First look at FoundationDB open by Apple
In the last article, we looked at the limitations and obstacles that arise when you need to horizontally scale data and have a guarantee of ACID transaction properties. In this article, we talk about FoundationDB technology and understand how it helps overcome these limitations when developing mission-critical applications.
FoundationDB is a distributed NoSQL database with ACID transactions at the Serializable level, storing ordered key-value store pairs. Keys and values can be arbitrary sequences of bytes. It does not have a single point of incidence - all cluster machines are equal. It itself distributes data across the cluster servers and scales on the fly: when you need to add resources to the cluster, you simply add the address of the new machine on the configuration servers and the database itself picks up it.
In FoundationDB, transactions never block each other. Reading is implemented through multi-version control of versions (MVCC), and writing through optimistic concurrency control (OCC). The developers say that when all the cluster machines are in the same data center, the write latency is 2-3 ms, and the read latency is less than a millisecond. The documentation contains estimates of 10-15 ms, which is probably closer to the results in real conditions.
')
 * Does not support ACID properties on multiple shards.
* Does not support ACID properties on multiple shards.
FoundationDB has a unique advantage - automatic resharing. The DBMS itself ensures uniform load of the machines in the cluster: when one server overflows, it in the background redistributes data to neighboring ones. At the same time, the guarantee of a Serializable level for all transactions is maintained, and the only noticeable effect to customers is a slight increase in latency. The database ensures that the amount of data on the most and least loaded servers in the cluster differs by no more than 5%.
Logically, the FoundationDB cluster is a set of similar processes on different physical machines. The processes do not have their own configuration files, so they are interchangeable. Several fixed processes have a dedicated role - the Coordinators, and each process of the cluster knows their addresses at startup. It is important that the fall of the Coordinators be as independent as possible, so they are best placed on different physical machines or even in different data centers.
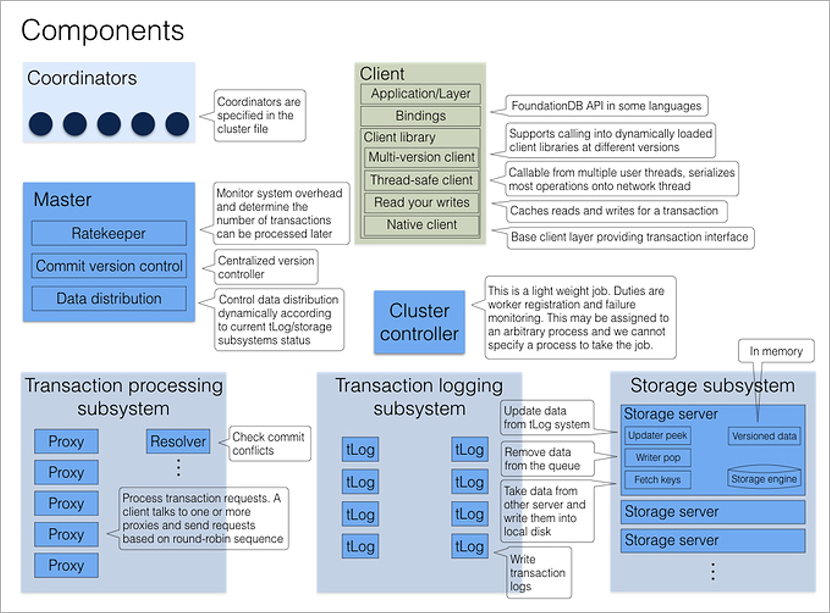
Coordinators agree among themselves through the Paxos consensus algorithm. They select the Cluster Controller process, which further assigns roles to the rest of the cluster processes. Cluster Controller continuously informs all Coordinators that he is alive. If the majority of Coordinators think he is dead, they simply choose a new one. Neither Cluster Controller nor Coordinators are involved in transaction processing, their main task is to eliminate the split brain situation.
