Quick start: Go + Apache Kafka + Redis
Recently, due to necessity, I looked through all the vacancy announcements of Go-developers, and half of them (at least) mention the platform for processing Apache Kafka message flows and the NoSQL Redis database. Well, everyone, of course, wants the candidate to know Docker and his ilk. All these requirements to us, who have seen the types of system engineers, seem to be somehow petty or something. Well, in fact, how does one line differ from another? With NoSQL databases, the situation is, of course, more diverse, but still they seem simpler than any MS SQL Server. All this, of course, my personal, repeatedly mentioned on Habré, the Effect of Dunning - Kruger .
So, since all employers require, you need to study these technologies. But starting with reading all the documentation from beginning to end is not very interesting. In my opinion, it is more productive to read the introduction, make a working prototype, correct mistakes, run into problems, solve them. And after all this, it is already with understanding to read the documentation, or even a separate book.

Those who are interested in a short time to get acquainted with the basic capabilities of these products, please read further.
The training program will be engaged in the factorization of numbers. It will consist of a generator of large numbers, a processor of numbers, a queue, column storage and a web server.
')
In the course of development, the following design patterns will be applied:
The system architecture will look like this:
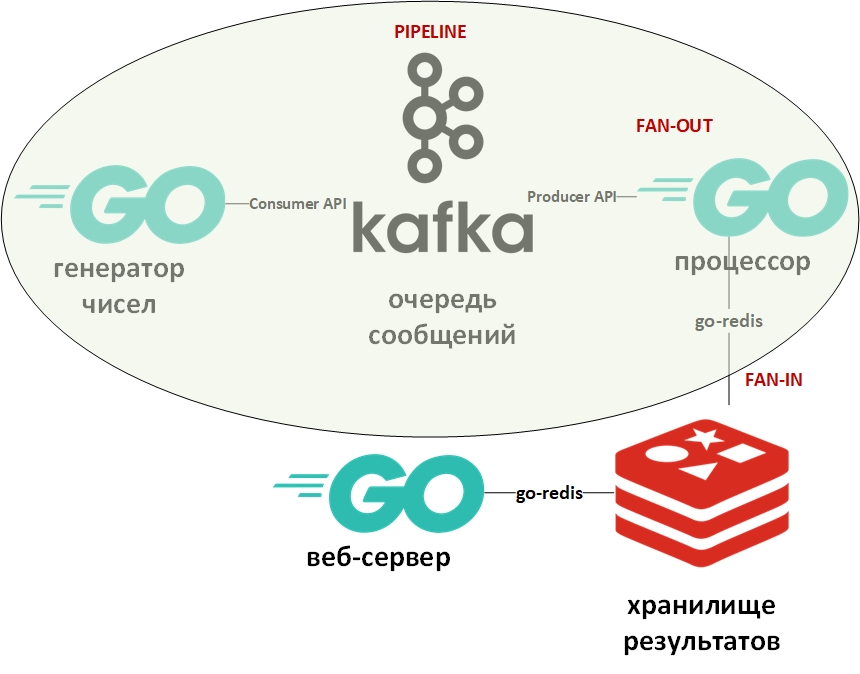
In the picture, the conveyor design pattern is marked with an oval. I will dwell on it in more detail.
The "pipeline" template assumes that information comes in the form of a stream and is processed in stages. Usually there is a generator (source of information) and one or several processors (information processors). In this case, the generator will be a program on Go, placing random large numbers in a queue. And the processor (the only one) will be the program that collects data from the queue and carries out factorization. On pure Go, this pattern is quite easily implemented using channels (chan). Above there is a link to my Github with an example. Here, the role of channels will be performed by the message queue.
Fan-In - Fan-Out templates are usually used together and in relation to Go, they mean paralleling computations with the help of Gorutin, followed by flattening the results and transferring them, for example, along the pipeline. The link to the example is also given above. Again, the channel is replaced by a queue, the gorutines remained in place.
Now a few words about Apache Kafka. Kafka is a message management system with excellent clustering tools, using transaction logs (exactly like in an RDBMS) for storing messages, and supporting both the queue model and the publisher / subscriber model. The latter is achieved through groups of message recipients. Each message gets only one member of the group (parallel processing), but the message will be delivered once to each group. There can be many groups like recipients within each group.
To work with Kafka, I will use the package "github.com/segmentio/kafka-go".
Redis is a key-value column database in memory that supports the ability to permanently store data. The main data type for keys and values is strings, but there are some others. Redis is considered one of the fastest (or most) databases in its class. It is good to store all sorts of statistics, metrics, message flows, etc. in it.
To work with Redis, I will use the "github.com/go-redis/redis" package.
Since this article is a quick start, we will deploy both systems using Docker using ready-made images from DockerHub. I use docker-compose on Windows 10 in container mode on a Linux VM (automatically created by the Docker VM program) with the following docker-compose.yml file:
Save this file, go to the directory with it and execute:
Three containers should download and run: Kafka (queue), Zookeeper (configuration server for Kafka) and (Redis).
