Almost reliable solutions
The main advantage in the IoT market is cost. Therefore, priority is given to cheap but unreliable components. Unreliable devices break, make errors, hang and require maintenance. It is not customary to talk about insecurity at conferences, but the report of Stanislav Yelizarov ( elstas ) on InoThings ++ was devoted to this — how things do not work.

Under the cut, we will discuss methods for compensating for the unreliability of equipment, communication channels and personnel using software; fault tolerance problems and their solutions; human factor; electrical tape and socks as a universal means of repairing spacecraft and data transmission by trucks.
')
About the speaker : Stanislav Yelizarov is involved in the network infrastructure department at STRIZH, which produces meters, sensors, basic LTE stations, and also collects readings where any other communication system simply does not work.
This is a quote from the Canadian philosopher Marshall McLuhan , which accurately describes the state of technology. Refuses everything: computers hang, smartphones slow down, elevators stop between floors, space probes go astray, and people are mistaken.
The topic of reliability, especially its part, is fault tolerance, as big as security. The letter S in the term IoT is responsible for Security , and the letter R is responsible for Reliability - reliability.
If we talk about the reliability and errors, then let us remember Johann Gutenberg . Officially, he is the first printer, and according to the version of Ilf and Petrov - the first printer , because he made many mistakes in his Bible.

Gutenberg's technology has progressed, the book market has grown, volumes have increased, and with them errors. 50 years after the first printed book, Gabriel Pierri came up with an errata - a list of typos at the end of the book. It was a good trick, because it is inconvenient and economically unprofitable to reprint large lots. If the reader notices a typo, then just open the list of errors and look at critical fixes. The leader of typos was Thomas Aquinas and his Summa Theologia - 180 pages of errors in the official errata.
Modern errata produced iron manufacturers. The picture below is the official errata of the most popular chip CC1101 , which is still in effect. In the list of errors, the chip sometimes does not accept something, sometimes it sends something wrong, and sometimes the PLL does not always work. This is not what you expect from a mass processor that has been produced for decades.

Another example is the MSP430 microprocessor, built on a set of commands. The microprocessor is about the same as the PDP-11 , on which Kernighan and Ritchie developed Unix. This is not Errata Thomas Aquinas, but the manufacturer offers us 27 pages of errors , many of which even do not know how to solve.

Iron is more or less clear, errors are described and reproducible, but the biggest source of errors in IoT systems is man .
On January 13, 2018, all residents of Hawaii came to the mobile phones with an alert about the missile threat and the need to hide in an air-raid shelter.

It is not clear who was wrong: the operator or the person who designed the interface. But if you look at the picture, the answer suggests itself. What to click to call a test, not a combat, warning of a missile threat? If you do not know the answer, you will be mistaken.

The operator pressed the wrong button, and the mass mailing started. The system did not have any parameters by which it would be possible to prevent or confirm the dispatch: “Are you sure you want to warn about a missile threat?”. It took 30 minutes for the staff of the center to realize what had happened and to send a message stating that the attack was false.
Why we do not see these errors and do not believe that something is wrong? Because the man himself corrects all errors.
If we feel that the computer does not work very well - we restart it. If we see that the mobile connection is gone, then we are looking for a place where it catches. If the machine does not work, we repair it.
The photo below shows human savvy to be proud of. Three people dangled in the Apollo 13 between the Earth and the Moon and were able to solve a non-trivial task - to put a square filter in a round hole. In addition to square filters, the mission was not lucky in another: the explosion of an oxygen cylinder, lack of water, engine damage. The team tried to survive using socks, electrical tape and packs of suits.

The man, as NASA said, is a very good backup system and fixes a lot. Solving problems on a spacecraft with the help of electrical tape and socks can be called almost reliable: it is completed in a short time, it will surely work and people will return alive, but this cannot be allowed into production.
The problem of resiliency for the Internet of things is very important, because the number of devices is growing. In the report of the consulting company McKinsey , in 2013 there were 10 billion IoT devices in the world, and by 2020 this number will increase to 30 billion.