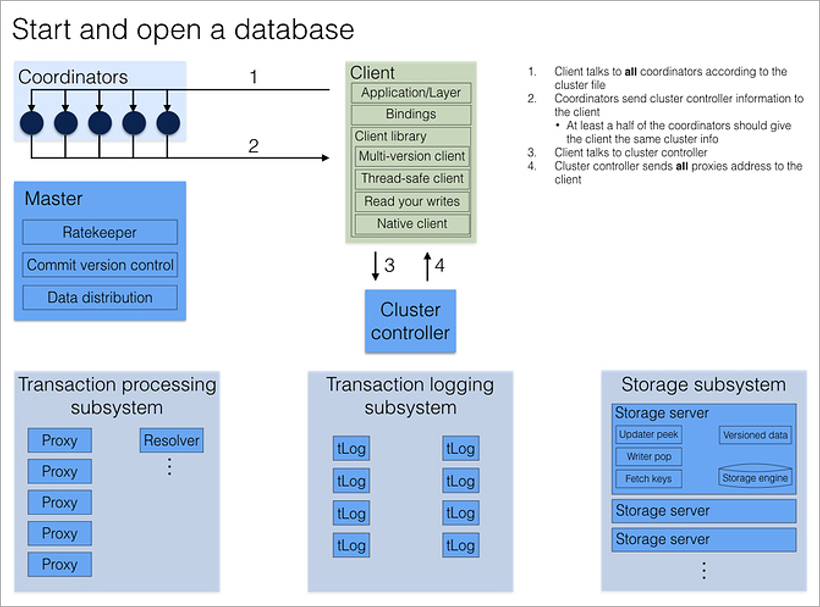
When a client wants to connect to the database, he contacts all Coordinators immediately for the address of the current Cluster Controller. If the majority of the answers coincide, it receives the full current cluster configuration from Cluster Controller (if it doesn’t coincide, it reapplies to the Coordinators).
Cluster Controller knows the total number of available processes and assigns roles: these 5 will be Proxy, these 2 will be Resolver, this will be Master. And if one of them dies, he will immediately find a replacement for him, by assigning the desired role to an arbitrary free process. This all happens in the background, unnoticed by the application programmer.
The Master process is responsible for the number of the current version of the data set (it increases with each entry in the database), as well as for distributing the set of keys to the storage servers and rate-throttling (artificially lowering the performance under heavy loads: if the cluster knows that the client he will make many small requests, he will wait, group them and answer all the pack at once).
Transaction logging and Storage are two independent data storage subsystems. The first is temporary storage for fast data writing to disk in the order of receipt, the second is permanent storage where the data on the disk is sorted in ascending order of keys. At each transaction commit, at least three tLog processes must save data before the cluster informs the client of success. In parallel, the data in the background is moved from the tLog servers to the Storage servers (storage on which is also redundant).
All client requests process proxy processes. Opening a transaction, the client calls on any proxy, which polls all other proxies, and returns the current version number of the cluster data. All subsequent readings occur at this version number. If another client has recorded data after I opened a transaction, I simply will not see any changes.
Writing a transaction is a bit more complicated, since conflicts need to be resolved. This includes the Resolver process, which stores all modified keys in memory for a period of time. When a client commits a write transaction, Resolver checks if the data it has read is out of date. (That is, whether the transaction that was opened after mine was changed and the keys that I read were changed.) If this happens, the transaction is rolled back and the client library itself (!) Tries to commit again. The only thing the developer has to think about is for the transactions to be idempotent, that is, re-use should give an identical result. One of the ways to achieve this is to save some unique value within a transaction, and at the beginning of a transaction, check its presence in the database.
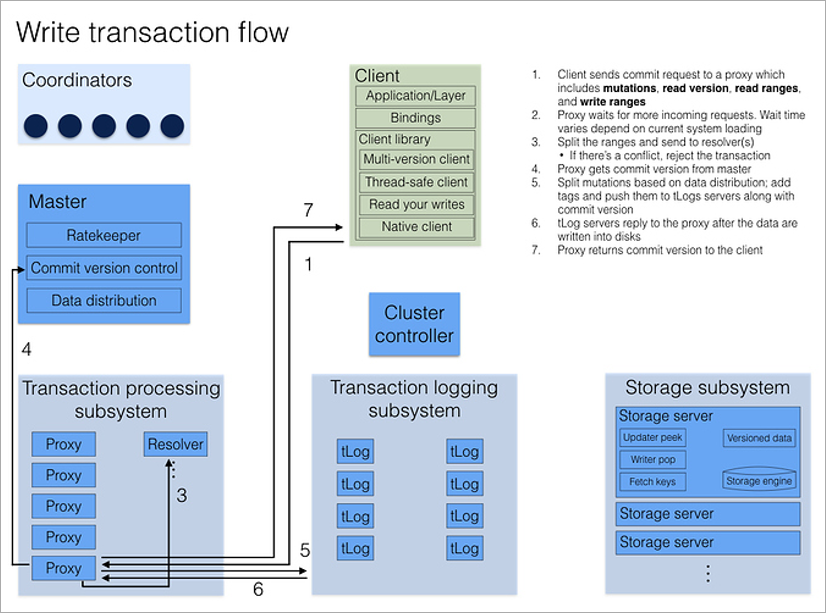
As with any client-server system, there are situations when a transaction is completed successfully, but the client has not received confirmation due to a connection failure. The client library treats them like any other error — it just tries again. This can potentially lead to the re-execution of the entire transaction. However, if the transaction is idempotent, there is no problem in this - it will not affect the final result.