You can make sure that the containers work with the help of the command:
It must be something like:
According to the yml file, three queues should be automatically created, you can see them with the command:
There should be queues (topics in Kafka terms) generated, solved and unsolved.
The data generator infinitely writes random numbers to the queue. Its code is extremely simple. You can verify that there are messages in the Generated queue using the command:
Next, the processor - here you should pay attention to the parallelization of the processing of values from the queue in the next block of code:
Since reading from the message queue blocks the program, I created a context.Context object with a timeout of 15 seconds. This timeout will terminate the program if the queue is empty for a long time.
Also, for each gorutina that factorizes the number, the maximum running time is also set. I wanted the numbers that I managed to factor in to be written to one database. And the numbers that could not be factorized in the allotted time - into another database.
The benchmark was used to determine the approximate time:
Benchmarks in Go are varieties of tests and are placed in a file with tests. Based on this measurement, the maximum number for a random number generator was selected. On my computer, some of the numbers had time to decompose into factors, and some - not.
Those numbers that could be decomposed were written in DB No. 0, non-decomposed numbers — in DB No. 1.
Here it must be said that in Redis there is no schema and tables in the classical sense. By default, the DBMS contains 16 databases available to the programmer. These bases are distinguished by their numbers - from 0 to 15.
The time limit for gorutin in the processor was provided using the context and the select statement:
This is another of the typical techniques of development on Go. Its meaning is that the select statement goes through the channels and executes the code corresponding to the first active channel. In this case, either the gorutin will produce the result in its channel, or the context channel with a timeout closes. Instead of the context, you can use an arbitrary channel that will play the role of a manager and ensure the forced termination of the gorutin.
The routines for writing to the database execute the command to select the desired database (0 or 1) and record pairs of the form (number - factors) for the parsed numbers or (number-number) for the non-resolved numbers.
The last part will be a web server , which will display a list of decomposed and non-decomposed numbers in the form of json. It will have two endpoints:
The handler of the http request with receiving data from Redis and returning them in the form of json looks like this:
Result of the request at: localhost / solved
Now you can delve into the documentation and specialized literature. Hope the article was helpful.
I ask the experts not to be lazy and point out my mistakes.
So, since all employers require, you need to study these technologies. But starting with reading all the documentation from beginning to end is not very interesting. In my opinion, it is more productive to read the introduction, make a working prototype, correct mistakes, run into problems, solve them. And after all this, it is already with understanding to read the documentation, or even a separate book.
Those who are interested in a short time to get acquainted with the basic capabilities of these products, please read further.
The training program will be engaged in the factorization of numbers. It will consist of a generator of large numbers, a processor of numbers, a queue, column storage and a web server.
')
In the course of development, the following design patterns will be applied:
The system architecture will look like this:
In the picture, the conveyor design pattern is marked with an oval. I will dwell on it in more detail.
The "pipeline" template assumes that information comes in the form of a stream and is processed in stages. Usually there is a generator (source of information) and one or several processors (information processors). In this case, the generator will be a program on Go, placing random large numbers in a queue. And the processor (the only one) will be the program that collects data from the queue and carries out factorization. On pure Go, this pattern is quite easily implemented using channels (chan). Above there is a link to my Github with an example. Here, the role of channels will be performed by the message queue.
Fan-In - Fan-Out templates are usually used together and in relation to Go, they mean paralleling computations with the help of Gorutin, followed by flattening the results and transferring them, for example, along the pipeline. The link to the example is also given above. Again, the channel is replaced by a queue, the gorutines remained in place.
Now a few words about Apache Kafka. Kafka is a message management system with excellent clustering tools, using transaction logs (exactly like in an RDBMS) for storing messages, and supporting both the queue model and the publisher / subscriber model. The latter is achieved through groups of message recipients. Each message gets only one member of the group (parallel processing), but the message will be delivered once to each group. There can be many groups like recipients within each group.
To work with Kafka, I will use the package "github.com/segmentio/kafka-go".
Redis is a key-value column database in memory that supports the ability to permanently store data. The main data type for keys and values is strings, but there are some others. Redis is considered one of the fastest (or most) databases in its class. It is good to store all sorts of statistics, metrics, message flows, etc. in it.
To work with Redis, I will use the "github.com/go-redis/redis" package.
Since this article is a quick start, we will deploy both systems using Docker using ready-made images from DockerHub. I use docker-compose on Windows 10 in container mode on a Linux VM (automatically created by the Docker VM program) with the following docker-compose.yml file:
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1" KAFKA_DELETE_TOPIC_ENABLE: "true" volumes: - /var/run/docker.sock:/var/run/docker.sock redis: image: redis ports: - "6379:6379" Save this file, go to the directory with it and execute:
docker-compose up -d Three containers should download and run: Kafka (queue), Zookeeper (configuration server for Kafka) and (Redis).