We just physically will not be able to repair all of these counters - just not enough time. Systems that were designed for maintenance by people will not help us; instead, we will fix them.
In 2018 in the media and scientific journals flashed the news that the Chinese covered 100,000 sensors 2 channels with a total length of 1,400 km. A total of 130 types of sensors: water, wind, camera. From the point of view of operating expenses, the system is simply catastrophic: how many people need to wipe the camera or remove the snags? The entire state will be busy only cleaning and maintaining the system - it is not very autonomous.
Therefore, I want to talk a little about fault tolerance , about ensuring the operation of the system. Using simple examples, I will talk about tricks that will help in a short time to get a guaranteed working solution to present the product to investors, and then think about how to increase reliability incrementally. These tricks are quite versatile and will always help. The only thing that they are not very recommended for use in production, because they are like the filter.
Imagine: the day will come when investors will come to you for a project report, and you need to show a working product. Where to start so as not to screw it up?
In the picture below there are two unrelated devices. On the left, a toy called a “sorter” : we insert a round one into a round one and a square one into a square one. A one-year-old child will learn how to use a toy in 2-3 attempts, because it is impossible to make a mistake with the “device” - a triangle will not fit into a square.

The same idea was proposed by the company Harris, which produces military radio stations. The picture on the right is Harris Falcon 3 , a marvel of engineering. Look at the interfaces, they are all different. In a state of combat, in conditions where there is no time to think, the operator will not physically be able to do something wrong. The power cable will not enter the connector from the antenna, and the radio operator will simply connect all the systems, even without turning on the brain. This is a simple and working way to prevent mistakes and reduce their likelihood. You say:
- And if we have a presentation tomorrow. Do we need to rewrite all interfaces? We did everything the same way there: 4 usb ports, 5 ethernet ports, we will definitely be mistaken.
No question, the simplification works here too - everything is closed. If you have 4 usb ports and one of them is guaranteed to work, leave it and close the rest. For example, tape - feel like an astronaut.
We created a simple device - a prototype, ready to be shown. What's next? Next, think about redundancy.
Internet of Things devices operate on the basis of information theory : there is a signal source, a receiver, a coder, a modulator, a propagation medium, and a source of errors that interferes and distorts the actual situation. A good way to reduce interference is to add redundancy , with which we can detect a critical situation and level out the effect of it: notify the operator or correct an error.

An example of redundancy is the STRIZH network. Most devices on the network are transmitted without confirmation: the device emits a signal and the base station receives it.
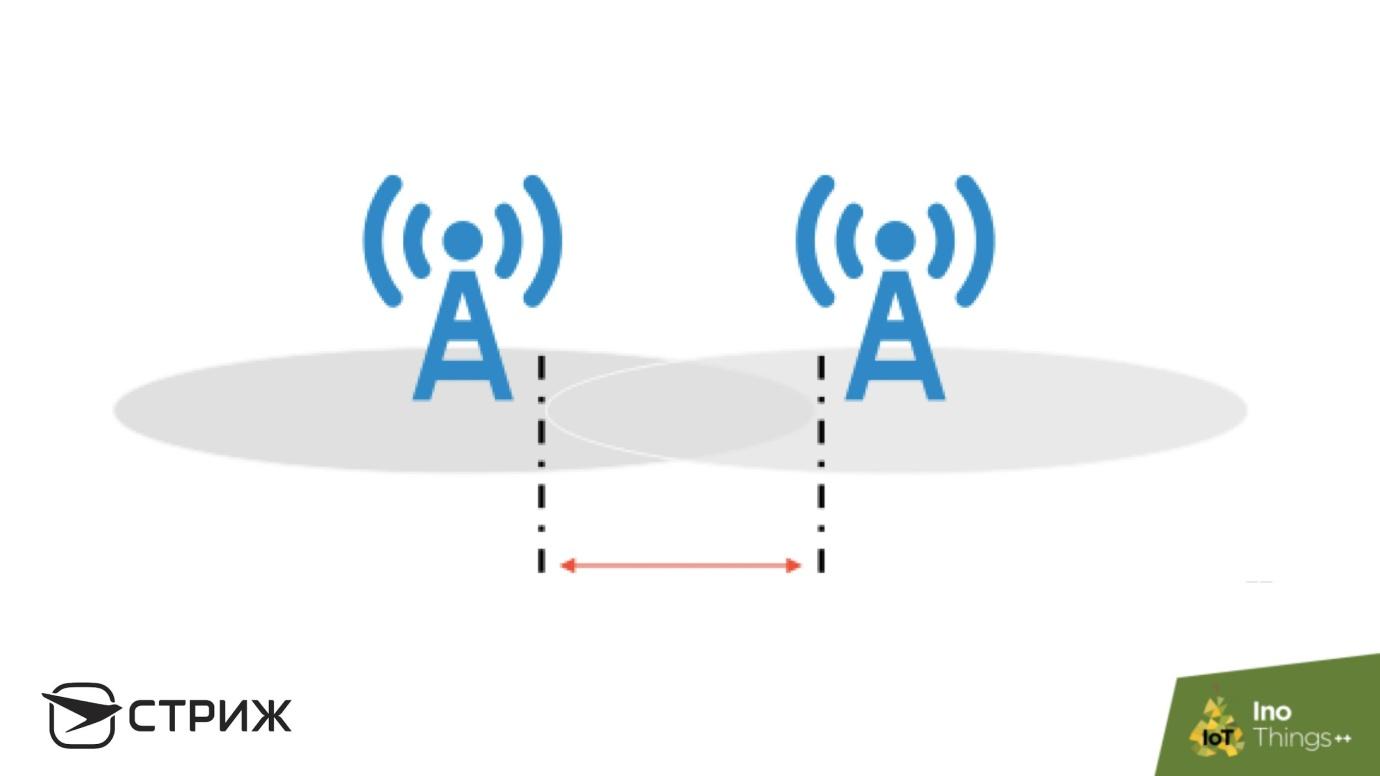
Imagine the situation. We have a zone with interference, in which the probability of message delivery to the base station is 90%, and the presentation is required to show no more than 1% loss. It seems that there is a lot of work: correcting protocols, reducing the range, but a quick and easy solution is redundancy. Next to the station that receives the signal with a delivery probability of 0.9, we put the second one, with the same delivery probability, and the probability of failure of both stations is simultaneously equal to 0.01. The probability multiplication theorem operates here: the probability of failure of each station individually is 0.1, and the failure of both of them is just 1%, provided that the base stations are independent. In this zone, there will be the highest probability of reception between base stations.
Another way to demonstrate the principle of redundancy - Watchdog Timer . This is a physical device that is embedded by most processor manufacturers. If the Watchdog Timer did not receive a signal from the computer after a certain time interval, then the device restarts the computer.