In the storage subsystem (Storage) there may be thousands of servers. To which of them should the client refer when they need data on a specific key? From Cluster Controller, the client knows the complete configuration of the entire cluster, and it includes key ranges on each Storage server. Therefore, it simply refers directly to the necessary Storage-servers without any intermediate requests.
If the storage server is unavailable, the client library takes the new configuration from Cluster Controller. If, as a result of a server crash, the cluster realizes that the redundancy is insufficient, it immediately begins to assemble a new node from pieces of other Storage.
Suppose you save gigabytes of data in a transaction. How can you provide fast response? No, and therefore, FoundationDB simply limited the size of a single transaction to 10 megabytes. Moreover, this restriction on all data that the transaction concerns - reads or writes. Each record in the database is also limited - the key can not exceed 10 kilobytes, the value is 100 kilobytes. (At the same time, for optimal performance, developers recommend keys with a length of 32 bytes, and values with a length of 10 kilobytes.)
Any transaction could potentially become a source of conflict, and then it will have to be rolled back. Therefore, for the sake of speed, until the commit command arrived, it makes sense to keep the current changes in RAM, and not on disk. Suppose you are writing data to a database with a load of 1GB / second. Then, in the extreme case, your cluster will allocate 3GB RAM every second (we write transactions on 3 machines). How to limit such avalanche growth of used memory? Very simple - limit the maximum transaction time. In FoundationDB, a transaction cannot last longer than 5 seconds. If a client tries to access the database 5 seconds after opening a transaction, the cluster will ignore all its commands until it opens a new one.
Suppose you keep a list of people, each person has a unique identifier, use it as a key, and in the meaning of writing all the other attributes - name, gender, age, etc.
How to get a list of all people who are 30 years old without complete busting? Usually an index is created in the database for this. An index is a different view of the data, created to quickly search for additional attributes. We can simply add records like:
Now, to get the desired list, you just need to search the key range (30, *). Since FoundationDB keeps data sorted by key, such a query will be executed very quickly. Of course, the index takes up additional disk space, but quite a bit. Please note that not all attributes are duplicated, but only an age and an identifier.
It is important that the operations of adding the record itself and the index to it were performed in a single transaction.
FoundationDB is written in C ++. The authors started working on it in 2009, the first version was released in 2013, and in March 2015 they were bought by Apple. Three years later, Apple unexpectedly opened the source code. Rumor has it that Apple uses it, among other things, to store data for the iCloud service.
Experienced developers usually do not immediately trust new solutions. It may take years before the technology reliably recommends itself and it will begin to be massively used in sales. To shorten this time, the authors made an interesting extension of the C ++ language: Flow . It allows you to elegantly emulate work with unreliable external components with the possibility of a complete predictable repetition of the program. Each call to a network or disk is wrapped in some kind of wrapper (Actor), and each Actor has several implementations. The standard implementation writes data to disk or to the network, as expected. And the other writes to disk 999 times out of 1000, and 1 time out of 1000 loses. An alternative network implementation may, for example, swap bytes in network packets. There are even Actors imitating the work of an unwary sysadmin. This can delete the data folder or swap two folders. Developers chase thousands of simulations , substituting different Actors, and using Flow, they achieve 100% reproducibility: if a test fails, they can restart the simulation and get a fall in the same place. In particular, to eliminate the ambiguity introduced when the threads are switched by the OS scheduler, each FoundationDB process is strictly single-threaded.
When a researcher who discovered data loss scenarios in almost all popular NoSQL solutions was asked to test FoundationDB, he refused, noting that he did not see the point, because the authors did a tremendous job and tested them much deeper and more thoroughly than his own.
It is customary to think that failures in the cluster are random, but experienced devops know that this is far from the case. If you have 10 thousand disks of one manufacturer and the same number of another, then the failure rate (failure rate) will be different for them. In FoundationDB, a so-called machine-aware configuration is possible in which you can specify a cluster, which machines are in the same data center, and which processes are on the same machine. The DB will take this into account when distributing the load between the machines. And also machines in a cluster usually have different characteristics. FoundationDB also takes this into account, looks at the length of the request queues, and redistributes the load in a balanced way: weaker machines receive fewer requests.