You can make sure that the containers work with the help of the command:
docker-compose ps It must be something like:
Name State Ports -------------------------------------------------------------------------------------- docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp According to the yml file, three queues should be automatically created, you can see them with the command:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181 There should be queues (topics in Kafka terms) generated, solved and unsolved.
The data generator infinitely writes random numbers to the queue. Its code is extremely simple. You can verify that there are messages in the Generated queue using the command:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning Next, the processor - here you should pay attention to the parallelization of the processing of values from the queue in the next block of code:
var wg sync.WaitGroup c := 0 //counter for { // 15 ctx, cancel := context.WithTimeout(context.Background(), 15*time.Second) defer cancel() // // - m, err := r.ReadMessage(ctx) if err != nil { fmt.Println("3") fmt.Println(err) break } wg.Add(1) // 10 goCtx, goCcancel := context.WithTimeout(context.Background(), 10*time.Millisecond) defer goCcancel() // () go process(goCtx, c, &wg, m) c++ } // wg.Wait() Since reading from the message queue blocks the program, I created a context.Context object with a timeout of 15 seconds. This timeout will terminate the program if the queue is empty for a long time.
Also, for each gorutina that factorizes the number, the maximum running time is also set. I wanted the numbers that I managed to factor in to be written to one database. And the numbers that could not be factorized in the allotted time - into another database.
The benchmark was used to determine the approximate time:
func BenchmarkFactorize(b *testing.B) { ch := make(chan []int) var factors []int for i := 1; i < bN; i++ { num := 2345678901234 go factorize(num, ch) factors = <-ch b.Logf("\n%d %+v\n\n", num, factors) } } Benchmarks in Go are varieties of tests and are placed in a file with tests. Based on this measurement, the maximum number for a random number generator was selected. On my computer, some of the numbers had time to decompose into factors, and some - not.
Those numbers that could be decomposed were written in DB No. 0, non-decomposed numbers — in DB No. 1.
Here it must be said that in Redis there is no schema and tables in the classical sense. By default, the DBMS contains 16 databases available to the programmer. These bases are distinguished by their numbers - from 0 to 15.
The time limit for gorutin in the processor was provided using the context and the select statement:
// go factorize(n, outChan) var item data select { case factors = <-outChan: { fmt.Printf("\ngoroutine #%d, input: %d, factors: %+v\n", counter, n, factors) item.Number = n item.Factors = factors err = storeSolved(item) if err != nil { fmt.Println("6") log.Fatal(err) } } case <-ctx.Done(): { fmt.Printf("\ngoroutine #%d, input: %d, exited on context timeout\n", counter, n) err = storeUnsolved(n) if err != nil { fmt.Println("7") log.Fatal(err) } return nil } } This is another of the typical techniques of development on Go. Its meaning is that the select statement goes through the channels and executes the code corresponding to the first active channel. In this case, either the gorutin will produce the result in its channel, or the context channel with a timeout closes. Instead of the context, you can use an arbitrary channel that will play the role of a manager and ensure the forced termination of the gorutin.
The routines for writing to the database execute the command to select the desired database (0 or 1) and record pairs of the form (number - factors) for the parsed numbers or (number-number) for the non-resolved numbers.
func storeSolved(item data) (err error) { // 0 cmd := redis.NewStringCmd("select", 0) err = client.Process(cmd) b, err := json.Marshal(item.Factors) err = client.Set(strconv.Itoa(item.Number), string(b), 0).Err() return err } The last part will be a web server , which will display a list of decomposed and non-decomposed numbers in the form of json. It will have two endpoints:
http.HandleFunc("/solved", solvedHandler) http.HandleFunc("/unsolved", unsolvedHandler) The handler of the http request with receiving data from Redis and returning them in the form of json looks like this:
func solvedHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization") // №0 - cmd := redis.NewStringCmd("select", 0) err := client.Process(cmd) if err != nil { w.WriteHeader(http.StatusInternalServerError) return } // keys := client.Keys("*") var solved []data var item data // for _, key := range keys.Val() { item.Key = key val, err := client.Get(key).Result() if err != nil { w.WriteHeader(http.StatusInternalServerError) return } item.Val = val solved = append(solved, item) } // JSON err = json.NewEncoder(w).Encode(solved) if err != nil { w.WriteHeader(http.StatusInternalServerError) return } } Result of the request at: localhost / solved
[{ "Key": "1604388558816", "Val": "[1,2,3,227]" }, { "Key": "545232916387", "Val": "[1,545232916387]" }, { "Key": "1786301239076", "Val": "[1,2]" }, { "Key": "698495534061", "Val": "[1,3,13,641,165331]" }] Now you can delve into the documentation and specialized literature. Hope the article was helpful.
I ask the experts not to be lazy and point out my mistakes.
Source: https://habr.com/ru/post/441250/
All Articles