Using WT does not increase reliability, but availability . The computer detects the problem, takes control actions and reboots the computer. NASA is very fond of this and knows many different ways to use Watchdog Timer.
Below is an example of a multi-stage Watchdog Timer: when certain events occur, it sends an NMI — a hardware interrupt that will be required to work on the processor. When a certain event occurs, Watchdog informs the computer: “Try to reboot itself, otherwise turn off the power”. If the first timer did not work, the second one will work.

Redundancy works well within the operating system. Our base station is like this. It consists of various and independent modules . The autonomy of the modules prevents the error from getting from one module to another - a “pool” with errors is created, which we block. Above the hierarchy - a set of supervisors : scripts that monitor the situation on certain parameters. For example, that the process is in the operating system, it is not Zombies and does not flow through the memory. The root element is the scheduler , for example, cron.
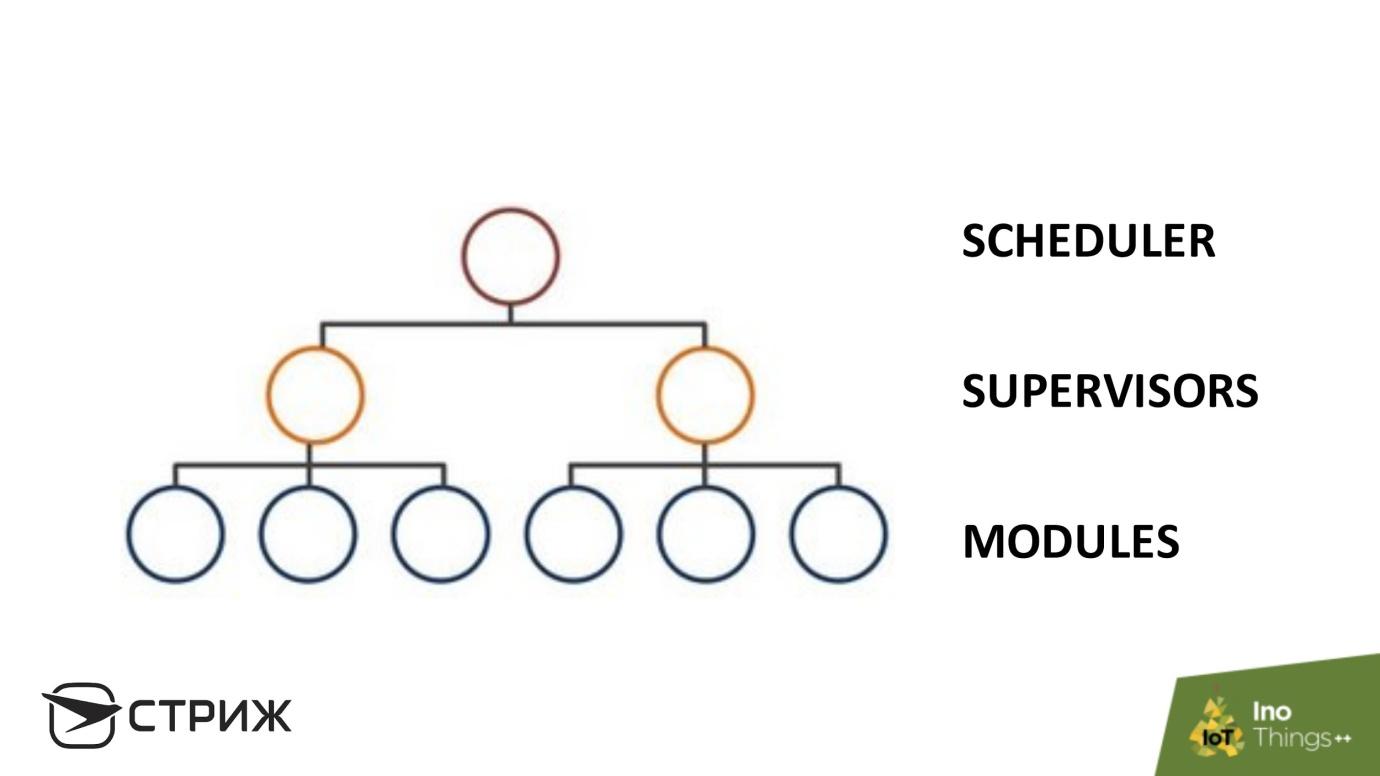
The hierarchical structure creates good parameters for system availability: if a module crashes, the supervisor sees and reloads it, there is some redundancy in the modules, some modules perform the function of others.
My favorite and most popular method among mathematicians. If it is known under what conditions the equipment operates, then in these conditions the pilot should be conducted. I will show you with examples.
Example number 1 . We created a device that works well at room temperature, and we are told:
- We are demonstrating the project in the Far North. Now there is −40, but make sure that everything works.
We run to the Internet and are looking for a solution:
- We need thermally stable quartz and flash drives that will not fail at −40.
Time goes on, resources are less and less, and panic - more. We think that the project is failed, but the transition to the reference system in which the base station operates will save us. Place the device in the box in which the heater and thermal relay are located. They are fairly stable guys and work almost always. When it is cold outside - the box is heated, and the device is working under normal conditions - we moved to the reference system in which we know and use the solution.