So FoundationDB provides ACID transactions and the highest isolation level, Serializable, on a cluster of thousands of machines. Together with amazing flexibility and high performance, this sounds like magic. But you have to pay for everything, so there are some technological limitations.
In addition to the limits on the size and length of the transaction already mentioned, it is important to note the following features:
Translated from English, “Foundation” means “Foundation” and the authors of this DBMS see its role in this way: to provide a high level of reliability at the level of simple records, and any other database can be implemented as a superstructure above the basic functionality. Thus, on top of FoundationDB, you can potentially make various other layers - documents, columns, etc. The question remains how these layers will scale without losing performance. For example, the authors of CockroachDB have already gone this way - by making a SQL layer on top of RocksDB (local key value store) and got the performance problems inherent in relational joins.
To date, Apple has developed and published 2 layers on top of FoundationDB: Document Layer (supports MongoDB API) and Record Layer (stores records as field sets in Protocol Buffers format, supports indexes, is available only in Java). I am glad and pleasantly surprised that the historically closed company Apple today follows in the footsteps of Google and Microsoft and publishes the source code of the technologies used inside.
In software development there is such an existential conflict: the business constantly wants changes and improvements from the product. But at the same time he wants reliable software. And these two requirements contradict each other, because when the software changes, bugs appear and the business suffers from it. Therefore, if in your product you can rely on some kind of reliable, proven technology and write less code yourself, it is always worth doing. In this sense, despite certain restrictions, it is cool to be able not to sculpt crutches to different NoSQL databases, but to use a solution proven in production with ACID properties.
A year ago, we were optimistic about another technology - CockroachDB, but it did not meet our expectations for performance. Since then, we have lost our appetite for the idea of a SQL layer over a distributed key-value store and, therefore, did not look closely at, for example, TiDB . We plan to carefully try FoundationDB as a secondary database for the largest datasets in our project. If you already have experience with real use FoundationDB or TiDB in the sale, we will be glad to hear your opinion in the comments.
FoundationDB is a distributed NoSQL database with ACID transactions at the Serializable level, storing ordered key-value store pairs. Keys and values can be arbitrary sequences of bytes. It does not have a single point of incidence - all cluster machines are equal. It itself distributes data across the cluster servers and scales on the fly: when you need to add resources to the cluster, you simply add the address of the new machine on the configuration servers and the database itself picks up it.
In FoundationDB, transactions never block each other. Reading is implemented through multi-version control of versions (MVCC), and writing through optimistic concurrency control (OCC). The developers say that when all the cluster machines are in the same data center, the write latency is 2-3 ms, and the read latency is less than a millisecond. The documentation contains estimates of 10-15 ms, which is probably closer to the results in real conditions.
')
* Does not support ACID properties on multiple shards.FoundationDB has a unique advantage - automatic resharing. The DBMS itself ensures uniform load of the machines in the cluster: when one server overflows, it in the background redistributes data to neighboring ones. At the same time, the guarantee of a Serializable level for all transactions is maintained, and the only noticeable effect to customers is a slight increase in latency. The database ensures that the amount of data on the most and least loaded servers in the cluster differs by no more than 5%.
Architecture
Logically, the FoundationDB cluster is a set of similar processes on different physical machines. The processes do not have their own configuration files, so they are interchangeable. Several fixed processes have a dedicated role - the Coordinators, and each process of the cluster knows their addresses at startup. It is important that the fall of the Coordinators be as independent as possible, so they are best placed on different physical machines or even in different data centers.
Coordinators agree among themselves through the Paxos consensus algorithm. They select the Cluster Controller process, which further assigns roles to the rest of the cluster processes. Cluster Controller continuously informs all Coordinators that he is alive. If the majority of Coordinators think he is dead, they simply choose a new one. Neither Cluster Controller nor Coordinators are involved in transaction processing, their main task is to eliminate the split brain situation.
When a client wants to connect to the database, he contacts all Coordinators immediately for the address of the current Cluster Controller. If the majority of the answers coincide, it receives the full current cluster configuration from Cluster Controller (if it doesn’t coincide, it reapplies to the Coordinators).
Cluster Controller knows the total number of available processes and assigns roles: these 5 will be Proxy, these 2 will be Resolver, this will be Master. And if one of them dies, he will immediately find a replacement for him, by assigning the desired role to an arbitrary free process. This all happens in the background, unnoticed by the application programmer.
