The experience of building infrastructure on microservice architecture

Over the past year, there have been so many publications about microservices that it would be a waste of time to tell what it was and why it would be necessary, so that further discussion will focus on the question of how this architecture would be implemented and why it was and what problems it encountered.
We had big problems in a small bank: 3 python monoliths connected by a monstrous number of synchronous RPC interactions with a large legacy volume. In order to at least partially solve all the problems arising from this, it was decided to switch to the microservice architecture. But before you decide on such a step, you need to answer 3 basic questions:
- How to break a monolith into microservices and what criteria should be guided by.
- How will microservices interact?
- How to monitor?
Actually, this article will be devoted to brief answers to these questions.
How to break a monolith into microservices and what criteria should be guided by.
This seemingly simple question ultimately determined the entire subsequent architecture.
We are a bank, respectively, the whole system revolves around operations with finances and various auxiliary things. It is certainly possible to transfer financial ACID transactions to a distributed system with sagas , but in general it is extremely difficult. Thus, we have developed the following rules:
- Comply with SOLID S for microservices
- The transaction must be fully implemented in microservice - no distributed transactions on database damage
- Microservice needs information from its own database or from a query.
- Try to ensure purity (in the sense of functional languages) for microservices
Naturally, simultaneously and completely satisfying them turned out to be impossible, but even partial implementation greatly simplifies development.
How will microservices interact?
There are many options, but in the end, all of them can be abstracted by simple "microservices exchange messages", but if you implement a synchronous protocol (for example, RPC via REST), most of the shortcomings of the monolith will remain, but the advantages of microservices will hardly appear. So the obvious solution was to take any message broker and start working. Choosing between RabbitMQ and Kafka, we stopped at the last one and that is why:
- Kafka is simpler and provides a single messaging model - Publish – subscribe
- It is relatively easy to get data from the kafka a second time. This is extremely convenient for debugging or fixing bugs for incorrect processing as well as for monitoring and logging.
- Understandable and simple way to scale the service: added partitions to the topic, launched more subscribers - the rest will be made by Kafka.
Additionally, I want to draw attention to a very high-quality and detailed comparison .
Queues at the kafka + asynchrony allow us:
- Shortly turn off any microservice for updates without noticeable consequences for the rest
- Turn off any service for a long time and not bother with data recovery. For example, recently fell microservice fiscalization. They repaired in 2 hours, he took the unprocessed bills from the kafka and processed everything. It was not necessary, as before, to restore via HTTP logs and restore a separate table in the database that had to happen there and manually perform it.
- Run test versions of services on actual data from the sale and compare the results of their processing with the version of the service on sale.
We chose AVRO as the data serialization system, why - it is described in a separate article .
But regardless of the serialization method chosen, it is important to understand how the protocol update will take place. Although AVRO supports Schema Resolution, we don’t use it and decide purely administratively:
- The data in the topics is written and read only through AVRO, the name of the topic corresponds to the name of the scheme (and Confluent has a different approach - they write the AVRO ID of the registry to the upper bytes of the message, so they can have different types of messages in one topic
- If you need to supplement or change the data, then a new scheme is created with a new topic in the Kafka, after which all producers switch to a new topic, followed by the subscribers.
We store the AVRO schemes in git-submodules and connect them to all Kafka projects. The centralized register of schemes was decided not to be implemented yet.
PS: Colleagues made opensource option but only with JSON-schema instead of AVRO .
Some subtleties
Each subscriber receives all messages from the topic.
This is the specificity of the Publish – subscribe interaction model - when subscribed to a topic, the subscriber will receive them all. As a result, if the service needs only some of the messages, it will have to filter them. If this becomes a problem, then it will be possible to make a separate service router, which will decompose messages in several different topics, thereby implementing part of the RabbitMQ functional, which is absent in the Kafka. Now we have one python subscriber in one thread that processes approximately 7-5 thousand messages per second, but if you start with PyPy, then the speed rises to 11-15 thousand / s.
Limit the lifetime of the pointer in the topic
In the settings of the kafka there is a parameter limiting the time that the kafka "remembers" where the reader stopped - by default 2 days. It would be good to raise up to a week so that if the problem arises during the holidays and 2 days is not solved, this would not lead to the loss of position in the topic.
Time limit for read confirmation
If the reader of the Kafka does not confirm the reading in 30 seconds (a custom parameter), then the broker believes that something went wrong and an error occurs when trying to confirm the reading. To avoid this, we during long-term processing of the message. We send read confirmations without moving the pointer.