Example number 2 . Transition to moving reference systems. Imagine that we are collecting container data from a train. The first standard solution is to use gsm modems. This method is not suitable: for fast moving objects, you should use LTE or 5G devices that do a good doppler, and this is expensive. If the train moves in Russia, then when it arrives at the railway station, all modems will connect to the station and it will simply fall due to network overload.
Solution: transition to a fixed frame of reference. Let us recall the motion relativity: we place the base station inside the train and it is motionless relative to the moving train. The station will collect information from all sensors and transmit further using a gateway, satellite or LTE modem.
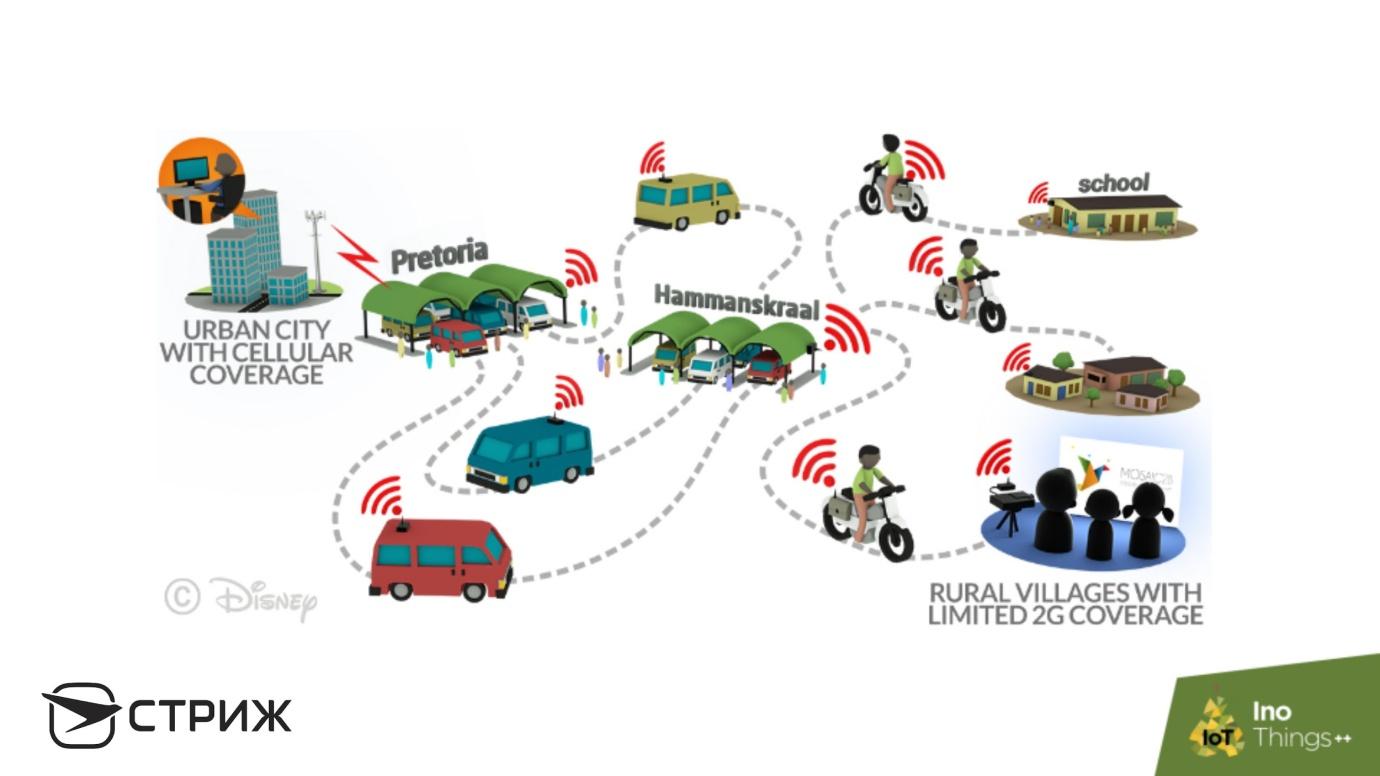
This approach improves reliability, helps to solve impossible tasks and organize delay-tolerant networking - a network that is resistant to discontinuities . For some reason, the approach is not loved in Russia, but it is actively promoted by the Disney Research division of the same corporation. They have not the Internet of things, but Internet toys - Internet of Toys . The company worries that African children do not watch Disney cartoons. It is expensive to carry out data transmission networks, install towers, draw fiber in Africa, and still they will steal everything, so they went the other way and used Richard Hamming's ideas:
At Disney, they did : equip bus stations and buses with a system of the cheapest Wi-Fi routers and a set of hard drives. The bus pulls up to the station, quickly downloads a set of Disney films to Wi-Fi and drives on. He comes to one village, to another, and unloads films in each one - African children are happy. This so-called Mul-Networks - cheap mules that move slowly, do not do well with the doppler, but deliver information to all points.
Similar developments in Disney exist for the transfer of email - the letter will arrive to you by bus. Very funny technology, but Amazon loves it, for example.
Amazon has a service for transporting exabytes of data - one million terabytes. If you have a large data center and you are thinking of moving to Amazon, because everything is already there, then in America they can fit such a truck to you and transport your data. If delays are not important to you, then this is a good way: the data transfer rate is of the order of tens or hundreds of Gbit / s. In addition to trucks, Amazon can send you a bag with hard drives - a snowball.

We understood that reliability is important, because both people and equipment refuse. Reliability needs to be thought the same as safety. For pilot presentations, turn on Watchdog, add redundancy and simplify so that it is impossible to go wrong. Think about how to go into the conditions under which the system is guaranteed to work. Now let's move on to the last method, which is different from the rest, and techies often ignore it.
You will be forgiven much if your prototype looks beautiful. If something goes wrong during the presentation and everything fails, you will hear: “Yes, everything is broken, but you have such a great product. I think that you need to give one more attempt to correct it. ” The principle works for Tesla: the company has problems with shipping, autopilot, accidents, but everyone loves them, because cars have a cool design. For this they all forgive.