The Master process is responsible for the number of the current version of the data set (it increases with each entry in the database), as well as for distributing the set of keys to the storage servers and rate-throttling (artificially lowering the performance under heavy loads: if the cluster knows that the client he will make many small requests, he will wait, group them and answer all the pack at once).
Transaction logging and Storage are two independent data storage subsystems. The first is temporary storage for fast data writing to disk in the order of receipt, the second is permanent storage where the data on the disk is sorted in ascending order of keys. At each transaction commit, at least three tLog processes must save data before the cluster informs the client of success. In parallel, the data in the background is moved from the tLog servers to the Storage servers (storage on which is also redundant).
Query Processing
All client requests process proxy processes. Opening a transaction, the client calls on any proxy, which polls all other proxies, and returns the current version number of the cluster data. All subsequent readings occur at this version number. If another client has recorded data after I opened a transaction, I simply will not see any changes.
Writing a transaction is a bit more complicated, since conflicts need to be resolved. This includes the Resolver process, which stores all modified keys in memory for a period of time. When a client commits a write transaction, Resolver checks if the data it has read is out of date. (That is, whether the transaction that was opened after mine was changed and the keys that I read were changed.) If this happens, the transaction is rolled back and the client library itself (!) Tries to commit again. The only thing the developer has to think about is for the transactions to be idempotent, that is, re-use should give an identical result. One of the ways to achieve this is to save some unique value within a transaction, and at the beginning of a transaction, check its presence in the database.
As with any client-server system, there are situations when a transaction is completed successfully, but the client has not received confirmation due to a connection failure. The client library treats them like any other error — it just tries again. This can potentially lead to the re-execution of the entire transaction. However, if the transaction is idempotent, there is no problem in this - it will not affect the final result.
Scaling
In the storage subsystem (Storage) there may be thousands of servers. To which of them should the client refer when they need data on a specific key? From Cluster Controller, the client knows the complete configuration of the entire cluster, and it includes key ranges on each Storage server. Therefore, it simply refers directly to the necessary Storage-servers without any intermediate requests.
If the storage server is unavailable, the client library takes the new configuration from Cluster Controller. If, as a result of a server crash, the cluster realizes that the redundancy is insufficient, it immediately begins to assemble a new node from pieces of other Storage.
Suppose you save gigabytes of data in a transaction. How can you provide fast response? No, and therefore, FoundationDB simply limited the size of a single transaction to 10 megabytes. Moreover, this restriction on all data that the transaction concerns - reads or writes. Each record in the database is also limited - the key can not exceed 10 kilobytes, the value is 100 kilobytes. (At the same time, for optimal performance, developers recommend keys with a length of 32 bytes, and values with a length of 10 kilobytes.)
Any transaction could potentially become a source of conflict, and then it will have to be rolled back. Therefore, for the sake of speed, until the commit command arrived, it makes sense to keep the current changes in RAM, and not on disk. Suppose you are writing data to a database with a load of 1GB / second. Then, in the extreme case, your cluster will allocate 3GB RAM every second (we write transactions on 3 machines). How to limit such avalanche growth of used memory? Very simple - limit the maximum transaction time. In FoundationDB, a transaction cannot last longer than 5 seconds. If a client tries to access the database 5 seconds after opening a transaction, the cluster will ignore all its commands until it opens a new one.
Indices
Suppose you keep a list of people, each person has a unique identifier, use it as a key, and in the meaning of writing all the other attributes - name, gender, age, etc.
| Key | Value |
| 12345 | (Ivanov Ivan Ivanovich, M, 35) |
How to get a list of all people who are 30 years old without complete busting? Usually an index is created in the database for this. An index is a different view of the data, created to quickly search for additional attributes. We can simply add records like:
| Key | Value |
| (35, 12345) | '' |
Now, to get the desired list, you just need to search the key range (30, *). Since FoundationDB keeps data sorted by key, such a query will be executed very quickly. Of course, the index takes up additional disk space, but quite a bit. Please note that not all attributes are duplicated, but only an age and an identifier.
It is important that the operations of adding the record itself and the index to it were performed in a single transaction.
Reliability
FoundationDB is written in C ++. The authors started working on it in 2009, the first version was released in 2013, and in March 2015 they were bought by Apple. Three years later, Apple unexpectedly opened the source code. Rumor has it that Apple uses it, among other things, to store data for the iCloud service.
