and published in the cloud, which allows for a cheap scaling solution. In the repository you can find a file with a Docker image.
Flight planning
Red warnings
How does Prometheus know where to send drones? We are integrating with national weather services to determine “red alerts”. These are areas in which air temperature, wind direction and strength, humidity and atmospheric pressure increase the likelihood of fires. Since weather services are focused on their countries, they can hardly be used for foreign search. Today we work with American and Argentine services.
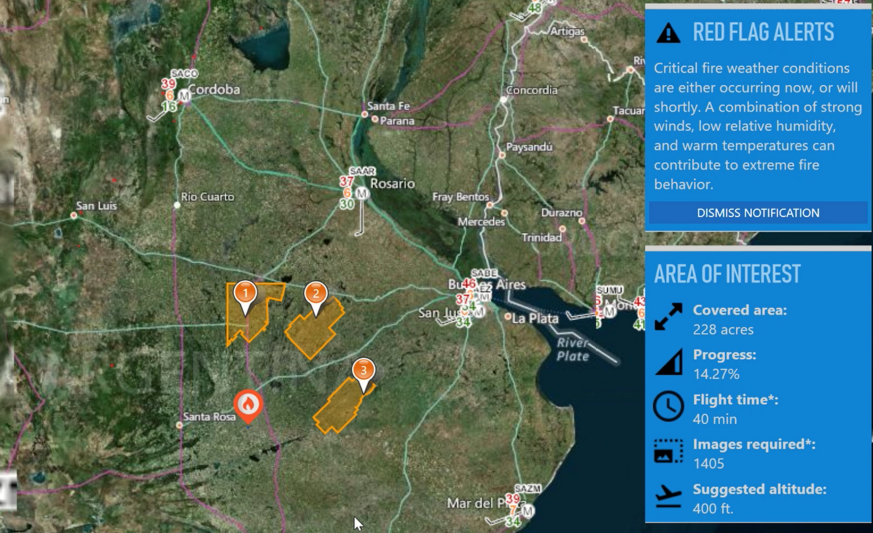
Weather Information
It is very important to have accurate weather data in the areas of interest. Firefighters asked us about this feature. We obtain weather data by polling weather stations through the National Weather Service map server and overlaying the information received on the map. We emphasize that this is not a weather forecast, but real measurements:
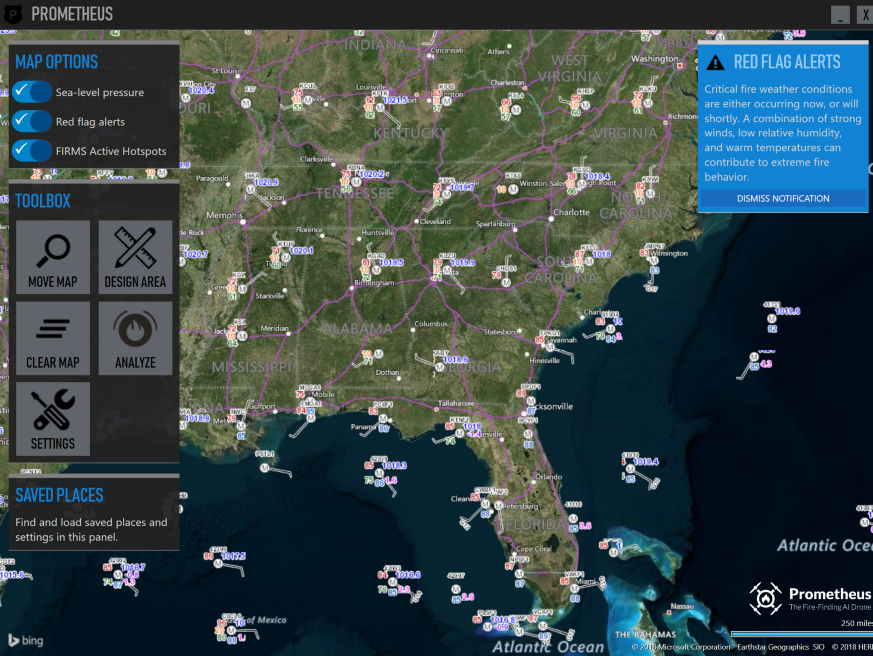
Weather stations in the USA .
Don't you understand how this card works? You are not alone in this. It took us a few weeks to figure out how to use it. There is little information in the network. If you want to experiment with data from weather stations, you will have to get API keys from providers, since we have no right to share them.
Warning system
When the system detects a fire, it asks the operator to confirm the fact of detection. The interface looks like this:

Fire Confirmation Window .
As you can see, the system works quite accurately even in such difficult cases as this one. A small red frame delineates the fire with a 67% probability. In fact, Prometheus tries to detect large fires and is unstable when calculating areas in scenarios like this. Everything is in order, and it was intended. We just were not interested in such situations.
The warning system sends an SMS notification to the pre-assigned phone numbers with GPS coordinates of the fire. The mailing is done using Twilio, a cloud platform whose APIs allow, among other things, to programmatically send and receive text messages.
Want to take a look?
→ The source code is here.
Thanks
Prometheus was developed in collaboration with the Tempe Fire Department, Arizona, the Argentine Fire Department and the Argentine National Institute of Agricultural Technologies of Argentina.
Source: https://habr.com/ru/post/441620/
All Articles