The future of the Internet of things is insecurity : IoT is aimed at mass markets, and for the mass market the decisive factor is price. So the Internet of things will consist of many cheap and unreliable devices . As the number of devices grows, so will the number of failures. We simply do not have enough hands to correct all errors. Therefore, the only way is that devices must independently deal with the consequences of failures . These are autonomous systems that must learn to repair themselves.
I would suggest that you take up the topic of reliability and learn how to show pilots in a cool way using three methods: simplify everything you can, add redundancy and create conditions under which the pilot will work. Do not forget that we are all human beings and are not guided by logic, but by feelings , so create beautiful projects .
There are no books or set of articles on reliability. To delve into the topic, start with an article about health, reliability, security , and then learn the experience of the NASA jet propulsion laboratory . They created Voyager and Curiosity and they know everything about reliability . Get inspired by the greats.
Under the cut, we will discuss methods for compensating for the unreliability of equipment, communication channels and personnel using software; fault tolerance problems and their solutions; human factor; electrical tape and socks as a universal means of repairing spacecraft and data transmission by trucks.
')
About the speaker : Stanislav Yelizarov is involved in the network infrastructure department at STRIZH, which produces meters, sensors, basic LTE stations, and also collects readings where any other communication system simply does not work.
Unreliability
"If something does not work, then it is already outdated."
This is a quote from the Canadian philosopher Marshall McLuhan , which accurately describes the state of technology. Refuses everything: computers hang, smartphones slow down, elevators stop between floors, space probes go astray, and people are mistaken.
First mistakes
The topic of reliability, especially its part, is fault tolerance, as big as security. The letter S in the term IoT is responsible for Security , and the letter R is responsible for Reliability - reliability.
If we talk about the reliability and errors, then let us remember Johann Gutenberg . Officially, he is the first printer, and according to the version of Ilf and Petrov - the first printer , because he made many mistakes in his Bible.
Gutenberg's technology has progressed, the book market has grown, volumes have increased, and with them errors. 50 years after the first printed book, Gabriel Pierri came up with an errata - a list of typos at the end of the book. It was a good trick, because it is inconvenient and economically unprofitable to reprint large lots. If the reader notices a typo, then just open the list of errors and look at critical fixes. The leader of typos was Thomas Aquinas and his Summa Theologia - 180 pages of errors in the official errata.
Modern errata produced iron manufacturers. The picture below is the official errata of the most popular chip CC1101 , which is still in effect. In the list of errors, the chip sometimes does not accept something, sometimes it sends something wrong, and sometimes the PLL does not always work. This is not what you expect from a mass processor that has been produced for decades.
Another example is the MSP430 microprocessor, built on a set of commands. The microprocessor is about the same as the PDP-11 , on which Kernighan and Ritchie developed Unix. This is not Errata Thomas Aquinas, but the manufacturer offers us 27 pages of errors , many of which even do not know how to solve.
This is exactly what is not obvious on the Internet of things. We read the datasheet of the cheap chip and see that everything is fine and everything works until we open the last pages with a list of errors.
Human factor
Iron is more or less clear, errors are described and reproducible, but the biggest source of errors in IoT systems is man .
On January 13, 2018, all residents of Hawaii came to the mobile phones with an alert about the missile threat and the need to hide in an air-raid shelter.
It is not clear who was wrong: the operator or the person who designed the interface. But if you look at the picture, the answer suggests itself. What to click to call a test, not a combat, warning of a missile threat? If you do not know the answer, you will be mistaken.
Correct answer
BMD False Alarm
The operator pressed the wrong button, and the mass mailing started. The system did not have any parameters by which it would be possible to prevent or confirm the dispatch: “Are you sure you want to warn about a missile threat?”. It took 30 minutes for the staff of the center to realize what had happened and to send a message stating that the attack was false.
Man is a reliable system
Why we do not see these errors and do not believe that something is wrong? Because the man himself corrects all errors.
We are used to correcting errors.
If we feel that the computer does not work very well - we restart it. If we see that the mobile connection is gone, then we are looking for a place where it catches. If the machine does not work, we repair it.
The photo below shows human savvy to be proud of. Three people dangled in the Apollo 13 between the Earth and the Moon and were able to solve a non-trivial task - to put a square filter in a round hole. In addition to square filters, the mission was not lucky in another: the explosion of an oxygen cylinder, lack of water, engine damage. The team tried to survive using socks, electrical tape and packs of suits.
The man, as NASA said, is a very good backup system and fixes a lot. Solving problems on a spacecraft with the help of electrical tape and socks can be called almost reliable: it is completed in a short time, it will surely work and people will return alive, but this cannot be allowed into production.
Fault tolerance problem
The problem of resiliency for the Internet of things is very important, because the number of devices is growing. In the report of the consulting company McKinsey , in 2013 there were 10 billion IoT devices in the world, and by 2020 this number will increase to 30 billion.