Experienced developers usually do not immediately trust new solutions. It may take years before the technology reliably recommends itself and it will begin to be massively used in sales. To shorten this time, the authors made an interesting extension of the C ++ language: Flow . It allows you to elegantly emulate work with unreliable external components with the possibility of a complete predictable repetition of the program. Each call to a network or disk is wrapped in some kind of wrapper (Actor), and each Actor has several implementations. The standard implementation writes data to disk or to the network, as expected. And the other writes to disk 999 times out of 1000, and 1 time out of 1000 loses. An alternative network implementation may, for example, swap bytes in network packets. There are even Actors imitating the work of an unwary sysadmin. This can delete the data folder or swap two folders. Developers chase thousands of simulations , substituting different Actors, and using Flow, they achieve 100% reproducibility: if a test fails, they can restart the simulation and get a fall in the same place. In particular, to eliminate the ambiguity introduced when the threads are switched by the OS scheduler, each FoundationDB process is strictly single-threaded.
When a researcher who discovered data loss scenarios in almost all popular NoSQL solutions was asked to test FoundationDB, he refused, noting that he did not see the point, because the authors did a tremendous job and tested them much deeper and more thoroughly than his own.
It is customary to think that failures in the cluster are random, but experienced devops know that this is far from the case. If you have 10 thousand disks of one manufacturer and the same number of another, then the failure rate (failure rate) will be different for them. In FoundationDB, a so-called machine-aware configuration is possible in which you can specify a cluster, which machines are in the same data center, and which processes are on the same machine. The DB will take this into account when distributing the load between the machines. And also machines in a cluster usually have different characteristics. FoundationDB also takes this into account, looks at the length of the request queues, and redistributes the load in a balanced way: weaker machines receive fewer requests.
So FoundationDB provides ACID transactions and the highest isolation level, Serializable, on a cluster of thousands of machines. Together with amazing flexibility and high performance, this sounds like magic. But you have to pay for everything, so there are some technological limitations.
Restrictions
In addition to the limits on the size and length of the transaction already mentioned, it is important to note the following features:
- The query language is not SQL, that is, developers with SQL experience will have to be retrained.
- The client library only supports 5 high-level languages (Phyton, Ruby, Java, Golang, and C). There is no official client for C # yet. Since there is no REST API, the only way to support another language is to write a wrapper on it over the standard C library.
- There are no access sharing mechanisms; all this logic should be provided by your application.
- The format of the data storage is not documented (although it is also not usually documented in commercial databases). This is a risk, because if the cluster suddenly fails, it is not immediately clear what to do and will have to dig into the source files.
- A strictly asynchronous programming model can seem complicated to novice developers.
- You need to constantly think about the idempotency of transactions.
- If you have to break long transactions into small ones, then you need to take care of integrity at the global level.
Translated from English, “Foundation” means “Foundation” and the authors of this DBMS see its role in this way: to provide a high level of reliability at the level of simple records, and any other database can be implemented as a superstructure above the basic functionality. Thus, on top of FoundationDB, you can potentially make various other layers - documents, columns, etc. The question remains how these layers will scale without losing performance. For example, the authors of CockroachDB have already gone this way - by making a SQL layer on top of RocksDB (local key value store) and got the performance problems inherent in relational joins.
To date, Apple has developed and published 2 layers on top of FoundationDB: Document Layer (supports MongoDB API) and Record Layer (stores records as field sets in Protocol Buffers format, supports indexes, is available only in Java). I am glad and pleasantly surprised that the historically closed company Apple today follows in the footsteps of Google and Microsoft and publishes the source code of the technologies used inside.
Perspectives
In software development there is such an existential conflict: the business constantly wants changes and improvements from the product. But at the same time he wants reliable software. And these two requirements contradict each other, because when the software changes, bugs appear and the business suffers from it. Therefore, if in your product you can rely on some kind of reliable, proven technology and write less code yourself, it is always worth doing. In this sense, despite certain restrictions, it is cool to be able not to sculpt crutches to different NoSQL databases, but to use a solution proven in production with ACID properties.
A year ago, we were optimistic about another technology - CockroachDB, but it did not meet our expectations for performance. Since then, we have lost our appetite for the idea of a SQL layer over a distributed key-value store and, therefore, did not look closely at, for example, TiDB . We plan to carefully try FoundationDB as a secondary database for the largest datasets in our project. If you already have experience with real use FoundationDB or TiDB in the sale, we will be glad to hear your opinion in the comments.
Source: https://habr.com/ru/post/441270/
All Articles