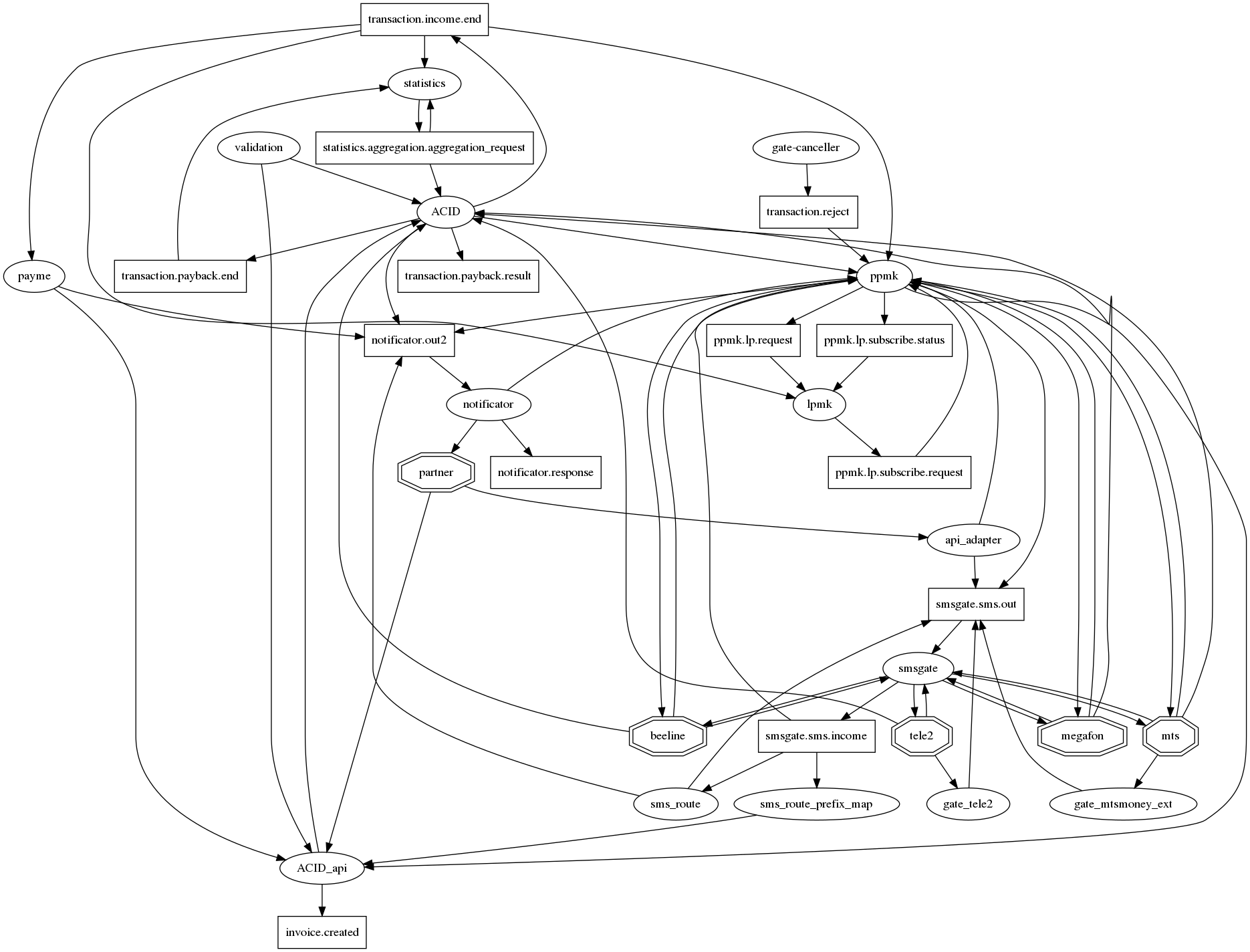
The link graph is difficult to grasp.
If you honestly draw all the relationships in graphviz, then a hedgehog of the apocalypse, traditional for microservices, with dozens of links in one node arises. In order to at least somehow make it (the graph of connections) readable, we agreed on the following notation: microservices - ovals, tops of the kafka - rectangles. Thus, it is possible to display both the fact of interaction and its type on one graph. But, alas, it is not much better. So this question is still open.
How to monitor?
Even as part of the monolith, we had logs in the files and Sentry. But as we move on to interacting through the kafka and deploying to k8s, the logs moved to ElasticSearch and, accordingly, first monitored reading the subscriber logs in Elastic. No logs - no work.