We just physically will not be able to repair all of these counters - just not enough time. Systems that were designed for maintenance by people will not help us; instead, we will fix them.
In 2018 in the media and scientific journals flashed the news that the Chinese covered 100,000 sensors 2 channels with a total length of 1,400 km. A total of 130 types of sensors: water, wind, camera. From the point of view of operating expenses, the system is simply catastrophic: how many people need to wipe the camera or remove the snags? The entire state will be busy only cleaning and maintaining the system - it is not very autonomous.
Therefore, I want to talk a little about fault tolerance , about ensuring the operation of the system. Using simple examples, I will talk about tricks that will help in a short time to get a guaranteed working solution to present the product to investors, and then think about how to increase reliability incrementally. These tricks are quite versatile and will always help. The only thing that they are not very recommended for use in production, because they are like the filter.
Imagine: the day will come when investors will come to you for a project report, and you need to show a working product. Where to start so as not to screw it up?
Simplify
In the picture below there are two unrelated devices. On the left, a toy called a “sorter” : we insert a round one into a round one and a square one into a square one. A one-year-old child will learn how to use a toy in 2-3 attempts, because it is impossible to make a mistake with the “device” - a triangle will not fit into a square.
The same idea was proposed by the company Harris, which produces military radio stations. The picture on the right is Harris Falcon 3 , a marvel of engineering. Look at the interfaces, they are all different. In a state of combat, in conditions where there is no time to think, the operator will not physically be able to do something wrong. The power cable will not enter the connector from the antenna, and the radio operator will simply connect all the systems, even without turning on the brain. This is a simple and working way to prevent mistakes and reduce their likelihood. You say:
- And if we have a presentation tomorrow. Do we need to rewrite all interfaces? We did everything the same way there: 4 usb ports, 5 ethernet ports, we will definitely be mistaken.
No question, the simplification works here too - everything is closed. If you have 4 usb ports and one of them is guaranteed to work, leave it and close the rest. For example, tape - feel like an astronaut.
Simplification is not only creating an interface in which errors are impossible, but also removing everything that is superfluous. Reliability begins with this.
We created a simple device - a prototype, ready to be shown. What's next? Next, think about redundancy.
Redundancy
Internet of Things devices operate on the basis of information theory : there is a signal source, a receiver, a coder, a modulator, a propagation medium, and a source of errors that interferes and distorts the actual situation. A good way to reduce interference is to add redundancy , with which we can detect a critical situation and level out the effect of it: notify the operator or correct an error.
An example of redundancy is the STRIZH network. Most devices on the network are transmitted without confirmation: the device emits a signal and the base station receives it.
Imagine the situation. We have a zone with interference, in which the probability of message delivery to the base station is 90%, and the presentation is required to show no more than 1% loss. It seems that there is a lot of work: correcting protocols, reducing the range, but a quick and easy solution is redundancy. Next to the station that receives the signal with a delivery probability of 0.9, we put the second one, with the same delivery probability, and the probability of failure of both stations is simultaneously equal to 0.01. The probability multiplication theorem operates here: the probability of failure of each station individually is 0.1, and the failure of both of them is just 1%, provided that the base stations are independent. In this zone, there will be the highest probability of reception between base stations.
Another way to demonstrate the principle of redundancy - Watchdog Timer . This is a physical device that is embedded by most processor manufacturers. If the Watchdog Timer did not receive a signal from the computer after a certain time interval, then the device restarts the computer.
Using WT does not increase reliability, but availability . The computer detects the problem, takes control actions and reboots the computer. NASA is very fond of this and knows many different ways to use Watchdog Timer.
Below is an example of a multi-stage Watchdog Timer: when certain events occur, it sends an NMI — a hardware interrupt that will be required to work on the processor. When a certain event occurs, Watchdog informs the computer: “Try to reboot itself, otherwise turn off the power”. If the first timer did not work, the second one will work.
Redundancy works well within the operating system. Our base station is like this. It consists of various and independent modules . The autonomy of the modules prevents the error from getting from one module to another - a “pool” with errors is created, which we block. Above the hierarchy - a set of supervisors : scripts that monitor the situation on certain parameters. For example, that the process is in the operating system, it is not Zombies and does not flow through the memory. The root element is the scheduler , for example, cron.
The hierarchical structure creates good parameters for system availability: if a module crashes, the supervisor sees and reloads it, there is some redundancy in the modules, some modules perform the function of others.
Transition to another reference system
My favorite and most popular method among mathematicians. If it is known under what conditions the equipment operates, then in these conditions the pilot should be conducted. I will show you with examples.