Beyond that, they started using Prometheus and kafka-exporter to slightly modify its dashboards: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
As a result, we get the following pictures: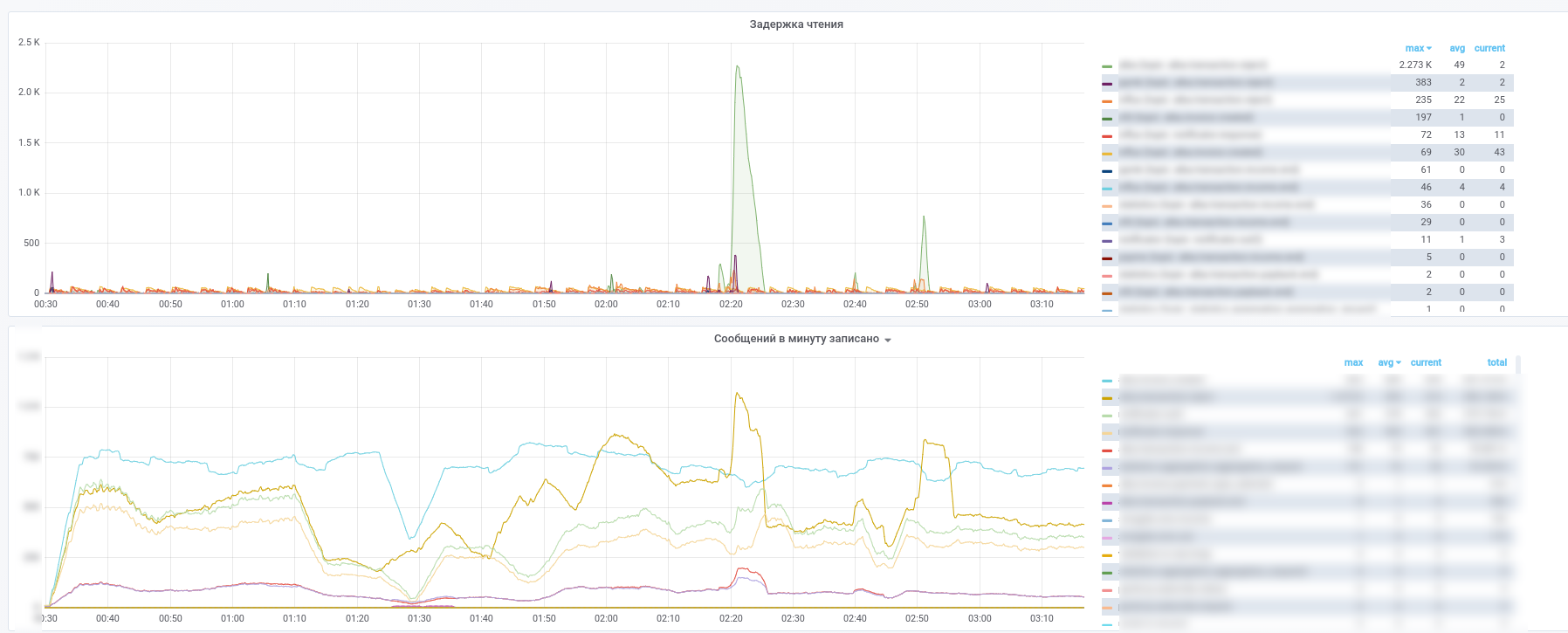
You can see which service any messages stopped processing.
In addition, all messages from the key (payment transactions, notifications from partners, etc.) topics are copied to InfluxDB, instituted in the same grafana. So that we can not only record the fact of message passing, but also make various selections by content. So, answers to questions like "what is the average delay time for a response from a service" or "Is the flow of transactions today very different from yesterday in this store" is always at hand.
Also, to simplify the analysis of incidents, we use the following approach: each service, when processing a message, complements it with meta-information containing a UUID issued when a system contains an array of records of the type:
- service name
- UUID of processing in this microservice
- start timestamp process
- process duration
- tag set
As a result, as the message passes through the computational graph, the message is enriched with information about the path traveled on the graph. It turns out to be an analogue of zipkin / opentracing for MQ, which allows getting a message to easily restore its path on the graph. This is especially valuable when there are cycles on the graph. Remember an example with a small service, the share in payments of which is only 0.0001%. By analyzing the meta-information in the message, it can determine if they were the initiators of the payment without going to the database for verification.
')
Source: https://habr.com/ru/post/441310/
All Articles