Example number 1 . We created a device that works well at room temperature, and we are told:
- We are demonstrating the project in the Far North. Now there is −40, but make sure that everything works.
We run to the Internet and are looking for a solution:
- We need thermally stable quartz and flash drives that will not fail at −40.
Time goes on, resources are less and less, and panic - more. We think that the project is failed, but the transition to the reference system in which the base station operates will save us. Place the device in the box in which the heater and thermal relay are located. They are fairly stable guys and work almost always. When it is cold outside - the box is heated, and the device is working under normal conditions - we moved to the reference system in which we know and use the solution.
Example number 2 . Transition to moving reference systems. Imagine that we are collecting container data from a train. The first standard solution is to use gsm modems. This method is not suitable: for fast moving objects, you should use LTE or 5G devices that do a good doppler, and this is expensive. If the train moves in Russia, then when it arrives at the railway station, all modems will connect to the station and it will simply fall due to network overload.
Solution: transition to a fixed frame of reference. Let us recall the motion relativity: we place the base station inside the train and it is motionless relative to the moving train. The station will collect information from all sensors and transmit further using a gateway, satellite or LTE modem.
This approach improves reliability, helps to solve impossible tasks and organize delay-tolerant networking - a network that is resistant to discontinuities . For some reason, the approach is not loved in Russia, but it is actively promoted by the Disney Research division of the same corporation. They have not the Internet of things, but Internet toys - Internet of Toys . The company worries that African children do not watch Disney cartoons. It is expensive to carry out data transmission networks, install towers, draw fiber in Africa, and still they will steal everything, so they went the other way and used Richard Hamming's ideas:
Transmission at a distance is the same as transmission over time, that is, storage. If you can not transmit - save the information and transport it to the receiver.
At Disney, they did : equip bus stations and buses with a system of the cheapest Wi-Fi routers and a set of hard drives. The bus pulls up to the station, quickly downloads a set of Disney films to Wi-Fi and drives on. He comes to one village, to another, and unloads films in each one - African children are happy. This so-called Mul-Networks - cheap mules that move slowly, do not do well with the doppler, but deliver information to all points.
Similar developments in Disney exist for the transfer of email - the letter will arrive to you by bus. Very funny technology, but Amazon loves it, for example.
Amazon has a service for transporting exabytes of data - one million terabytes. If you have a large data center and you are thinking of moving to Amazon, because everything is already there, then in America they can fit such a truck to you and transport your data. If delays are not important to you, then this is a good way: the data transfer rate is of the order of tens or hundreds of Gbit / s. In addition to trucks, Amazon can send you a bag with hard drives - a snowball.
We understood that reliability is important, because both people and equipment refuse. Reliability needs to be thought the same as safety. For pilot presentations, turn on Watchdog, add redundancy and simplify so that it is impossible to go wrong. Think about how to go into the conditions under which the system is guaranteed to work. Now let's move on to the last method, which is different from the rest, and techies often ignore it.
beauty
You will be forgiven much if your prototype looks beautiful. If something goes wrong during the presentation and everything fails, you will hear: “Yes, everything is broken, but you have such a great product. I think that you need to give one more attempt to correct it. ” The principle works for Tesla: the company has problems with shipping, autopilot, accidents, but everyone loves them, because cars have a cool design. For this they all forgive.
findings
The future of the Internet of things is insecurity : IoT is aimed at mass markets, and for the mass market the decisive factor is price. So the Internet of things will consist of many cheap and unreliable devices . As the number of devices grows, so will the number of failures. We simply do not have enough hands to correct all errors. Therefore, the only way is that devices must independently deal with the consequences of failures . These are autonomous systems that must learn to repair themselves.
I would suggest that you take up the topic of reliability and learn how to show pilots in a cool way using three methods: simplify everything you can, add redundancy and create conditions under which the pilot will work. Do not forget that we are all human beings and are not guided by logic, but by feelings , so create beautiful projects .
There are no books or set of articles on reliability. To delve into the topic, start with an article about health, reliability, security , and then learn the experience of the NASA jet propulsion laboratory . They created Voyager and Curiosity and they know everything about reliability . Get inspired by the greats.
A little more than a month is left until the next InoThings ++ developer conference. It will be held on April 4th. We will prepare a program that covers all aspects of the Internet of Things world: the development of hardware and software devices, security for users, ways to transfer information between devices and the “server” and their testing, operation and change of business processes under the influence of IoT technologies. But perhaps it’s your report that is not enough to cover all the topics - submit your application before March 1.
Source: https://habr.com/ru/post/441606/
All Articles